基於深度學習的車型識別系統(Python+清新介面+資料集)

摘要:基於深度學習的車型識別系統用於識別不同型別的車輛,應用YOLO V5演演算法根據不同尺寸大小區分和檢測車輛,並統計各型別數量以輔助智慧交通管理。本文詳細介紹車型識別系統,在介紹演演算法原理的同時,給出Python的實現程式碼以及PyQt的UI介面。在介面中可以選擇各種圖片、視訊進行檢測識別;可對影象中存在的多目標進行識別分類,檢測速度快、識別精度高。博文提供了完整的Python程式碼和使用教學,適合新入門的朋友參考,完整程式碼資原始檔請轉至文末的下載連結。本博文目錄如下:
完整程式碼下載:https://mbd.pub/o/bread/ZJaXlZlx
參考視訊演示:https://www.bilibili.com/video/BV1yM411p7kq/
離線依賴庫下載:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取碼:oy4n )
前言
智慧交通系統是現代化交通的重要組成部分,是未來交通系統的發展趨勢。在智慧交通中,車型的自動識別是一個重要的研究方向。其在停車場車輛管理、道路交通狀況監管和車流量統計等眾多領域有著廣泛的應用。針對交通視訊,車型識別系統主要利用影象處理和圖形識別技術來實時進行分析處理視訊監控資料。
本系統基於YOLOv5,採用登入註冊進行使用者管理,對於圖片、視訊和攝像頭捕獲的實時畫面,可檢測車型,系統支援結果記錄、展示和儲存,每次檢測的結果記錄在表格中。對此這裡給出博主設計的介面,同款的簡約風,功能也可以滿足圖片、視訊和攝像頭的識別檢測,希望大家可以喜歡,初始介面如下圖:

檢測類別時的介面截圖(點選圖片可放大)如下圖,可識別畫面中存在的多個類別,也可開啟攝像頭或視訊檢測:
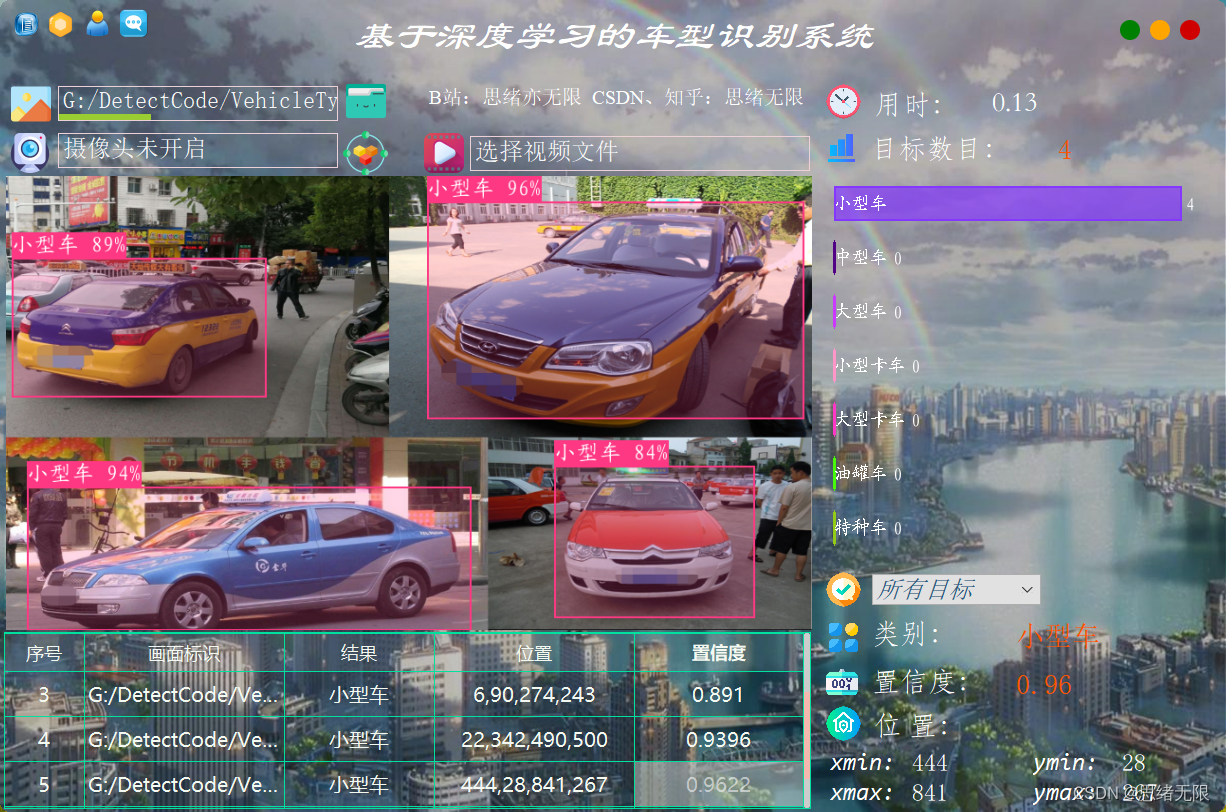
詳細的功能演示效果參見博主的B站視訊或下一節的動圖演示,覺得不錯的朋友敬請點贊、關注加收藏!系統UI介面的設計工作量較大,介面美化更需仔細雕琢,大家有任何建議或意見和可在下方評論交流。
1. 效果演示
一款軟體的顏值和功能同樣重要,首先我們還是通過動圖看一下識別的效果,系統主要實現的功能是對圖片、視訊和攝像頭畫面中的車型進行識別,識別的結果視覺化顯示在介面和影象中,另外提供多個目標的顯示選擇功能,演示效果如下。
(一)系統介紹
基於深度學習的車型識別系統主要用於不同尺寸型別的車輛識別,利用攝像裝置採集的影象、視訊或實時畫面,應用深度學習技術識別多種包括小型車、中型車、大型車、小型卡車、大型卡車等7種型別車輛,在軟體介面中標記檢測框和車型類別,並視覺化數量;軟體準確定位檢測車輛並記錄在介面中顯示記錄結果,支援各個型別車輛數目、類別、置信度等結果視覺化、展示和儲存;軟體提供登入註冊功能,可進行使用者管理。
(二)技術特點
(1)檢測模型支援更換,模型採用YOLOv5訓練;
(2)攝像頭實時檢測車型,展示、記錄和儲存識別結果;
(3)可檢測圖片、視訊等檔案,統計結果實時視覺化;
(4)支援使用者登入、註冊,檢測結果視覺化功能;
(三)使用者註冊登入介面
這裡設計了一個登入介面,可以註冊賬號和密碼,然後進行登入。介面還是參考了當前流行的UI設計,左側是一個LOGO圖,右側輸入賬號、密碼、驗證碼等等。

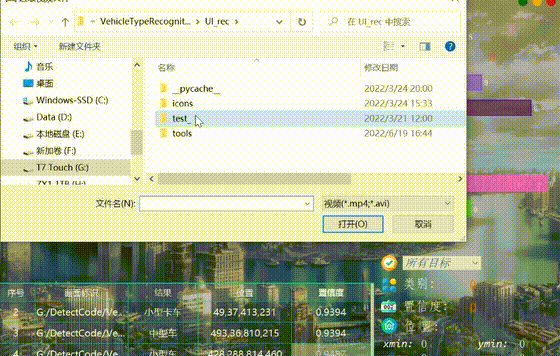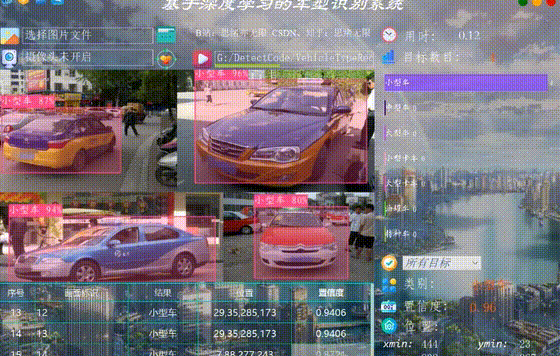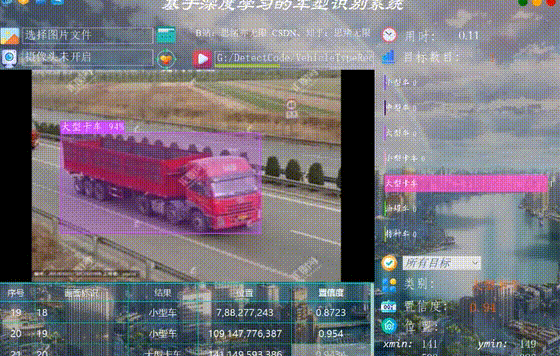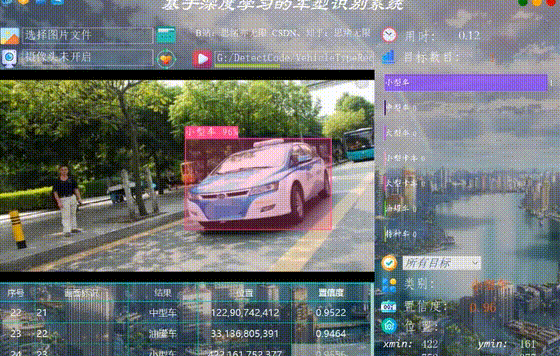
(四)選擇圖片識別
系統允許選擇圖片檔案進行識別,點選圖片選擇按鈕圖示選擇圖片後,顯示所有識別的結果,可通過下拉選框檢視單個結果,以便具體判斷某一特定目標。本功能的介面展示如下圖所示:
(五)視訊識別效果展示
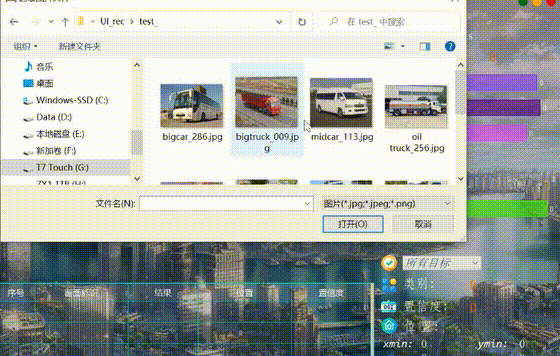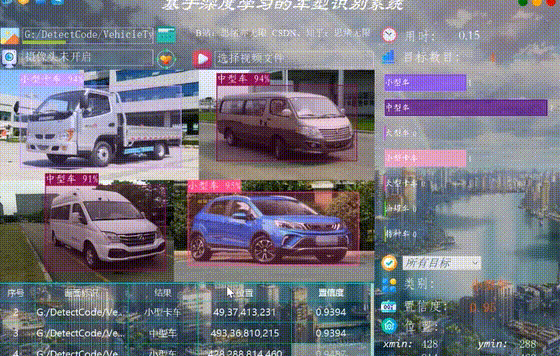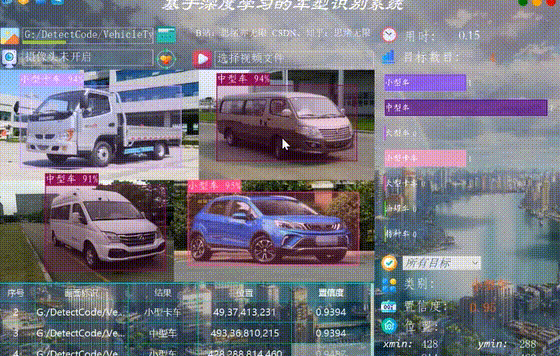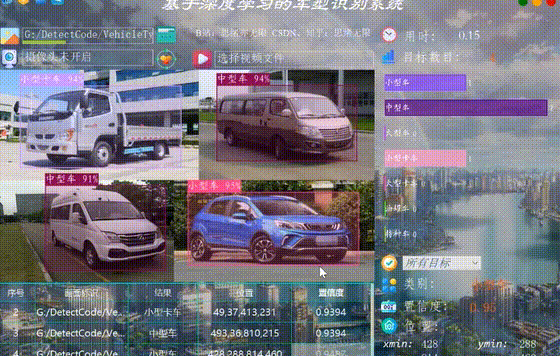
很多時候我們需要識別一段視訊中的多個車輛,這裡設計了視訊選擇功能。點選視訊按鈕可選擇待檢測的視訊,系統會自動解析視訊逐幀識別多個車型,並將車型的分類和計數結果記錄在右下角表格中,效果如下圖所示:
(六)攝像頭檢測效果展示
在真實場景中,我們往往利用道路的攝像頭獲取實時畫面,同時需要對車型進行識別,因此本文考慮到此項功能。如下圖所示,點選攝像頭按鈕後系統進入準備狀態,系統顯示實時畫面並開始檢測畫面中的車型,識別結果展示可見本人視訊。
2. 車型資料集及訓練
(一)YOLOv5模型簡介
本文藉助YOLOv5實現對不同大小車輛的型別進行識別,YOLOv5的呼叫、訓練和預測都十分方便,並且它為不同的裝置需求和不同的應用場景提供了大小和引數數量不同的網路。
YOLOv5模型是一個在COCO資料集上預訓練的物體檢測架構和模型系列,它是YOLO系列的一個延伸,能夠很好的用來進行車型的特徵提取,其網路結構共分為:input、backbone、neck和head四個模組,yolov5對yolov4網路的優點在於:在input端使用了Mosaic資料增強、自適應錨框計算、自適應圖片縮放; 在backbone端使用了Focus結構與CSP結構;在neck端新增了FPN+PAN結構;在head端改進了訓練時的損失函數,使用GIOU_Loss,以及預測框篩選的DIOU_nms。除了模型結構,yolov5使用Pytorch框架,對使用者非常友好;程式碼易讀;模型訓練快速;能夠直接對影象,視訊進行推理;能直接部署到手機應用端;預測速度非常快。YoloV5模型詳解可以參照連結。
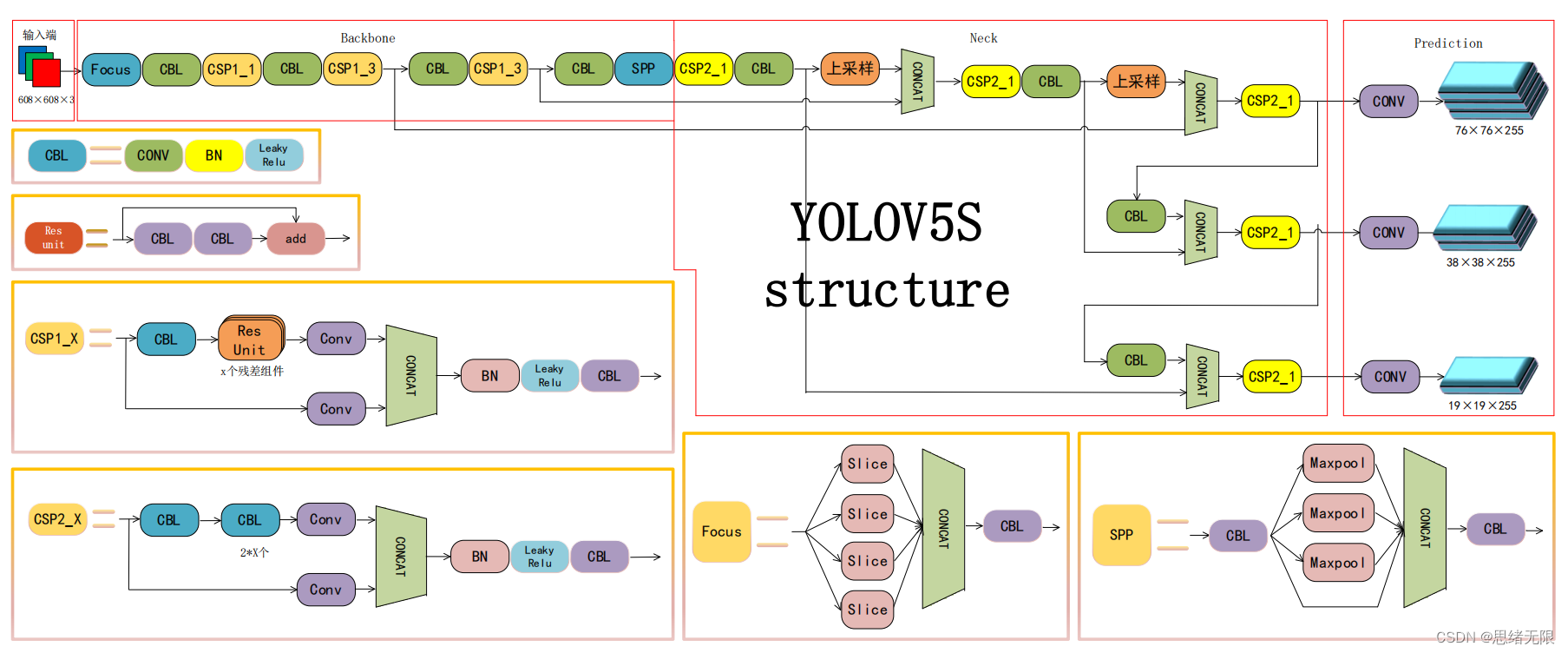
(1)主幹部分:使用了Focus網路結構,具體操作是在一張圖片中每隔一個畫素拿到一個值,這個時候獲得了四個獨立的特徵層,然後將四個獨立的特徵層進行堆疊,此時寬高資訊就集中到了通道資訊,輸入通道擴充了四倍。該結構在YoloV5第5版之前有所應用,最新版本中未使用。
(2)資料增強:Mosaic資料增強、Mosaic利用了四張圖片進行拼接實現資料中增強,優點是可以豐富檢測物體的背景,且在BN計算的時候可以計算四張圖片的資料。
(3)多正樣本匹配:在之前的Yolo系列裡面,在訓練時每一個真實框對應一個正樣本,即在訓練時,每一個真實框僅由一個先驗框負責預測。YoloV5中為了加快模型的訓練效率,增加了正樣本的數量,在訓練時,每一個真實框可以由多個先驗框負責預測。
(二)車型識別資料集
這裡我們使用的車型資料集,其中訓練集包含1488張圖片,驗證集包含507張圖片,測試集包含31張圖片,共計2026張圖片。部分圖片和標註情況如下圖所示。

每張影象均提供了影象類標記資訊,影象中車型的bounding box,車型的關鍵part資訊,以及車型的屬性資訊,資料集並解壓後得到如下的圖片

該資料集分為7類,分別有小型車,中型車,大型車,小型卡車,大型卡車,油罐車,特種車。
Chinese_name = {'tiny-car': "小型車", 'mid-car': "中型車", 'big-car': "大型車", 'small-truck': "小型卡車",
'big-truck': "大型卡車", 'oil-truck': "油罐車", 'special-car': "特種車"}
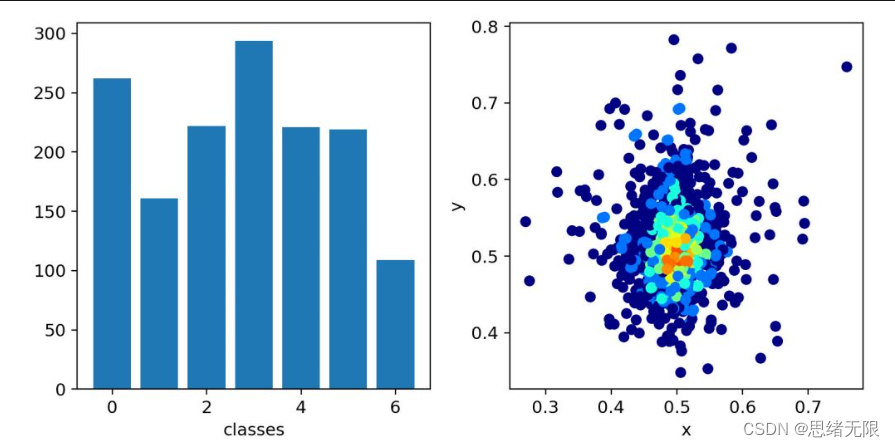
我們分析一下資料集的組成結構,第4類也就是小型卡車的的圖片最多,並且x,y座標主要集中在0.5,0.5的位置。
這裡我們開始訓練和測試自己的資料集,在cmd終端中執行train.py進行訓練,以下是訓練過程中的結果截圖。
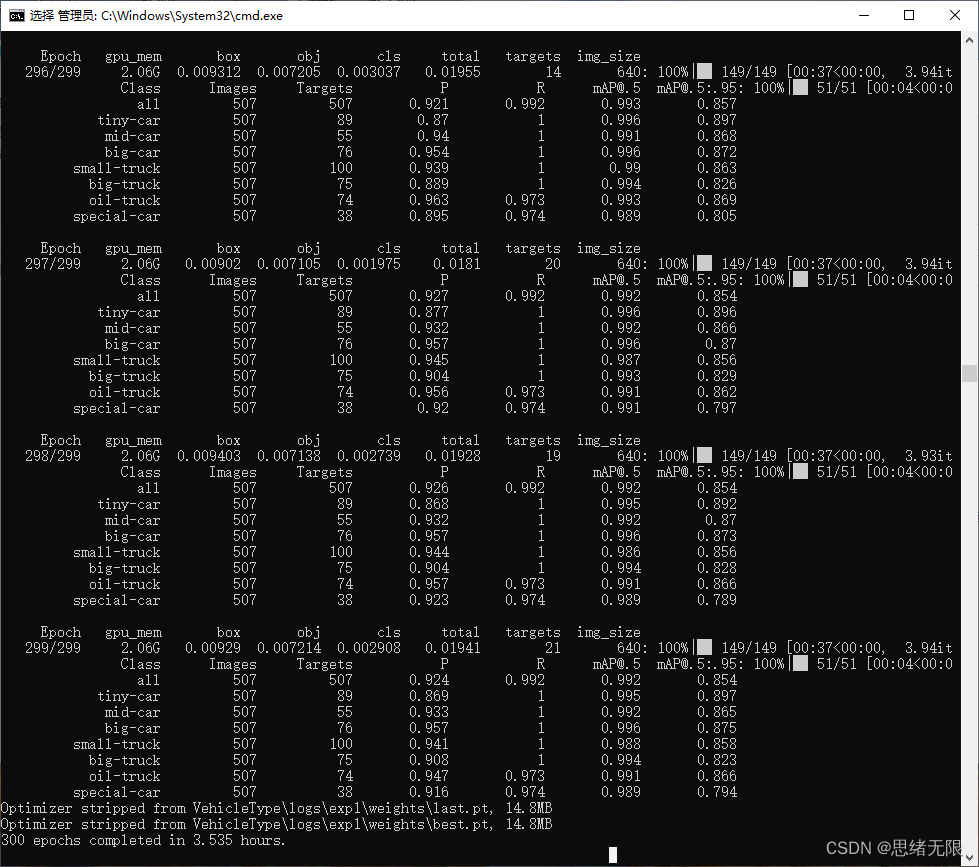
在深度學習中,我們通常通過損失函數下降的曲線來觀察模型訓練的情況。而YOLOv5訓練時主要包含三個方面的損失:矩形框損失(box_loss)、置信度損失(obj_loss)和分類損失(cls_loss),在訓練結束後,我們也可以在logs目錄下找到生成對若干訓練過程統計圖。下圖為博主訓練車型類識別的模型訓練曲線圖。
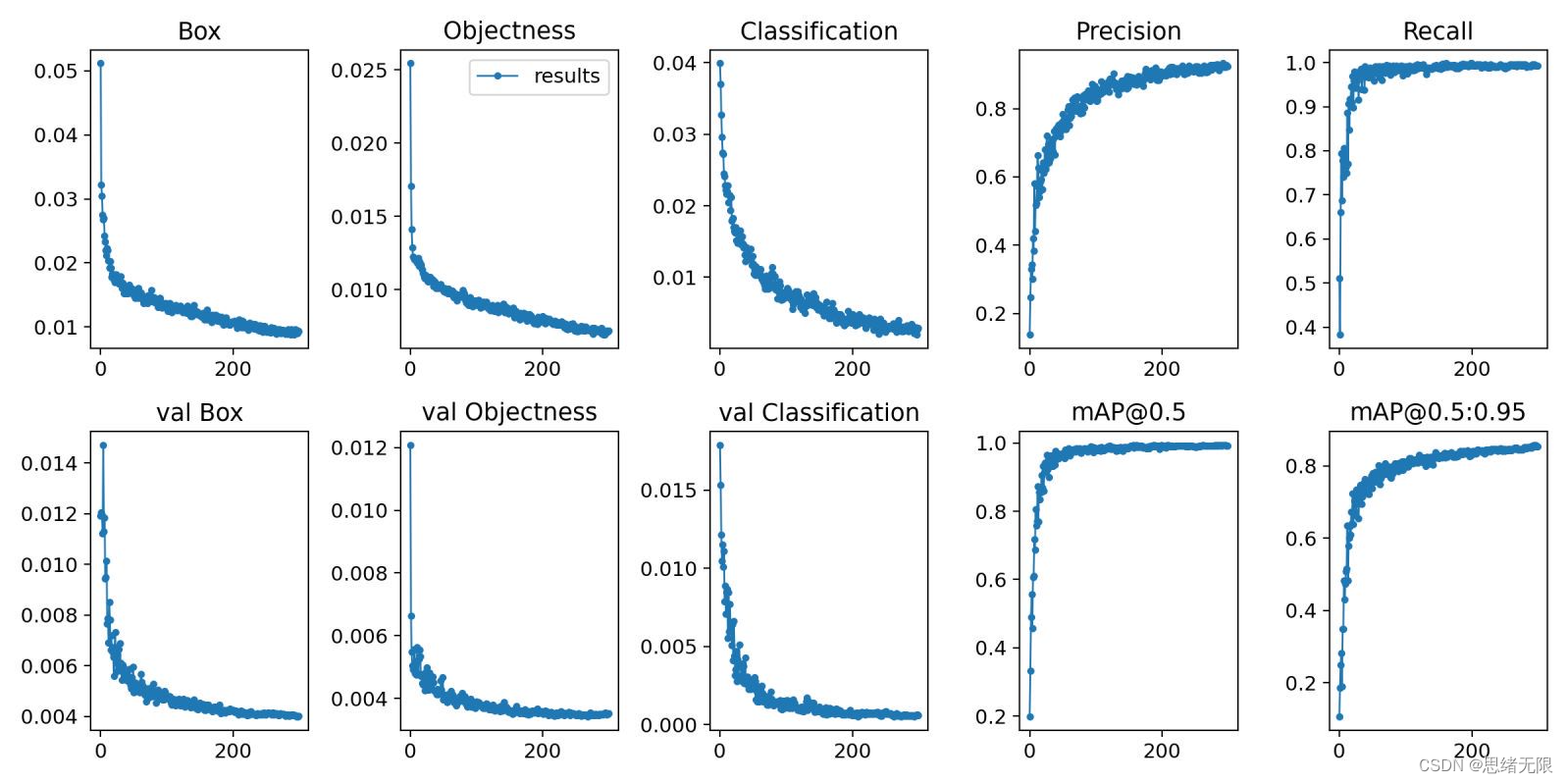
一般我們會接觸到兩個指標,分別是召回率recall和精度precision,兩個指標p和r都是簡單地從一個角度來判斷模型的好壞,均是介於0到1之間的數值,其中接近於1表示模型的效能越好,接近於0表示模型的效能越差,為了綜合評價目標檢測的效能,一般採用均值平均密度map來進一步評估模型的好壞。我們通過設定不同的置信度的閾值,可以得到在模型在不同的閾值下所計算出的p值和r值,一般情況下,p值和r值是負相關的,繪製出來可以得到如下圖所示的曲線,其中曲線的面積我們稱AP,目標檢測模型中每種目標可計算出一個AP值,對所有的AP值求平均則可以得到模型的mAP值。

以PR-curve為例,你可以看到我們的模型在驗證集上的均值平均準確率為0.992。
3. 車型檢測識別
在訓練完成後得到最佳模型,接下來我們將幀影象輸入到這個網路進行預測,從而得到預測結果,預測方法(testVideo.py)部分的程式碼如下所示:
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
def plot_one_box(img, x, color=None, label=None, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
執行得到的結果如下圖所示,圖中車型的種類和置信度值都標註出來了,預測速度較快。基於此模型我們可以將其設計成一個帶有介面的系統,在介面上選擇圖片、視訊或攝像頭然後呼叫模型進行檢測。
if __name__ == '__main__':
# video_path = 0
video_path = "./UI_rec/test_/test.mp4"
# 初始化視訊流
vs = cv2.VideoCapture(video_path)
(W, H) = (None, None)
frameIndex = 0 # 視訊幀數
try:
prop = cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
# print("[INFO] 視訊總幀數:{}".format(total))
# 若讀取失敗,報錯退出
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
fourcc = cv2.VideoWriter_fourcc(*'XVID')
ret, frame = vs.read()
vw = frame.shape[1]
vh = frame.shape[0]
print("[INFO] 視訊尺寸:{} * {}".format(vw, vh))
output_video = cv2.VideoWriter("./results.avi", fourcc, 20.0, (vw, vh)) # 處理後的視訊物件
# 遍歷視訊幀進行檢測
while True:
# 從視訊檔中逐幀讀取畫面
(grabbed, image) = vs.read()
# 若grabbed為空,表示視訊到達最後一幀,退出
if not grabbed:
print("[INFO] 執行結束...")
output_video.release()
vs.release()
exit()
# 獲取畫面長寬
if W is None or H is None:
(H, W) = image.shape[:2]
image = cv2.resize(image, (850, 500))
img0 = image.copy()
img = letterbox(img0, new_shape=imgsz)[0]
img = np.stack(img, 0)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
pred, useTime = predict(img)
det = pred[0]
p, s, im0 = None, '', img0
if det is not None and len(det): # 如果有檢測資訊則進入
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把影象縮放至im0的尺寸
number_i = 0 # 類別預編號
detInfo = []
for *xyxy, conf, cls in reversed(det): # 遍歷檢測資訊
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# 將檢測資訊新增到字典中
detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])
number_i += 1 # 編號數+1
label = '%s %.2f' % (names[int(cls)], conf)
# 畫出檢測到的目標物
plot_one_box(image, xyxy, label=label, color=colors[int(cls)])
# 實時顯示檢測畫面
cv2.imshow('Stream', image)
image = cv2.resize(image, (vw, vh))
output_video.write(image) # 儲存標記後的視訊
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# print("FPS:{}".format(int(0.6/(end-start))))
frameIndex += 1
執行得到的結果如下圖所示,圖中車輛的種類和置信度值都標註出來了,預測速度較快。基於此模型我們可以將其設計成一個帶有介面的系統,在介面上選擇圖片、視訊或攝像頭然後呼叫模型進行檢測。

博主對整個系統進行了詳細測試,最終開發出一版流暢得到清新介面,就是博文演示部分的展示,完整的UI介面、測試圖片視訊、程式碼檔案,以及Python離線依賴包(方便安裝執行,也可自行設定環境),均已打包上傳,感興趣的朋友可以通過下載連結獲取。
下載連結
若您想獲得博文中涉及的實現完整全部程式檔案(包括測試圖片、視訊,py, UI檔案等,如下圖),這裡已打包上傳至博主的麵包多平臺,見可參考部落格與視訊,已將所有涉及的檔案同時打包到裡面,點選即可執行,完整檔案截圖如下:
在資料夾下的資源顯示如下,下面的連結中也給出了Python的離線依賴包,讀者可在正確安裝Anaconda和Pycharm軟體後,複製離線依賴包至專案目錄下進行安裝,離線依賴的使用詳細演示也可見本人B站視訊:win11從頭安裝軟體和設定環境執行深度學習專案、Win10中使用pycharm和anaconda進行python環境設定教學。

注意:該程式碼採用Pycharm+Python3.8開發,經過測試能成功執行,執行介面的主程式為runMain.py和LoginUI.py,測試圖片指令碼可執行testPicture.py,測試視訊指令碼可執行testVideo.py。為確保程式順利執行,請按照requirements.txt設定Python依賴包的版本。Python版本:3.8,請勿使用其他版本,詳見requirements.txt檔案;
完整資源中包含資料集及訓練程式碼,環境設定與介面中文字、圖片、logo等的修改方法請見視訊,專案完整檔案下載請見以下連結處給出:➷➷➷
完整程式碼下載:https://mbd.pub/o/bread/ZJaXlZlx
參考視訊演示:https://www.bilibili.com/video/BV1yM411p7kq/
離線依賴庫下載:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取碼:oy4n )
介面中文字、圖示和背景圖修改方法:
在Qt Designer中可以徹底修改介面的各個控制元件及設定,然後將ui檔案轉換為py檔案即可呼叫和顯示介面。如果只需要修改介面中的文字、圖示和背景圖的,可以直接在ConfigUI.config檔案中修改,步驟如下:
(1)開啟UI_rec/tools/ConfigUI.config檔案,若亂碼請選擇GBK編碼開啟。
(2)如需修改介面文字,只要選中要改的字元替換成自己的就好。
(3)如需修改背景、圖示等,只需修改圖片的路徑。例如,原檔案中的背景圖設定如下:
mainWindow = :/images/icons/back-image.png
可修改為自己的名為background2.png圖片(位置在UI_rec/icons/資料夾中),可將該項設定如下即可修改背景圖:
mainWindow = ./icons/background2.png
結束語
由於博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處。希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前。同時如果有更好的實現方法也請您不吝賜教。