Debiased Contrastive Learning of Unsupervised Sentence Representations 論文精讀
1. 介紹(Introduction)
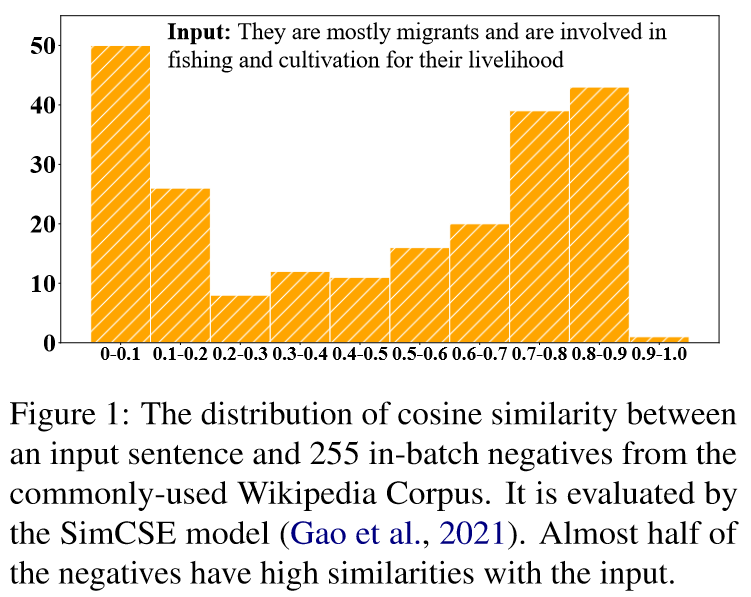
問題: 由PLM編碼得到的句子表示在方向上分佈不均勻, 在向量空間中佔據一個狹窄的錐形區域, 這在很大程度上限制了它們的表達能力.
已有的解決辦法: 對比學習. 對於一個原句, 構造他的正例(語意相似的句子)和負例(語意不相似的句子), 拉近語意相近的句子來提高對齊性,同時讓語意不同的句子遠離來使向量空間中的句子更均勻. 正例通常用資料增強的策略來獲得. 由於沒有真實標註的資料, 負例一般在一個batch中隨機抽樣得到. 但這可能會導致抽樣偏差, 影響句子表示的學習. 表現在以下兩個方面:
- 抽樣的負例很可能是假負例, 他們在語意上其實是接近原句的. 如果簡單地拉遠些抽樣得到的非負例, 很可能會損害句子表示的語意.
- 由於各向異性問題, 由PLMs得到的句子向量本身就在向量空間中僅佔據一個狹窄的錐形區域, 從他們中隨機抽取出的負例也不能完全反映表示空間的整體語意.
2. 方法(Approach)
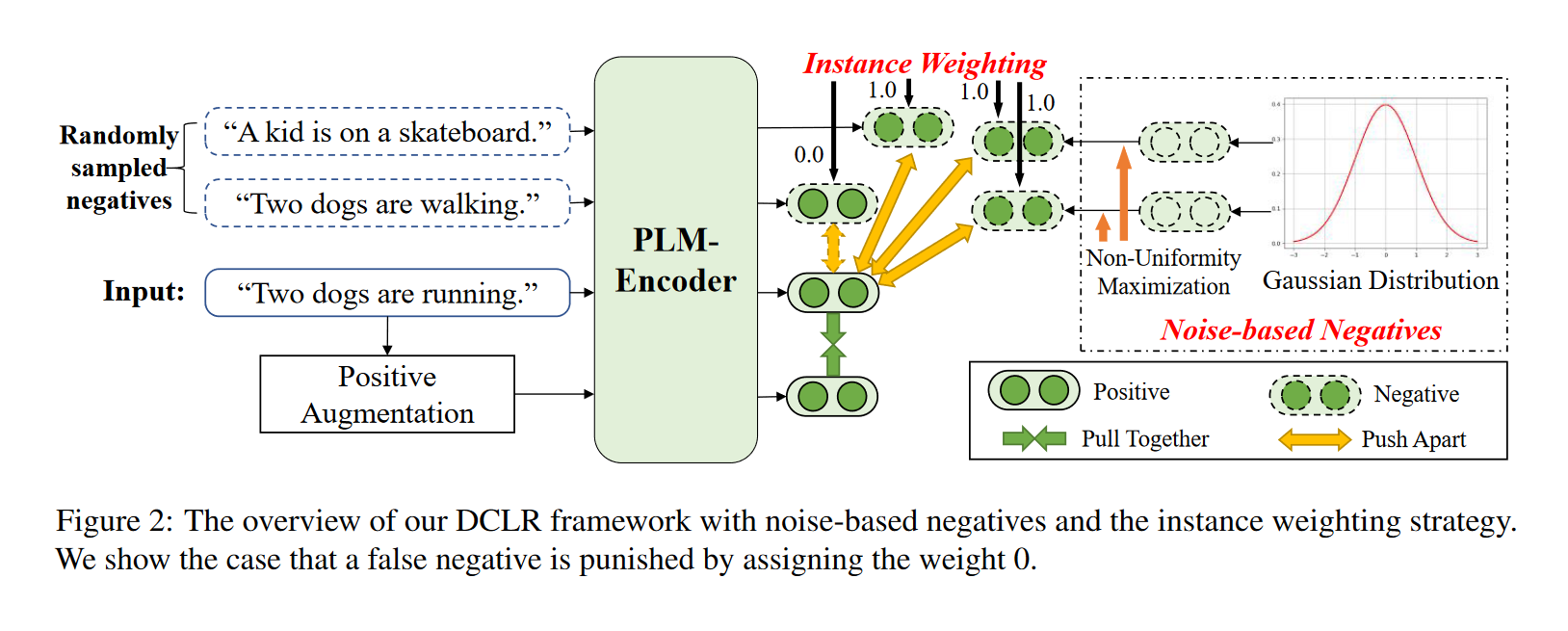
DCLR(a general framework towards Debiased Contrastive Learning of unsupervised sentence Representations), 一種無監督句子表示的去偏向對比學習的一般框架。
核心思想是改進隨機負抽樣策略, 以緩解抽樣偏差問題:
- 設計了一種加權方法來懲罰訓練過程中取樣的假負例。用一個輔助模型(complementary model)來評估每個負例與原句之間的相似性,為相似性得分較高的負例分配較低的權重。
- 用基於隨機高斯噪聲隨機初始化新負例來模擬整個語意空間內的取樣,並設計了一種基於梯度的演演算法,將這些負例優化到最不均勻的點。
步驟:
-
從高斯分佈初始化基於噪聲負例,並利用基於梯度的演演算法, 通過考慮表示空間的均勻性來更新這些負例。
-
用輔助模型對這些基於噪聲的負例和在batch中隨機抽樣的負例進行加權, 懲罰其中的假負例.
-
通過SimCSE中dropout的方式來獲得正例, 並將其與上述加權負例相結合進行對比學習.
基於高斯噪聲的負例的構建與優化:
- 構建: 對於每個輸入句子\(x_i\),我們首先初始化\(k\)個來自高斯分佈的噪聲向量作為負例:
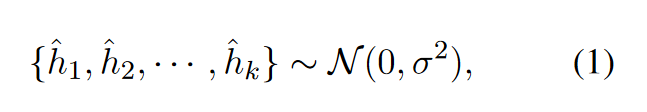
- 非均勻性損失(non-uniformity loss)來優化這些負例向量:
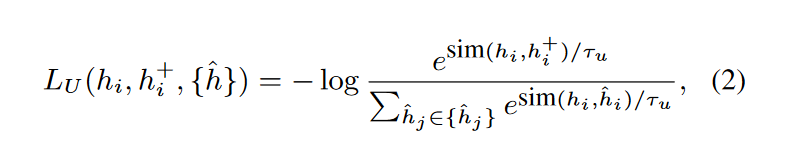
梯度下降:
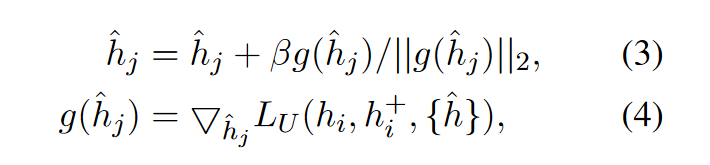
這樣,基於噪聲的負例將朝著句子表示空間的非均勻點進行優化. 通過學習對比這些負例, 可以進一步提高表徵空間的均勻性, 這對於得到更有效的句子表示至關重要.
輔助模型(complementary model):
使用SOTA模型SimCSE作為輔助模型, 用於判斷句子間的語意相似度. 具體的:
對於一個句子\(s_i\), 定義它的向量表示為\(h_i\), 從batch中隨機抽取的負例為\(\set{\tilde{h}}\), 基於噪聲構造的的負例為\(\set{\hat{h}}\), 對於來自\(\set{\tilde{h}}\)和\(\set{\hat{h}}\)的負例\(h^-\), 其權重為:
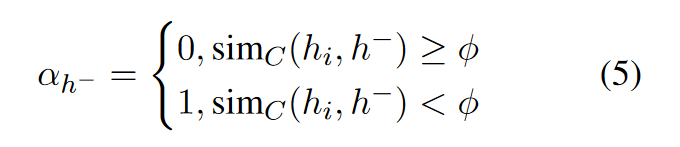
其中\(\phi\)是超引數, \(\text{sim}_C(h_i, h^-)\)表示SimCSE的相似度打分. 相當於直接捨棄了閾值小於\(\phi\)的負例.
對比學習的損失
最後, 對比學習的損失函數如下:
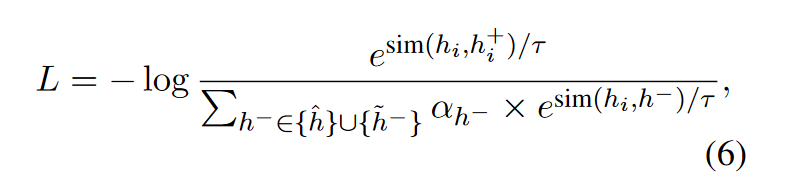
3. 效能(Performance)
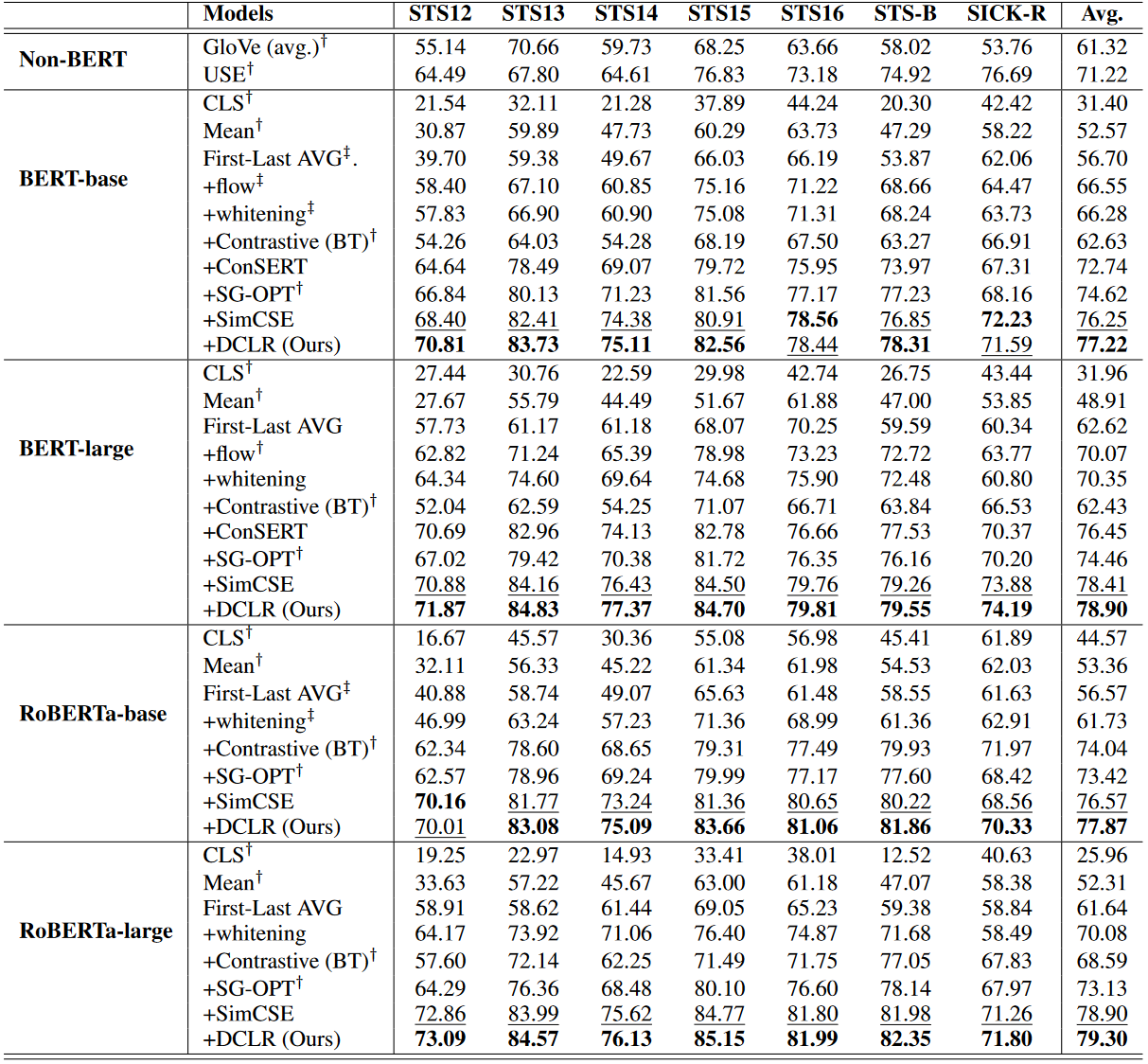
4. 分析(Analysis)
4.1 超引數分析(Hyper-parameters Analysis)
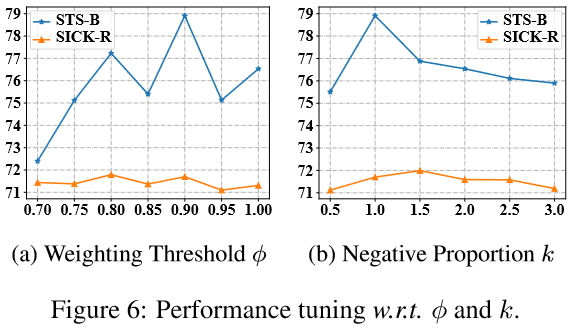
\(k\)表示基於噪聲的負例數量與批次大小的比值.
4.2 均勻性分析(Uniformity Analysis)
用一下損失來評估句子表示的均勻性:
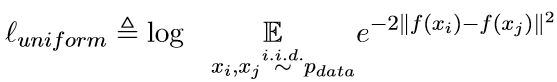
該損失值越小說明分佈越均勻.
含義: 希望來自資料分佈的句子之間歐氏距離的期望儘可能大.
與SimCSE的對比:
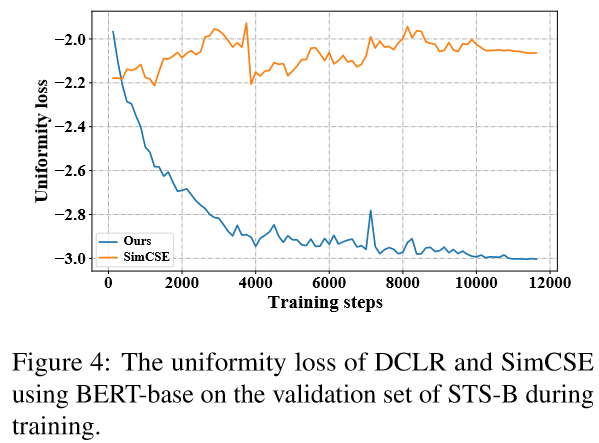
因為DCLR在表示空間之外對基於噪聲的負例進行了取樣, 這樣可以更好地提高句子表示的均勻性.
有個問題, 文章沒有對對齊性(Alignment)進行分析.
4.3 消融實驗(Ablation Study)
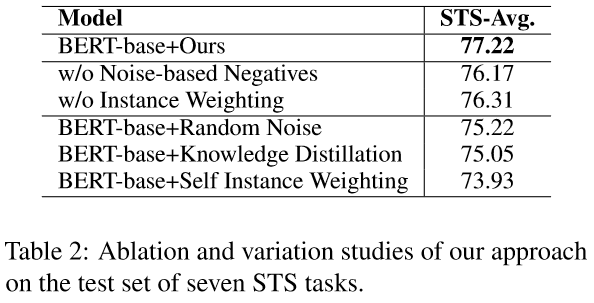
隨機噪聲(Random Noise): 直接生成基於噪聲的負例, 不進行基於梯度的優化.
知識蒸餾(Knowledge Distillation): 利用SimCSE作為教師模型,在訓練時將知識蒸餾到學生模型中.
自加權(Self Instance Weighting): 採用模型本身作為輔助模型來生成權重.
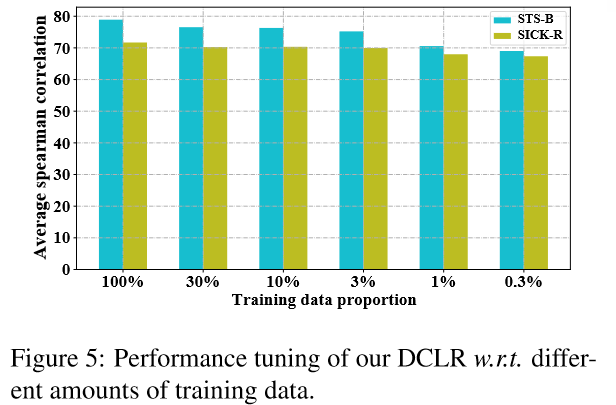
4.4 少樣本下的效能(Performance under Few-shot Settings)
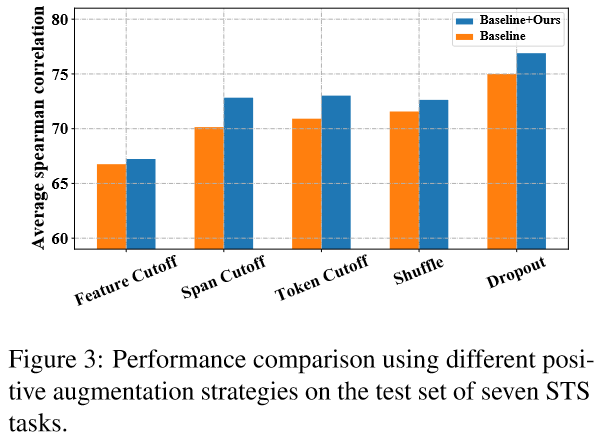
4.5 採用其他正例生成策略(Debiased Contrastive Learning on Other Methods)
DCLR主要關注的是對比學習中的負例取樣策略, 因此在構建正例時, 有多種資料增強策略可選. 文中測試了3種:
- 亂序(Token Shuffing): 隨機打亂輸入序列中token的順序
- 刪詞(Feature/Token/Span Cutoff): 隨機去掉輸入中的features/tokens/token spans.
- Dropout: 即SimCSE中正例的生成方式.