王樹森Transformer學習筆記
Transformer
Transformer是完全由Attention和Self-Attention結構搭建的深度神經網路結構。
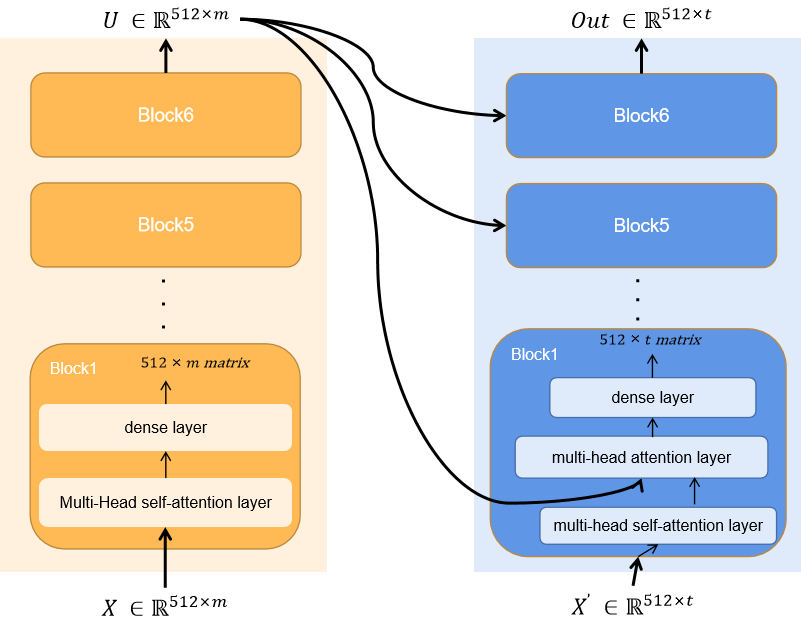
其中最為重要的就是Attention和Self-Attention結構。
Attention結構
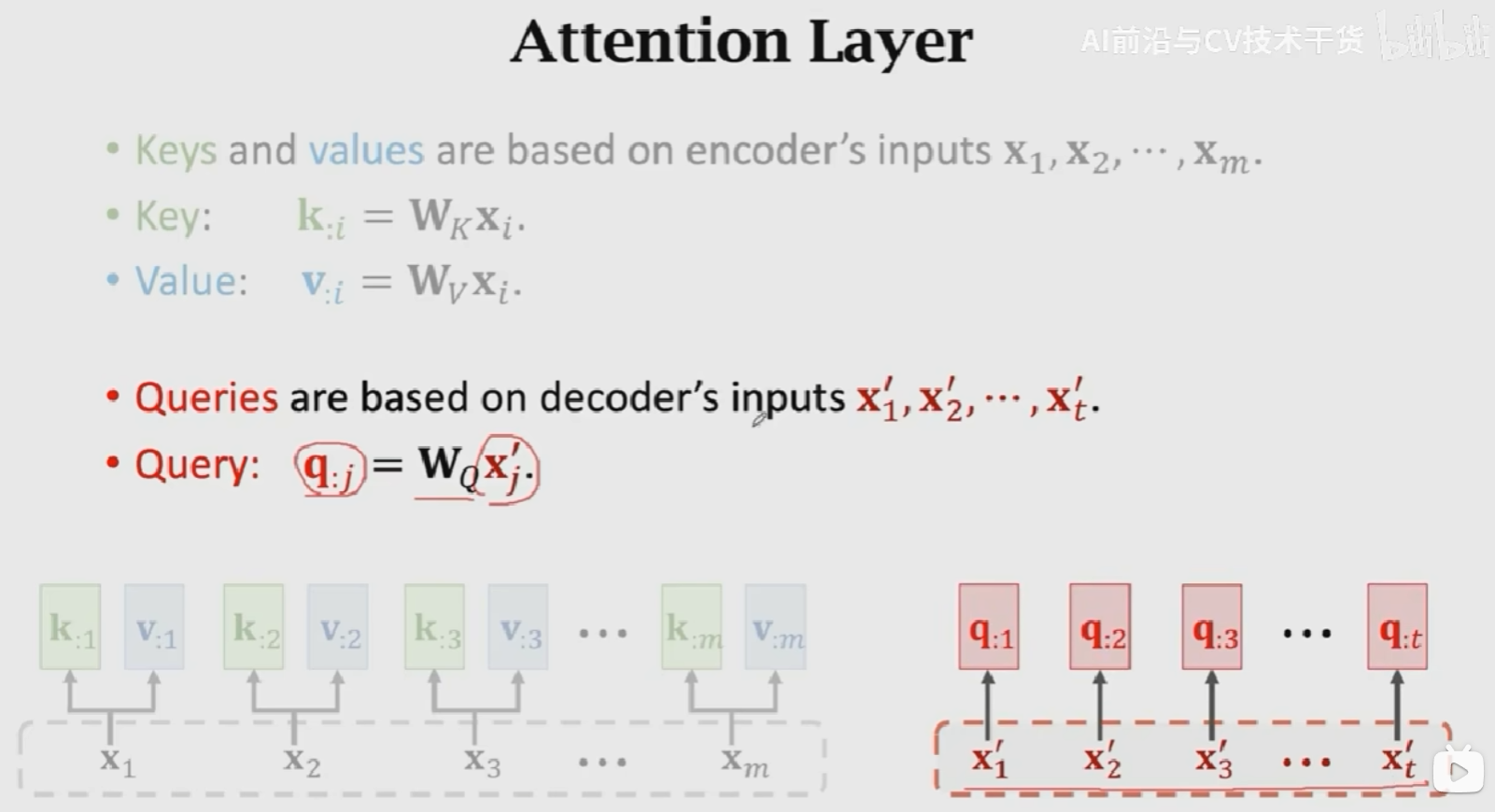
Attention Layer接收兩個輸入\(X = [x_1, x_2, x_3, ..., x_m]\),Decoder的輸入為 \(X' = [x_1^{'}, x_2^{'}, x_3^{'}, ...,x_t^{'}]\),得到一個輸出\(C = [c_1, c_2, c_3, ..., c_t]\),包含三個引數:\(W_Q, W_K, W_V\)。

具體的計算流程為:
- 首先,使用Encoder的輸入來計算Key和Value向量,得到m個k向量和v向量:\(k_{:i} = W_Kx_{:i}, v_{:i} = W_vx_{:i}\)
- 然後,對Decoder的輸入做線性變換,得到t個q向量:\(q_{:j} = W_Qx_{:j}^{'}\)
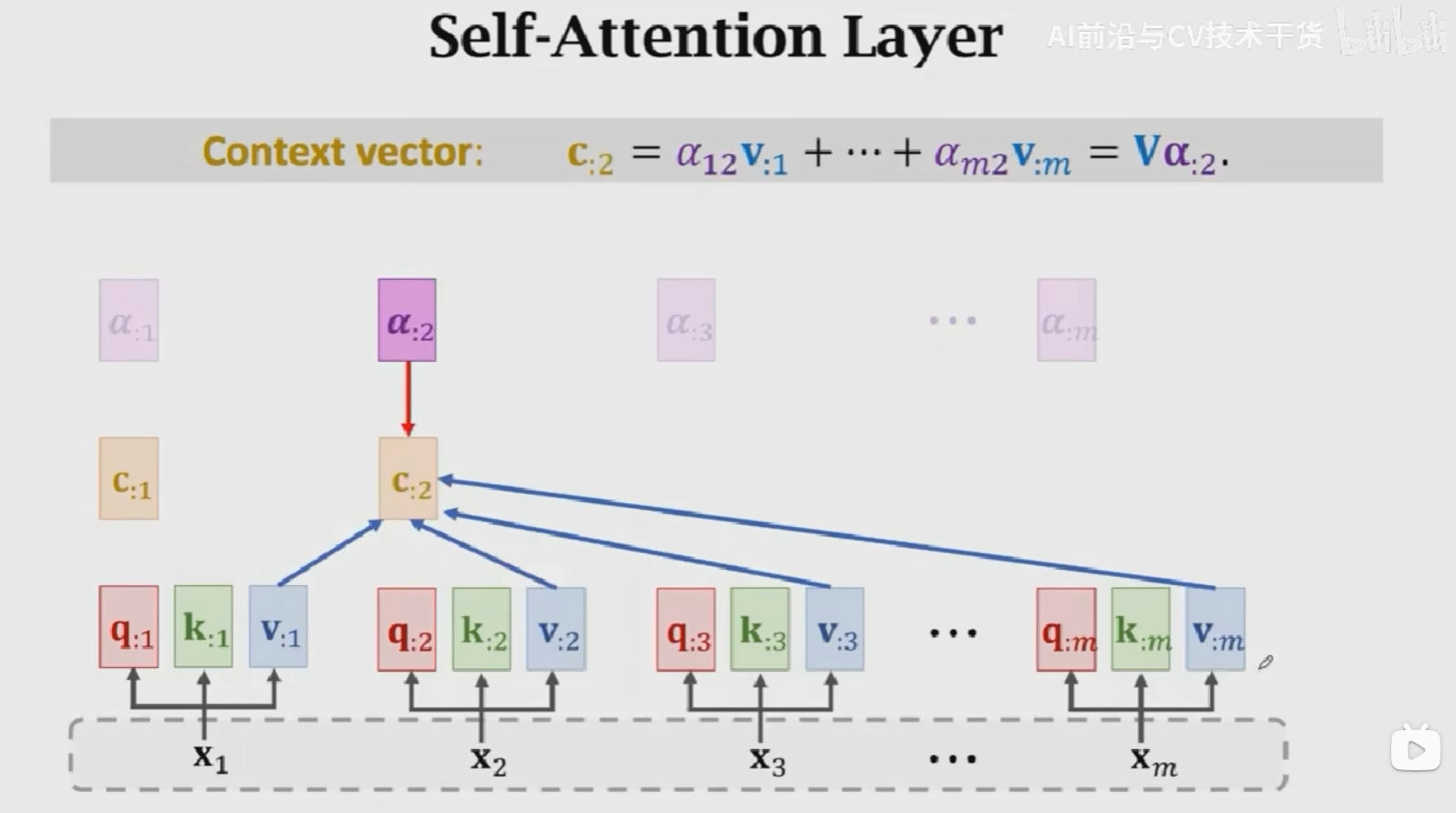
- 計算權重:\(\alpha_{:1} = Softmax(K^Tq_{:1})\)
- 計算Context vector:\(c_{:1} = \alpha_{11}v_{:1} + \alpha_{21}v_{:2} + ...\alpha_{m1}v_{:m} = V\alpha_{:1} = VSoftmax(K^Tq_{:1})\)
- 用相同的方式計算\(c_2, c_3, ..., c_t\),得到\(C = [c_1, c_2, ..., c_t]\)
Key:表示待匹配的值,Query表示查詢值,這m個\(\alpha_{:j}\)就說明是query(\(q_j\))和所有key(\([k_{:1}, k_{:2}, ..., k_{:m}]\))之間的匹配程度。匹配程度越高,權重越大。V是對輸入的一個線性變化,使用權重對其進行加權平均得到相關矩陣\(C\)。在Attention+RNN的結構中,是對輸入狀態進行加權平均,這裡\(V\)相當於對\([h_1, h_2, ..., h_m]\)進行線性變換。

Self-Attention結構
Attention結構接收兩個輸入得到一個輸出,Self-Attention結構接收一個輸入得到一個輸出,如下圖所示。中間的計算過程與Attention完全一致。
Multi-head Self-Attention
上述的Self-Attention結構被稱為單頭Self-Attention(Single-Head Self-Attention)結構,Multi-Head Self-Attention就是將多個Single-Head Self-Attention的結構進行堆疊,結果Concatenate到一塊兒。
假如有\(l\)個Single-Head Self-Attention組成一個Multi-Head Self-Attention,Single-Head Self-Attention的輸入為\(X = [x_{:1}, x_{:2}, x_{:3}, ..., x_{:m}]\),輸出為\(C = [c_{:1}, c_{:2}, c_{:3}, ..., c_{:m}]\)維度為\(dm\),
則,Multi-Head Self-Attention的輸出維度為\((ld)*m\),引數量為\(l\)個\(W_Q, W_K, W_V\)即\(3l\)個引數矩陣。
Multi-Head Attention操作一致,就是進行多次相同的操作,將結果Concatenate到一塊兒。
BERT:Bidirectional Encoder Representations from Transformers
BERT的提出是為了預訓練Transformer的Encoder網路【BERT[4] is for pre-training Transformer's[3] encoder.】,通過兩個任務(1)預測被遮擋的單詞(2)預測下一個句子,這兩個任務不需要人工標註資料,從而達到使用海量資料訓練超級大模型的目的。
BERT有兩種任務:
- Task 1: Predict the masked word,預測被遮擋的單詞
輸入:the [MASK] sat on the mat
groundTruth:cat
損失函數:交叉熵損失

- Task 2: Predict the next sentence,預測下一個句子,判斷兩句話在文中是否真實相鄰
輸入:[CLS, first sentence, SEP, second sentence]
輸出:true or false
損失函數:交叉熵損失
這樣做二分類可以讓Encoder學習並強化句子之間的相關性。
好處:
- BERT does not need manually labeled data. (Nice, Manual labeling is expensive.)
- Use large-scale data, e.g., English Wikipedia (2.5 billion words)
- task 1: Randomly mask works(with some tricks)
- task 2: 50% of the next sentences are real. (the other 50% are fake.)
- BERT將上述兩個任務結合起來預訓練Transformer模型
- 想法簡單且非常有效
消耗極大【普通人玩不起,但是BERT訓練出來的模型引數是公開的,可以拿來使用】:
- BERT Base
- 110M parameters
- 16 TPUs, 4 days of training
- BERT Large
- 235M parameters
- 64 TPUs, 4days of training
Summary
Transformer:
- Transformer is a Seq2Seq model, it has an encoder and a decoder
- Transformer model is not RNN
- Transfomer is purely based on attention and dense layers(全連線層)
- Transformer outperforms all the state-of-the-art RNN models
Attention的發展:
- Attention was originally developed for Seq2Seq RNN models[1].
- Self-Attention: attention for all the RNN models(not necessarily for Seq2Seq models)[2].
- Attention can be used without RNN[3].
Reference
王樹森的Transformer模型
[1] Bahdanau, Cho, & Bengio, Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
[2] Cheng, Dong, & Lapata. Long Short-Term Memory-Networks for Machine Reading. In EMNLP, 2016.
[3] Vaswani et al. Attention Is All You Need. In NIPS, 2017.
[4] Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In ACL, 2019.
