Unity JobSystem使用及技巧
什麼是JobSystem
並行程式設計
在遊戲開發過程中我們經常會遇到要處理大量資料計算的需求,因此為了充分發揮硬體的多核效能,我們會需要用到並行程式設計,多執行緒程式設計也是並行程式設計的一種。
執行緒是在程序內的,是共用程序記憶體的執行流,執行緒上下文切換的開銷是相當高的,大概有2000的CPU Circle,同時會導致快取失效,導致萬級別的CPU Circle,Job System的設計使用了執行緒池,一開始先將大量的計算任務分配下去儘量減少執行緒的執行流被打斷,也降低了一些thread的切換開銷。
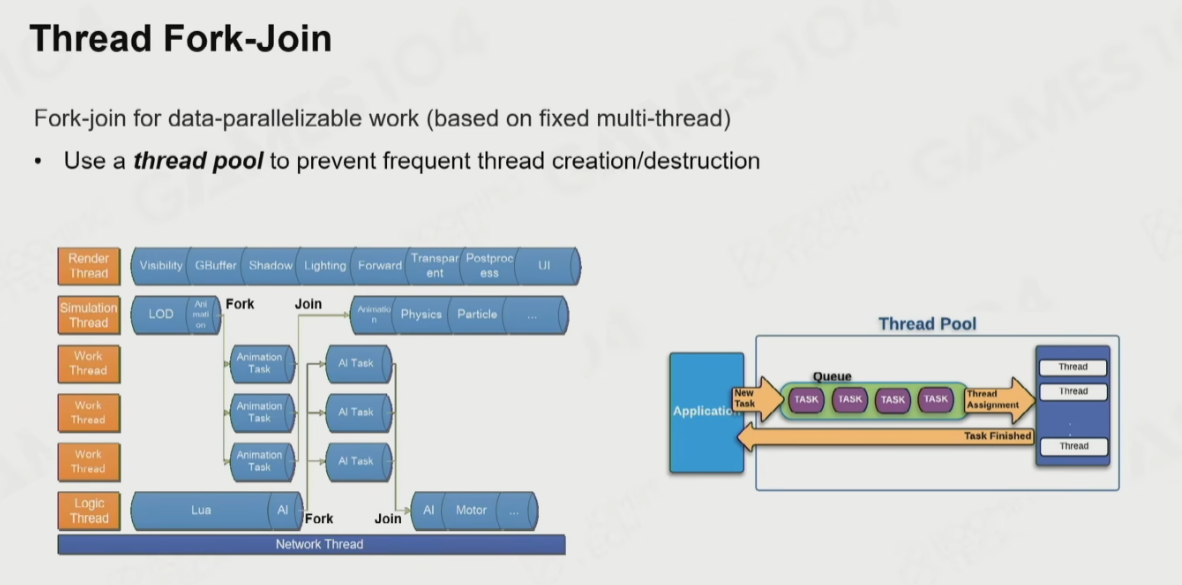
Unreal Unity大部分都是這種模型,分配了一些work thread 然後其他的執行緒往這個執行緒塞Task,相比fixed thread模式效能好一些,多出了Task的概念,Unity裡稱這個為Job。
建議看看Games104並行架構部分
Unity JobSystem
通常Unity在一個執行緒上執行程式碼,該執行緒預設在程式開始時執行,稱為主執行緒。我們在主執行緒使用JobSystem的API,去給worker執行緒下發任務,就是使用多執行緒。
通常Unity JobSystem會和Burst編譯器一起使用,Burst會把IL變成使用LLVM優化的CPU程式碼,執行效率可以說大幅提升,但是使用Burst時候debug會變得困難,會缺少一些報錯的堆疊,此時關閉burst可以看到一些堆疊,更方便debug。
雖然並行程式設計有著種種的技巧,比如,執行緒之間溝通交流資料有需要加鎖、原子操作等等的資料交換等操作。但是Unity為了讓我們更容易的編寫多執行緒程式碼,
通過一些規則的制定,規避了一些複雜行為,同時也限制了一些功能,必要時這些功能也可以通過新增attribute、或者使用指標的方式來打破一些規則。
規定包括但不限於:
- 不允許存取靜態變數
- 不允許在Job裡排程子Job
- 只能向Job裡傳遞值型別,並且是通過拷貝的方式從主執行緒將資料傳輸進Job,當Job執行結束資料會拷貝回主執行緒,我們可以在主執行緒的job物件存取Job的執行結果。
- 不允許在Native容器裡新增託管型別
- 不允許使用指標
- 不允許多個Job同時寫入同一個地方
- 不允許在Job裡分配額外記憶體
可以檢視 官方檔案。
應用場景
基本上所有需要處理資料計算的場景都可以使用,我們可以用它做大量的遊戲邏輯的計算,
我們也可以用它來做一些編輯器下的工具,可以達到加速的效果。
細節
介面
unity官方提供了一系列的介面,寫一個Struct實現介面便可以執行多執行緒程式碼,提供的介面包括:
- IJob:一個執行緒
- IJobParallelFor:多執行緒,使用時傳入一個陣列,根據陣列長度會劃分出任務數量,每個任務的索引就是陣列元素的索引
- IJobParallelForTransform:並行存取Transform元件的,這是unity自己實現的比較特殊的讀寫Transform資訊的Job,實測下來用起來貌似worker還是一個在動,但是經過Burst編譯後快不少。
- IJobFor:幾乎沒用
IJobParallelFor是最常用的,對資料來源中的每一項都呼叫一次 Execute 方法。Execute 方法中有一個整數引數。該索參照於存取和操作作業實現中的資料來源的單個元素。
容器
Job使用的資料都需要使用Unity提供的Native容器,我們在主執行緒將要計算的資料裝進NativeContainer裡然後再傳進Job。
主要會使用的容器就是NativeArray,其實就是一個原生的陣列型別,其他的容器這裡暫時不提
這些容器還要指定分配器,分配器包括
Allocator.Temp: 最快的設定。將其用於生命週期為一幀或更少的分配。從主執行緒傳資料給Job時,不能使用Temp分配器。Allocator.TempJob: 分配比 慢Temp但比 快Persistent。在四幀的生命週期內使用它進行執行緒安全分配。Allocator.Persistent: 最慢的分配,但只要你需要它就可以持續,如果有必要,可以貫穿應用程式的整個生命週期。它是直接呼叫malloc. 較長的作業可以使用此 NativeContainer 分配型別。
容器在實現Job的Struct裡可以打標記,包括ReadOnly、WriteOnly,一方面可以提升效能,另一方面有時候會有讀寫衝突的情況,此時應該儘量多標記ReadOnly,避免一些資料衝突。
建立 使用
官方檔案已經說的很好。
https://docs.unity3d.com/Manual/JobSystemCreatingJobs.html
對於ParallelFor的Schedule多了一些引數,innerloopBatchCount這個引數可以留意一下,可以理解為一個執行緒次性拿走多少任務。
Job之間互相依賴
https://docs.unity3d.com/Manual/JobSystemJobDependencies.html
其實執行了一個Job之後,在主線再執行另一個Job也不會效能差很多,並且易於debug,可以斷點檢視多個階段執行過程中Job的資料情況,但是追求完美還是可以把依賴填上。
效能測試比較
筆者曾經做過簡單的使用Job和不用Job的對比,通過打上Unity Profiler的標記,可以方便的在圖表裡檢視執行開銷。
Profiler.BeginSample("Your Target Profiler Name");
// your code
Profiler.EndSample();
IJob
using System.Collections;
using System.Collections.Generic;
using Unity.Collections;
using Unity.Jobs;
using UnityEngine;
using Unity.Burst;
[BurstCompile]
public class JobTest : MonoBehaviour
{
public bool useJob;
// Update is called once per frame
void Update()
{
float startTime = Time.realtimeSinceStartup;
if (useJob)
{
NativeArray<int> result = new NativeArray<int>(1, Allocator.TempJob);//four frame allocate
MyJobSystem0 job0 = new MyJobSystem0();
job0.a = 0;
job0.b = 1;
job0.result = result;
JobHandle handle = job0.Schedule();
handle.Complete();
result.Dispose();
Debug.Log(("Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
else
{
var index = 0;
for(int i = 0; i < 1000000; i++)
{
index++;
}
Debug.Log(("Not Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
}
}
[BurstCompile]
public struct MyJobSystem0 : IJob
{
public int a;
public int b;
public NativeArray<int> result;
public void Execute()
{
var index = 0;
for(int i = 0; i < 1000000; i++)
{
index++;
}
result[0] = a + b;
}
}
使用IJob執行一項複雜的工作,沒有使用job跑了2-4ms,使用job也是跑了2-4 ms,但是使用了job+burst,這個for迴圈的速度就變得只有0.2-0.8 ms了,burst對此優化挺大的。
IJobParallelFor
using System;
using System.Collections;
using System.Collections.Generic;
using Unity.Collections;
using Unity.Jobs;
using UnityEngine;
public class JobForTest : MonoBehaviour
{
public bool useJob;
public int dataCount;
private NativeArray<float> a;
private NativeArray<float> b;
private NativeArray<float> result;
private List<float> noJobA;
private List<float> noJobB;
private List<float> noJobResult;
// Update is called once per frame
private void Start()
{
a = new NativeArray<float>(dataCount, Allocator.Persistent);
b = new NativeArray<float>(dataCount, Allocator.Persistent);
result = new NativeArray<float>(dataCount, Allocator.Persistent);
noJobA = new List<float>();
noJobB = new List<float>();
noJobResult = new List<float>();
for (int i = 0; i < dataCount; ++i)
{
a[i] = 1.0f;
b[i] = 2.0f;
noJobA.Add(1.0f);
noJobB.Add(2.0f);
noJobResult.Add(0.0f);
}
}
void Update()
{
float startTime = Time.realtimeSinceStartup;
if (useJob)
{
MyParallelJob jobData = new MyParallelJob();
jobData.a = a;
jobData.b = b;
jobData.result = result;
// 排程作業,為結果陣列中的每個索引執行一個 Execute 方法,且每個處理批次只處理一項
JobHandle handle = jobData.Schedule(result.Length, 1);
// 等待作業完成
handle.Complete();
Debug.Log(("Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
else
{
for(int i = 0; i < dataCount; i++)
{
noJobA[i] = 1;
noJobB[i] = 2;
noJobResult[i] = noJobA[i]+noJobB[i];
}
Debug.Log(("Not Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
}
private void OnDestroy()
{
// 釋放陣列分配的記憶體
a.Dispose();
b.Dispose();
result.Dispose();
}
}
// 將兩個浮點值相加的作業
public struct MyParallelJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<float> a;
[ReadOnly]
public NativeArray<float> b;
public NativeArray<float> result;
public void Execute(int i)
{
result[i] = a[i] + b[i];
}
}
普通for尋找兩個list,遍歷list元素然後相加,資料量10萬,每一個批次這裡是處理1個execute, 不開job 2.48ms,開job 1.34ms,job開了burst就0.28ms。
IJobParalForTransform
using Unity.Burst;
using Unity.Collections;
using Unity.Jobs;
using Unity.Mathematics;
using UnityEngine;
using UnityEngine.Jobs;
public class TransformJobs : MonoBehaviour
{
public bool useJob;
public int dataCount = 100;
//public int batchCount;
// 用於儲存transform的NativeArray
private TransformAccessArray m_TransformsAccessArray;
private NativeArray<Vector3> m_Velocities;
private PositionUpdateJob m_Job;
private JobHandle m_PositionJobHandle;
private GameObject[] sphereGameObjects;
//[BurstCompile]
struct PositionUpdateJob : IJobParallelForTransform
{
// 給每個物體設定一個速度
[ReadOnly]
public NativeArray<Vector3> velocity;
public float deltaTime;
// 實現IJobParallelForTransform的結構體中Execute方法第二個引數可以獲取到Transform
public void Execute(int i, TransformAccess transform)
{
transform.position += velocity[i] * deltaTime;
}
}
void Start()
{
m_Velocities = new NativeArray<Vector3>(dataCount, Allocator.Persistent);
// 用程式碼生成一個球體,作為複製的模板
var sphere = GameObject.CreatePrimitive(PrimitiveType.Sphere);
// 關閉陰影
var renderer = sphere.GetComponent<MeshRenderer>();
renderer.shadowCastingMode = UnityEngine.Rendering.ShadowCastingMode.Off;
renderer.receiveShadows = false;
// 關閉碰撞體
var collider = sphere.GetComponent<Collider>();
collider.enabled = false;
// 儲存transform的陣列,用於生成transform的Native Array
var transforms = new Transform[dataCount];
sphereGameObjects = new GameObject[dataCount];
int row = (int)Mathf.Sqrt(dataCount);
// 生成1W個球
for (int i = 0; i < row; i++)
{
for (int j = 0; j < row; j++)
{
var go = GameObject.Instantiate(sphere);
go.transform.position = new Vector3(j, 0, i);
sphereGameObjects[i * row + j] = go;
transforms[i*row+j] = go.transform;
m_Velocities[i*row+j] = new Vector3(0.1f * j, 0, 0.1f * j);
}
}
m_TransformsAccessArray = new TransformAccessArray(transforms);
}
void Update()
{
//float startTime = Time.realtimeSinceStartup;
if (useJob)
{
// 範例化一個job,傳入資料
m_Job = new PositionUpdateJob()
{
deltaTime = Time.deltaTime,
velocity = m_Velocities,
};
// 排程job執行
m_PositionJobHandle = m_Job.Schedule(m_TransformsAccessArray);
//Debug.Log(("Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
else
{
for (int i = 0; i < dataCount; ++i)
{
sphereGameObjects[i].transform.position += m_Velocities[i] * Time.deltaTime;
}
//Debug.Log(("Not Use Job:"+ (Time.realtimeSinceStartup - startTime) * 1000f) + "ms");
}
}
// 保證當前幀內Job執行完畢
private void LateUpdate()
{
m_PositionJobHandle.Complete();
}
// OnDestroy中釋放NativeArray的記憶體
private void OnDestroy()
{
m_Velocities.Dispose();
m_TransformsAccessArray.Dispose();
}
}
100+vec3,不用job 0.02ms,用job +burst 0.02ms
1600+vec3,不用job 0.31ms,用job 0.07ms +burst 0.04ms
1萬+vec3,不用job 2.23ms,用job 0.35ms + burst 0.12ms
1萬+float3,不用job 2.55ms,用job 0.4ms
100萬+float3,不用job 199ms ,用job 40ms + burst 31ms
100萬+vec3,不用job 189ms ,用job 35ms + burst 31ms
高階技巧
使用特定的數學庫中的實現
unity特定的數學庫中的資料型別可以獲取simd優化,比如vector3就可以換成float3,但是缺少的數學庫,就要自己解決了,所以我一般就vector3。
在合適的時機Schedule和Complete
擁有作業所需的資料後就立即在作業上呼叫 Schedule,並僅在需要結果時才開始在作業上呼叫 Complete。最好是排程當前不與正在執行的任何其他作業競爭的、不需要等待的作業。例如,如果在一幀結束和下一幀開始之間的一段時間沒有作業正在執行,並且可以接受一幀延遲,則可以在一幀結束時排程作業,並在下一幀中使用其結果。另一方面,如果遊戲佔滿了與其他作業的轉換期,但在幀中的其他位置存在大量未充分利用的時段,那麼在這個時段排程作業會更加有效。
在單執行緒裡執行JobSystem
IJobParallelForExtensions可以呼叫Run方法,會將所有的Job放到一個Thread裡執行,之前我們提到了Schedule的innerloopBatchCount引數,將它調到和資料來源一樣大,也是在一個Thread裡執行,
當我們的資料量小於1000,分配執行緒可能都覺得費勁,用單執行緒的JobSystem配合Burst效果可能更好。
需要注意的是,如果我們出現了並行寫入問題(多個Thread同時寫一個位置),在單執行緒模式下是不會報錯的。
使用NativeDisableUnsafePtrRestriction
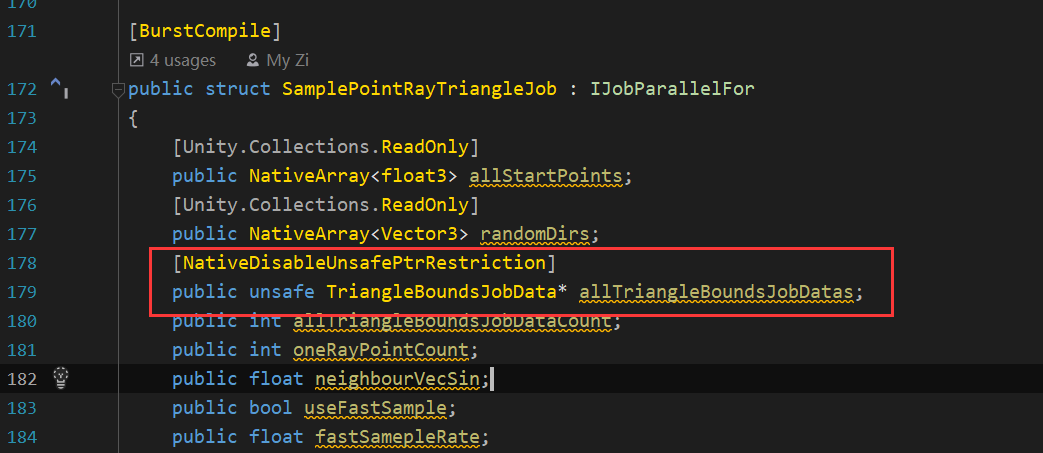
打上這個標記後可以在Job裡使用Unsafe程式碼塊,使用指標
有多個好處
- 可以不需要拷貝陣列就把主執行緒的資料塞進子執行緒,對資料量大,需要頻繁呼叫的可以考慮
- 可以包裝一些託管記憶體,比如我這裡就包裝了一個二維陣列,每個containsTriangleIndex其實是一個int的NativeArray
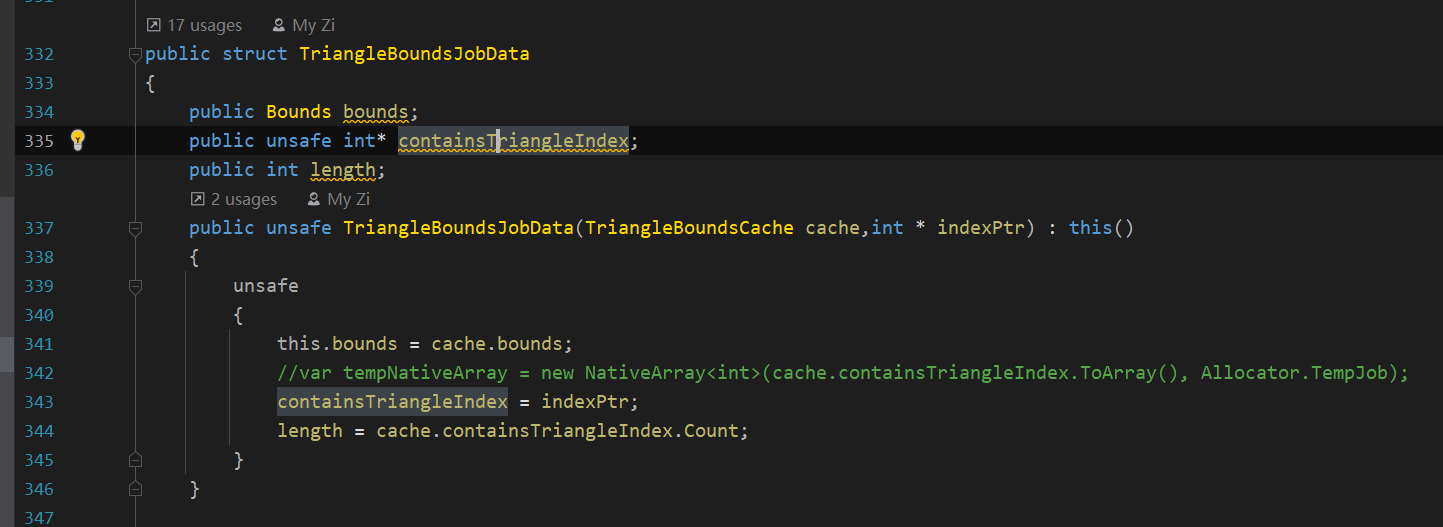
如果struct裡有NativeArray,這個struct放進NativeArray的時候會過不了安全檢查。
我這裡是在主執行緒維護好了這些動態的陣列,然後再傳進了這個結構的。
在unsafe程式碼塊裡,Native容器相關的API中有GetUnsafePtr可以獲得指標。
SamplePointRayTriangleJob samplePointRayTriangleJob = new SamplePointRayTriangleJob();
samplePointRayTriangleJob.meshTriangles = jobMeshTriangles;
samplePointRayTriangleJob.randomDirs = jobRandomDirs;
samplePointRayTriangleJob.useGrid = useGrid;
samplePointRayTriangleJob.allStartPoints = startPoints;
samplePointRayTriangleJob.allTriangleBoundsJobDatas = (TriangleBoundsJobData*)triangleBoundsJobDatas.GetUnsafePtr();
NativeDisableParallelForRestriction並行寫入

打上這個標記後,多個Thread同時陣列的同一個地方進行寫入,unity不會阻攔,但是自己也要處理好邏輯問題。
舉個例子:下面這篇文章裡
https://blog.csdn.net/n5/article/details/123742777
在Parallel Job裡面進行光柵化三角形時,多個三角形有可能並行存取depth buffer/frame buffer的相同地方。這在多執行緒程式設計中屬於race conditions,Job system內部會檢測出來,會直接報錯。
IndexOutOfRangeException: Index 219108 is out of restricted IJobParallelFor range [4392…4392] in ReadWriteBuffer.
ReadWriteBuffers are restricted to only read & write the element at the job index. You can use double buffering strategies to avoid race conditions due to reading & writing in parallel to the same elements from a job.
NativeDisableContainerSafetyRestriction
使用這個Attribute可以在子執行緒分配一塊記憶體,比如我這裡每個子執行緒是建立了一個陣列來接受光線三角形求交,一根光線擊中了多少個點,一個子任務會執行許多次光線遍歷Mesh
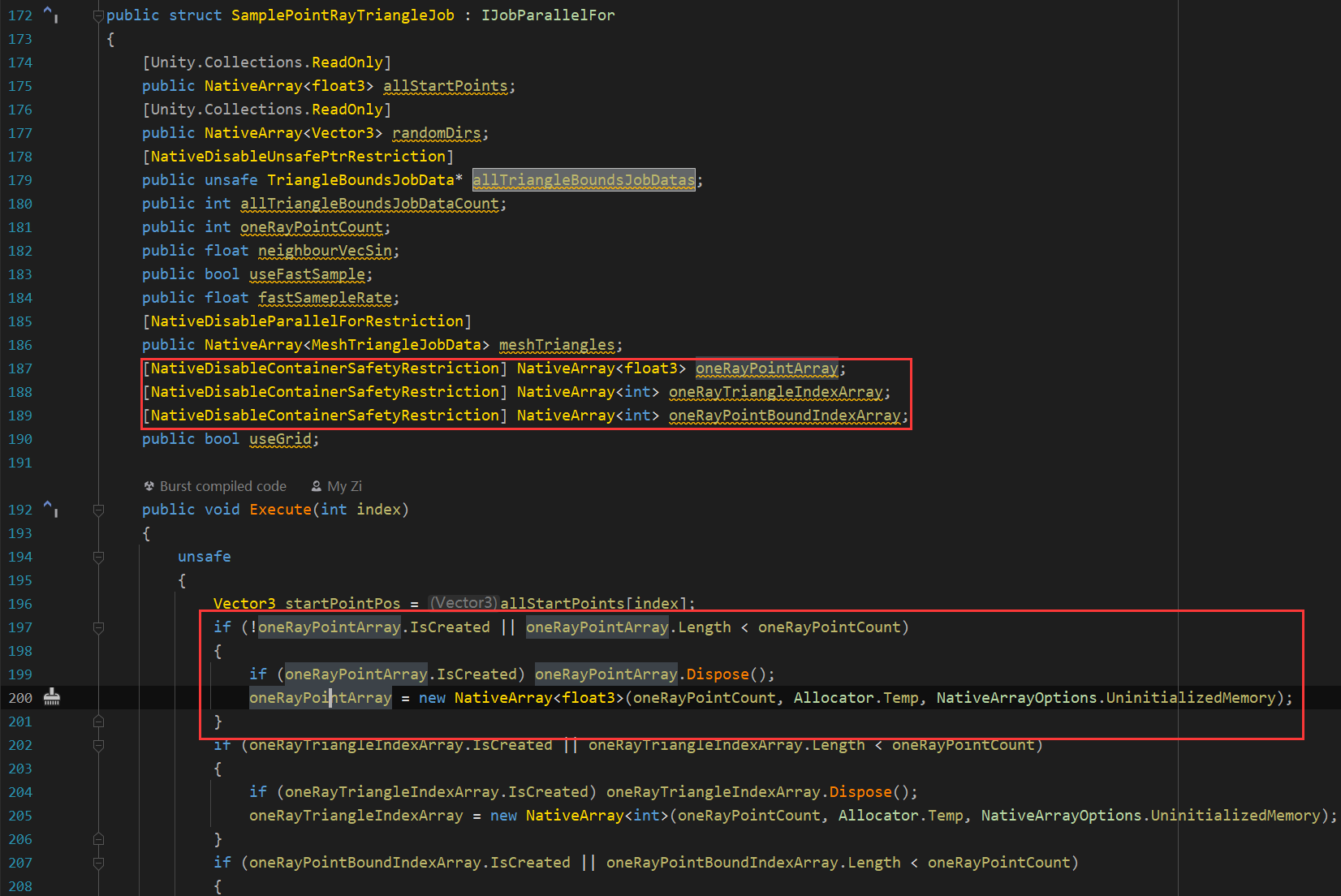
這個主要是博主在Github上學習Unity官方的MeshApiExample專案看到的案例,有點像StaticBatch
可以檢視這個連結:把整個場景的Mesh合併
DeallocateOnJobCompletion
容器在job結束之後自動釋放
這個博主用的很少 基本都是主動釋放
可能在用非並行Job的時候 接受外面的NativeArray後自己不想管釋放之類的。
可以檢視一個github上別人的案例看看:案例
自定義Native容器
https://docs.unity3d.com/Manual/job-system-custom-nativecontainer-example.html
思考
JobSystem與ComputeShader相比 優勢
JobSystem主要是利用CPU來降低計算負載,在數量級上遠遠比不上GPU,在前面的效能測試中資料到萬以上就相當吃力了。
ComputeShader是利用GPU來降低計算負載,,現在GPU Driven的技術也逐漸越來越多。
思考這兩個的取捨主要應該看業務邏輯的資料流向,如果我們的資料是從CPU發起的,那麼在把資料從CPU拷貝到GPU也是肯定是不如在CPU內做拷貝要快的,
如果我們的計算的資料最後是給CPU做下步計算的,如果用GPU做計算就會出現CPU等GPU的回讀問題,資料若停留在GPU,那麼ComputeShader自然好。
另外就是考慮兩個後端的硬體特性,CPU高主頻,處理複雜的邏輯,大量的迴圈、分支判斷上比GPU要有優勢,數量級上則GPU更有優勢。
最後也可以考慮一下易用性問題,如果用到了很多原本在CPU裡的數學庫,在JobSystem裡都是可以直接用的,ComputeShader的話則需要自己實現一版,不過腳手架這種東西屬於見仁見智,
只要自己方便就好。
2023.3.21
flyingziming