作為移動開發你不能不瞭解的編譯流程
作者:京東零售 李臣臣
閱讀本文,或許能夠了解關於以下的幾個問題: 1、編譯器是什麼?為什麼會有編譯器這樣一個東西? 2、編譯器做了哪些工作?整個編譯過程又是什麼? 3、Apple的編譯器發展歷程以及為什麼會拋棄GCC換成自研的LLVM? 4、從編譯器角度看Swift與OC能夠實現混編的底層邏輯
一、找個翻譯官,說點計算機能懂的語言
說點常識,眾所周知,作為開發者我們能看懂這樣的程式碼:
int a = 10;
int b = 20;
int c = a + b;
而對於計算機貌似只能明白這樣的內容:
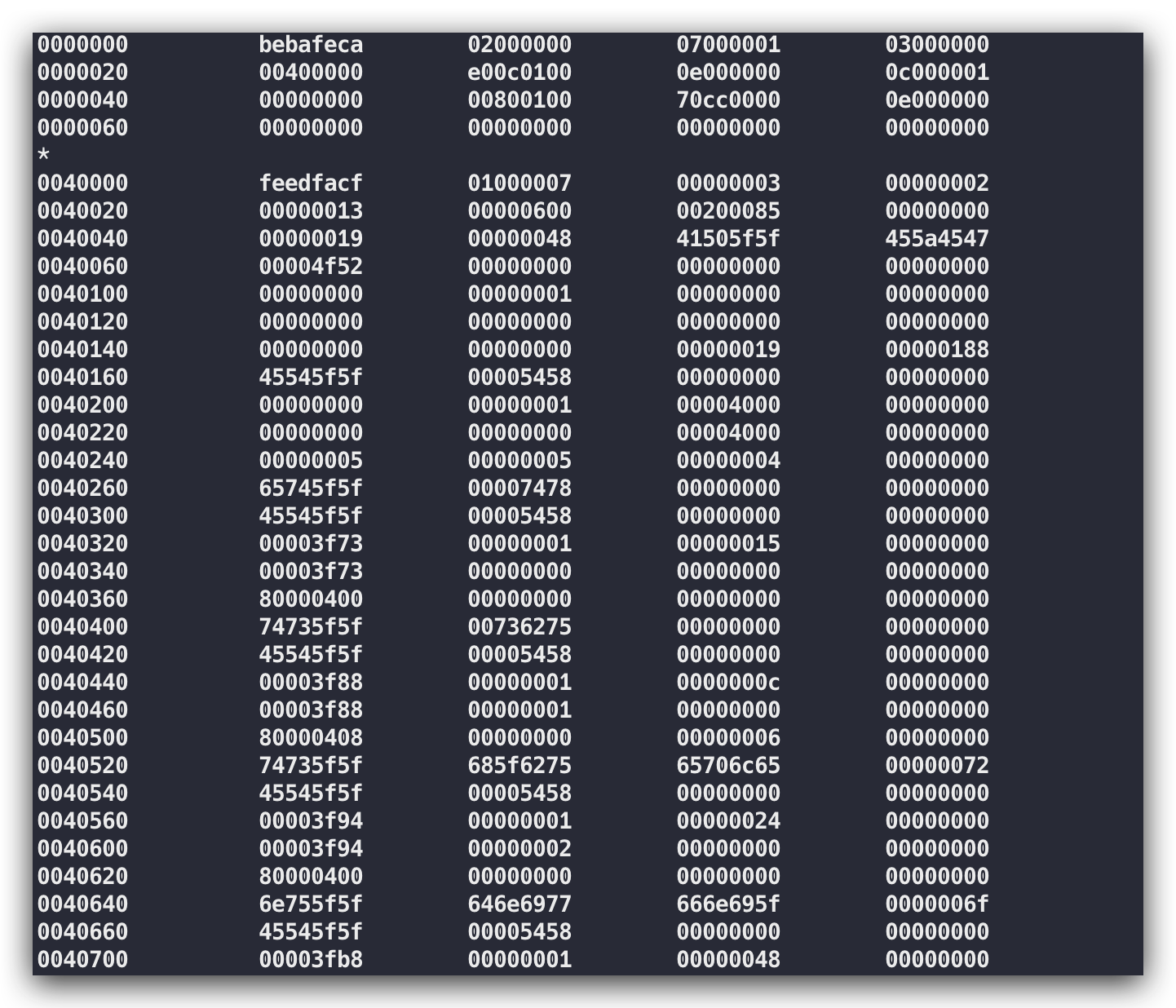
注:使用 od -tx1 /tmp/binary.bin 可以根據需要輸出二進位制、八進位制或者十六進位制的內容
這樣看的話,計算機除了知道1與0的含義,其他的字元內容完全不知道。為了去給計算機下達我們需要的指令,我們又不得不得按照計算機能夠懂得語言與其進行通訊交流,怎麼辦呢?我們貌似需要找一個翻譯,將我們的想要下達的指令內容交給翻譯讓其成計算機能夠識別的指令進行內容傳達,這樣計算機就能通過翻譯來一步步執行我們的指令動作了,那這個翻譯其實就是我們經常說到的編譯器。
說到編譯器呢?它的歷史還是很悠久的,早期的計算機軟體都是用組合語言直接編寫的,這種狀況持續了數年。當人們發現為不同型別的中央處理器CPU編寫可重用軟體的開銷要明顯高於編寫編譯器時,人們發明了高階程式語言。簡單說就是由於中央處理器CPU的差異,使得軟體的開發成本很高,我們要針對不同的CPU編寫不同的組合程式碼,而且不同的CPU架構呢相對應的組合的指令集也有差異。如果在組合體系之上定義一套與組合無關的編碼語言,通過對通用的這樣語言進行轉換,將其轉換成不同型別的CPU的組合指令,是不是就能解決不同CPU架構適配的問題呢?那其中的定義的通用編碼語言就是我們所說的高階語言,比如C/C++、Object-C、Swift、Java等等,而其中的組合翻譯轉換工作呢則交由具體的編譯器進行實現。
二、說到編譯器當然少不了Apple
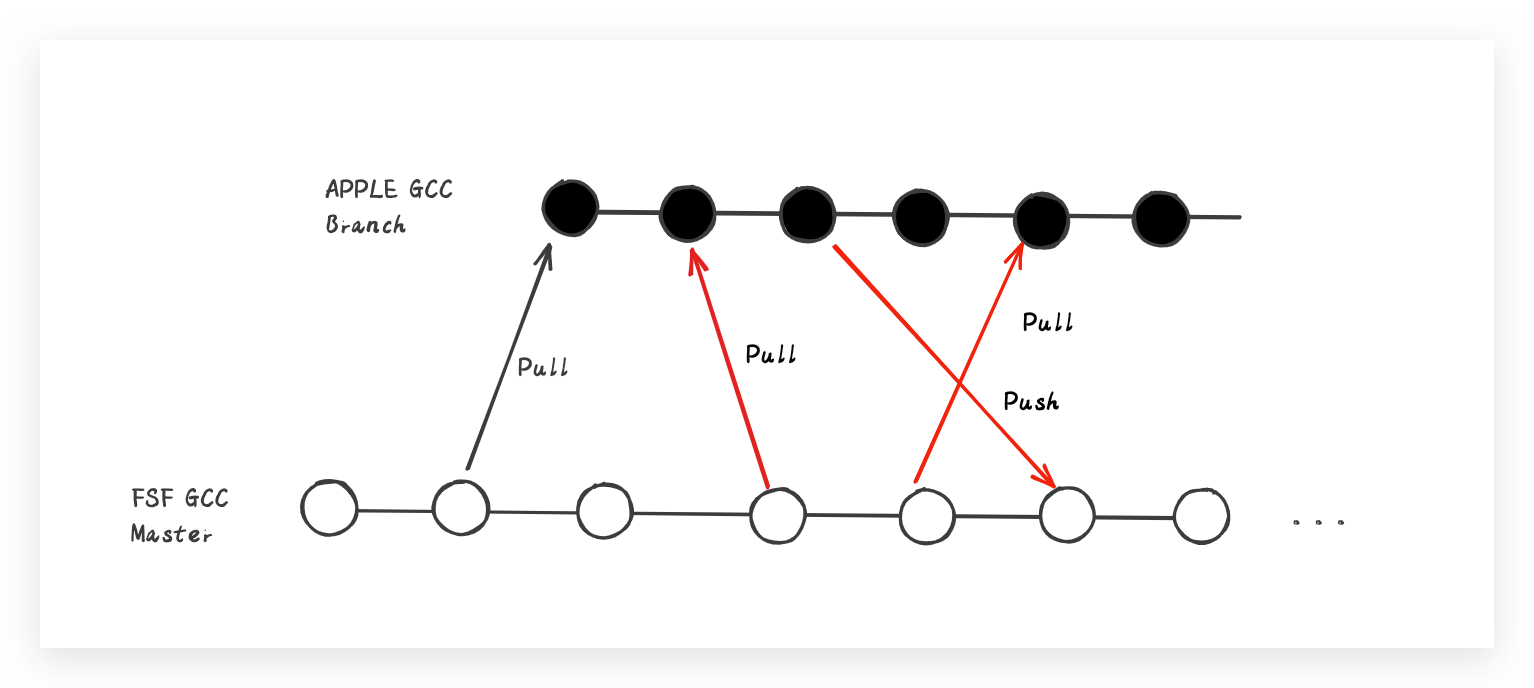
對於Apple的編譯器,就不得不說一下GCC與LLVM的相愛相殺了。由於編譯器涉及到從高階開發語言到低階語言的轉換處理,複雜度自然不必多說。我們都知道Apple產品軟體的開發語言是Objective-C,可以認為是對C語言的擴充套件。而C語言所使用的編譯器則是大名鼎鼎的GCC,此時的GCC肯定是妥妥的大哥了,所以早些年為了不必要的資源投入,對於自家OC(Objective-C簡稱OC)編譯器的開發索性直接拿大哥的程式碼GCC進行二次開發了,沒錯,從主幹版本中拉個獨立分支搞起。這麼看的話,Apple早期就已經開始了降本增效了?
隨著OC語言的不斷迭代發展,語言特性也就愈來愈多,那編譯器的新特效能力支援當然也得跟得上啊?但是C也在不斷的迭代發展,GCC編譯器的主幹功能當然也越來越多,OMG!單獨維護的OC編譯器版本對GCC主幹的新功能並沒有很好的同步,關鍵在合併功能的時候不可避免的出現種種衝突。為此,Apple曾多次申請與GCC主幹功能合併同步,GCC乍一看都是OC 特性feature,跟C有毛線關係?所以關於合併的優先順序總是排到最低,Apple也是沒有辦法,結果只能是差異化的東西越來越多,編譯器的維護成本也變得異常之高。
除了以上的問題之外,GCC整體的架構設計也是非模組化的,那什麼是模組化呢?比如我們通常在系統設計的時候,會將各個系統的功能進行模組化分割設計,不同的模組能夠單獨為系統內部提供不同的功能。同時呢,我們還能把這些模組單獨抽離出來提供給外部使用,這就增大了系統的底層的靈活度,簡單說就是能夠直接使用模組化的介面能力。
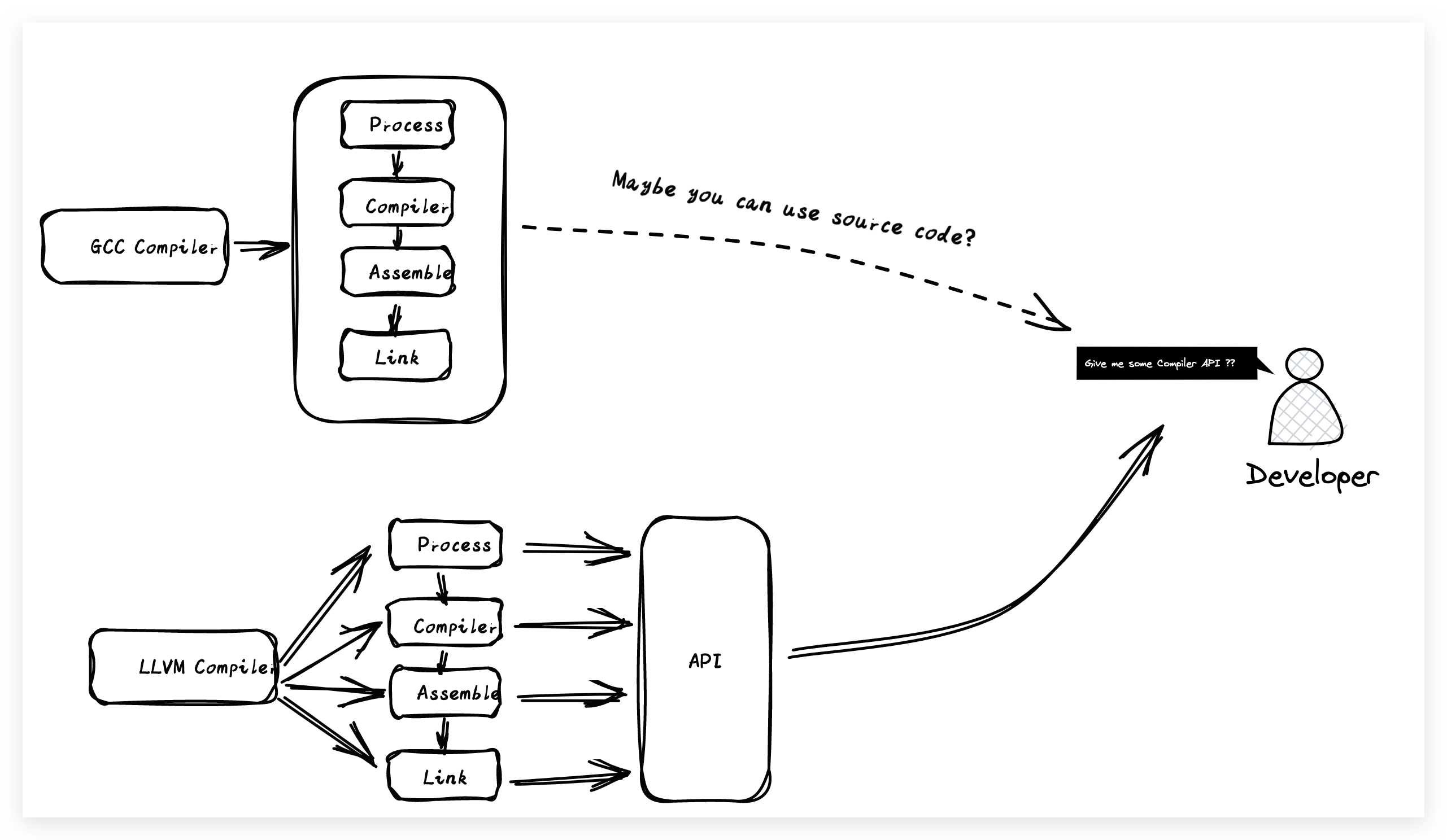
所以Apple深知客製化化的GCC編譯器將是後續語言迭代升級的絆腳石,內部也在不斷的探索能夠替代GCC的替代品。在編譯器的探索路上,這裡不得不說一下Apple的一位神級工程師 Chris Lattner(克里斯·拉特納),可能光說名字的話可能沒有太多人知道他,那如果要說Swift語言的創始人是不是就有所耳聞了?由於克里斯在大學期間對編譯器的細緻的研究,發起了LLVM(Low Level Virtual Machine)專案對編譯的原始碼進行了整體的優化。Apple將目光放在了克里斯團隊身上,同時直接顧用了他們團隊,當然克里斯也沒有辜負眾望,在 Xcode從 3.1實現了llvm-gcc compiler,到 3.2實現了Clang 1.0, 再到4.0實現了Clang 2.0 ,後來在Mac OS X 10.6 開始使用LLVM的編譯技術,到現在已經將LLVM發展成為了Apple的核心編譯器。
三、LLVM編譯器的編譯過程與特點
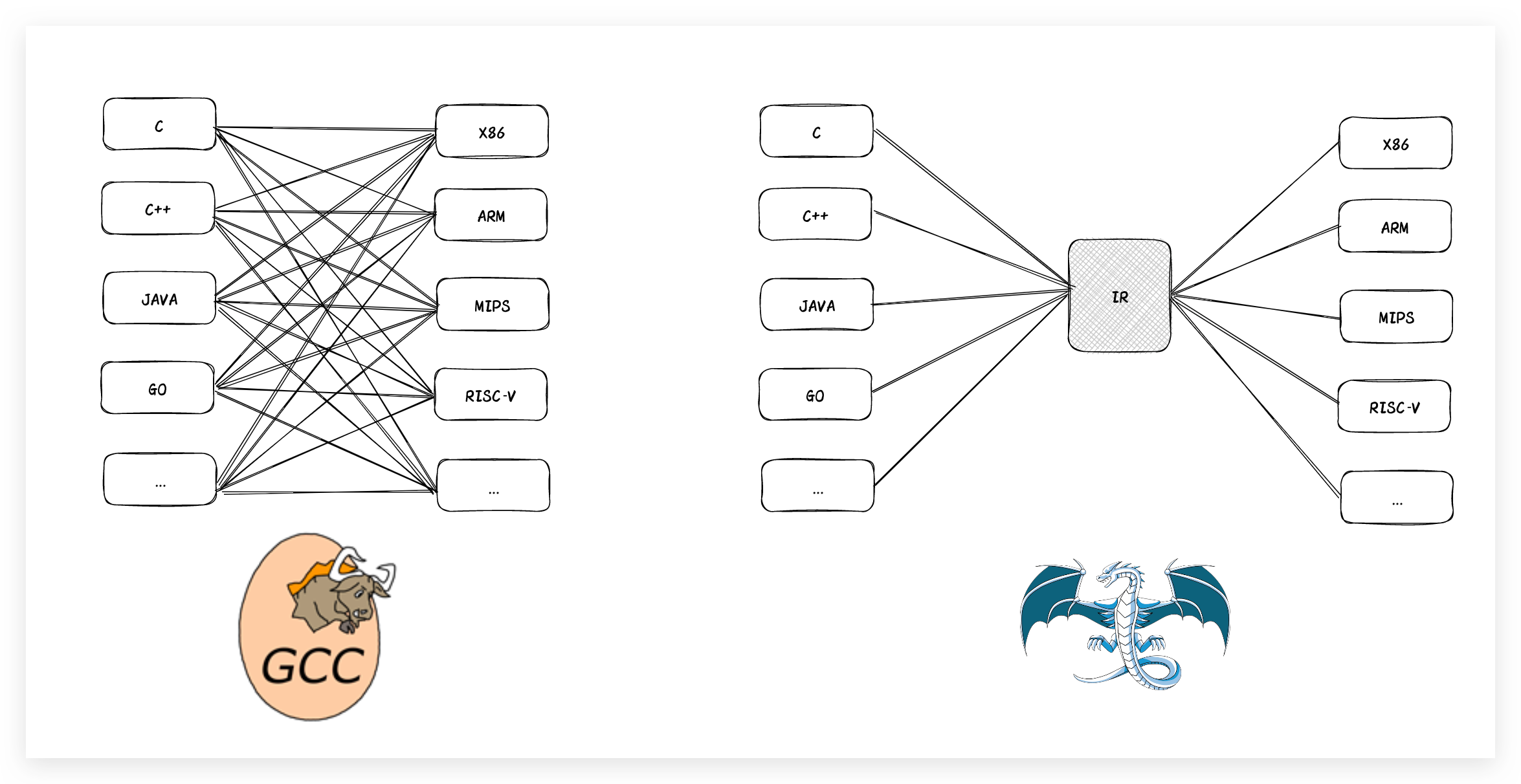
對於傳統的編譯器,主要分為前端、優化器和後端,參照一張通用的簡潔的編譯過程圖,如下:

簡單來說,針對於原始碼翻譯成計算機底層程式碼的過程中呢要經歷三個階段:前端編譯、優化器優化、後端編譯。通過前端編譯之後,針對編譯的產物進行優化處理,最後通過後端完成機器碼的生成。而對於LLVM編譯器來說,這裡我們以OC的前端編譯器Clang為例,它負責LLVM的前端的整體編譯流程(預處理、詞法分析、語法分析和語意分析),生成中間產物LLVMIR,最後由後端進行架構處理生成目的碼,如下圖:

可以看出LLVM將編譯的前後端獨立分開了,前端負責不同語言的編譯操作,如果增加一個語言的編譯支援,只需要擴充套件支援當前語言的前端編譯支援(Clang負責OC前端編譯、SwiftC負責Swift前端編譯)即可,優化器與後端編譯器整體均不用修改即可完成新增語言的支援。同理,對於後端,如果需要新增新的架構裝置的支援,只需要擴充套件後端架構對應編譯器的支援即可完成新架構裝置的支援,這也是LLVM編譯器的優點之一。
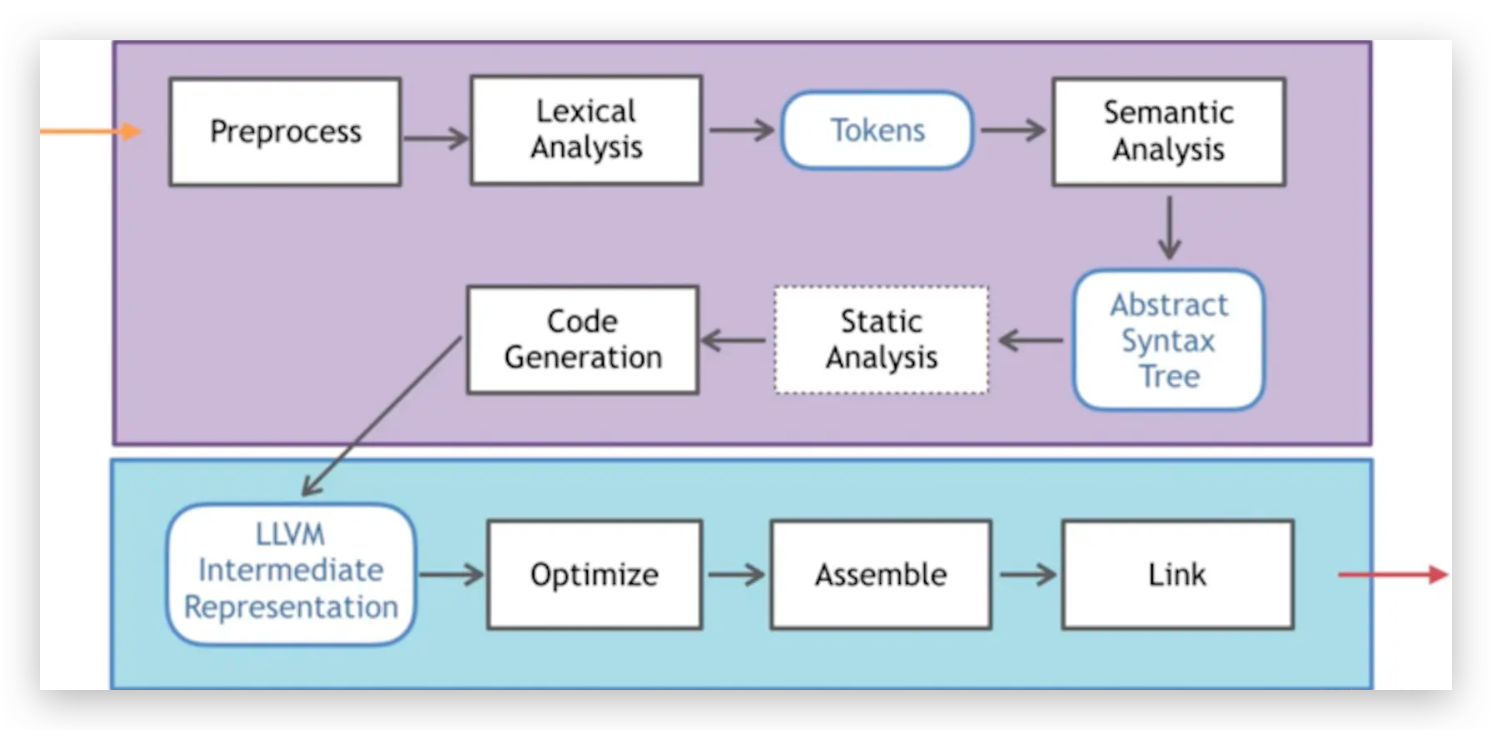
3.1、編譯器前端
在XCode中針對於OC與Swift的編譯有著不同的前端編譯器,OC採用Clang進行編譯,而Swift則採用SwiftC編譯器,兩種不同的編譯器前端在編譯之後,生成的中間產物都是LLVMIR。這也就解釋了對於高階語言Swift或者OC開發,哪怕是混編,在經過各自的編譯器前端編譯之後,最終的編譯產物都是一樣的,所以選用哪種開發語言對於最終生成的中間程式碼IR都是通用的。對於Clang的整體編譯過程,如下圖所示:
預處理
通過對原始碼中以「#」號開頭如包含#include,宏定義制定#define等掃描。然後進行原始碼定義替換,進行標頭檔案內容的展開。通過前處理器把原始檔處理成.i檔案。
詞法分析
在詞法分析完成之後會生成 token 產物,它是做什麼的?這裡不貼官方的解釋了,簡單點說就是對原始碼的原子切分,切分成能夠底層描述的單個原子,就是所謂的token,至於token長什麼樣子?可以通過 clang 的命令執行編譯檢視生成的原子內容:
clang -fmodules -E -Xclang -dump-tokens xxx.m
#import <UIKit/UIKit.h>
#import "AppDelegate.h"
int main(int argc, char * argv[]) {
NSString * appDelegateClassName;
@autoreleasepool {
// Setup code that might create autoreleased objects goes here.
appDelegateClassName = NSStringFromClass([AppDelegate class]);
int a = 0;
}
return UIApplicationMain(argc, argv, nil, appDelegateClassName);
}
我們拿工程的main.m 做個測試,編譯生成的內容如下:
注:如果遇到 main.m:8:9: fatal error: 'UIKit/UIKit.h' file not found 錯誤,可以加上系統基礎庫路徑如下:
clang \
-fmodules \
-E \
-Xclang \
-dump-tokens \
-isysroot \
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \
main.m
可以發現,計算機在進行原始碼處理的時候,並不能像人一樣能夠理解整個原始碼內容的含義。所以為了進行轉換,在進行原始碼分析的時候,將整體的內容進行單詞切分,形成原子為後續的語意分析做準備,整體的切分過程大致採用的是狀態機原理。
語法分析
在完成詞法分析之後,編譯器大致理解了每個原始碼中的單詞的意思,但是對於單詞組合起來的語句內容並不能理解。所以接下來需要對單詞組合起來的內容進行識別,也就是我們所說的**語法分析**。 語法分析的原理有點模板匹配的意思,怎麼理解呢?就是我們常說的語法規則,在編譯器中預置了相關語言的語法規則模板,如果匹配了相關的規則,則按照相關語法規則進行解析。舉個例子,比如我們在OC中寫一個這樣的語句:
int a = 100;
這是一種通用的賦值語法格式,所以在編譯器進行語法分析的時候,將其按照賦值語法的規則進行解析,如下:
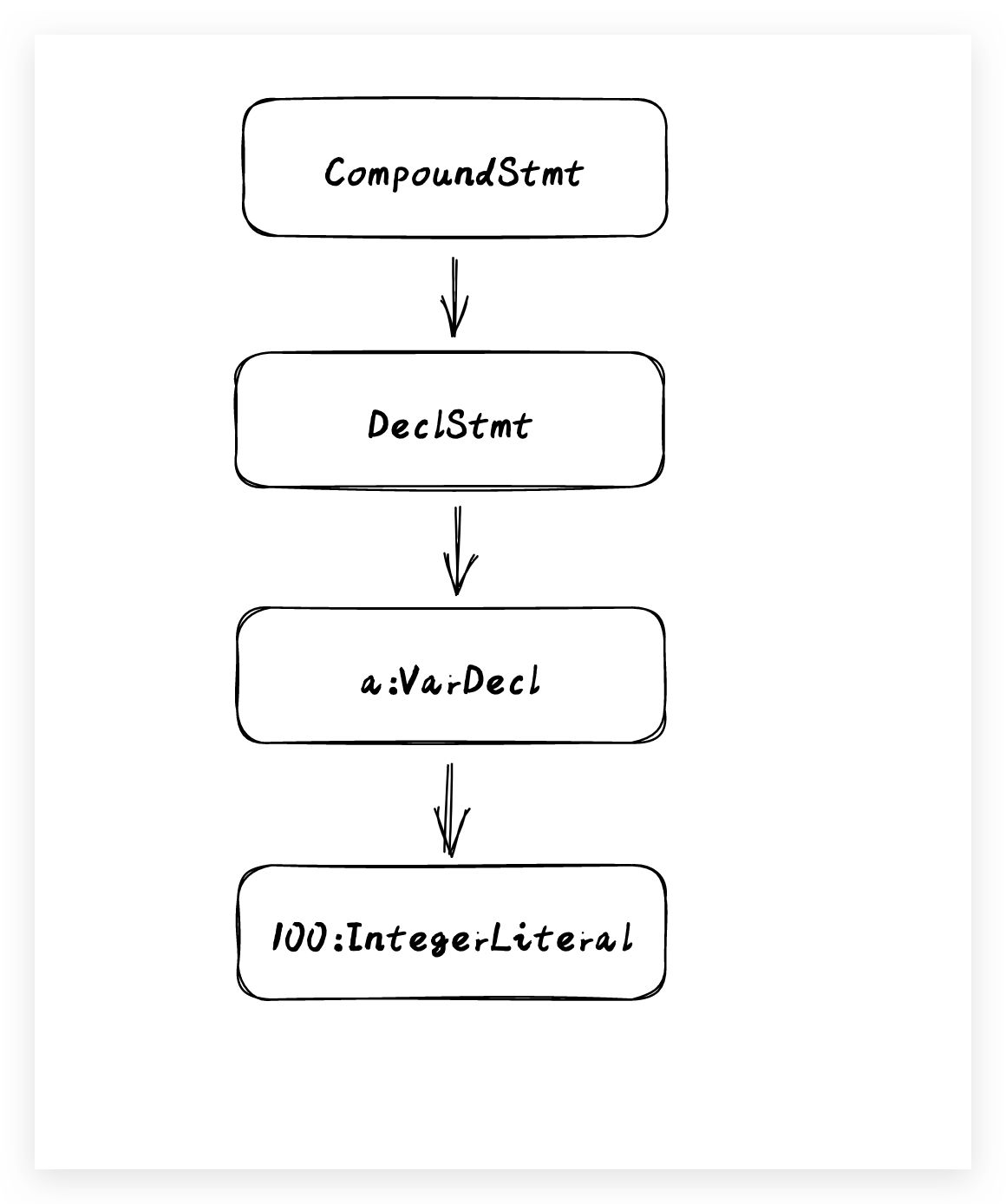
通過對原子token的組合解析,最終會生成了一個抽象語法樹(AST),AST抽象語法樹將原始碼轉換成樹狀的資料結構,它描述了原始碼的內容含義以及內容結構,它的生成能夠讓計算機更好的理解和處理中間產物。以XCode生成的預設專案的main.m內容為例,在 clang 中我們依舊可以檢視具體的抽象生成樹(AST)的樣子,可以對原始碼進行如下的編譯:
clang \
-isysroot \
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \
-fmodules \
-fsyntax-only \
-Xclang \
-ast-dump \
main.m
編譯後的結果如下:
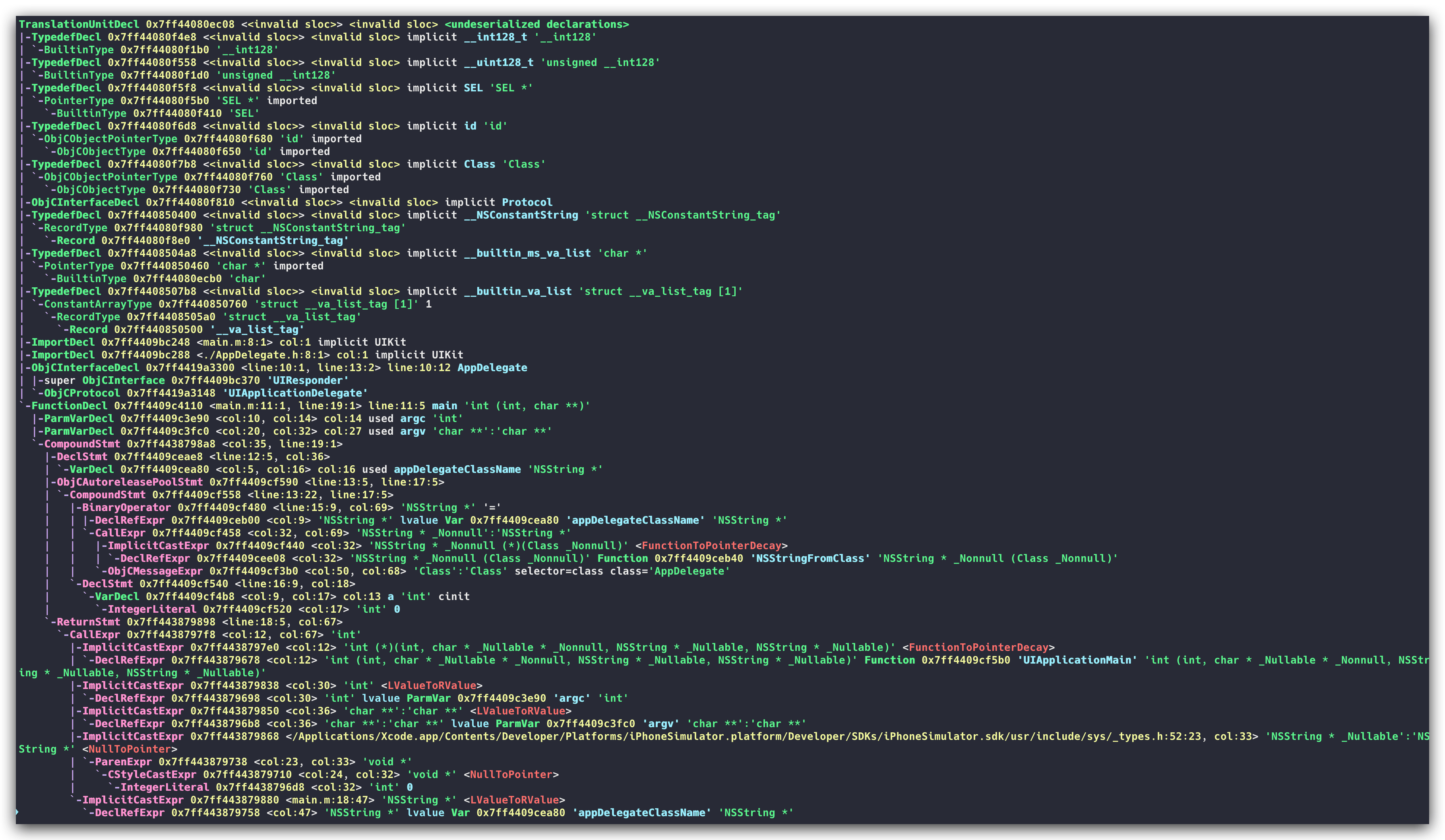
簡單轉換一下樹形檢視,大致長這樣:

可以發現,經歷過語法分析之後,原始碼轉換成了具體的資料結構,而資料結構的整體生成是後續進行語意分析生成中間程式碼的基礎前提。
語意分析
在經歷過語法分析之後,編譯器會對語法分析之後生成的抽象語法樹(AST)再次進行處理,需要注意的是編譯器並不會直接通過AST編譯成目的碼,主要原因是因為編譯器將編譯過程拆分了前後端,而前後端的通訊的媒介就是IR,沒錯就是之前提到過的LLVMIR這樣一箇中間產物。該中間產物與語言無關,同時與cpu的架構也無關,那麼為什麼要加上中間產物這個環節,直接生成目的碼難道不是更好嗎?我們都知道cpu的不同架構直接影響cpu的指令集,不同的指令集對應不同的組合指令,所以針對於不同的cpu架構要對應生成不同適配的組合指令才能正常的執行到不同的cpu架構的機器上。如果將前後端的編譯過程繫結死,那麼就會導致每增加一個新的編譯前端,同時增加對所有cpu架構的後端的支援(1對n的關係),同理,如果增加新的一個cpu架構支援,編譯前端也需要通通再實現一遍,這個工作量是很重複以及繁瑣的。所以為了避免這樣的問題,Apple對編譯器的前後端進行了拆分,用中間產物來進行前後端的邏輯適配。
對於語意分析生成中間產物的過程,也可以通過 Clang 的編譯命令檢視,具體如下:
# 生成擴充套件為.ll的便於閱讀的文字格式
clang \
-isysroot \
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \
-S \
-emit-llvm \
main.m \
-o \
main.ll
# 生成二進位制格式,擴充套件為.bc
clang \
-isysroot \
/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/SDKs/iPhoneSimulator.sdk \
-emit-llvm \
-c \
main.m \
-o \
main.bc
編譯後生成的內容如下:
; ModuleID = 'main.m'
source_filename = "main.m"
target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-ios16.2.0-simulator"
%0 = type opaque
%struct._class_t = type { %struct._class_t*, %struct._class_t*, %struct._objc_cache*, i8* (i8*, i8*)**, %struct._class_ro_t* }
%struct._objc_cache = type opaque
%struct._class_ro_t = type { i32, i32, i32, i8*, i8*, %struct.__method_list_t*, %struct._objc_protocol_list*, %struct._ivar_list_t*, i8*, %struct._prop_list_t* }
%struct.__method_list_t = type { i32, i32, [0 x %struct._objc_method] }
%struct._objc_method = type { i8*, i8*, i8* }
%struct._objc_protocol_list = type { i64, [0 x %struct._protocol_t*] }
%struct._protocol_t = type { i8*, i8*, %struct._objc_protocol_list*, %struct.__method_list_t*, %struct.__method_list_t*, %struct.__method_list_t*, %struct.__method_list_t*, %struct._prop_list_t*, i32, i32, i8**, i8*, %struct._prop_list_t* }
%struct._ivar_list_t = type { i32, i32, [0 x %struct._ivar_t] }
%struct._ivar_t = type { i64*, i8*, i8*, i32, i32 }
%struct._prop_list_t = type { i32, i32, [0 x %struct._prop_t] }
%struct._prop_t = type { i8*, i8* }
@"OBJC_CLASS_$_AppDelegate" = external global %struct._class_t
@"OBJC_CLASSLIST_REFERENCES_$_" = internal global %struct._class_t* @"OBJC_CLASS_$_AppDelegate", section "__DATA,__objc_classrefs,regular,no_dead_strip", align 8
@llvm.compiler.used = appending global [1 x i8*] [i8* bitcast (%struct._class_t** @"OBJC_CLASSLIST_REFERENCES_$_" to i8*)], section "llvm.metadata"
; Function Attrs: noinline optnone ssp uwtable
define i32 @main(i32 %0, i8** %1) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i8**, align 8
%6 = alloca %0*, align 8
%7 = alloca i32, align 4
store i32 0, i32* %3, align 4
store i32 %0, i32* %4, align 4
store i8** %1, i8*** %5, align 8
%8 = call i8* @llvm.objc.autoreleasePoolPush() #1
%9 = load %struct._class_t*, %struct._class_t** @"OBJC_CLASSLIST_REFERENCES_$_", align 8
%10 = bitcast %struct._class_t* %9 to i8*
%11 = call i8* @objc_opt_class(i8* %10)
%12 = call %0* @NSStringFromClass(i8* %11)
store %0* %12, %0** %6, align 8
store i32 0, i32* %7, align 4
call void @llvm.objc.autoreleasePoolPop(i8* %8)
%13 = load i32, i32* %4, align 4
%14 = load i8**, i8*** %5, align 8
%15 = load %0*, %0** %6, align 8
%16 = call i32 @UIApplicationMain(i32 %13, i8** %14, %0* null, %0* %15)
ret i32 %16
}
; Function Attrs: nounwind
declare i8* @llvm.objc.autoreleasePoolPush() #1
declare %0* @NSStringFromClass(i8*) #2
declare i8* @objc_opt_class(i8*)
; Function Attrs: nounwind
declare void @llvm.objc.autoreleasePoolPop(i8*) #1
declare i32 @UIApplicationMain(i32, i8**, %0*, %0*) #2
attributes #0 = { noinline optnone ssp uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="core2" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+ssse3,+x87" "tune-cpu"="generic" }
attributes #1 = { nounwind }
attributes #2 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="core2" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+ssse3,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10, !11}
!llvm.ident = !{!12}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 16, i32 2]}
!1 = !{i32 1, !"Objective-C Version", i32 2}
!2 = !{i32 1, !"Objective-C Image Info Version", i32 0}
!3 = !{i32 1, !"Objective-C Image Info Section", !"__DATA,__objc_imageinfo,regular,no_dead_strip"}
!4 = !{i32 1, !"Objective-C Garbage Collection", i8 0}
!5 = !{i32 1, !"Objective-C Is Simulated", i32 32}
!6 = !{i32 1, !"Objective-C Class Properties", i32 64}
!7 = !{i32 1, !"Objective-C Enforce ClassRO Pointer Signing", i8 0}
!8 = !{i32 1, !"wchar_size", i32 4}
!9 = !{i32 7, !"PIC Level", i32 2}
!10 = !{i32 7, !"uwtable", i32 1}
!11 = !{i32 7, !"frame-pointer", i32 2}
!12 = !{!"Apple clang version 13.1.6 (clang-1316.0.21.2.5)"}
從編譯的產物來看,其中也包含了常見的記憶體分配、所用到的標識定義等內容,可以明顯的發現生成的中間產物已經沒有任何原始碼語言的影子了。同時我們會發現針對於中間程式碼,暫存器(%+數位)的使用好像沒有個數限制,為什麼呢?因為中間程式碼只是將原始碼進行了中間程式碼的描述跳脫,此時並沒有相關的目標架構資訊可供參考使用,所以針對於變數的參照也僅僅是中間層的標識。在後端編譯的過程中會將中間的這些暫存器的參照再次進行指令的轉換,最終會生成對應CPU架構指令集的組合程式碼。
還記得XCode中的BitCode開關選項嗎?它決定了編譯生成的中間產物IR是否需要儲存,如果儲存的話,會把當前的中間產物插入到可執行檔案的資料段中,保留這些中間產物內容又有什麼作用呢?我們知道在沒有保留中間產物之前,為了確保所有cpu架構的機型能夠正常安裝打出的安裝包,在打包的時候會把能夠支援的所有cpu架構的集合進行合併打包,生成一個Fat Binary,確保安裝包能夠適配所有的機型,這樣會有一個問題,比如ARM64架構的機器在安裝的時候只需要ARM64的架構二進位制檔案即可,但是由於安裝包裡相容了所有的cpu架構,其他的架構程式碼實際上根本沒有用到,這也就間接的導致了安裝包的體積變大。而蘋果在應用分發的時候,是知道目標機器的cpu架構的,所以如果能夠將中間的編譯產物交給AppStore後臺,由Appstore後臺通過編譯後端優化生成目標機器的二進位制可執行檔案,去除無用的相容架構程式碼,進而縮減安裝包的體積大小。這也即是BitCode的出現目的,為了解決編譯架構冗餘的問題,同時也為APP的瘦身提供參考。
編譯器在進行語意分析期間還有一個重要的過程叫做靜態分析(Static Analysis),llvm官方檔案是這樣介紹靜態分析的:
The term "static analysis" is conflated, but here we use it to mean a collection of algorithms and techniques used to analyze source code in order to automatically find bugs. The idea is similar in spirit to compiler warnings (which can be useful for finding coding errors) but to take that idea a step further and find bugs that are traditionally found using run-time debugging techniques such as testing.↳
Static analysis bug-finding tools have evolved over the last several decades from basic syntactic checkers to those that find deep bugs by reasoning about the semantics of code. The goal of the Clang Static Analyzer is to provide a industrial-quality static analysis framework for analyzing C, C++, and Objective-C programs that is freely available, extensible, and has a high quality of implementation.
靜態分析它能夠幫助我們在編譯期間自動查詢錯誤,比起執行時的時候去找出錯誤要更早一步,可以用於分析 C、C++ 和 Objective-C 程式。編譯器通過靜態分析依據AST中節點與節點之間的關係,找出有問題的節點並丟擲警告錯誤,達到修改提醒的目的。比如官方檔案中介紹的記憶體洩露的靜態分析的案例:
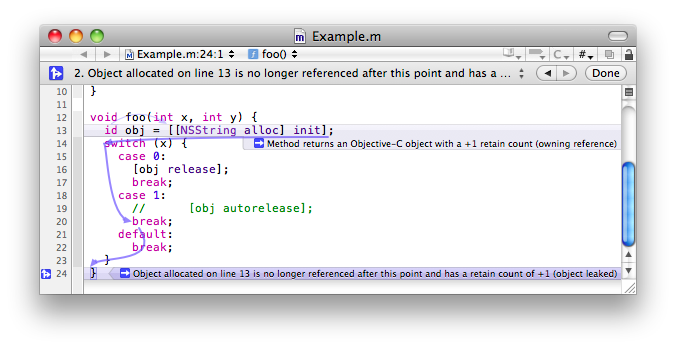
除了官方的靜態分析,我們常用的OCLint也是在編譯器生成AST抽象語法樹之後,對抽象語法樹進行遍歷分析,達到校驗規範的目的,總結一下編譯前端的所經歷的流程:通過原始碼輸入,對原始碼進行詞法分析將原始碼進行內容切割生成原子token。通過語法分析對原子token的組合進行語法模板匹配,生成抽象語法樹(AST)。通過語意分析,對抽象語法樹進行遍歷生成中間程式碼IR與符號表資訊內容。
3.2、編譯器後端
編譯器後端主要做了兩件重要的事情: 1、優化中間層程式碼LLVMIR(經歷多次的Pass操作) 2、生成組合程式碼,最終連結生成機器碼
編譯器前端完成編譯後,生成了相關的編譯產物LLVMIR,LLVMIR會經過優化器進行優化,優化的過程會經歷一個又一個的Pass操作,什麼是Pass呢?參照官方的解釋:
The LLVM Pass Framework is an important part of the LLVM system, because LLVM passes are where most of the interesting parts of the compiler exist. Passes perform the transformations and optimizations that make up the compiler, they build the analysis results that are used by these transformations, and they are, above all, a structuring technique for compiler code.
我們可以理解為一個個的中間過程的優化,比如指令選擇、指令排程、暫存器的分配等,輸入輸出也都是IR,如下圖:
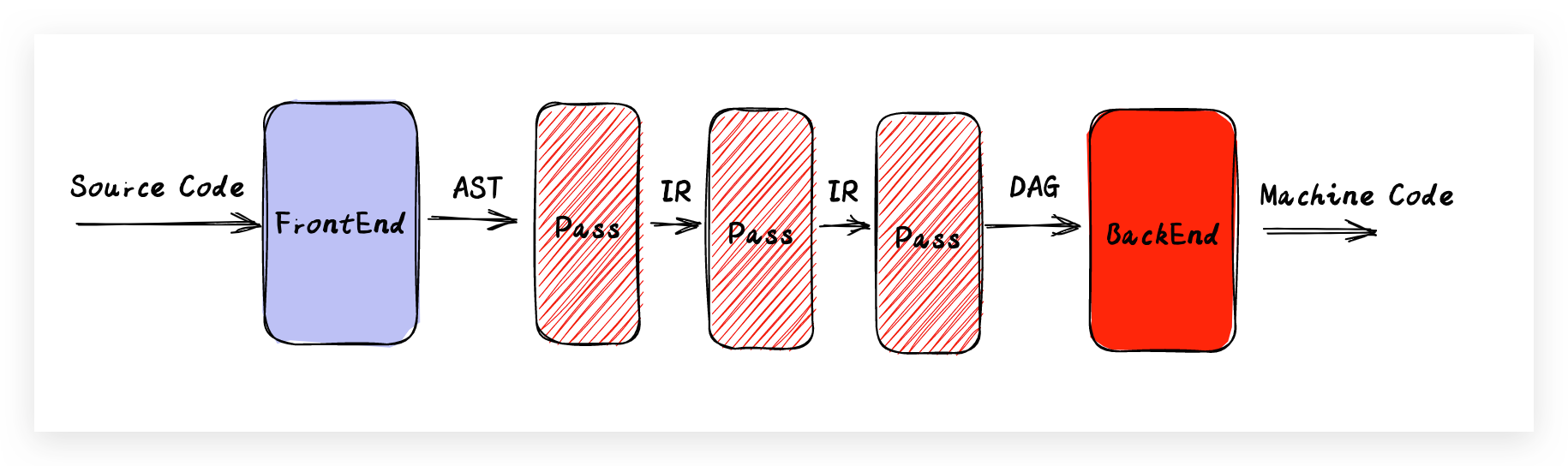
在最終優化完成之後,會生成一張DAG圖給到後端。我們知道DAG是一張有向的非環圖,這個特性可以用來標識硬體的特定順序,方便後端的內容處理。我們也可以根據自己的需要通過繼承Pass來寫一些自定義的Pass用於自定義的優化,官方對於自定義的Pass也有相關的說明,感興趣的同學可以去看看(連結放在本文最後了)。在經過優化之後,後端依據不同架構的編譯器生成對應的組合程式碼,最終通過連結完成機器碼的整體生成。
四、編譯器讓計算機更懂人類
可以發現編譯器是計算機高階語言的中樑砥柱,現在隨著高階語言的發展越來越迅速,向著簡單高效靈活的方向不斷前進,這裡面與編譯器的發展有著密切的聯絡。同時隨著編譯器的發展升級,讓高階語言到低階語言的轉換變得更高效,同時也為諸多的跨平臺語言實現提供了諸多可能。通過對計算機底層語言的層層抽象,誕生了我們所熟知的計算機高階語言,讓我們能夠用人類的思維邏輯進行指令輸入,而抽象的層層翻譯處理則交給了編譯器,它的存在建立了人類與計算機溝通的重要橋樑。
參考:
The Architecture of Open Source Applications: LLVM (aosabook.org)
LLVM Language Reference Manual — LLVM 17.0.0git documentation