Kubernetes 的親和性汙點與容忍
寫在前面
我們在使用k8s過程中經常有這樣的需求:我的k8s叢集有多臺伺服器,設定不盡相同。我想把資料庫部署到CPU、記憶體比較好的這幾臺機;我想把靜態承載服務部署到有固態硬碟的機器等;而這些需求,就是我們今天要講的k8s的排程:
在Kubernetes 中,排程 是指將 Pod 部署到合適的節點(node)上。
k8s的預設排程器是kube-scheduler,它執行的是一個類似平均分配的原則,讓同一個service管控下的pod儘量分散在不同的節點。
那接下來分別說說k8s幾種不同的排程策略。
節點標籤
在介紹排程策略之前,我們先提一句節點標籤;節點標籤關聯的指令是kubectl label ,標籤是一種鍵值對,可以用來標識和選擇資源。例如,你需要給某個節點打個標記以便後面用得上,這個標記就叫標籤。
增加標籤
kubectl label node docker-desktop restype=strong-cpu
這裡增加了一個restype=strong-cpu的標籤,表示這個節點cpu很強;
檢視標籤
kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
docker-desktop Ready <none> 328d v1.22.5 disktype=ssd
刪除標籤
kubectl label node docker-desktop restype-
nodeSelector-簡單的節點選擇器
nodeSelector:在部署pod的時候告訴叢集,我要部署到符合我要求的節點;
前面已經看到我k8s的節點 docker-desktop,已經打了disktype=ssd的標籤,那我們來部署一個測試的pod看看
建立檔案:test-netcore6-dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapi-net6
namespace: aspnetcore
labels:
name: demoapi-net6
spec:
replicas: 1
selector:
matchLabels:
name: demoapi-net6
template:
metadata:
labels:
name: demoapi-net6
spec:
containers:
- name: demoapi-net6
image: gebiwangshushu/demoapi-net6 #這是個kong的webapi
nodeSelector:
restype: strong-cpu #我這裡要求節點要有資源型別restype=strong-cpu的標籤
部署
kubectl apply -f .\test-netcore6-dep.yaml
檢視pod狀態
確實處於pending狀態
kubectl get pods
NAME READY STATUS RESTARTS AGE
demoapi-net6-c9c5cb85-rwqn2 0/1 Pending 0 52m
describe一下
可以清楚看到pending原因是affinity/selector不匹配
kubectl describe pod demoapi-net6-c9c5cb85-rwqn2
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 32s default-scheduler 0/1 nodes are available: 1 node(s) didn't match Pod's node affinity/selector.
給node加上strong-cpn加上label看看
kubectl label node docker-desktop restype=strong-cpu
再看看
...
Normal Scheduled 46s default-scheduler Successfully assigned aspnetcore/demoapi-net6-c9c5cb85-l7sdb to docker-desktop
Normal Pulling 45s kubelet Pulling image "gebiwangshushu/demoapi-net6"
#可以清楚看到已分配好node了,pod run起來了
nodeName-更粗暴的節點選擇器
前面的nodeSelector是「我要部署到符合我要求的節點」;見名思意,nodeName是更粗暴的節點選擇器,意思是:我就要部署到這個節點!
寫法範例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapi-net6
namespace: aspnetcore
labels:
name: demoapi-net6
spec:
replicas: 1
selector:
matchLabels:
name: demoapi-net6
template:
metadata:
labels:
name: demoapi-net6
spec:
containers:
nodeName: docker-desktop #就要部署到這個
這種寫法簡單粗暴,一般用來測試和測試用途,一般不這麼寫,因為存在比較多的侷限性:
- 比如節點不存在或者節點名字寫錯了,部署失敗;
- 指定的節點硬體資源不夠,比如cpu或者記憶體不夠了,部署失敗;
- 在雲服務環境中,節點名字總是變化的,指定節點名沒什麼意義;
affinity-節點親和性和pod反親和性
節點親和性功能類似於 nodeSelector 欄位,但它的選擇表達能力更強,有各種各樣的規則,還有軟規則。甚至還可以有反親和性,拒絕/排斥部署到哪些節點;
nodeAffinity--節點親和性
節點親和性(nodeAffinity)分成兩種:
requiredDuringSchedulingIgnoredDuringExecution: 硬策略。就是node你一定要滿足我的要求,才能執行排程,不然pod就一直pending;preferredDuringSchedulingIgnoredDuringExecution: 軟策略。就是我更傾向於滿足我要去的node,如果沒有那就按預設規則排程。
範例
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapi-net6
namespace: aspnetcore
labels:
name: demoapi-net6
spec:
replicas: 1
selector:
matchLabels:
name: demoapi-net6
template:
metadata:
labels:
name: demoapi-net6
spec:
containers:
- name: demoapi-net6
image: gebiwangshushu/demoapi-net6
affinity:
nodeAffinity: #親和性
requiredDuringSchedulingIgnoredDuringExecution: #硬策略
nodeSelectorTerms:
- matchExpressions: #這裡意思一定要restype=strong-cpu的節點
- key: restype
operator: In
values:
- strong-cpu
preferredDuringSchedulingIgnoredDuringExecution: #軟策略
- weight: 1
preference:
matchExpressions: #這裡意思傾向於部署到有ssd硬碟的節點
- key: disktype
operator: In
values:
- ssd
affinity: 親和性
requiredDuringSchedulingIgnoredDuringExecution:硬策略
preferredDuringSchedulingIgnoredDuringExecution:軟策略
nodeSelectorTerms:節點選擇項,陣列
matchExpressions:匹配表示式,陣列
weight: preferredDuringSchedulingIgnoredDuringExecution 可設定的權重欄位,值範圍是 1 到 100。 會計算到排程打分演演算法上,分數高的優先順序高;
operator:邏輯操作符,比如這裡的in表示包含,一共有以下邏輯運運算元;
- In:label 的值在某個列表中
- NotIn:label 的值不在某個列表中
- Gt:label 的值大於某個值
- Lt:label 的值小於某個值
- Exists:某個 label 存在
- DoesNotExist:某個 label 不存在
#可用NotIn和DoesNotExist實現反親和性;
匹配規則:
如果你同時指定了 nodeSelector 和 nodeAffinity,兩者 必須都要滿足, 才能將 Pod 排程到候選節點上。
如果你在與 nodeAffinity 型別關聯的 nodeSelectorTerms 中指定多個條件, 只要其中一個 nodeSelectorTerms 滿足,Pod 就可以被排程到節點上。
如果你在與 nodeSelectorTerms的一個 matchExpressions 中寫個表示式, 則只有當所有表示式都滿足,Pod 才能被排程到節點上。
pod間的親和反親和性
前面的節點親和性是通過pod和節點之間的標籤進行匹配,選擇的;
pod的親和性和反親和性排程指:通過已在執行中的pod標籤進行選擇排程部署的節點;
pod的親和性排程:一個典型的使用場景就是在叢集環境是有多資料中心的,那一個服務部署已經部署到廣東了,那我跟他相關的需要大量通訊的其他服務也儘量部署到廣東,降低彼此間的通訊延遲;
pod的反親和性排程:一個典型的使用場景就是我的服務要儘可能分散到各個資料中心、區域,比如廣東、西安、上海、北京,都要有我的服務,避免某個資料中心故障服務全部宕機;
範例
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapi-net6
namespace: aspnetcore
labels:
name: demoapi-net6
spec:
replicas: 1
selector:
matchLabels:
name: demoapi-net6
template:
metadata:
labels:
name: demoapi-net6
spec:
containers:
- name: demoapi-net6
image: gebiwangshushu/demoapi-net6
affinity:
podAffinity: #pod親和性
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: restype
operator: In
values:
- strong-cpu
topologyKey: topology.kubernetes.io/zone #topology.kubernetes.io/hostname 表示同一節點
podAntiAffinity: #pod間反親和性
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
topologyKey: topology.kubernetes.io/zone
親和性規則表示:當且僅當至少一個已執行且有 restype=strong-cpu 的標籤的 Pod 處於同一區域時(topology.kubernetes.io/zone=GuangDong),才可以將該 Pod 排程到節點上。
反親和性規則表示:如果節點處於 Pod 所在的同一可用區(也是看topology.kubernetes.io/zone)且至少一個 Pod 具有 disktype=ssd 標籤,則該 Pod 不應被排程到該節點上。
PS:Pod 間親和性和反親和性都需要一定的計算量,因此會在大規模叢集中顯著降低排程速度(比如上百個節點上千上萬的pod),影響效能;
這塊我也用的不多,就寫到這裡;
taint + tolerations -汙點與容忍度排程
nodeSelector/nodeName和節點親和性都是pod的一種屬性,它可以主動選擇某些節點。但如果Node想排他性地部署呢?答案就是汙點+容忍的排程;
名稱理解
taint-汙點:汙點是節點用來排斥pod的一組標籤,比如設定一個weak-cpu的汙點;當然你也可以設定strong-cpu這種「汙點」;
toleration-容忍:容忍是pod用來容忍,接收節點汙點的,比如給pod一個weak-cpu的容忍,這樣它就可以被排程到weak-cpu的節點上了;
taint-汙點
新增汙點
語法
kubectl taint NODE NAME key1=value1:EFFECT(容忍的效果)
範例
kubectl taint nodes docker-desktop restype=strong-cpu:NoSchedule
EFFECT取值
- PreferNoSchedule: 儘量不要排程。
- NoSchedule: 一定不能被排程。
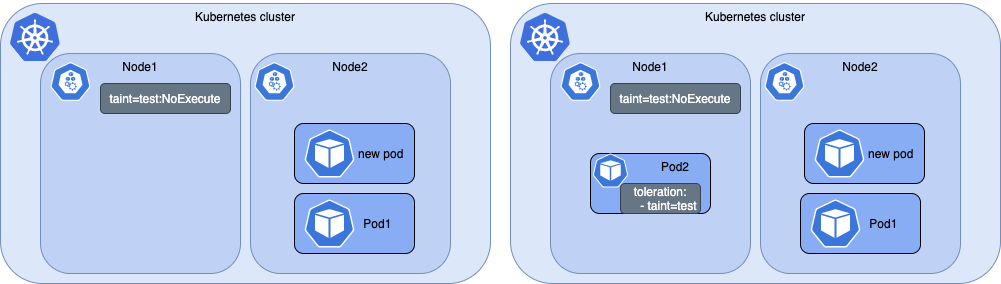
- NoExecute: 不僅不會排程, 還會驅逐 Node 上已有的 Pod。
我們這時候再看看可以明顯看到pod是pending狀態
Warning FailedScheduling 12s default-scheduler 0/1 nodes are available: 1 node(s) had taint {restype: strong-cpu}, that the pod didn't tolerate.
檢視汙點
kubectl describe node docker-desktop|grep Taints
刪除汙點
kubectl taint node restype-
tolerations-容忍
apiVersion: apps/v1
kind: Deployment
metadata:
name: demoapi-net6
namespace: aspnetcore
labels:
name: demoapi-net6
spec:
spec:
containers:
- name: demoapi-net6
image: gebiwangshushu/demoapi-net6
tolerations: #新增容忍
- key: "restype"
operator: "Equal"
value: "strong-cpu"
effect: "NoSchedule"
這裡表示容忍restype=strong-cpu
tolerations有兩種寫法
寫法1、operator="Equal"
tolerations:
- key: "restype"
operator: "Equal"
value: "strong-cpu"
effect: "NoSchedule"
這種寫法時,key、value跟effect都要跟taint的一致;
寫法2、operator="Exists"
tolerations:
- key: "restype"
operator: "Exists"
effect: "NoSchedule"
這種寫法時,key、effect 跟taint的要一致,且不能寫value的值;
tolerationSeconds-容忍時間
容忍時間是指:以指定當節點失效時, Pod 依舊不被驅逐的時間。
範例
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000 #單位(秒)
node.kubernetes.io/unreachable是k8s內建的汙點,功能是讓節點網路不可用時pod自動驅逐;這裡tolerationSeconds: 6000,意思是網路不可用6000秒後,才開始驅逐;
說明
Kubernetes 會自動給 Pod 新增針對 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 的容忍度,且設定 tolerationSeconds=300, 除非使用者自身或者某控制器顯式設定此容忍度。
這些自動新增的容忍度意味著 Pod 可以在檢測到對應的問題之一時,在 5 分鐘內保持繫結在該節點上。
其他規則
DaemonSet 中的 Pod 被建立時, 針對以下汙點自動新增的 NoExecute 的容忍度將不會指定 tolerationSeconds:
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
容忍規則
1、operator="Exists"且key為空,表示這個容忍度與任意的 key、value 和 effect 都匹配,即這個容忍度能容忍任何汙點。
tolerations:
- operator: "Exists"
2、如果 effect 為空,,那麼將匹配所有與 key 相同的 effect。
tolerations:
- key: "key"
operator: "Exists"
3、一個 node 可以有多個汙點,一個 pod 可以有多個容忍。
4、pod如果需要排程到某個node,需要容忍該node的所有汙點;
5、pod如果需要排程到某個node,但沒有容忍該node的所有汙點,且剩下的汙點effect 均為 PreferNoSchedule,那存在排程的可能;
6、如果 Node 上帶有汙點 effect 為 NoExecute,這個已經在 Node 上執行的 、不容忍該汙點的Pod 會從 Node 上驅逐掉(排程到其他node);
7、當叢集只有一個 node 節點時,無法做到 Pod 遷移(主要是驅逐),因為 Pod 已經無路可退了。
總結
總的來說k8s中Node&Pod的排程策略還是比較實用,常用的需求,學學防身沒毛病;
[參考]
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/kube-scheduler/
https://www.cnblogs.com/hukey/p/15724506.html