瘋一樣的向自己發問
瘋一樣的向自己發問 - 剖析lsm 索引原理
lsm簡析
lsm 更像是一種設計索引的思想。它把資料分為兩個部分,一部分放在記憶體裡,一部分是存放在磁碟上,記憶體裡面的資料檢索方式可以利用紅黑樹,跳錶這種時間複雜度低的資料結構進行檢索。

而當記憶體資料到達一定閥值的時候則會將資料同步到一個新的磁碟檔案上。此時寫入磁碟的方式是順序寫,這也是為什麼lsm寫入效能高的原因。
提問開始
打住,你說寫入效能高,但是我們知道記憶體中的資料如果在處於正在同步到磁碟的過程中,如果此時有新資料的插入,則會帶來並行讀寫問題,要想解決就要給這片記憶體區域加鎖了。加鎖會導致寫入過程阻塞,這樣效能會高嗎?
業界一般是這樣解決的,當記憶體到達某個閥值後,就將這片記憶體標記為可讀,然後新的資料插入將會寫到新的記憶體區域,而舊的記憶體因為是唯讀的原因,便可以不加鎖的進行同步到磁碟的過程。
再來思考,由於每次同步是生成一個新的磁碟檔案,那麼lsm是如何再多個磁碟檔案範圍裡進行資料檢索的呢? 由於記憶體容量有限,每次生成的磁碟檔案必然不會過大,這樣會不會產生大量的小容量的磁碟檔案?
我來回答下, 查詢資料的時候是從多個磁碟檔案中讀取資料,然後對結果進行合併,只取最新的資料。
這裡已經可以看到和b+tree比較明顯的區別了,b+tree是插入的時候進行原地合併,而lsm則是讀取時進行資料合併。
由於資料在記憶體中是有序的,所以在寫入磁碟時,也保證了每個小的磁碟檔案是有序的。我們將這些小的磁碟檔案稱作sstable。
但是這樣的設計還有沒有問題,如果僅僅保證sstable檔案有序,不同sstable檔案索引的範圍有重疊的話,我們查詢一個值的時候就可能會在多個sstable檔案裡尋找,最差的情況可能要找所有的sstable檔案,如圖:
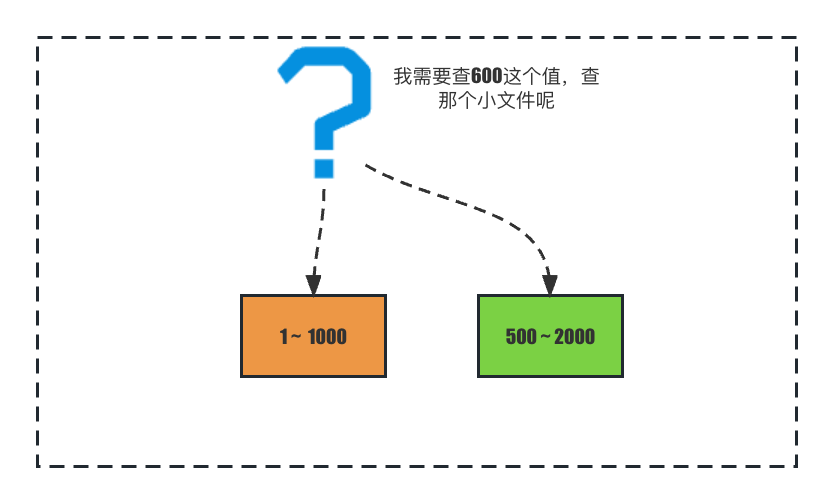
有個索引範圍是1-1000的sstable,和值範圍為500-2000的sstable,當我們查詢600時,無法一開始就知曉600在哪個sstable裡。
因此,業界一般是這樣做,對多個小檔案進行合併,讓磁碟檔案之間不再有覆蓋關係。
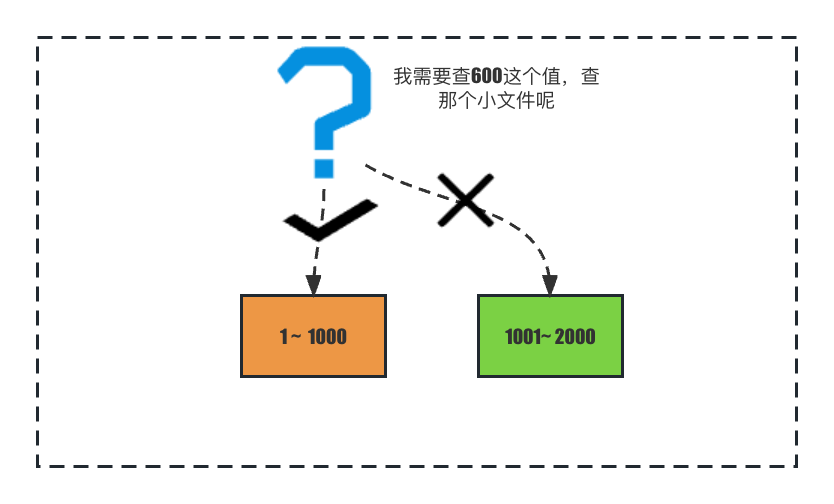
將索引範圍合併後,兩個sstable之間將不再重疊,便能快速檢索到 查詢的值所在的sstable了。
還沒完,剛才提到了合併sstable檔案,合併既能讓sstable檔案之間不會產生索引範圍覆蓋,又能減少大量小體積的sstable,但是在什麼時候進行合併呢?
如果在新增sstable時進行合併,新增一個sstable,發現現有的sstable和和新增的sstable索引的範圍都有重合關係,是不是要將新增的sstable全部與現有的sstable進行多路歸併排序,然後再生成新的一個或多個sstable。
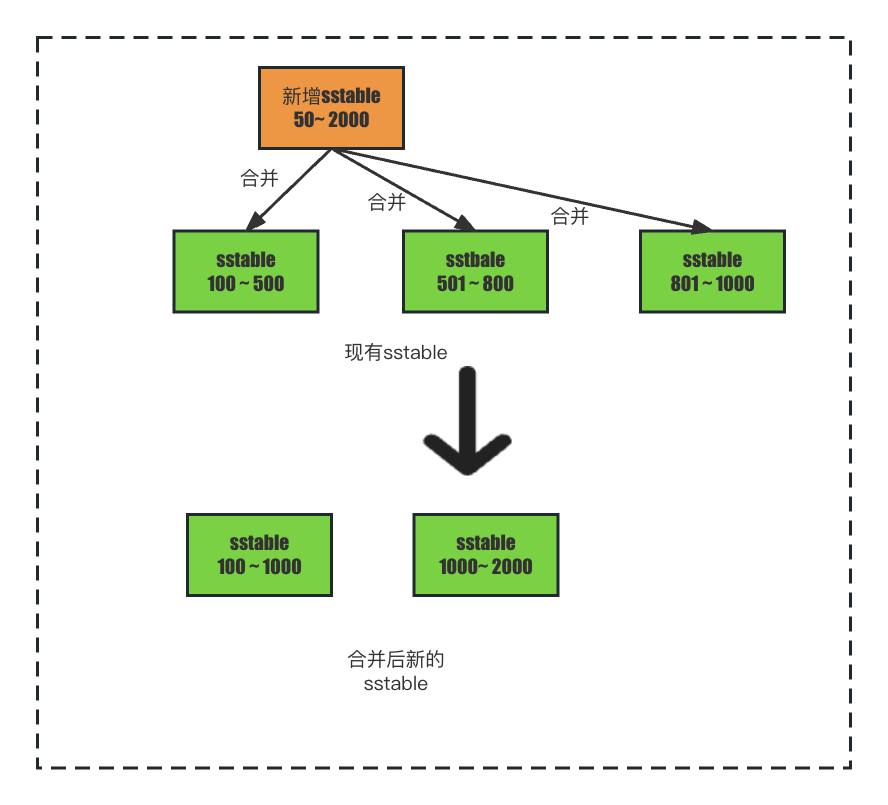
這樣的效率真的會高嗎? 新增的索引體積是比較小的,如果新增一個比較小的數量級的sstable檔案就去合併所有的sstable檔案顯然是不合理的,並且由於新增的sstable體積小,產生較為頻繁,如果每次都全量合併將會導致磁碟io在較長時間都處於一個比較高的值。
所以,最後業界的實現一般採用下面的多層次合併的方式。每一層的容量是上一層容量的10倍。

level0層 是標記為可讀的那片記憶體直接順序寫入磁碟形成的sstable 檔案的集合,只有4個檔案,注意由於level0是記憶體直接寫入生成的,所以level0層索引範圍是有重合的,而其他層的索引範圍將不會有重合產生。
當再有新的的sstable檔案生成時,那麼新的sstable就會和當前層有重合的sstable合併到下一層。
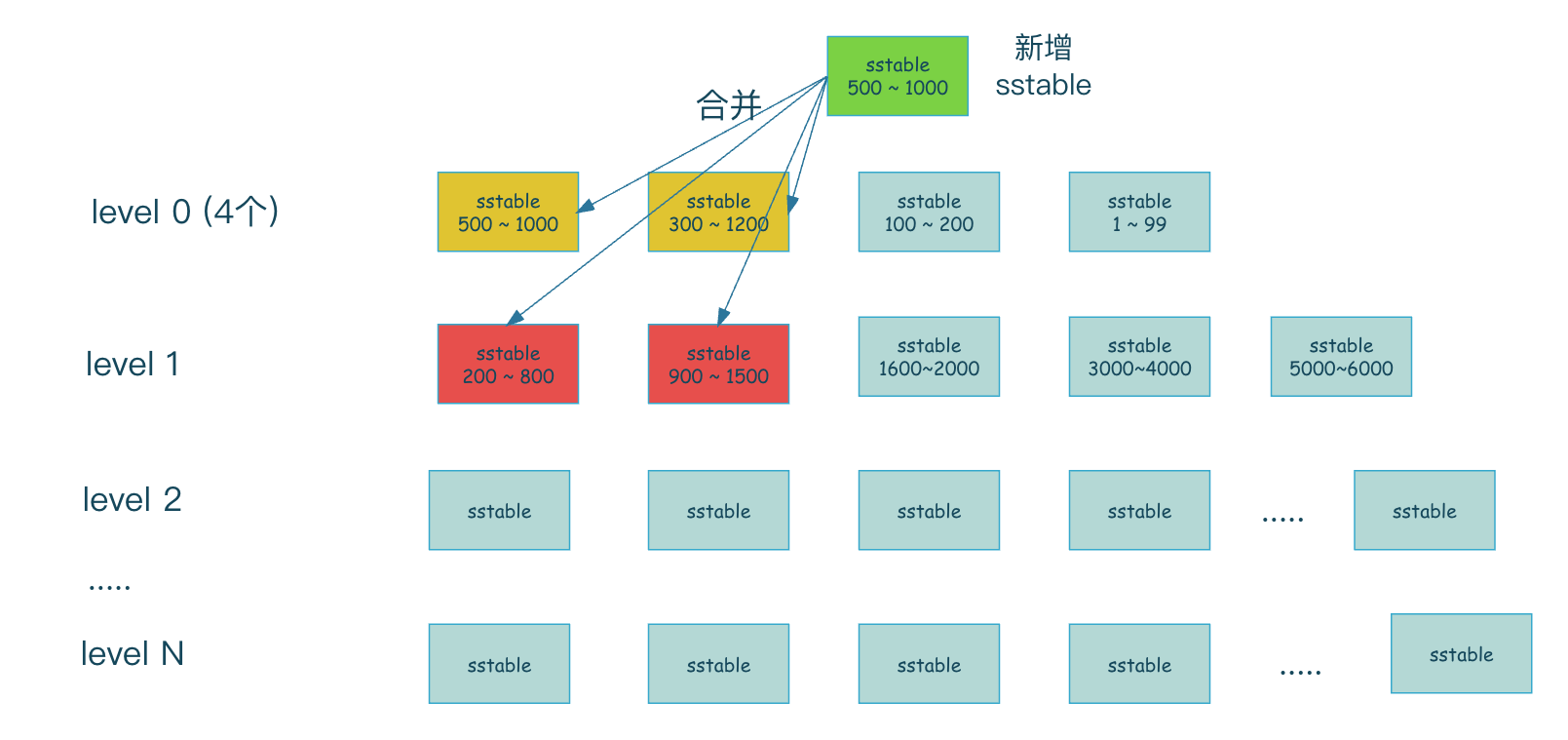 當新增一個sstable時,sstable的範圍是500 ~ 1000 ,那麼這個範圍中level0層有500 ~ 1000的sstable和300 ~ 1200的sstable都和新增的sstable有重合,所以需要將這3個sstable一起合併到下一層,而合併到下一層時,發現上一層需要合併的索引範圍是500 ~ 1200,所以找出level1層中與此索引範圍有重合的sstable,即level1 中標記為紅色的sstable,然後再與它們進行合併產生新的sstable。
當新增一個sstable時,sstable的範圍是500 ~ 1000 ,那麼這個範圍中level0層有500 ~ 1000的sstable和300 ~ 1200的sstable都和新增的sstable有重合,所以需要將這3個sstable一起合併到下一層,而合併到下一層時,發現上一層需要合併的索引範圍是500 ~ 1200,所以找出level1層中與此索引範圍有重合的sstable,即level1 中標記為紅色的sstable,然後再與它們進行合併產生新的sstable。
如果合併後發現當前層的容量達到了某個閥值,那麼就又會將當前層的sstable繼續合併到一層,一般我們會限制一個最大的層數,到達最大層數後就不再繼續合併了。
這樣多層捲動合併的設計能很好的解決每次新的sstable產生可能引發的高磁碟io的情況,因為它將之前的一次性合併按層次分攤到了多次,將整個合併過程分攤到了不同的時間段,緩解了寫放大問題。
lsm 小結
從lsm的實現上來看,已經能夠明白它的一個資料寫入和檢索過程。這裡再來總結一下。
lsm 寫入時,會先寫入到記憶體,記憶體裡資料的檢索一般是比較高效的資料結構,類似跳錶,紅黑樹等,記憶體中的資料是有序。 記憶體到達某個閥值後,會將這片記憶體標記為唯讀,後續新的寫入將在新的記憶體區域上進行,而唯讀的記憶體會將有序的資料寫入到磁碟level0層,形成sstable檔案。當level0層的sstable檔案超過4個後,將會與level1層sstable產生合併行為,level0層以後的層級的索引範圍都是沒有重合的。
lsm讀取資料時,同樣先從記憶體中讀取,如果讀取不到則會從磁碟由低層到高層進行讀取,讀取到則返回,讀取不到則直至最後一層為止。由於level0層以後的 每層 sstable資料都是有序且不重合的,在快速檢索到資料所在的sstable 後,便能快速通過二分查詢判斷資料是否在該層中,真實實現,在sstable還用上了布隆過濾,來快速判斷元素不在sstable的情況。如果該層找不到,則繼續往下一層尋找。
可以看到,在讀取資料時,最差的情況要遍歷所有的層次,這也是為什麼說lsm適合寫多讀少的場景,在讀時也最好讀取最近的資料。
看看與b+tree的區別
b+tree的索引更新是原地更新,原地更新帶來的代價很明顯,第一個是要加鎖,第二個由於更新時各個節點之前的在磁碟位置並不相鄰帶來的隨機寫入問題。 但b+tree的隨機讀效能很好,上千萬的資料最多也只需要兩三次磁碟io。
而lsm在高效寫的優勢下 帶來了讀放大問題,最壞的情況可能要在lsm多層磁碟索引結構中,每個層次都找一遍。在寫頻繁的場景下,查詢也基本上是查最近資料時,lsm具有很好的效能。
問了一通之後,算是理清楚了lsm的原理了,平時我也傾向於向自己發問來不斷剖析問題,結尾我再問一個問題吧,這篇文章裡,我一共問了幾個問題呢?