工良出品:包教會,Hadoop、Hive 搭建部署簡易教學
導讀
最近一個資料分析朋友需要學習 Hive,剛好我也想學,便利用手頭的伺服器搭建一個學習環境,但是搭建過程中,發現網上的教學很多過時了,而且部署過程中,很多地方走不通,博主也沒有給出對應的說明。花了大力氣才從各種資料中完成 Hadoop、Mysql、Hive 三者的部署。
因此,本文記錄在 Windows 下部署三者的過程以及如何解決部署過程中出現的問題,減少讀者折騰消耗的時間。
Hadoop、Hive 是什麼
由於 Hadoop、Hive 都是 Java 編寫的程式,因此在 Windows 、Linux 下的部署是差不多的,最重要的是設定 Hadoop、Hive 的組態檔,在 Windows、Linux 設定方式是相同的,過程也是一致的。所以在 Windows 學習設定後,在 Linux 下也適用。
本文之所以使用 Windows 部署,是因為筆者在 Linux 下部署屢次失敗,前後重新部署了幾次,花掉了大量時間,最後使用 Windows 部署,折騰好久之後終於成功。
不愧是 Java,屎環境又設定了一天。
首先有一個疑問,為什麼學習 Hive,還要部署 Hadoop、Mysql?
在一開始筆者就不理解,初入門學習,為什麼要部署這麼多東西呢?
在 Google 很多資料之後,筆者發現這得先了解 Hadoop 和 Hive 是什麼玩意兒開始說起。
首先是 Hadoop,看檔案對 Hadoop 的描述:
「Hadoop 是一個開源軟體框架,用於在分散式運算環境中儲存和處理大量資料。它旨在處理巨量資料,並基於 MapReduce 程式設計模型,該模型允許並行處理巨量資料集。」
讀者可以從這裡瞭解 Hadoop 到底是啥玩意兒:https://aws.amazon.com/cn/emr/details/hadoop/what-is-hadoop/
也就是說,首先 Hadoop 可以儲存大量資料,這不就是資料庫麼,只不過它的特點是為分散式而生,可以在不同伺服器上儲存資料。接著, Hadoop 還可以處理大量資料。
總結起來就是,Haddop 具有兩大功能:儲存、處理巨量資料。
實現這兩大功能,是通過 HDFS 儲存大量資料、MapReduce 平行計算資料,兩大元件完成的。
HDFS:一個在標準或低端硬體上執行的分散式檔案系統。
MapReduce:對資料執行平行計算的框架。這個東西學習成本高。
另外 Hadoop 為了維護叢集,還需要管理與監控叢集節點和資源使用情況,所以還需要使用 YARN 元件。
在入門階段,我們並不需要了解 HDFS、MapReduce 有多牛逼,我們只需要知道 HDFS 是用來儲存資料的,MapReduce 是用來計算資料的即可。
既然 Hadoop 自己就可以儲存、計算資料,那麼還要 Hive 這些東西幹嘛?
原因是:Hadoop 生態系統包含眾多工具和應用程式,可用來幫助收集、儲存、處理、分析和管理巨量資料。
也就是說,基於 Hadoop 的基礎能力,Spark、Hive、HBase 等工具可以對 Hadoop 進行擴充套件,提供對開發者來說更加容易使用的方式,簡化使用成本。
Hadoop 沒有提供 SQL 支援,而 Hive 提供了通過 SQL 介面使用 Hadoop MapReduce 的方式。所以,我們要安裝 Hive,才能通過 SQL 去使用 Hadoop。
在 Hive 中,它提供類似 SQL 的介面來處理/查詢資料,稱為 HiveQL。Hive 會將 HiveQL 查詢轉換成在 Hadoop 的 MapReduce 上,完成對資料的處理。但是Hive 可以將資料儲存在外部表中,所以可以不使用 HDFS,Hive 還支援其他檔案格式,如 ORC、 Avro 檔案、文字檔案等。
瞭解完 Hadoop、Hive 之後,再來看看另一個問題,為啥還需要安裝 Mysql 呢?
原因是需要儲存與 Hive 相關的後設資料(列名、資料型別、註釋等),Hive 通過 Metastore 元件來實現儲存後設資料,Metastore 需要一個儲存後端才能儲存這些後設資料,Hive 本身附帶了 derby 資料庫,但是這個 derby 資料庫並不是一個出色的資料庫,因此我們可以使用 MySQL 或 PostgreSQL 來儲存 Hive 的後設資料。
如果只是學習使用,並不需要安裝 Mysql 或 PostgreSQL。
執行環境
搞懂 Hadoop、Hive、Mysql 之間的關係之後,我們開始下載各種東西,提前做好準備給 Hadoop、HIve 執行的環境。
Java 環境
首先安裝 Java 執行環境,請一定使用 Java8,經過大量踩坑之後,筆者才發現 Java 11 執行 Hive 最後一步會爆炸, Windows 、Linux 都是如此。
下載 Java8 地址:
官網地址: https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html
國內華為映象站點: https://repo.huaweicloud.com/java/jdk/
點選
jdk-8u202-windows-x64.exe下載安裝包。
下載後,點選 .exe 檔案進行安裝。
請一定不要安裝到有空格的目錄,如:C:\Program Files\Java。
目錄一定不能帶有空格。
安裝目錄路徑儘可能簡單,例如,筆者安裝到了 E:\Java。
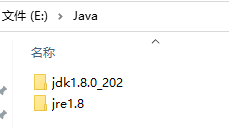
接著,新增環境變數 JAVA_HOME :
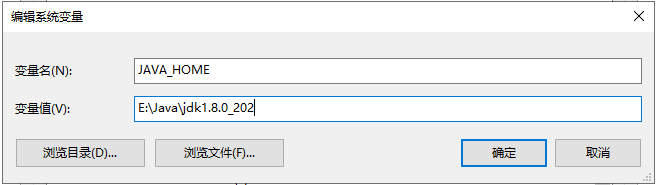
新增 Path 環境變數:E:\Java\jdk1.8.0_202\bin

然後開啟 cmd,執行 java -version,確保 Java8 已經被成功安裝。
Mysql
大多數教學都是在安裝 Hive 時,穿插安裝 Mysql,搞得安裝的時候莫名其妙的,思路容易斷。。。
所以,我們可以提前裝好 Mysql,設定好賬號密碼,設定 Hive 的時候可以一步到位。
安裝 Mysql 的方法有很多,不盡相同,讀者可以參考別的文章安裝 Mysql,可以根據其它資料以最簡單的方法安裝。
下載 Mysql 安裝包不能直接執行,需要先安裝 Microsoft Visual C++ Redistributable,點選此連結找到對應 x64 的安裝包地址:
https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist?view=msvc-170

點選 VC_redist.x64.exe 開始安裝。
接著通過國內的華為映象站點加速下載 Mysql:
https://mirrors.huaweicloud.com/mysql/Downloads/MySQL-8.0/
找到
mysql-8.0.24-winx64.msi,點選下載。


安裝 Mysql 之後,需要找到安裝位置,然後新增到環境變數 Path 中,如:
C:\Program Files\MySQL\MySQL Server 8.0\bin
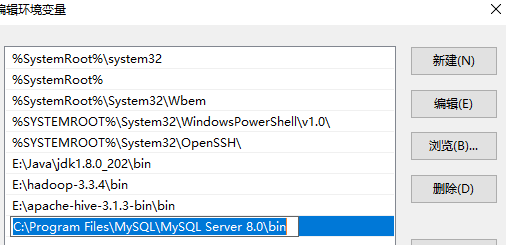
接著執行命令初始化 Mysql 服務:
mysqld --install
mysqld --initialize --user=mysql --console
執行命令之後,請注意控制檯輸出的 Mysql 隨機密碼!
如果安裝出現其他問題,可以試試:
mysqld --initialize --user=mysql --console
sc delete mysql
mysqld -install
執行命令之後,請注意控制檯輸出的 Mysql 隨機密碼!
然後執行 net start mysql 命令,啟動 Mysql 引擎,讓其在後臺執行。
然後使用工具連線 Mysql 資料庫:
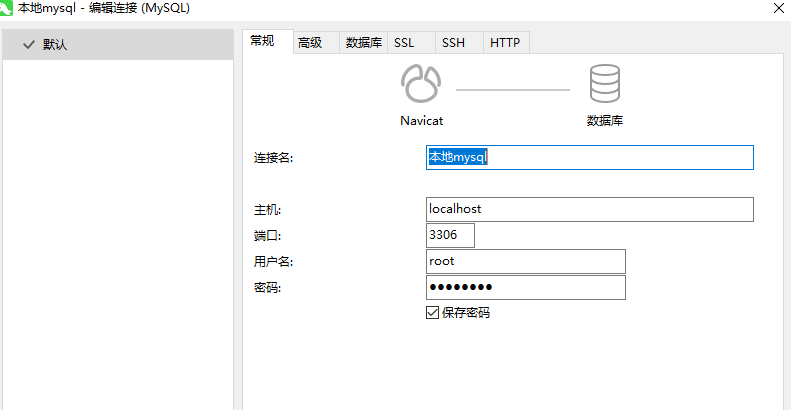
建立一個名稱為 hive 的資料庫,其字元集使用 latin1。

下載 Hadoop、Hive 和 驅動
接下來先點選下面的連結把檔案下載好,不急於安裝。
下面提供一些國內映象源,方便下載。
下載 hadoop :
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
筆者當前版本是 3.3.4。
下載 hive:
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.3/
下載 Windows hive 支援
https://github.com/HadiFadl/Hive-cmd
後面再解釋為什麼要下載這個。
下載 Mysql Java 驅動
https://downloads.mysql.com/archives/c-j/
Hive 連線 Mysql 需要一個 Mysql 驅動,開啟頁面後,選擇 Platform Independent,然後下載其中一種壓縮包即可。

安裝 Hadoop
將壓縮包解壓到目錄中,請不要使用帶空格的目錄,解壓目錄不宜太深,路徑越短越好。

然後新增一個 HADOOP_HOME 環境變數:

然後新增 Path 環境變數:

接著開啟 https://github.com/cdarlint/winutils ,下載壓縮包:

Hadoop 要在 Windows 下執行,需要 winutils.exe 、hadoop.dll 、hdfs.dll,這個倉庫中包含了 Hadoop 在 Windows 下執行所需要的一些依賴。
解壓後,找到最新版本的目錄(不一定跟你下載的 Hadoop 版本一致),將 bin 目錄中的所有檔案,複製到 Hadoop 的 bin 目錄中。
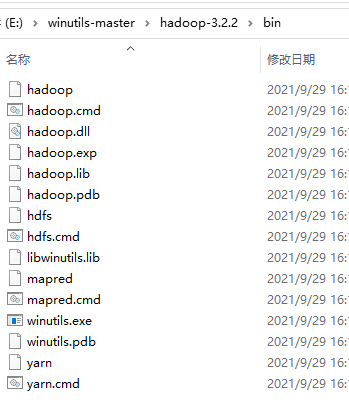
然後將 hadoop.dll 複製放到 sbin 和 C:\Windows\System32 中。

接下來需要修改五個組態檔,檔案都在 etc\hadoop 目錄中。
.xml 檔案的設定都是空的:
<configuration>
</configuration>
複製下面的設定直接替換再編輯即可。
core-site.xml
直接替換,不需要修改:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
複製內容進行替換:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50070</value>
</property>
<property>
<name>dfs.namenode.dir</name>
<value>/E:/hadoop-3.3.4/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/E:/hadoop-3.3.4/data/dfs/datanode</value>
</property>
</configuration>
裡面有兩個地址需要替換。
首先到 Hadoop 目錄下,依次建立 data/dfs/namenode,data/dfs/datanode 目錄。
然後替換到上面即可,注意前面有個 / 開頭。
俺也不清楚這個為啥要加上
/。實際上好像建立了這些也沒用。
筆者根本沒有建立這兩個目錄也可以執行 Hadoop。
mapred-site.xml
直接替換即可。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
yarn-site.xml
直接替換即可。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
hadoop-env.cmd
找到 set JAVA_HOME=...,改成:
set JAVA_HOME=E:\Java\jdk1.8.0_202
如果沒有記錄,就在最後一行加上此命令。注意替換地址為 jdk 安裝目錄。
有就改,沒有就新增。
啟動 Hadoop
開啟 powershell 或 cmd,執行命令格式化節點:
hdfs namenode -format
然後到 sbin 目錄,先點選 start-dfs.cmd,跑起來之後再點選 start-yarn.cmd。
如果跑起來沒有報錯,那麼下次可以使用 start-all.cmd 一次性啟動,不需要再分開啟動。
啟動之後,會有四個視窗。

然後開啟檔案儲存系統介面:
http://localhost:50070/dfshealth.html
開啟叢集管理介面:
接著,先關閉所有視窗,以便停止 Hadoop。
然後開啟 powershell 或 cmd,執行以下命令,以便後面為 Hive 提供資料儲存。這一步並不影響 Hadoop,而是為了 Hive 執行而新增的。
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/
hadoop fs -mkdir /user/hive/
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
然後再執行 start-all.cmd,讓四個視窗一直掛在後臺。
安裝 Hive
將 Hive 壓縮包解壓,然後設定環境變數 HIVE_HOME。

接著設定 Path:

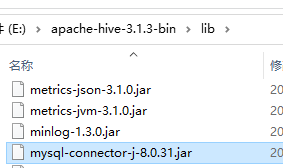
因為本文使用 Mysql 儲存 Hive 的後設資料,因此需要給 Hive 設定 Mysql 的驅動。
將下載的 Mysql java 驅動解壓,找到 mysql-connector-j-8.0.31.jar 檔案複製放到 lib 目錄中。

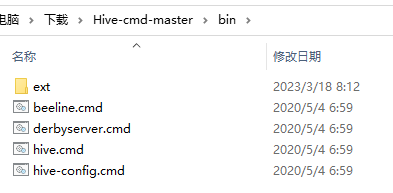
Hive 只做了 Linux 啟動指令碼,官方並沒有支援在 Windows 下執行,因此,必須自己新增 Windows Hive 執行指令碼和檔案。
解壓前面從 https://github.com/HadiFadl/Hive-cmd 下載的檔案,將 Hive-cmd-master/bin 目錄下的所有檔案和目錄複製到 Hive 中的 bin 目錄下。

設定 Hive
開啟 Hive 的 conf 目錄。
複製四個模板檔案,並修改為新的名稱:
如果已經存在新名稱的檔案,則直接編輯即可。
如果沒有找到對應的模板檔案,直接建立新的名稱檔案即可。
| 原名稱 | 新的名稱 |
|---|---|
| hive-default.xml.template | hive-site.xml |
| hive-env.sh.template | hive-env.sh |
| hive-exec-log4j2.properties.template | hive-exec-log4j2.properties |
| hive-log4j2.properties.template | hive-log4j2.properties |
hive-env.sh
新增三行:
HADOOP_HOME=E:\hadoop-3.3.4
export HIVE_CONF_DIR=E:\apache-hive-3.1.3-bin\conf
export HIVE_AUX_JARS_PATH=E:\apache-hive-3.1.3-bin\lib
需要修改 Hive 目錄地址。
如果檔案不存在,直接建立並新增三行內容即可。
hive-site.xml
這個檔案要修改的地方太多,而且這個檔案有幾千行,所以修改的時候需要注意別改錯,查詢的時候要複製名稱直接搜尋。
筆者下面給出了 <property> ... </property> 標籤,讀者替換的時候,只需要替換 <value> ... </value> 中的內容即可,並不需要將整個內容替換過去。
首先在 Hive 目錄下建立一個 data 目錄。
找到 hive.exec.local.scratchdir,替換目錄地址。你需要在 data 目錄下新建一個 scratch_dir 目錄。
<property>
<name>hive.exec.local.scratchdir</name>
<value>E:/apache-hive-3.1.3-bin/data/scratch_dir</value>
<description>Local scratch space for Hive jobs</description>
</property>
替換
E:/apache-hive-3.1.3-bin/data/scratch_dir為實際的目錄。
找到 hive.downloaded.resources.dir,替換目錄地址。你需要在 data 目錄下新建一個 resources_dir 目錄。
<property>
<name>hive.downloaded.resources.dir</name>
<value>E:/apache-hive-3.1.3-bin/data/resources_dir</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
找到 hive.querylog.location,替換目錄地址。你需要在 data 目錄下新建一個 querylog 目錄。
<property>
<name>hive.querylog.location</name>
<value>E:/apache-hive-3.1.3-bin/data/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
找到 hive.server2.logging.operation.log.location,替換目錄地址。你需要在 data 目錄下新建一個 operation_logs 目錄。
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>E:/apache-hive-3.1.3-bin/data/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
接著,需要修改 Hive 預設連線的儲存後設資料的資料庫。
找到 javax.jdo.option.ConnectionDriverName,替換其值為 com.mysql.jdbc.Driver,表示使用 Mysql 驅動連線資料庫。
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
找到 javax.jdo.option.ConnectionURL,替換其資料庫連線字串:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
替換為
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true。
找到 javax.jdo.option.ConnectionUserName,替換其中的值為連線資料庫的使用者名稱,預設為 root。
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
找到 javax.jdo.option.ConnectionPassword,替換值為資料庫密碼。
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
執行 Hive
前面提到,Hive 需要儲存後設資料,其依賴於一個名為 Metastore 的元件。在上一個小節中,我們已經在 hive-site.xml 設定好了 Mysql,現在我們可以先啟動 Metastore。
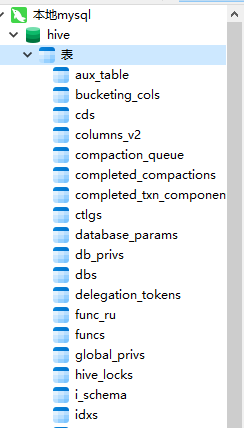
hive --service metastore
順利的話,過一段時間後,可以在 Mysql 看到被寫入了很多表:
接著,再啟動一個 powershell 或 cmd 終端,執行 hive 命令。
啟動之後,就可以輸入命令。

你可以執行命令建立資料庫,命令完成後,可以在 Hadoop 中看到變化。
create table userinfo(id int, name string, age int);
然後開啟:http://localhost:50070/explorer.html
可以看到新建的表。
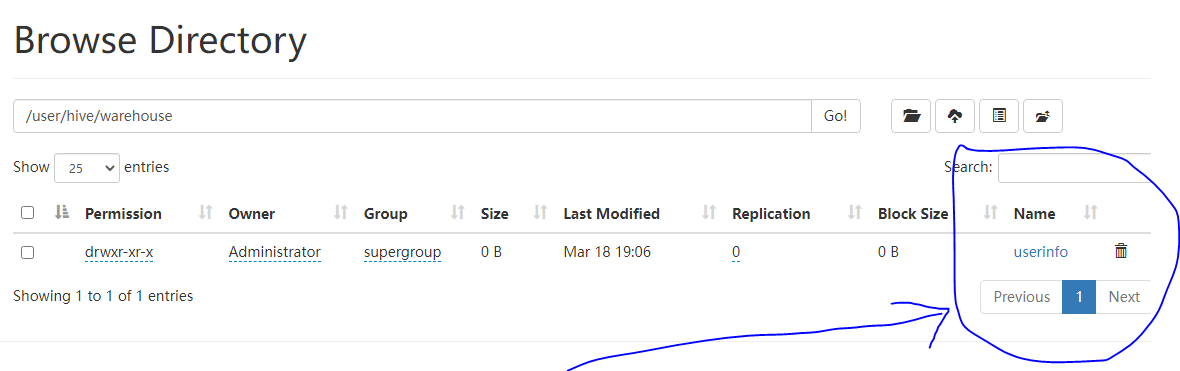
經過以上步驟,即可將 Hadoop、Hive 跑起來。
連線到 Hive
DBeaver 為開發人員、資料庫管理員、分析人員和所有需要使用資料庫的人提供免費的多平臺資料庫工具,功能強大,支援 Hive,在本節中將會使用 DBeaver 連線到 Hive 中。
DBeaver 下載地址:https://dbeaver.io/download/
下載完成之後直接安裝即可。
為了可以使用資料庫連線工具連線到 Hive 執行命令,需要啟動 hiveserver2 服務。
執行命令:
hive --service hiveserver2
開啟 webui: http://localhost:10002/

為了能夠通過通過連線到 Hive 執行命令,需要先到 Hadoop 設定允許其它使用者執行命令。
否則會報這個錯誤:

接著,停止 Hadoop(關閉四個視窗)、停止 hiveserver2,然後複製下面的設定到 Hadoop 的 etc/hadoop/core.site.xml 中。
<property>
<name>hadoop.proxyuser.Administrator.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.Administrator.groups</name>
<value>*</value>
</property>
請替換裡面的 Administrator 為你當前使用者的使用者名稱。
修改後的完整設定:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.proxyuser.Administrator.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.Administrator.groups</name>
<value>*</value>
</property>
</configuration>
然後再點選 start-all.cmd,恢復 Hadoop 服務。
重新執行 hive --service metastore、 hive --service hiveserver2。
接著檢視 Hive 目錄下的 hive-site.xml,找到 hive.server2.thrift.client.user,裡面記錄了 hiveserver2 進行登入的使用者名稱和密碼,預設都是 anonymous。
<property>
<name>hive.server2.thrift.client.user</name>
<value>anonymous</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>anonymous</value>
<description>Password to use against thrift client</description>
</property>
然後設定 DBeaver,在使用者名稱和密碼中輸入 anonymous。
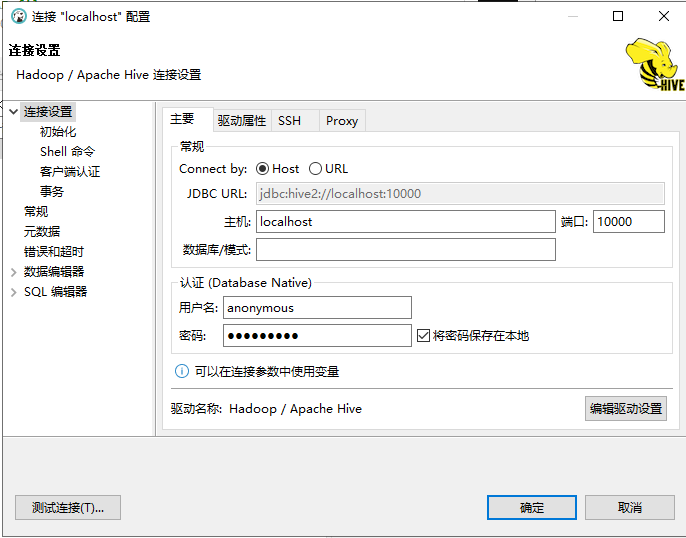
然後點選 」編輯驅動設定「。
把裡面原有的記錄都刪除掉,然後點選 」新增檔案「,使用 Hive 中最新的驅動。

這個驅動檔案在 Hive 的 jdbc 目錄中。
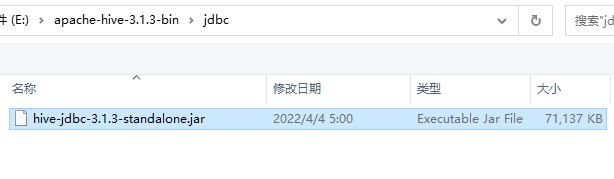
新增完成後,測試連線到 Hive。
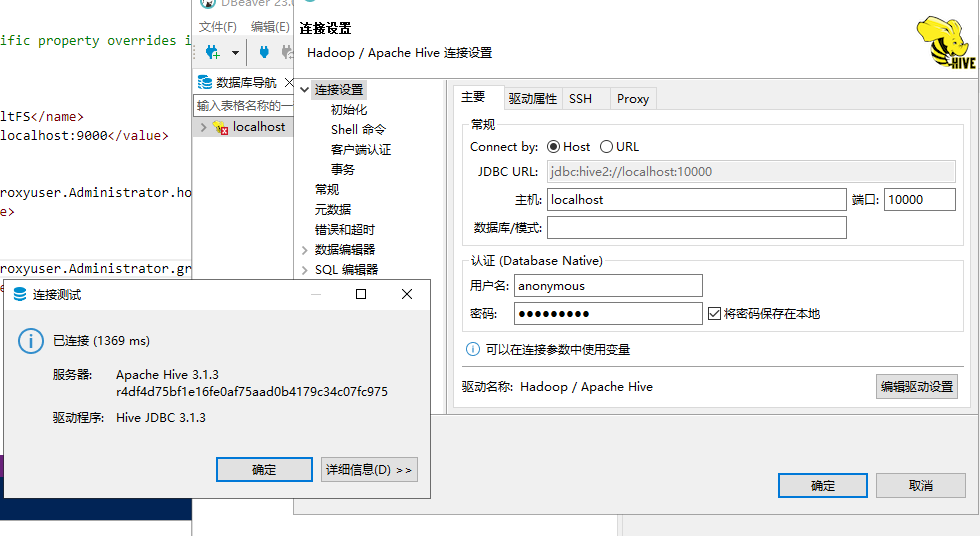
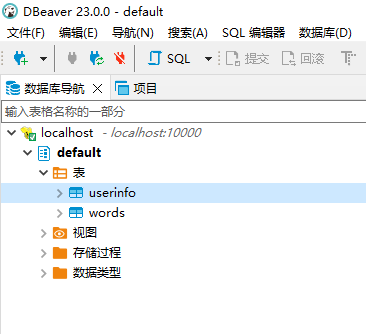
至此,可以愉快地學習 Hive 啦!