一文讀懂儲存過程
0 導讀
經常聽別人說,「呼叫一個儲存過程「,「把處理過程改寫為儲存過程之後就快了」此類的話,本篇文章我們來聊一聊儲存過程。將從以下幾個方面去描述儲存過程。
1 儲存過程解決了什麼樣的問題?

我們看這樣一個場景:假設使用者現在正在進行下單操作,那你的資料庫需要做這些事。
1)核對保證庫存中有對應的商品。
2)如果有商品,那商品需要預定防止賣給別人,並且要減少可用的商品數量 以反應正確的庫存量。
3)庫存中沒有的商品需要訂購,這需要與供應商進行某種互動。
4)關於那些物品入庫和哪些物品退訂,需要通知到對應的客戶。
之前我們接觸的場景都是單條的SQL語句,現在這種場景也可以使用一條一條的SQL去處理,但是如果一條一條的SQL去處理,每次需要重新寫語句,還得保證不寫錯。那麼儲存過程這個時候就誕生了。
儲存過程簡單來說,就是為以後的使用而儲存的一條或多條SQL的集合,通過把零散的處理封裝到一個單元中,簡化複雜的操作。由於不要求反覆建立一系列的處理步驟,這裡保證了開發人員和應用系統使用的是同樣的一段程式碼,保障了資料的完整性。簡化對變動的管理,如果業務或者表名列名改變,只需要去修改儲存過程即可,呼叫者無需知道具體實現。
每個技術的誕生解決了問題,但是也帶來了缺點。
2 儲存過程的優缺點是什麼?
先講優點:
提高效能:因為儲存過程只需要編譯一次,而我們單獨的SQL語句每次執行前都需要編譯,所以儲存過程比SQL要快。
使用儲存過程寫的程式碼更加的靈活。
再談一談缺點:
一般來說,儲存過程比單獨的SQL要複雜,這就需要有經驗的老開發來編寫。而且很多時候可能還沒有建立儲存過程的許可權,許多資料庫管理員允許呼叫,但是不準建立,因為維護的成本比較高。
3 應用場景有哪些?
儲存過程內部包含業務規則和智慧處理時,他的威力才能真正的顯示出來。
對查詢出來的訂單進行加稅處理,這時候用儲存過程是比較好的處理方式。
總之在資料量大,計算複雜的場景,就可以考慮是否可以用儲存過程來解決。
4 儲存過程有哪些組成部分?
首先看建立的語句
create procedure readdata() begin select AVG(read_count) AS readaverage from blog; end;
這裡得注意如果是MySQL需要重定義分隔符,因為mysql預設結束符是「;」,如果按照上面的語句,MySQL以為到from blog;這裡儲存過程就結束了,不完整。MySQL中正確的定義如下:
delimiter // create procedure readdata() begin select AVG(read_count) AS readaverage from blog; end // delimiter ;
這裡需要注意delimiter後面是要空一格,否則執行失敗。
其次看一下呼叫,只需使用call即可:
call readdata();
刪除儲存過程:
drop procedure readdata;
這裡只需要給出名字即可刪除。
注:儲存過程還可以攜帶引數,這裡只是介紹簡單的原理,具體使用需要自己去查。
5 底層原理是怎樣的?
create之後資料庫做了什麼?call呼叫的時候又是怎樣找到的?
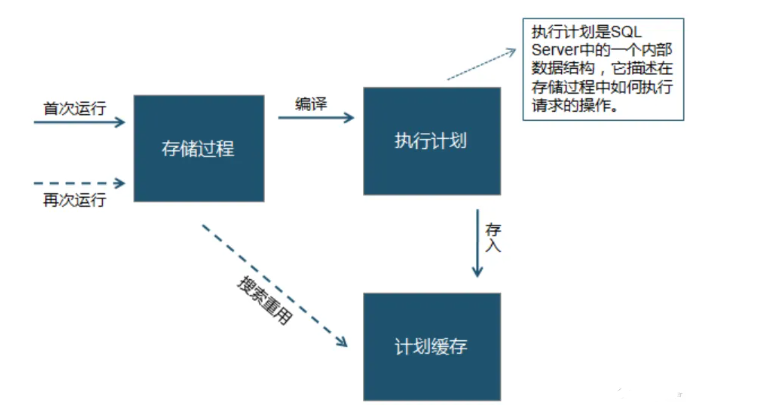
建立一個儲存過程 (procedure) 時,資料庫底層會將其編譯成一個可執行的二進位制程式碼,以便在需要執行該儲存過程時能夠直接呼叫該程式碼,而無需重新解析 SQL 查詢語句。這有助於提高執行速度,降低資料庫伺服器的負載。
在儲存過程被編譯時,資料庫會執行以下步驟:
- 語法檢查:資料庫會檢查儲存過程的語法是否正確,如果存在語法錯誤則會報錯。
- 語意分析:資料庫會檢查儲存過程中所參照的表、檢視、函數等物件是否存在,並檢查引數的資料型別是否正確。
- 優化:資料庫會對儲存過程進行優化,以便在執行時能夠儘可能地提高執行效率。
- 生成可執行程式碼:資料庫會將儲存過程轉換成可執行的二進位制程式碼,並將其儲存在系統表中,以便在需要執行該儲存過程時能夠直接呼叫。
- 快取可執行程式碼:資料庫會將生成的可執行程式碼快取到記憶體中,以便在需要執行該儲存過程時能夠快速地呼叫。
當呼叫儲存過程 (procedure) 時,資料庫會執行以下步驟:
- 檢查許可權:資料庫會檢查當前使用者是否有執行該儲存過程的許可權,如果沒有則會拒絕執行。
- 載入可執行程式碼:資料庫會從系統表中載入該儲存過程的可執行程式碼,並將其快取到記憶體中。
- 解析引數:如果儲存過程有引數,則資料庫會解析傳入的引數,並將其傳遞給儲存過程。
- 執行儲存過程:資料庫會執行儲存過程中的程式碼,並根據程式碼的邏輯執行相應的操作,如查詢、插入、更新或刪除資料等。
- 返回結果:儲存過程執行完成後,資料庫會將執行結果返回給呼叫者。
總之,呼叫儲存過程可以讓資料庫執行預定義的邏輯操作,避免了每次執行一組 SQL 語句的開銷。資料庫會載入儲存過程的可執行程式碼,並解析傳入的引數,執行儲存過程中的程式碼並返回執行結果,從而提高了執行效率和效能。
