解放AI生產力——為什麼要使用ComfyUI
最近狀態不好,所以這幾天基本沒幹什麼,就分享一下和AI繪畫有關的東西吧。
此前我都沒有抱著一種教學的心態來寫部落格,因為我所掌握的東西實在太過簡單,只要一說大家就會了,我害怕我在人群裡失去自己的特徵,但不得不承認,這是一種很醜陋的心態,重要的是我否定了自己所學的東西,如果不願承認現在的軟弱,我就始終看不清我走到了一個什麼樣的位置上。
學過3D建模的應該都知道,3D建模軟體裡面都有一套類似於這種的東西:
上面我所展示的,就是今天介紹的重點:AI繪畫的工作流,不知道的兄弟也沒關係,這東西用起來很簡單。
但在介紹怎麼使用它之前,我先介紹一下它相比於原來的工作優點。
各位請看,這是我原來的UI:

原來的UI用起來很簡單,輸入正面提示詞和負面提示詞後點選生成之後,就會生成圖片,這也是一開始就有的生成方式。
但點選生成之後,電腦的內部並不像我們使用起來那麼簡單:
在載入了這個UI之後,電腦會首先讀取你原先設定好的模型,就是我們左上角看見的anything,並且這個模型型別被限定,隨著某個日本大神發明的簡易訓練模型lora誕生,越來越多的私人模型誕生,但左上角這個我試了一下,好像沒辦法讀入私人模型,也可能是因為我的電腦沒有N卡的問題,而能否使用私人模型,對於流水線式的生產圖片很關鍵
在你點選生成之後,電腦會通過你設定的取樣器進行取樣,取樣生成出來的圖片會再次經過vae的處理,如果你的圖片生成出來偏灰,可以載入一下vae試試。
這樣的生產方式面臨兩個問題:
1.有些東西你很難用文字表達清楚,比如坐著,腳放在前面。Ai並不知道坐著是什麼意思,也不知道腳放在前面是什麼意思,但是它會模仿模型裡它已經學習過的坐著,腳放在前面的圖片來生成一個差不多的給你,問題來了,你怎麼知道AI模型裡它模仿的圖片是什麼樣的?和你不一樣的時候要怎麼辦,萬一這個動作它根本沒學過呢?
為了解決的這個問題,斯坦福的某個天才發明了controlnet,它可以通過不同的預處理方式,來控制圖片的構成,這裡貼上連結,想要細看的看官可以去看一下:https://github.com/Mikubill/sd-webui-controlnet
不想點連結的也沒事,我會放出圖片:
這是一張用3D建模做的圖片:
利用canny預處理,這張圖片可以變成這樣:
在這個外掛面世之前,AI生成圖片從來都是隨機的,比如這兩張:

如果不是我人為的控制了它,這個AI可以放縱得更離譜。
通過上面兩個例子的對比各位可以發現,controlnet展現了驚人的圖片控制能力,而不需要人為的控制AI,限制AI發揮的強度,更厲害的是controlnet不止有canny預處理這樣將影象退化為線稿再處理的預處理方式,它也可以只控制人物的姿勢,而不控制影象的其他任何部分,只保留產品和建築物的結構,對產品和建築物進行重新裝修也不再話下,配合文字,可以變成任何你想要的圖片。
說了這麼多,其實我想說,控制AI一直是AI繪畫愛好者的心頭病。
也是面臨的第一個問題:AI生成出來的東西不可控,單單controlnet的發明,在AI繪畫圈內就引起了巨大的轟動,但這終究只能控制影象的冰山一角,想要將AI的生產力解放出來,這還不夠。
舉一個很恰當的例子:我要開一個方便麵廠,我生產紅燒牛肉麵的時候你不能給我香辣牛肉麵,不然我還要人為地在生產完成後給你分出來,浪費時間浪費金錢,而且我不能只有一條流水線,我還得有另一條流水線生產香辣牛肉麵,不能兩種面混合著生產,不然你就要人為地調整流水線的生產,費時費力。
但是很不巧的是,這個繪畫AI一開始的UI把這兩個缺點全佔了,我們先不從動畫說起,就以遊戲業內最簡單的圖片CG說起:
一個正常的遊戲CG的人物表情是有好幾種變化的,其背後的景物是不能變,為了解決這個問題,我需要讓AI做到景物不變人變,但其實這很難做到。
可能有一些知道AI繪畫的人會說利用圖生圖降低噪聲強度,減少修改的範圍,只修改你要修改的部分就行了,(或者使用蒙版,意思是一樣的)在這裡我可以和你說,在關於這個方法的視訊發出來的幾個月前我就試出來了這種方法,我可能也是最先放棄它的人。

這是我當時的記錄,時間去年11月,這個方法第一個視訊我沒記錯的話是1月才看見有第一個人發。
我不是說我是第一個發現它的人,而是想說,在評價這個方法的缺點的時候,我應該比你更有發言權。
這個方法屬於治標不治本,本質上你還是在讓AI隨機抽卡,而且你修改的範圍再大一點你就會發現,我靠,兩個部分的色塊完全不一樣啊。(甚至有可能人都不一樣,如果你是個小白的話)
或許也有人會說,如果AI不能生成只變化圖片的部分的話,那我多生成幾張CG,多良心啊。
大哥,cg的動作,場景細節,光照角度,視角都是要設計的,繪畫本身是一門藝術,應該要告訴玩家某種感覺,只是排放一堆圖片給觀眾的話,觀眾容易審美疲勞,誰還會注意你的音樂,圖片的細節啊。像這種東西建議稱為AI垃圾,和那種口水歌差不多。
這樣的話就更容易出現一個問題了,如果我連場景細節,光照角度都要管,那對AI的控制不是更難了嗎?
何止,你不僅要管控制,你還要管AI繪畫的第二個問題:崩壞:
相信大家都或多或少聽說過AI畫手的問題吧?
為了避免有些人要睡著了,我先炫一下技:
這是別人的AI畫手:
這是我的AI畫手:
(可能有人感覺我是用momoke模型控制的,我可以保證說不是,不信你可以拿我的圖片放進你的AI裡讀取資訊)
在對SDUI的使用方面來說,我可以說我比得過一半的人,即便如此,我依然放棄了它選擇了ComfyUI,為什麼?
AI繪畫會出現這兩個問題,原因很簡單,因為這個畫不是我們畫的,而是AI畫的,畫的過程我們是控制不了的,我們能做的只有點一下生成。
是的,大家應該猜到問題出在哪裡了————點一下生成。
我上面說SDUI把兩個缺點全佔了:這裡我們重點說說是哪兩個缺點:
1.我們只能輸入一次,雖然SDUI支援不斷地生成,但除非你人為地去改,否則輸入的內容都是一樣的,AI根據我們的提示輸出的也不會差太多,就好像我們只有一條流水線,只能生產紅燒牛肉麵一樣,但ComfyUI可以有多條流水線。
2.SDUI裡面人物和環境是一起預處理的,哪怕是controlnet也一樣,這種感覺就好像你生產的一包紅燒牛肉麵混進了香辣牛肉麵的醬包,但ComfyUI可以分開處理:
這是原圖:
接著我跟我的AI強調了不需要背景,背景接著白色就可以了,但這是效果:

我連手都能控制,卻不能控制背景,因為SDUI並沒有給我分開處理的機會,但ComfyUI給了我這個機會,剛才的測試也成功了。

我明白要說明ComfyUI的優點應該也說明一下它的工作方式,可是已經快四千字了(好累),我就簡短的說明一下,詳細的下次再說或者這裡有:https://github.com/comfyanonymous/ComfyUI
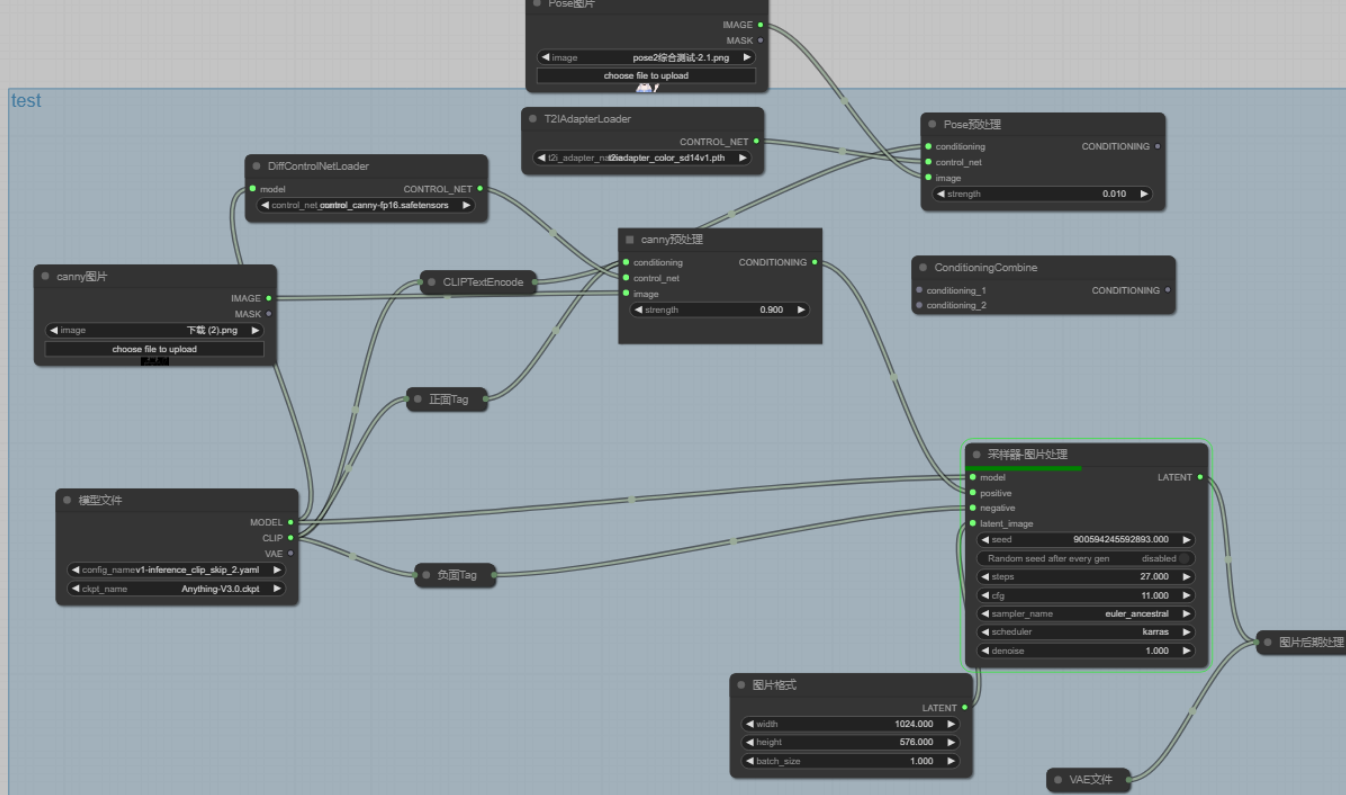
相比於SDUI,ComfyUI的生成方式並不是點一下滑鼠就好了,你需要用節點的方式輸入模型,外掛(如果你要使用的話),正面和負面的提示詞,圖片格式,vae,然後用線把它們連線起來,就像這樣:

在這個UI中,你每一次的生成並不只是生成一張圖片,而是每一個應該輸出圖片的節點都會輸出圖片,對於同樣一份輸入資料,你可以用線把它連到不同的節點,用不同的外掛和強度處理,然後生成圖片輸入下一個節點或者就這樣輸出,它就像有好幾條流水線在同時工作,並且你可以通過許多模型控制一張圖片,這在ComfyUI裡面時允許,前面提到了lora,你可以使用多個自己訓練的小模型來同時控制圖片,增強你對AI的控制。
綜上,ComfyUI相比於SDUI,它可以使用多個流水線工作,用不同的處理方式處理多個不同的圖片,輸出不同的圖片,如果工作量很大,你只需要調整後節點然後出去玩一整天,而不用像SDUI一樣坐在電腦前這張跑完了,換個輸入資料換個處理方式再跑另一張。
同時,它也支援多個模型和外掛(包括controlnet),輸入資料同時控制一張圖片,滿足你對視角,動作,場景細節的要求,甚至得益於它的高效率和搞控制能力,許多AI動畫愛好者狂喜,儘管這些人數量不多,因為要做到這些,需要和我差不多的對AI的控制能力,基本沒人會研究的。(所以在ComfyUI面世時,很多大佬都在狂喜,但卻有很多聲音覺得AI退化了,不會畫畫,又不去學,只會讓AI畫,又懶得鑽研........)
雖然cComfyUI很厲害,但它其實只是把AI工作的過程透明化了,它的本質還是SDAI,我也一直很感謝SDai。