有監督學習——高斯過程
1. 高斯過程
高斯過程(Gaussian Process)是一種假設訓練資料來自無限空間且各特徵都符合高斯分佈(高斯分佈又稱「正態分佈」)的有監督學習。
高斯過程是一種概率模型,在迴歸或分類預測都以高斯分佈標準差的方式給出預測置信區間估計。
隨機過程
高斯過程應用於機器學習已有數十年曆史,,它來源於數學中的隨機過程(Stochastic Process)理論。隨機過程是研究一組無限個隨機變數內在規律的學科。
如果把每次取樣的目標值\(y\)都看成一個隨機變數,那麼單條取樣就是一個隨機分佈事件的結果,\(N\)條資料就是多個隨機分佈取樣的結果,而整個被學習空間就是無數個隨機變數構成的隨機過程了。
Q: 為何將取樣看成隨機變數?
A: 一、所有資料的產生就是隨機的;二、資料的採集有噪聲存在。因此不可能給出精確值的預測,更合理的是給出一個置信區間。
無限維高斯分佈
高斯分佈或者說正態分佈的特點:
- 可標準化:一個高斯分佈可由均值\(\mu\)和標準差\(\sigma\)唯一確定,用符號\(\sim N(\mu,\sigma)\)表示。並且任意高斯分佈可以轉化用\(\mu=0\)和\(\sigma=1\)標準正態分佈表達。
- 方便統計:高斯分佈約67.27%的樣本落在\((\mu-\sigma,\mu+\sigma)\),約95%的樣本落在\((\mu-2\sigma,\mu+2\sigma)\),約99%的樣本落在\((\mu-3\sigma,\mu+3\sigma)\)。
- 多元高斯分佈(Multivariate Gaussian):\(n\)元高斯分佈描述\(n\)個隨機變數的聯合概率分佈,由均值向量\(<\mu_1,\mu_2,\cdots\mu_n>\)和協方差矩陣\(\sum\)唯一確定。其中\(\sum\)是一個\(n\times n\)的矩陣,每個矩陣元素描述\(n\)個隨機變數兩兩間的協方差。
協方差(Covariance)用於衡量兩個變數的總體誤差。度量各個維度偏離其均值的程度。協方差的值如果為正值,則說明兩者是正相關的(從協方差可以引出「相關係數」的定義),結果為負值就說明負相關的,如果為0,也是就是統計上說的「相互獨立」。方差就是協方差的一種特殊形式,當兩個變數相同時,協方差就是方差了。協方差公式如下:
\(E\)為期望;\(X\)、\(Y\) 為兩個變數;\(\mu_x\)、\(\mu_y\)分別代表\(X\)、\(Y\)均值。
期望值不等於平均值。期望值是衡量一個隨機變數的中心趨勢的加權平均數,是計算該變數的所有可能值,其中權重是每個值發生的概率。均值是一種特定型別的期望值,計算方法為變數的所有值除以值的總數之和。因此,雖然平均值是計算期望值的一種方法,但它不是唯一的方法,而且這兩個術語是不可互換的。
- 和與差:設有任意兩個獨立的高斯分佈\(U\)和\(V\),那麼它們的和\(U+V\)一定是高斯分佈,它們的差\(U-V\)也一定是高斯分佈。
- 部分與整體:多分高斯分佈的條件分佈任然是多元高斯分佈,也可理解為多元高斯分佈的子集也是多元高斯分佈。
上文說過:高斯過程可被看成無限維的多元高斯分佈,那麼機器學習的訓練過程目標就是學習該無限維高斯分佈的子集,也就是多元高斯分佈的引數:均值向量\(<\mu_1,\mu_2,\cdots\mu_n>\)和協方差矩陣\(\sum\)。
協方差矩陣的元素表徵兩兩元素之間的協方差,如果用核函數計算兩者,便使得多元高斯分佈也具有表徵高維空間樣本之間關係的能力。此時協方差矩陣可表示為:
其中\(K_{XX}\)表示樣本資料特徵集\(X\)的核函數矩陣;\(k()\)表示所選核函數;\(x_1,x_2,\cdots x_n\)等是單個樣本特徵向量。同\(SVM\)一樣,此處核函數需要指定形式,常用的包括:徑向基核、多項式核、線性核等。在訓練過程中可以定義演演算法自動尋找核的最佳超引數。
設樣本目標值\(Y\),被預測的變數\(Y_*\),由高斯分佈的特型可知,由訓練資料與被預測資料組成的隨機變數集合仍然符合多元高斯分佈,即:
其中\(u_*\)是代求變數\(Y_*\)的均值,\(K_{X_*X}\)是樣本資料與預測資料特徵的協方差矩陣,\(K_{X_*X_*}\)是預測資料特徵的協方差矩陣。
由完美多元高斯特型可知\(Y_*\)滿足高斯分佈\(N(u_*,\sum)\),可直接用公式求得該分佈的超引數,即預測值的期望值和方差:
與其他機器學習模型不同的是:高斯過程在預測中仍然需要原始訓練資料,這導致該方法在高維特徵和超多訓練樣本的場景下顯得運算效率低,但因此高斯過程才能提供其他模型不具備的基於概率分佈的預測。
對於白噪聲的處理,就是在計算訓練資料協方差矩陣\(K_{XX}\)的對角元素上增加噪聲分量。因此協方差矩陣變為如下形似:
其中,\(\alpha\)是模型訓練者需要定義的噪聲估計引數。該值越大,模型抗噪聲能力越強,但容易產生擬合不足。
在機器學習中,噪聲是指真實標記與資料集中的實際標記間的偏差1,也就是資料本身的不確定性或隨機性。白噪聲是一種特殊的噪聲,它具有以下特點:
- 白噪聲是獨立同分布的,也就是說每個樣本的噪聲都是相互獨立且服從同一分佈的。
- 白噪聲的均值為零,也就是說每個樣本的噪聲都不會對真實標記產生系統性的偏移。
- 白噪聲的方差為常數,也就是說每個樣本的噪聲都具有相同的波動程度。
- 白噪聲和其他型別的噪聲相比,更容易處理和分析,因為它不會引入額外的複雜性或相關性。
Python中使用高斯模型
在sklearn.gaussian_process.kernels中以類的方式提供了若干核函數,常用的如下表:
| 核函數 | 描述 |
|---|---|
| ConstantKernels | 常數核,對所有特徵向量返回相同的值,即模型忽略了特徵資料資訊。 |
| DotProduct | 點積核,返回特徵向量點積,也就是線性核。 |
| RBF | 徑向基核,把特徵向量提升到無限維以解決非線性問題。 |
此外,使用如下類,還允許不同核之間進行組合
| 組合核 | 描述 |
|---|---|
| Sum(k1,k2) | 用兩個核分別計算後將模型相加 |
| Product(k1,k2) | 兩個核分別運算後,結果相乘 |
| Exponentiation(k,exponent) | 返回核函數結果的指數運算結果,即\(k^{exponent}\) |
GaussianProcessRegressor與GaussianProcessClassifier分別表示python中的高斯過程迴歸模型和高斯過程分類模型。
與其他模型不同的是:它們的預測函數predict()有兩個返回值,第一個為預測期望值,第二個為預測標準差。此外,以下為幾個高斯過程特有的初始化引數:
| 引數 | 描述 |
|---|---|
| kernel | 核函數物件,即sklearn.gaussian_process.kernels中類的範例。 |
| alpha | 為了考慮樣本噪聲在協方差矩陣對角量增加值,可為數值(應用在所有對角線元素),也可以是一個向量(分別應用在每個對角元素上)。 |
| optimizer | 可以是一個函數,用於訓練過程中優化核函數超引數 |
| n_restarts_optimizer | optimizer被呼叫的次數,預設為1 |
以下是對一個非線性函數\(y=x\times sin(x)-x\)的訓練預測。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF
from sklearn.gaussian_process.kernels import Product
from sklearn.gaussian_process.kernels import ConstantKernel as C
def f(X): # 原函數
return X * np.sin(X) - X
X = np.linspace(0, 10, 20).reshape(-1, 1) # 訓練20個訓練樣本
y = np.squeeze(f(X) + np.random.normal(0, 0.5, X.shape[1])) # 樣本目標值,並加入噪聲
x = np.linspace(0, 10, 200) # 測試樣本特徵值
# 定義兩個核函數,並取它們的積
kernel = Product(C(0.1), RBF(10, (1e-2, 1e2)))
# 初始化模型:傳入核函數物件、優化次數、噪聲超引數
gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=3, alpha=0.3)
gp.fit(X, y) # 訓練
y_pred, sigma = gp.predict(x.reshape(-1, 1), return_std=True) # 預測
fig = plt.figure() # matplotlib進行繪圖
plt.plot(x, f(x), 'r:', label=u'$f(x) = x\,\sin(x)-x$')
plt.plot(X, y, 'r.', markersize=10, label=u'Observations')
plt.plot(x, y_pred, 'b-', label=u'Prediction')
# 填充(u-2σ,u+2σ)的置信區間
plt.fill_between(
np.concatenate([x, x[::-1]]),
np.concatenate([y_pred-2*sigma, (y_pred+2*sigma)[::-1]]),
alpha=0.3,
fc='b',
label=r"95% confidence interval"
)
plt.legend(loc='lower left')
plt.show()
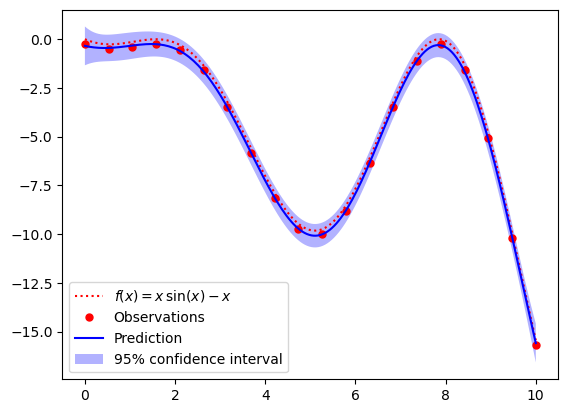
可以看到整體測試樣本的真實虛線與測試的實線基本一致,即使有偏差但都在95%的置信區間內。
參考文獻
[1]劉長龍. 從機器學習到深度學習[M]. 1. 電子工業出版社, 2019.3.