kafka的原理及叢集部署詳解
訊息佇列概述
訊息佇列分類
對等
-
組成:訊息佇列(Queue)、傳送者(Sender)、接收者(Receiver)
-
特點:一個生產者生產的訊息只能被一個接受者接收,訊息一旦被消費,訊息就不在訊息佇列中了
釋出/訂閱
-
組成:訊息佇列(Queue)、釋出者(Publisher)、訂閱者(Subscriber)、主題(Topic)
-
特點:每個訊息可以有多個消費者,彼此互不影響,即釋出到訊息佇列的訊息能被多個接受者(訂閱者)接收
-
ActiveMQ: 歷史悠久,支援性較好,效能相對不高
-
RabbitMQ: 可靠性高、安全
-
Kafka: 分散式、高效能、高吞吐量、跨語言
-
RocketMQ: 阿里開源的訊息中介軟體,純Java實現
kafka架構
kafka介紹
Kafka是一個分散式的釋出/訂閱訊息系統,最初由LinkedIn(領英)公司釋出,使用Scala語言編寫,後成為Apache的頂級專案。
kafka主要用於處理活躍的資料,如登入、瀏覽、點選、分享等使用者行為產生的資料。
kafka架構組成
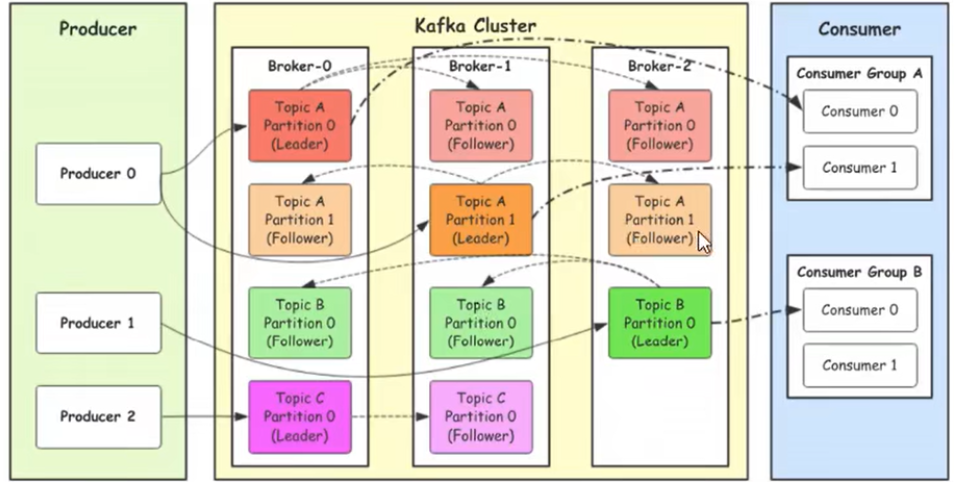
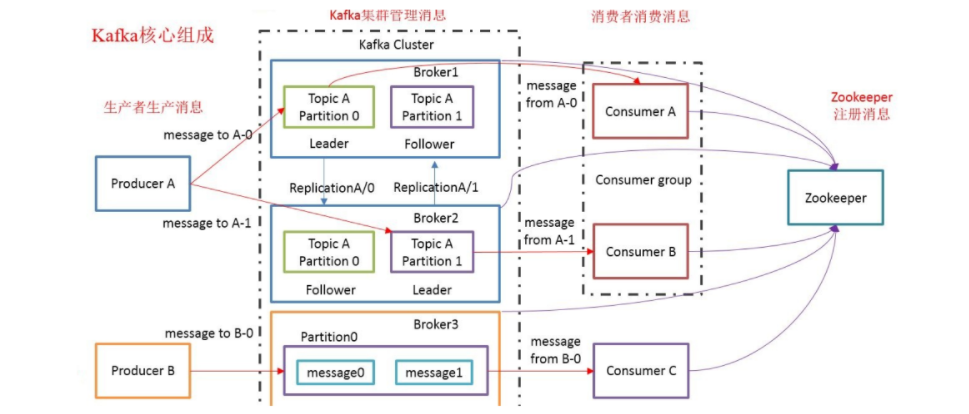
Broker
-
broker表示kafka的節點,kafka叢集包含多個kafka服務節點,每個kafka服務節點就稱為一個broker
Topic
-
主題,用來儲存不同類別的訊息(kafka的訊息資料是分主題儲存在硬碟上的)
-
儲存訊息時,需要指定儲存在哪個主題下面,如發帖,發哪種型別的
Partition
-
分割區,每個topic包含一個或多個partition,在建立topic時指定包含的partition資料(目的是為了進行分散式儲存)
-
分割區可以提高負載(每個分割區是不同的磁碟,所以會提高負載)
Replication
-
副本,每個partition分割區可以有多個副本,分佈在不同的Broker上
-
kafka會選出一個副本作為Leader,所有的讀寫請求都會通過Leader完成,Follower只負責備份資料
-
所有Follower會自動從Leader中複製資料,當Leader宕機後,會從Follower中選出一個新的Leader繼續提供服務,實現故障自動轉移
Message
-
訊息,是通訊資料的基本單位,每個訊息都屬於一個Partition,訊息都是放在Partition裡面的
Producer
-
訊息的生產者,向kafka的一個topic釋出訊息,釋出訊息時,需要指定釋出到哪個topic主題
Consumer
-
訊息的消費者,訂閱Topic並讀取其釋出的訊息,消費或訂閱哪個topic主題裡的訊息,可以訂閱多個主題的訊息(類似訂閱多個微信公眾號)
Consumer Group
-
消費者組,每個Consumer屬於一個特定的Consumer Group,多個Consumer可以屬於同一個Consumer Group
-
各個consumer可以組成一個組,每個訊息只能被組中的一個consumer消費,如果一個訊息可以被多個consumer消費的話,那麼這些consumer必須在不同的組。
ZooKeeper
-
協調Kafka的正常執行,kafka將後設資料資訊儲存在ZooKeeper中,但傳送給Topic本身的訊息資料並不儲存在ZK中,而是儲存在磁碟檔案中
-
後設資料資訊包括:kafka有多少個節點、有哪些主題,主題叫什麼,有哪些分割區的等(訊息自身的資料不在ZK中,而是在磁碟上對應的分割區中)
kafka的工作流程
生產者向kafka傳送資料的流程(六步)
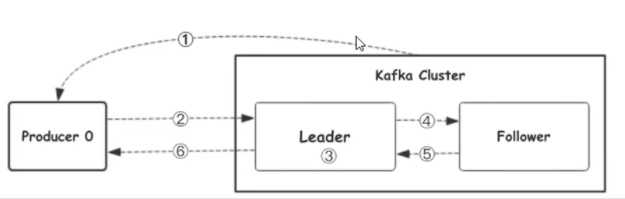
一共六步:
-
生產者查詢Leader:producer先從zookeeper的「/brokers/.../state」節點找到該partition的leader
-
找到Leader之後往Leader寫資料:producer將訊息傳送給該leader
-
Leader落盤:leader將訊息寫入本地log
-
Leader通知Follower
-
Follower從Leader中拉取資料:replication寫入到Follower的本地log後,follower向leader傳送ack
-
Kafka向生產者回應ACK:leader收到所有的replication的ack之後,向producer傳送ack
Kafka選擇分割區的模式(三種)
-
直接指定往哪個分割區寫
-
指定key,然後kafka根據key做hash後決定寫哪個分割區
-
各個分割區輪詢
生產者往kafka傳送資料的模式(三種)
-
把資料傳送給Leader就認為成功,效率最高,安全性低
-
把資料傳送給Leader,等待Leader回覆Ack後則認為傳送成功
-
把資料傳送給Leader,確保Follower從Leader拉取資料回覆Ack給Leader,Leader再向生產者回復Ack才認為傳送成功,安全性最高
資料消費
多個消費者可以組成一個消費者組,並用一個標籤來標識這個消費者組(一個消費者範例可以執行在不同的程序甚至不同的伺服器上)
-
如果所有的消費者範例都在同一個消費者組中,那麼訊息記錄會被很好的均衡傳送到每個消費者範例
-
如果所有的消費者範例都在不同的消費者組,那麼每一條訊息記錄會被廣播到每一個消費者範例
各個consumer可以組成一個組,每個訊息只能被組中的一個consumer消費,如果一個訊息可以被多個consumer消費的話,那麼這些consumer必須在不同的組
注意:每個消費者範例可以消費多個分割區,但是每一個分割區最多隻能被消費者組中的一個範例消費
kafka的檔案儲存機制
topic、partition和segment
1)在kafka檔案儲存中,同一個topic下有多個不同的partition:
-
每個partition就是一個目錄,partition的命名規則為:topic名稱+有序序號
-
第一個partition序號從0開始,序號最大值為partition數量減一
2)每個partition的目錄下面會有多組segment檔案:
-
每個partition(目錄)相當於一個巨型大檔案被平均分配到多個大小都相等的segment資料檔案中(但每個segment file訊息數量不一定相等,這種特性方便old segment file快速被刪除)
-
每組segment檔案包含:.index檔案、.log檔案、.timeindex檔案(.log檔案就是實際儲存message的地方,.index和.timeindex檔案為索引檔案,用於檢索訊息)
-
每個partition只需要支援順序讀寫就行了,segment檔案生命週期由伺服器端設定引數決定
-
這樣做能快速刪除無用檔案,有效提高磁碟利用率
3)segment檔案
-
segment檔案由2大部分組成,分別為index file和data file,此2個檔案一一對應,成對出現,字尾".index"和「.log」分別表示為segment索引檔案、資料檔案
-
segment檔案命名規則:partion全域性的第一個segment從0開始,後續每個segment檔名為上一個segment檔案最後一條訊息的offset值。數值最大為64位元long大小,19位數位字元長度,沒有數位用0填充
儲存和查詢message的過程
1)資料寫入過程
每個Partition都是一個有序並且不可改變的訊息記錄集合(每個partition都是一個有序佇列),當新的資料寫入時,就被追加到partition的末尾。
在每個partition中,每條訊息都會被分配一個順序的唯一標識,這個標識被稱為Offset(偏移量),用於partition唯一標識一條訊息。
2)資料查詢過程
在partition中通過offset查詢message:
-
查詢segment file:每一個segment檔名都包含了上一個segment最後一條訊息的offset值,所以只要根據offset二分查詢檔案列表,就能定位到具體segment檔案
-
通過segment file查詢message:當定位到segment檔案後,可以通過對應的.index後設資料檔案,在對應的.log檔案中順序查詢對應的offset,然後即可拿到資料
3)說明:
-
kafka只能保證在同一個partition內部訊息是有序的,在不同的partition之間,並不能保證訊息有序
-
為什麼kafka快:因為它把對磁碟的隨機讀變成了順序讀
kafka安裝部署及操作
kafka單機部署
安裝ZooKeeper
kafka需要依賴ZooKeeper,所以需要先安裝並啟動ZooKeeper,kafka使用zk有兩種方式:
-
使用kafka自帶的ZooKeeper(一般不推薦使用內建的ZooKeeper)
-
單獨搭建ZooKeeper
使用kafka自帶的ZooKeeper:
# kafka的bin目錄中,有自帶的zk的啟動命令
/usr/local/kafka/bin/zookeeper-server-start.sh
# kafka的config目錄中,有自帶的zk的組態檔
/usr/local/kafka/bin/zookeeper.properties
如果要使用kafka內建的ZooKeeper,修改好組態檔 ./config/zookeeper.properties(主要修改zk的data位置和埠),直接啟動即可
# 後臺啟動,並指定組態檔
zookeeper-server-start.sh -daemon ../config/zookeeper.properties
安裝kafka
kafka需要java環境,需要安裝jdk
# 1.安裝jdk
yum install -y java-1.8.0-openjdk
# 2.準備kafka安裝包
tar zxvf kafka_2.11-2.2.0.tgz -C /usr/local/
ln -s /usr/local/kafka_2.11-2.2.0 /usr/local/kafka
mkdir -pv /data/kafka/data/ # 建立kafka資料儲存目錄
# 設定環境變數
sed -i '$aPATH="/usr/local/kafka/bin:$PATH"' /etc/profile
source /etc/profile
# 3.修改kafka組態檔
vim /usr/local/kafka/config/server.properties
listeners=PLAINTEXT://10.0.0.80:9092 # kafka預設監聽埠號為9092,
log.dirs=/data/kafka/data # 指定kafka資料存放目錄
zookeeper.connect=localhost:2181 # 指定ZooKeeper地址,kafka要將後設資料存放到zk中,這裡會在本機啟動一個zk
# 4.啟動kafka
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
# 5.檢視程序及埠
ps -ef | grep kafka
ss -tnl | grep 9092 # kafka監聽在9092埠
kafka指令碼程式及組態檔
幾個kafka的操作指令碼
-
kafka-server-start.sh kafka啟動程式
-
kafka-server-stop.sh kafka停止程式
-
kafka-topics.sh 建立topic程式
-
kafka-console-producer.sh 命令列模擬生產者生產訊息資料程式
-
kafka-console-consumer.sh 命令列模擬消費者消費訊息資料程式
kafka的組態檔
vim /usr/local/kafka/config/server.properties
############################# Server Basics #############################
# broker的id,值為整數,且必須唯一,在一個叢集中不能重複,預設為0
broker.id=0
############################# Socket Server Settings #############################
# kafka預設監聽的埠為9092
#listeners=PLAINTEXT://:9092
# 處理網路請求的執行緒數量,預設為3個
num.network.threads=3
# 執行磁碟IO操作的執行緒數量,預設為8個
num.io.threads=8
# socket服務傳送資料的緩衝區大小,預設100KB
socket.send.buffer.bytes=102400
# socket服務接受資料的緩衝區大小,預設100KB
socket.receive.buffer.bytes=102400
# socket服務所能接受的一個請求的最大大小,預設為100M
socket.request.max.bytes=104857600
############################# Log Basics #############################
# kafka儲存訊息資料的目錄
log.dirs=../data
# 每個topic預設的partition數量
num.partitions=1
# 在啟動時恢復資料和關閉時重新整理資料時每個資料目錄的執行緒數量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# 訊息重新整理到磁碟中的訊息條數閾值
#log.flush.interval.messages=10000
# 訊息重新整理到磁碟中的最大時間間隔
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 紀錄檔保留小時數,超時會自動刪除,預設為7天
log.retention.hours=168
# 紀錄檔保留大小,超出大小會自動刪除,預設為1G,log.retention.bytes這是指定 Broker 為訊息儲存的總磁碟容量大小
#log.retention.bytes=1073741824
# 紀錄檔分片策略,單個紀錄檔檔案的大小最大為1G,超出後則建立一個新的紀錄檔檔案
log.segment.bytes=1073741824
# 每隔多長時間檢測資料是否達到刪除條件
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper連線資訊,如果是zookeeper叢集,則以逗號隔開
zookeeper.connect=localhost:2181
# 連線zookeeper的超時時間
zookeeper.connection.timeout.ms=6000
# 是否可以刪除topic,預設為false
delete.topic.enable=true
kafka叢集部署
環境資訊
| 節點 | IP | ZK Port | Kafka Port | OS |
|---|---|---|---|---|
| node01 | 10.0.0.80 | 2181 | 9092 | CentOS7.9 |
| node02 | 10.0.0.81 | 2181 | 9092 | CentOS7.9 |
| node03 | 10.0.0.82 | 2181 | 9092 | CentOS7.9 |
部署ZooKeeper叢集
kakfa依賴ZooKeeper,可以用以下兩種方式使用ZooKeeper:
-
使用kafka自帶的ZooKeeper(一般不推薦使用內建的ZooKeeper)
-
單獨搭建ZooKeeper
搭建ZooKeeper叢集見ZooKeeper檔案。
部署kafka叢集
所有節點(node01、node02、node03)上操作:
# 1.安裝jdk
yum install -y java-1.8.0-openjdk
# 2.準備kafka安裝包
tar zxvf kafka_2.11-2.2.0.tgz -C /usr/local/
ln -s /usr/local/kafka_2.11-2.2.0 /usr/local/kafka
mkdir -pv /data/kafka/data/ # 建立kafka資料儲存目錄
# 設定環境變數
sed -i '$aPATH="/usr/local/kafka/bin:$PATH"' /etc/profile
source /etc/profile
# 3.修改kafka組態檔
broker.id=1 # 各自節點的id號,每個節點都有自己的id,值為整數,且必須唯一,在一個叢集中不能重複,預設為0
listeners=PLAINTEXT://10.0.0.80:9092 # kafka預設監聽的埠號為9092,指定各自節點的地址和埠
log.dirs=/data/kafka/data # 指定kafka資料的存放目錄
zookeeper.connect=10.0.0.80:2181,10.0.0.81:2181,10.0.0.82:2181 # zookeeper的連線資訊,kafka要將後設資料資訊存放到zk中
zookeeper.connection.timeout.ms=600000 #連線zk超時時間調大,否則可能起不來,預設: 6000
# 4.啟動kafka
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
# 5.檢視程序及埠
ps -ef | grep kafka
ss -tnl | grep 9092 # kafka監聽在9092埠
生產和消費訊息測試
-
kafka-server-start.sh kafka啟動程式
-
kafka-server-stop.sh kafka停止程式
-
kafka-topics.sh 建立topic程式
-
kafka-console-producer.sh 命令列模擬生產者生產訊息資料程式
-
kafka-console-consumer.sh 命令列模擬消費者消費訊息資料程式
topic相關操作
操作topic使用kafka-topic.sh指令碼
# 檢視主題topic列表,需指定zk的地址
kafka-topics.sh --list --zookeeper 10.0.0.80:2181
# 建立topic hello
kafka-topics.sh --create --zookeeper 10.0.0.80:2181 --replication-factor 1 --partitions 3 --topic hello
# --create 是建立主題topic
# --zookeeper localhost:2181 主題topic資訊是儲存在zk中,需要指定zk服務的地址
# --replication-factor 1 主題topic資訊的副本數,因為現在只要一個節點,所以只能是1,有多個節點時候,可以指定副本數多個
# --partitions 3 主題topic有多少個分割區
# --topic test-topic 指定主題topic的名字
# 檢視某個具體的主題topic訊息
kafka-topics.sh --describe --zookeeper 10.0.0.80:2181 --topic hello
# 修改主題topic資訊,增加到5個分割區
kafka-topics.sh --alter --zookeeper 10.0.0.80:2181 --topic hello --partitions 5
# 刪除主題topic hello
kafka-topics.sh --delete --zookeeper 10.0.0.80:2181 --topic hello
生產和消費命令
-
生產訊息:
kafka-console-producer.sh -
消費訊息:
kafka-console-consumer.sh
1)生產訊息
使用kafka自帶的生產者命令生產訊息 (可開一個視窗,模擬生產者)
# 生產者生產訊息,是往topic裡傳送訊息的,需要指明kafka地址和topic的名字
kafka-console-producer.sh --broker-list 10.0.0.80:9092 --topic test-topic
>hello
>test1
>test2
>
2)消費訊息
使用kafka自帶的消費者命令消費訊息 (可開多個視窗,模擬消費者)
# 消費者消費訊息,也是從指定topic裡取出的,需要指明kafka地址和topic的名字,加--from-beginning是從頭開始收,不加就從當前狀態開始收
kafka-console-consumer.sh --bootstrap-server 10.0.0.80:9092 --topic test-topic --from-beginning
檢視訊息本體及相關資料
檢視kafka存放的訊息
# 來到kafka的資料目錄,檢視kafka存放的訊息
cd /data/kafka/data/
ls -d ./test-topic* # kafka存放的訊息會被分佈儲存在各個分割區,這裡目錄名test-topic就表示對應的topic名稱,字尾-0就表示對應的分割區
./test-topic-0 # 有幾個分割區就會有幾個這樣的目錄,訊息被分佈儲存在各個目錄(目錄名稱格式: topic名稱-分割區編號)
# 檢視對應分割區下的檔案(每個分割區中存放的訊息內容都不一樣)
ls ./test-topic-0/
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
# 檢視訊息本體
cat ./test-topic-0/00000000000000000000.log
=CͰ