快速搞懂Vue2 diff演演算法(圖文詳解)
diff演演算法是一種通過同層的樹節點進行比較的高效演演算法,避免了對樹進行逐層搜尋遍歷。那麼大家對diff演演算法嗎有多少了解?下面本篇文章就來帶大家深入解析下vue2的diff演演算法,希望對大家有所幫助!

看 Vue 2 的原始碼已經很久了,從用 flow 到如今使用 TypeScript,我每次都會開啟它的原始碼看一看,但是每次都只看到了 資料初始化 部分,也就是 beforeMount 的階段,對於如何生成 VNode(Visual Dom Node, 也可以直接稱為 vdom) 以及元件更新時如何比較 VNode(diff)始終沒有仔細研究,只知道採用了 雙端 diff 演演算法,至於這個雙端是怎麼開始怎麼結束的也一直沒有去看過,所以這次趁寫文章的機會仔細研究一下。如果內容有誤,希望大家能幫我指出,非常感謝~
什麼是 diff ?
在我的理解中,diff 指代的是 differences,即 新舊內容之間的區別計算;Vue 中的 diff 演演算法,則是通過一種 簡單且高效 的手段快速對比出 新舊 VNode 節點陣列之間的區別 以便 以最少的 dom 操作來更新頁面內容。【相關推薦:、】
此時這裡有兩個必須的前提:
對比的是 VNode 陣列
同時存在新舊兩組 VNode 陣列
所以它一般只發生在 資料更新造成頁面內容需要更新時執行,即 renderWatcher.run()。
為什麼是 VNode ?
上面說了,diff 中比較的是 VNode,而不是真實的 dom 節點,相信為什麼會使用 VNode 大部分人都比較清楚,筆者就簡單帶過吧?~
在 Vue 中使用 VNode 的原因大致有兩個方面:
VNode 作為框架設計者根據框架需求設計的 JavaScript 物件,本身屬性相對真實的 dom 節點要簡單,並且操作時不需要進行 dom 查詢,可以大幅優化計算時的效能消耗
在 VNode 到真實 dom 的這個渲染過程,可以根據不同平臺(web、微信小程式)進行不同的處理,生成適配各平臺的真實 dom 元素
在 diff 過程中會遍歷新舊節點資料進行對比,所以使用 VNode 能帶來很大的效能提升。
流程梳理
在網頁中,真實的 dom 節點都是以 樹 的形式存在的,根節點都是 <html>,為了保證虛擬節點能與真實 dom 節點一致,VNode 也一樣採用的是樹形結構。
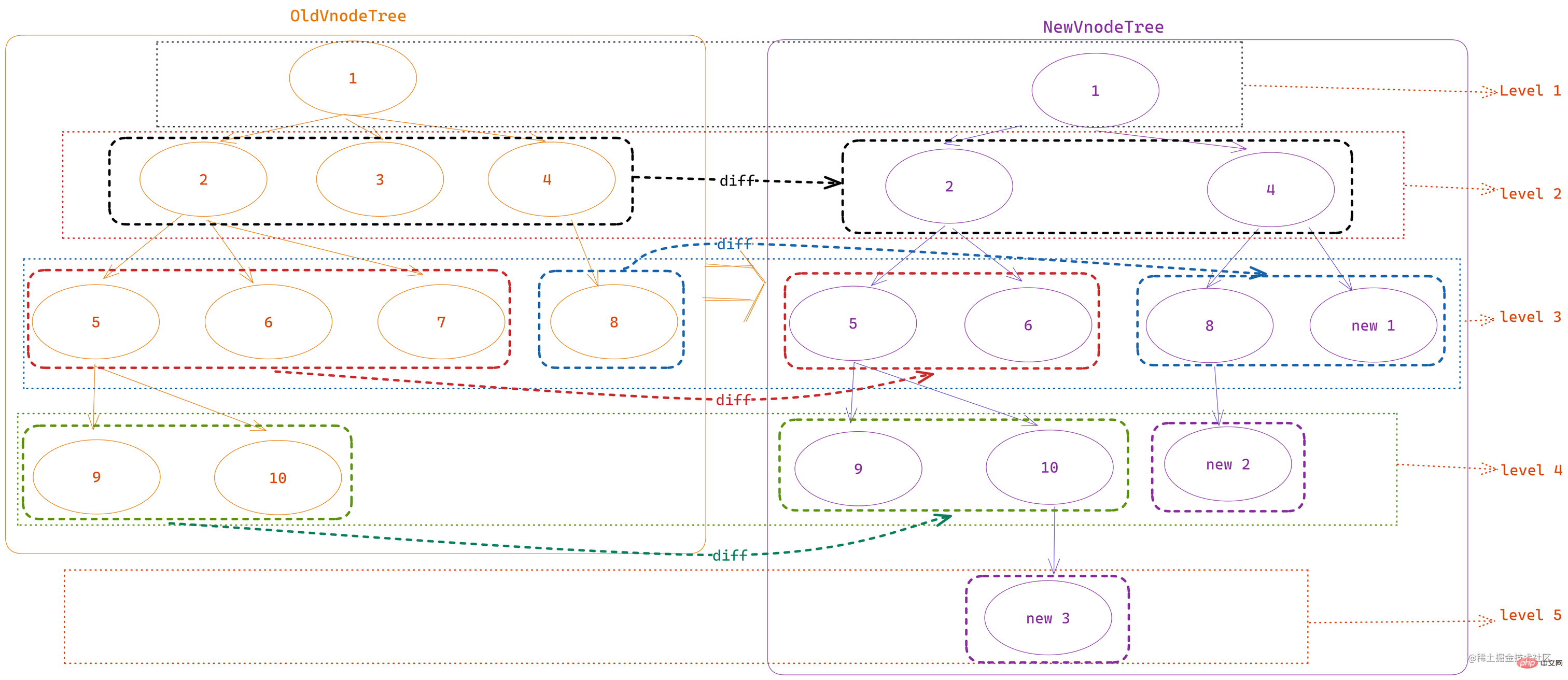
如果在元件更新時,需要對比全部 VNode 節點的話,新舊兩組節點都需要進行 深度遍歷 和比較,會產生很大的效能開銷;所以,Vue 中預設 同層級節點比較,即 如果新舊 VNode 樹的層級不同的話,多餘層級的內容會直接新建或者捨棄,只在同層級進行 diff 操作。
一般來說,diff 操作一般發生在 v-for 迴圈或者有 v-if/v-else 、component 這類 動態生成 的節點物件上(靜態節點一般不會改變,對比起來很快),並且這個過程是為了更新 dom,所以在原始碼中,這個過程對應的方法名是 updateChildren,位於 src/core/vdom/patch.ts 中。如下圖:
這裡回顧一下 Vue 元件範例的建立與更新過程:
首先是
beforeCreate到created階段,主要進行資料和狀態以及一些基礎事件、方法的處理然後,會呼叫
$mount(vm.$options.el)方法進入Vnode與 dom 的建立和掛載階段,也就是beforeMount到mounted之間(元件更新時與這裡類似)原型上的
$mount會在platforms/web/runtime-with-compiler.ts中進行一次重寫,原始實現在platforms/web/runtime/index.ts中;在原始實現方法中,其實就是呼叫mountComponent方法執行render;而在web下的runtime-with-compiler中則是增加了 模板字串編譯 模組,會對options中的的template進行一次解析和編譯,轉換成一個函數繫結到options.render中
mountComponent函數內部就是 定義了渲染方法updateComponent = () => (vm._update(vm._render()),範例化一個具有before設定的watcher範例(即renderWatcher),通過定義watch觀察物件為 剛剛定義的updateComponent方法來執行 首次元件渲染與觸發依賴收集,其中的before設定僅僅設定了觸發beforeMount/beforeUpdate勾點函數的方法;這也是為什麼在beforeMount階段取不到真實 dom 節點與beforeUpdate階段獲取的是舊 dom 節點的原因
_update方法的定義與mountComponent在同一檔案下,其核心就是 讀取元件範例中的$el(舊 dom 節點)與_vnode(舊 VNode)與_render()函數生成的vnode進行patch操作
patch函數首先對比 是否具有舊節點,沒有的話肯定是新建的元件,直接進行建立和渲染;如果具有舊節點的話,則通過patchVnode進行新舊節點的對比,並且如果新舊節點一致並且都具有children子節點,則進入diff的核心邏輯 ——updateChildren子節點對比更新,這個方法也是我們常說的diff演演算法
前置內容
既然是對比新舊 VNode 陣列,那麼首先肯定有 對比 的判斷方法:sameNode(a, b)、新增節點的方法 addVnodes、移除節點的方法 removeVnodes,當然,即使 sameNode 判斷了 VNode 一致之後,依然會使用 patchVnode 對單個新舊 VNode 的內容進行深度比較,確認內部資料是否需要更新。
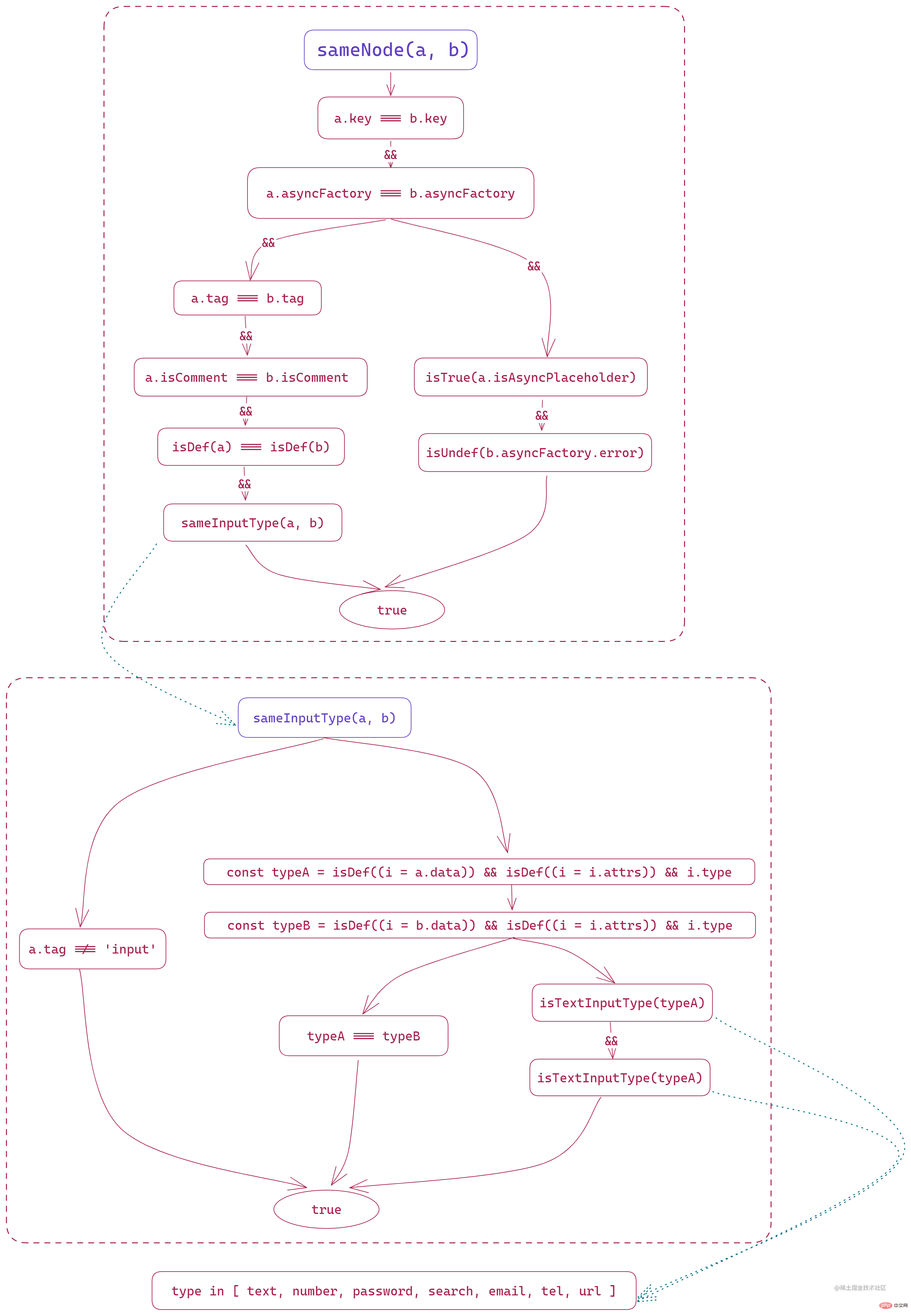
sameNode(a, b)
這個方法就一個目的:比較新舊節點是否相同。
在這個方法中,首先比較的就是 a 和 b 的 key 是否相同,這也是為什麼 Vue 在檔案中註明了 v-for、v-if、v-else 等動態節點必須要設定 key 來標識節點唯一性,如果 key 存在且相同,則只需要比較內部是否發生了改變,一般情況下可以減少很多 dom 操作;而如果沒有設定的話,則會直接銷燬重建對應的節點元素。
然後會比較是不是非同步元件,這裡會比較他們的建構函式是不是一致。
然後會進入兩種不同的情況比較:
- 非非同步元件:標籤一樣、都不是註釋節點、都有資料、同型別文字輸入框
- 非同步元件:舊節點預留位置和新節點的錯誤提示都為
undefined
函數整體過程如下
addVnodes
顧名思義,新增新的 VNode 節點。
該函數接收 6 個引數:parentElm 當前節點陣列父元素、refElm 指定位置的元素、vnodes 新的虛擬節點陣列、startIdx 新節點陣列的插入元素開始位置、endIdx 新節點陣列的插入元素結束索引、insertedVnodeQueue 需要插入的虛擬節點佇列。
函數內部會 從 startIdx 開始遍歷 vnodes 陣列直到 endIdx 位置,然後呼叫 createElm 依次在 refElm 之前建立和插入 vnodes[idx] 對應的元素。
當然,在這個 vnodes[idx] 中有可能會有 Component 元件,此時還會呼叫 createComponent 來建立對應的元件範例。
因為整個
VNode和 dom 都是一個 樹結構,所以在 同層級的比較之後,還需要處理當前層級下更深層次的 VNode 和 dom 處理。
removeVnodes
與 addVnodes 相反,該方法就是用來移除 VNode 節點的。
由於這個方法只是移除,所以只需要三個引數:vnodes 舊虛擬節點陣列、startIdx 開始索引、endIdx 結束索引。
函數內部會 從 startIdx 開始遍歷 vnodes 陣列直到 endIdx 位置,如果 vnodes[idx] 不為 undefined 的話,則會根據 tag 屬性來區分處理:
- 存在
tag,說明是一個元素或者元件,需要 遞迴處理vnodes[idx]的內容, 觸發remove hooks 與 destroy hooks - 不存在
tag,說明是一個 純文位元組點,直接從 dom 中移除該節點即可
patchVnode
節點對比的 實際完整對比和 dom 更新 方法。
在這個方法中,主要包含 九個 主要的引數判斷,並對應不同的處理邏輯:
新舊 VNode 全等,則說明沒有變化,直接退出
如果新的 VNode 具有真實的 dom 繫結,並且需要更新的節點集合是一個陣列的話,則拷貝當前的 VNode 到集合的指定位置
如果舊節點是一個 非同步元件並且還沒有載入結束的話就直接退出,否則通過
hydrate函數將新的 VNode 轉化為真實的 dom 進行渲染;兩種情況都會 退出該函數如果新舊節點都是 靜態節點 並且
key相等,或者是isOnce指定的不更新節點,也會直接 複用舊節點的元件範例 並 退出函數如果新的 VNode 節點具有
data屬性並且有設定prepatch勾點函數,則執行prepatch(oldVnode, vnode)通知進入節點的對比階段,一般這一步會設定效能優化如果新的 VNode 具有
data屬性並且遞迴改節點的子元件範例的 vnode,依然是可用標籤的話,cbs回撥函數物件中設定的update勾點函數以及data中設定的update勾點函數如果新的 VNode 不是文位元組點的話,會進入核心對比階段:
- 如果新舊節點都有
children子節點,則進入updateChildren方法對比子節點 - 如果舊節點沒有子節點的話,則直接建立 VNode 對應的新的子節點
- 如果新節點沒有子節點的話,則移除舊的 VNode 子節點
- 如果都沒有子節點的話,並且舊節點有文字內容設定,則清空以前的
text文字
- 如果新舊節點都有
如果新的 VNode 具有
text文字(是文位元組點),則比較新舊節點的文字內容是否一致,否則進行文字內容的更新最後呼叫新節點的
data中設定的postpatch勾點函數,通知節點更新完畢
簡單來說,patchVnode 就是在 同一個節點 更新階段 進行新內容與舊內容的對比,如果發生改變則更新對應的內容;如果有子節點,則「遞迴」執行每個子節點的比較和更新。
而 子節點陣列的比較和更新,則是 diff 的核心邏輯,也是面試時經常被提及的問題之一。
下面,就進入 updateChildren 方法的解析吧~
updateChildren diff 核心解析
首先,我們先思考一下 以新陣列為準比較兩個物件陣列元素差異 有哪些方法?
一般來說,我們可以通過 暴力手段直接遍歷兩個陣列 來查詢陣列中每個元素的順序和差異,也就是 簡單 diff 演演算法。
即 遍歷新節點陣列,在每次迴圈中再次遍歷舊節點陣列 對比兩個節點是否一致,通過對比結果確定新節點是新增還是移除還是移動,整個過程中需要進行 m*n 次比較,所以預設時間複雜度是 On。
這種比較方式在大量節點更新過程中是非常消耗效能的,所以 Vue 2 對其進行了優化,改為 雙端對比演演算法,也就是 雙端 diff。
雙端 diff 演演算法
顧名思義,雙端 就是 從兩端開始分別向中間進行遍歷對比 的演演算法。
在 雙端 diff 中,分為 五種比較情況:
新舊頭相等
新舊尾相等
舊頭等於新尾
舊尾等於新頭
四者互不相等
其中,前四種屬於 比較理想的情況,而第五種才是 最複雜的對比情況。
判斷相等即
sameVnode(a, b)等於true
下面我們通過一種預設情況來進行分析。
1. 預設新舊節點狀態
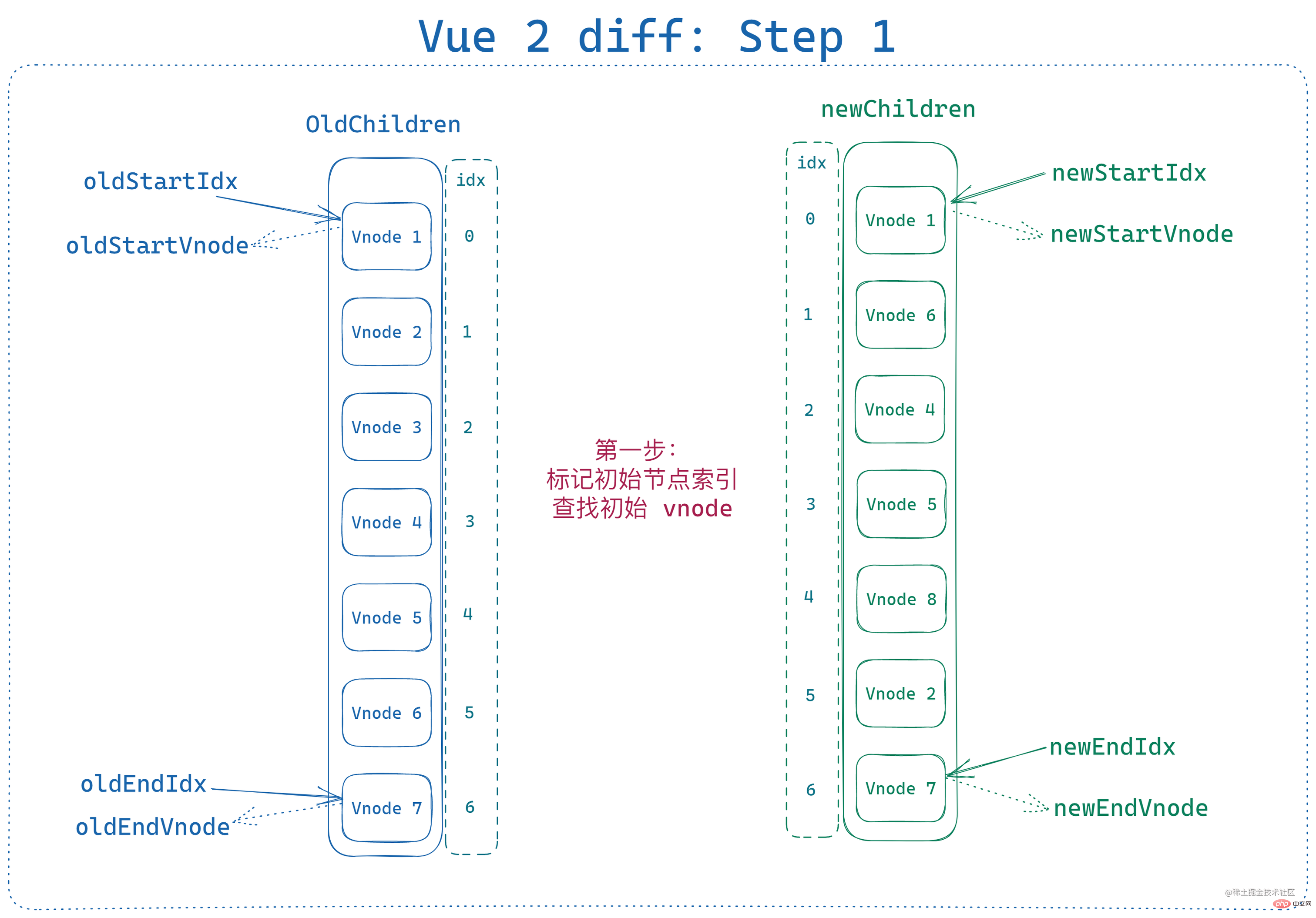
為了儘量同時演示出以上五種情況,我預設了以下的新舊節點陣列:
- 作為初始節點順序的舊節點陣列
oldChildren,包含 1 - 7 共 7 個節點 - 作為亂序後的新節點陣列
newChildren,也有 7 個節點,但是相比舊節點減少了一個vnode 3並增加了一個vnode 8
在進行比較之前,首先需要 定義兩組節點的雙端索引:
let oldStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newStartIdx = 0
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
登入後複製複製的原始碼,其中
oldCh在圖中為oldChildren,newCh為newChildren
然後,我們定義 遍歷對比操作的停止條件:
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx)
登入後複製這裡的停止條件是 只要新舊節點陣列任意一個遍歷結束,則立即停止遍歷。
此時節點狀態如下:
2. 確認 vnode 存在才進行對比
為了保證新舊節點陣列在對比時不會進行無效對比,會首先排除掉舊節點陣列 起始部分與末尾部分 連續且值為 Undefined 的資料。
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx]
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]登入後複製
當然我們的例子中沒有這種情況,可以忽略。
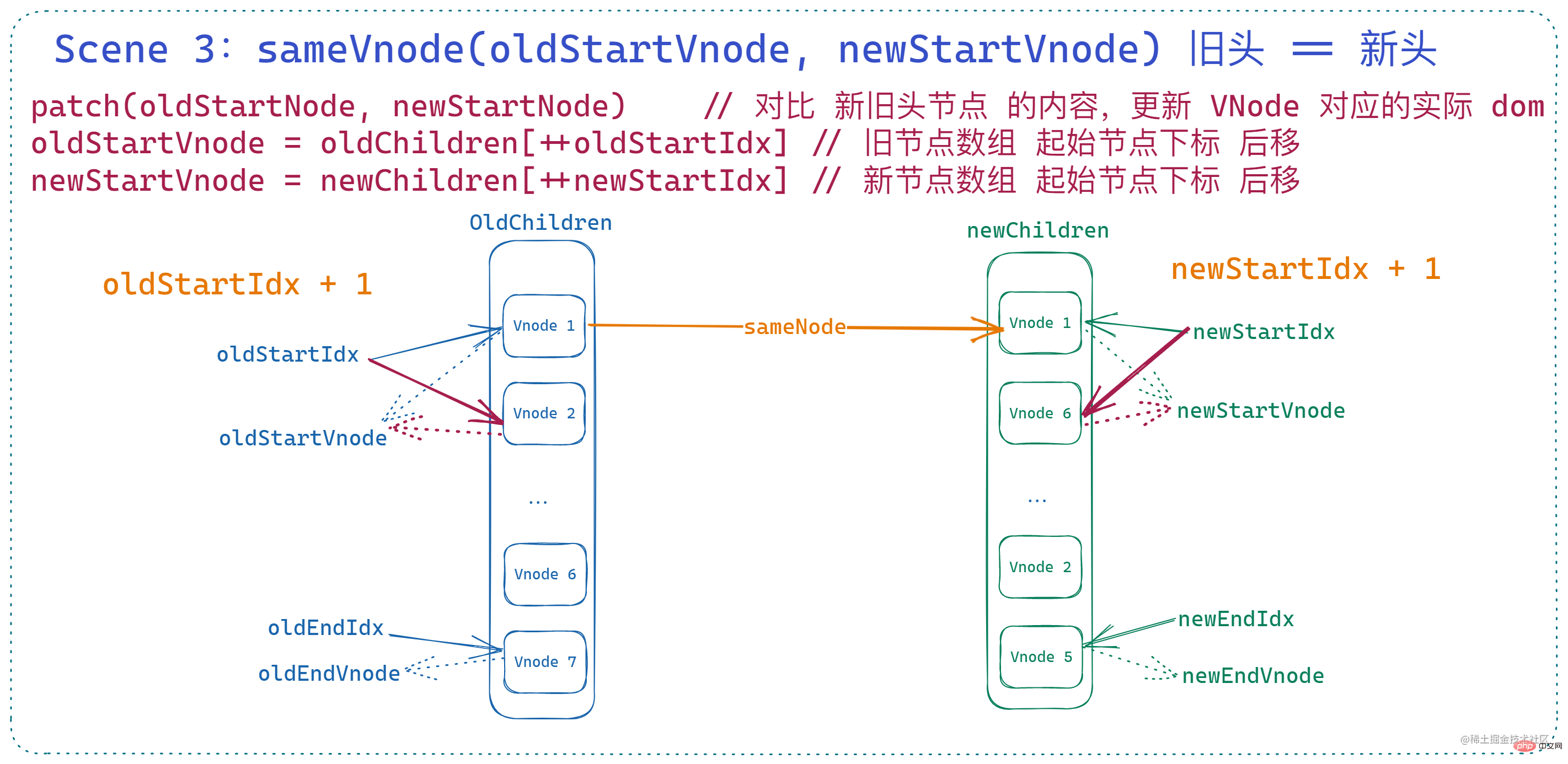
3. 舊頭等於新頭
此時相當於新舊節點陣列的兩個 起始索引 指向的節點是 基本一致的,那麼此時會呼叫 patchVnode 對兩個 vnode 進行深層比較和 dom 更新,並且將 兩個起始索引向後移動。即:
if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(
oldStartVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}登入後複製這時的節點和索引變化如圖所示:
4. 舊尾等於新尾
與頭結點相等類似,這種情況代表 新舊節點陣列的最後一個節點基本一致,此時一樣呼叫 patchVnode 比較兩個尾結點和更新 dom,然後將 兩個末尾索引向前移動。
if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(
oldEndVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}登入後複製這時的節點和索引變化如圖所示:
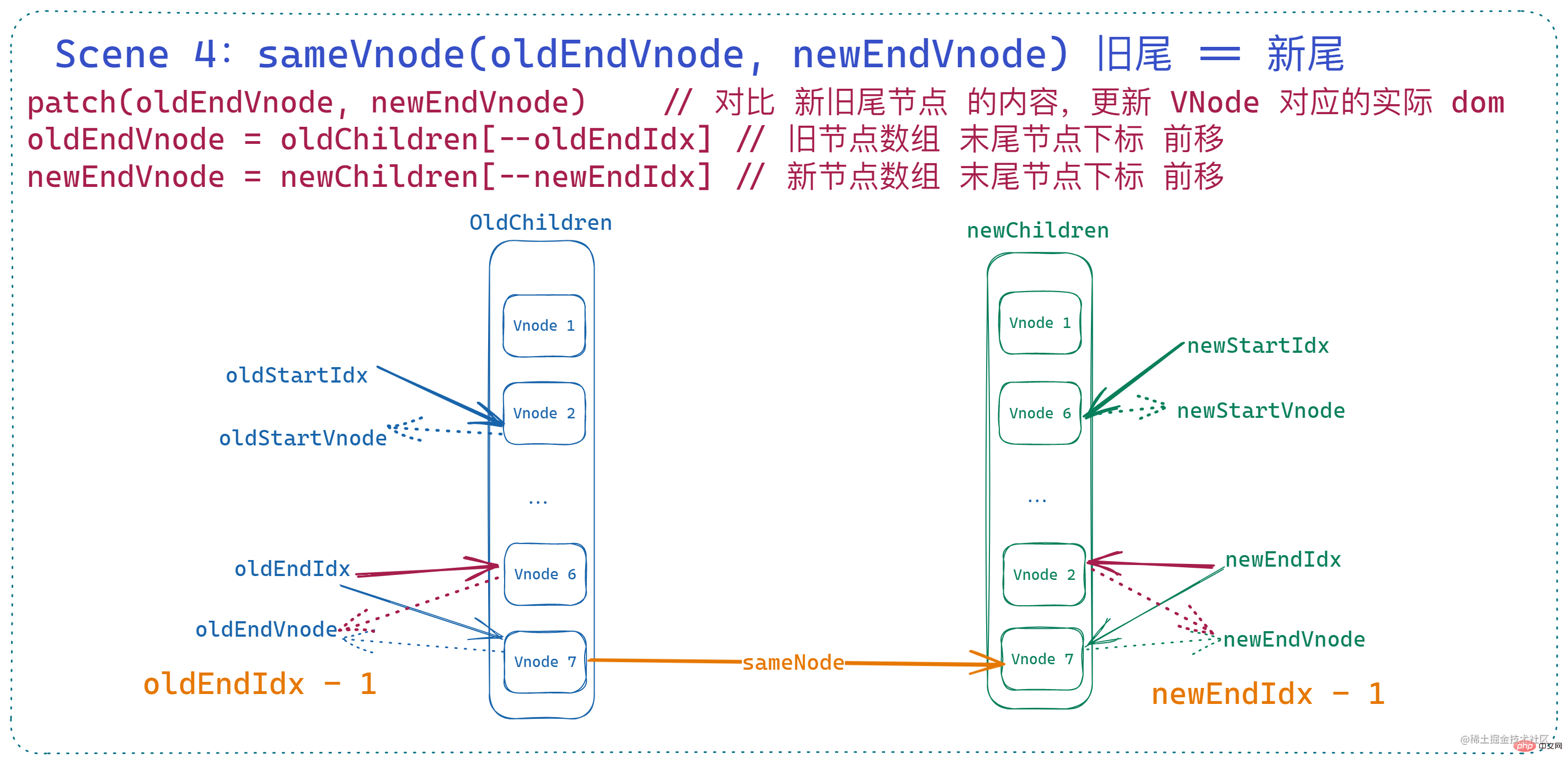
5. 舊頭等於新尾
這裡表示的是 舊節點陣列 當前起始索引 指向的 vnode 與 新節點陣列 當前末尾索引 指向的 vnode 基本一致,一樣呼叫 patchVnode 對兩個節點進行處理。
但是與上面兩種有區別的地方在於:這種情況下會造成 節點的移動,所以此時還會在 patchVnode 結束之後 通過 nodeOps.insertBefore 將 舊的頭節點 重新插入到 當前 舊的尾結點之後。
然後,會將 舊節點的起始索引後移、新節點的末尾索引前移。
看到這裡大家可能會有一個疑問,為什麼這裡移動的是 舊的節點陣列,這裡因為 vnode 節點中有一個屬性
elm,會指向該 vnode 對應的實際 dom 節點,所以這裡移動舊節點陣列其實就是 側面去移動實際的 dom 節點順序;並且注意這裡是 當前的尾結點,在索引改變之後,這裡不一定就是原舊節點陣列的最末尾。
即:
if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(
oldStartVnode,
newEndVnode,
insertedVnodeQueue,
newCh,
newEndIdx
)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}登入後複製此時狀態如下:
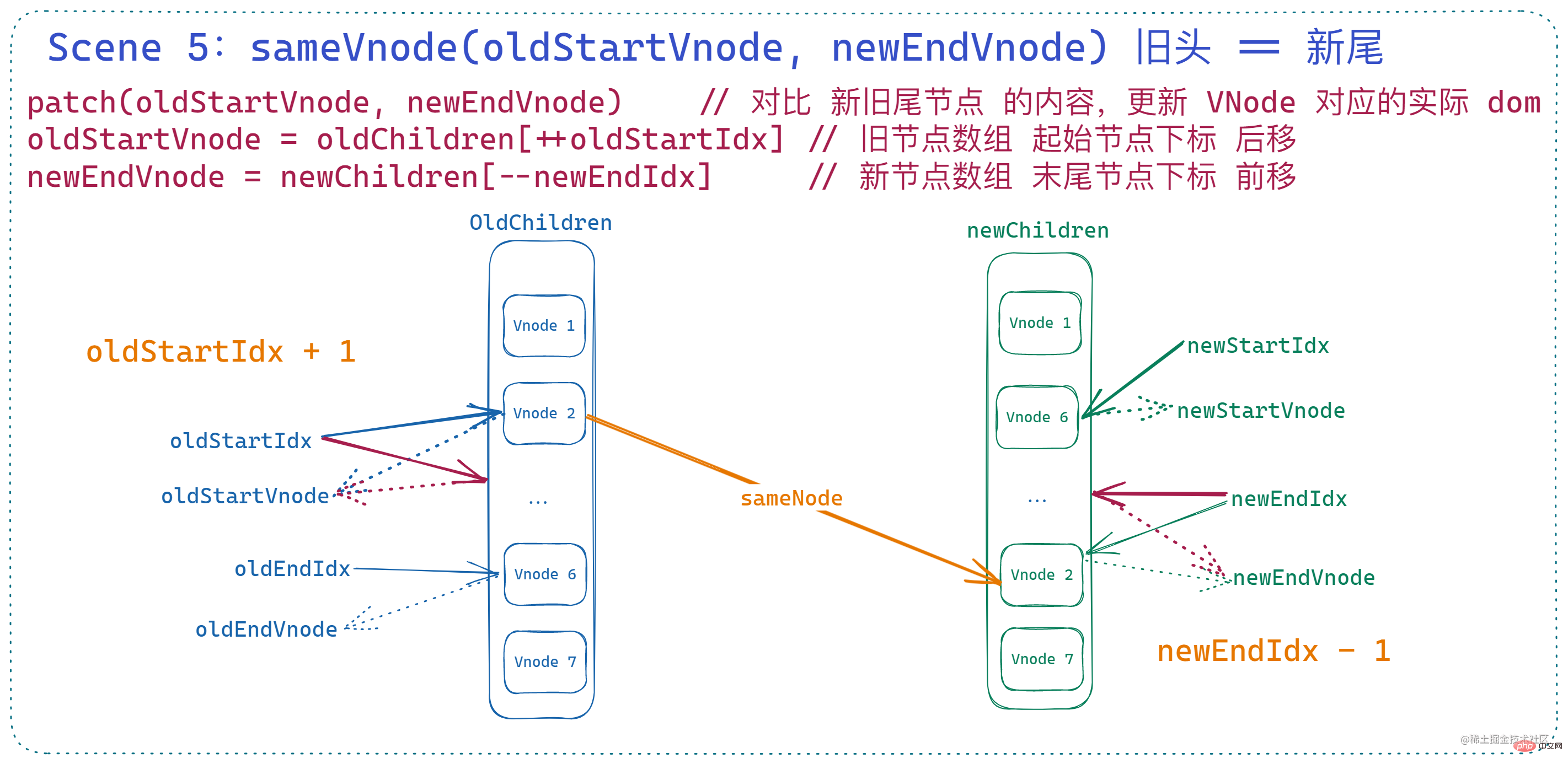
6. 舊尾等於新頭
這裡與上面的 舊頭等於新尾 類似,一樣要涉及到節點對比和移動,只是調整的索引不同。此時 舊節點的 末尾索引 前移、新節點的 起始索引 後移,當然了,這裡的 dom 移動對應的 vnode 操作是 將舊節點陣列的末尾索引對應的 vnode 插入到舊節點陣列 起始索引對應的 vnode 之前。
if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(
oldEndVnode,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}登入後複製此時狀態如下:
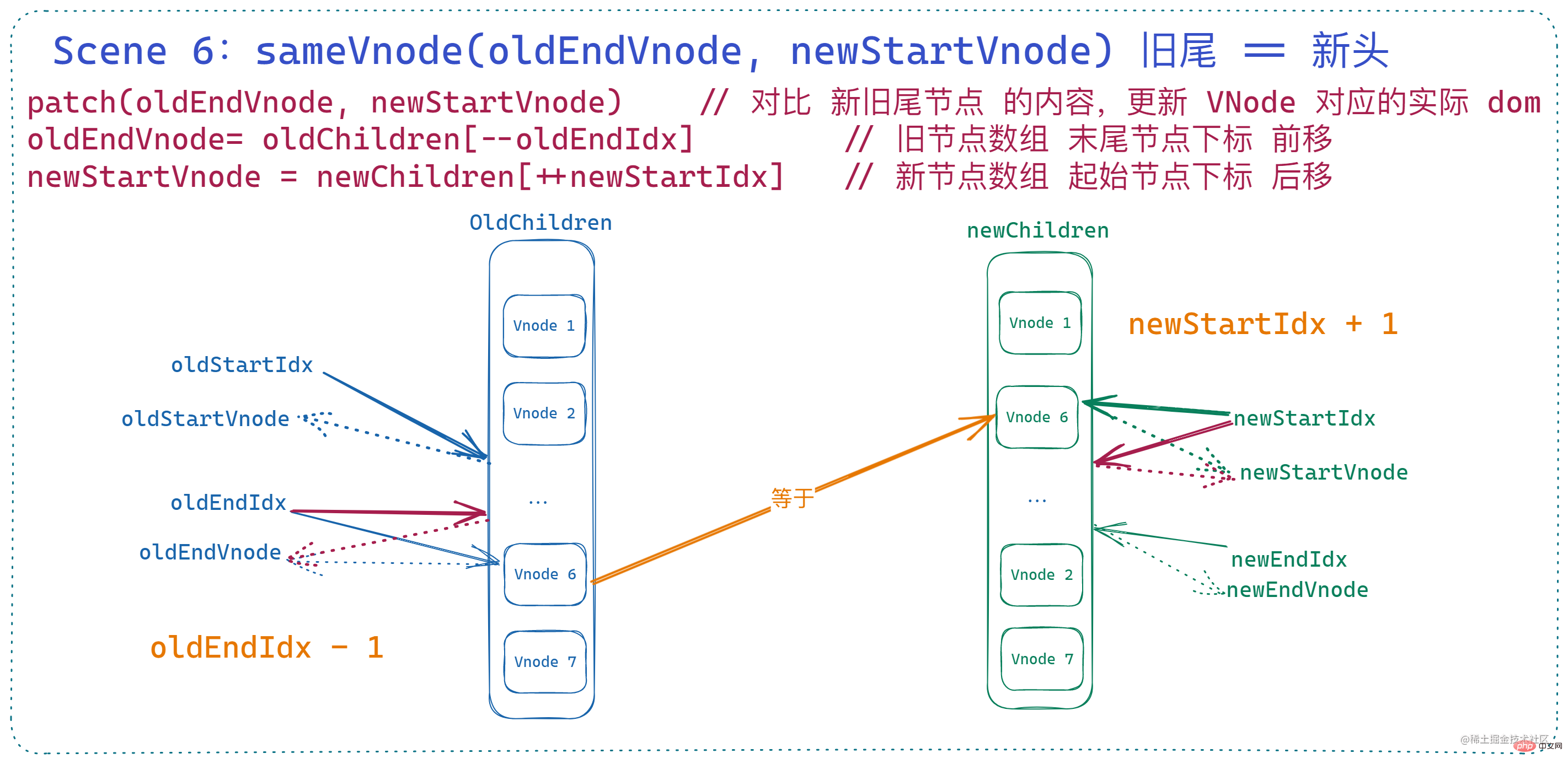
7. 四者均不相等
在以上情況都處理之後,就來到了四個節點互相都不相等的情況,這種情況也是 最複雜的情況。
當經過了上面幾種處理之後,此時的 索引與對應的 vnode 狀態如下:
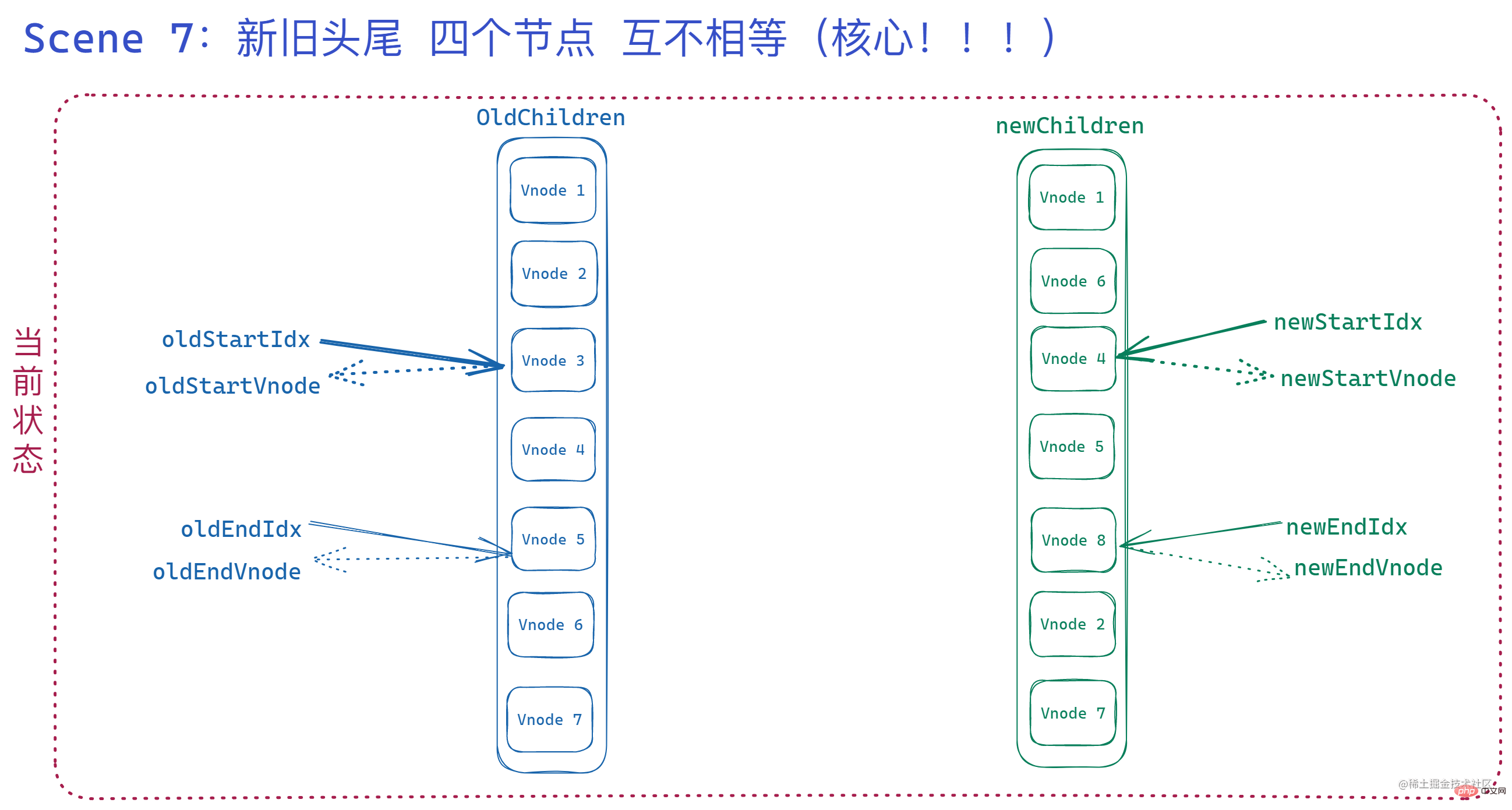
可以看到四個索引對應的 vnode 分別是:vnode 3、vnode 5、 vnode 4、vnode 8,這幾個肯定是不一樣的。
此時也就意味著 雙端對比結束。
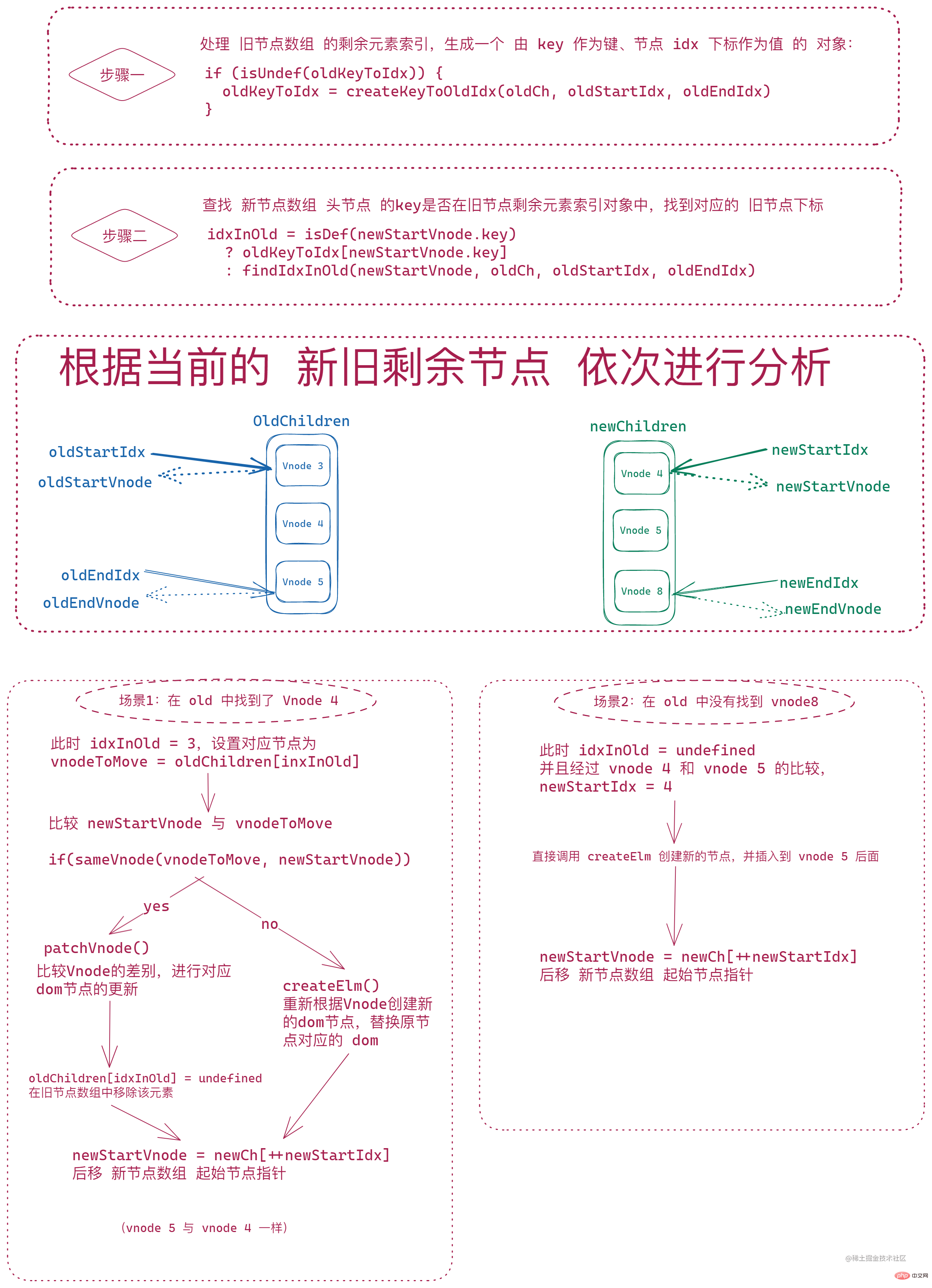
後面的節點對比則是 將舊節點陣列剩餘的 vnode (oldStartIdx 到 oldEndIdx 之間的節點)進行一次遍歷,生成由 vnode.key 作為鍵,idx 索引作為值的物件 oldKeyToIdx,然後 遍歷新節點陣列的剩餘 vnode(newStartIdx 到 newEndIdx 之間的節點),根據新的節點的 key 在 oldKeyToIdx 進行查詢。此時的每個新節點的查詢結果只有兩種情況:
找到了對應的索引,那麼會通過
sameVNode對兩個節點進行對比:- 相同節點,呼叫
patchVnode進行深層對比和 dom 更新,將oldKeyToIdx中對應的索引idxInOld對應的節點插入到oldStartIdx對應的 vnode 之前;並且,這裡會將 舊節點陣列中idxInOld對應的元素設定為undefined - 不同節點,則呼叫
createElm重新建立一個新的 dom 節點並將 新的 vnode 插入到對應的位置
- 相同節點,呼叫
沒有找到對應的索引,則直接
createElm建立新的 dom 節點並將新的 vnode 插入到對應位置
注:這裡 只有找到了舊節點並且新舊節點一樣才會將舊節點陣列中
idxInOld中的元素置為undefined。
最後,會將 新節點陣列的 起始索引 向後移動。
if (isUndef(oldKeyToIdx)) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) {
// New element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(
vnodeToMove,
newStartVnode,
insertedVnodeQueue,
newCh,
newStartIdx
)
oldCh[idxInOld] = undefined
canMove &&
nodeOps.insertBefore(
parentElm,
vnodeToMove.elm,
oldStartVnode.elm
)
} else {
// same key but different element. treat as new element
createElm(
newStartVnode,
insertedVnodeQueue,
parentElm,
oldStartVnode.elm,
false,
newCh,
newStartIdx
)
}
}
newStartVnode = newCh[++newStartIdx]
}登入後複製大致邏輯如下圖:
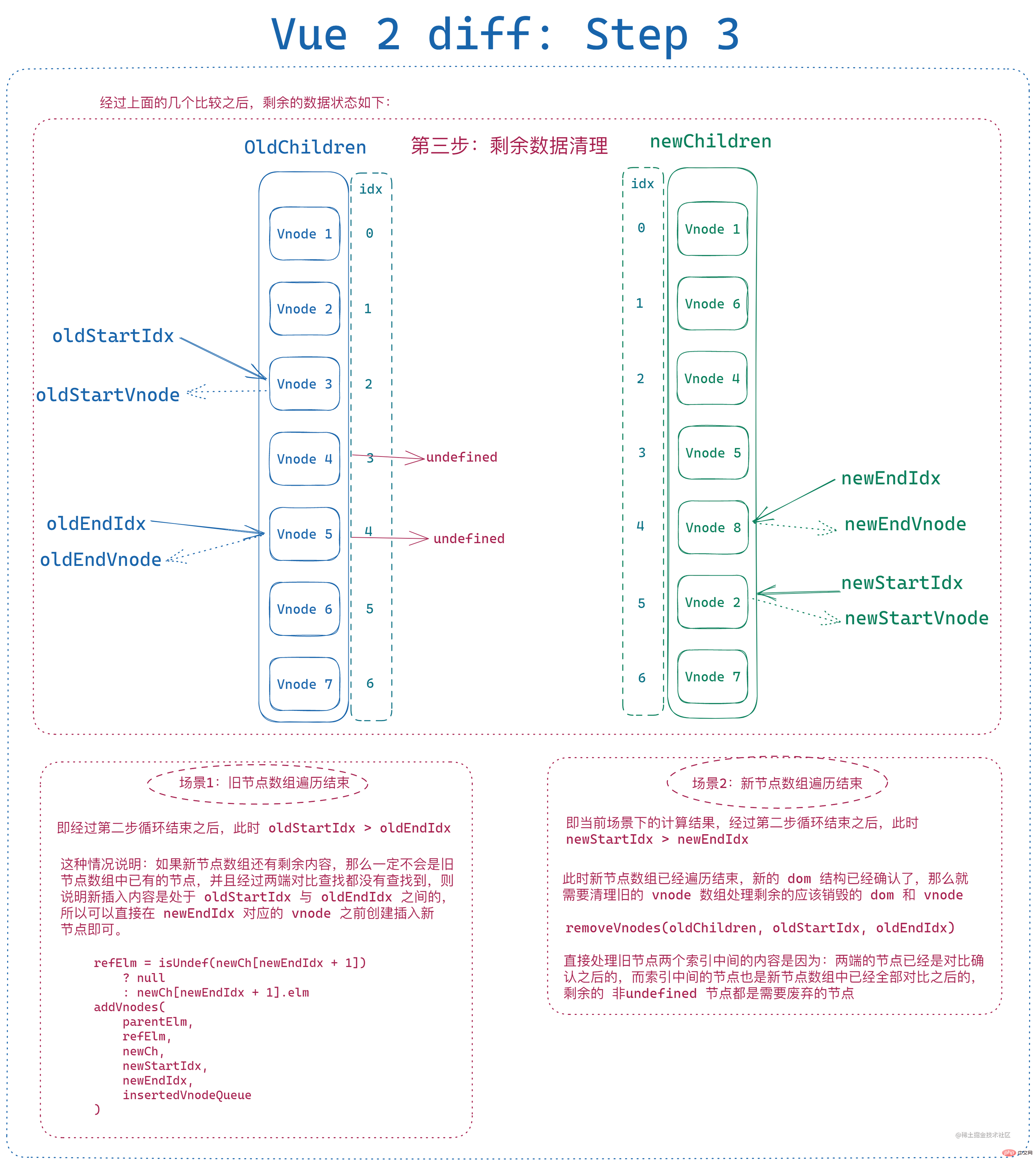
剩餘未比較元素處理
經過上面的處理之後,根據判斷條件也不難看出,遍歷結束之後 新舊節點陣列都剛好沒有剩餘元素 是很難出現的,當且僅當遍歷過程中每次新頭尾節點總能和舊頭尾節點中總能有兩個新舊節點相同時才會發生,只要有一個節點發生改變或者順序發生大幅調整,最後 都會有一個節點陣列起始索引和末尾索引無法閉合。
那麼此時就需要對剩餘元素進行處理:
- 舊節點陣列遍歷結束、新節點陣列仍有剩餘,則遍歷新節點陣列剩餘資料,分別建立節點並插入到舊末尾索引對應節點之前
- 新節點陣列遍歷結束、舊節點陣列仍有剩餘,則遍歷舊節點陣列剩餘資料,分別從節點陣列和 dom 樹中移除
即:
小結
Vue 2 的 diff 演演算法相對於簡單 diff 演演算法來說,通過 雙端對比與生成索引 map 兩種方式 減少了簡單演演算法中的多次迴圈操作,新舊陣列均只需要進行一次遍歷即可將所有節點進行對比。
其中雙端對比會分別進行四次對比和移動,效能不算最優解,所以 Vue 3 中引入了 最長遞增子序列 的方式來 替代雙端對比,而其餘部分則依然通過轉為索引map 的形式利用空間擴充套件來減少時間複雜度,從而更高的提升計算效能。
當然本文的圖中沒有給出 vnode 對應的 elm 真實 dom 節點,兩者的移動關係可能會給大家帶來誤解,建議配合 《Vue.js 設計與實現》一起閱讀。
整體流程如下:
(學習視訊分享:、)
以上就是快速搞懂Vue2 diff演演算法(圖文詳解)的詳細內容,更多請關注TW511.COM其它相關文章!