MS SQL Server 刪除重複行資料
您可以使用以下 SQL 語句刪除 MS SQL Server 表中重複的行:
WITH CTE AS (
SELECT ROW_NUMBER() OVER(PARTITION BY column1, column2, ... columnN ORDER BY (SELECT 0)) RN
FROM table_name
)
DELETE FROM CTE WHERE RN > 1;您需要將 table_name 替換為要刪除重複行的表名,並將 column1, column2, ... columnN 替換為用於檢查重複的列名。該語句使用 ROW_NUMBER() 函數和 PARTITION BY 子句來標識重複的行,然後使用 DELETE 語句刪除其中一個副本。
這樣說有些抽象,下面舉一個例子:
比如我有一個deadUrlRecord_copy1 表,存的資料如下格式。
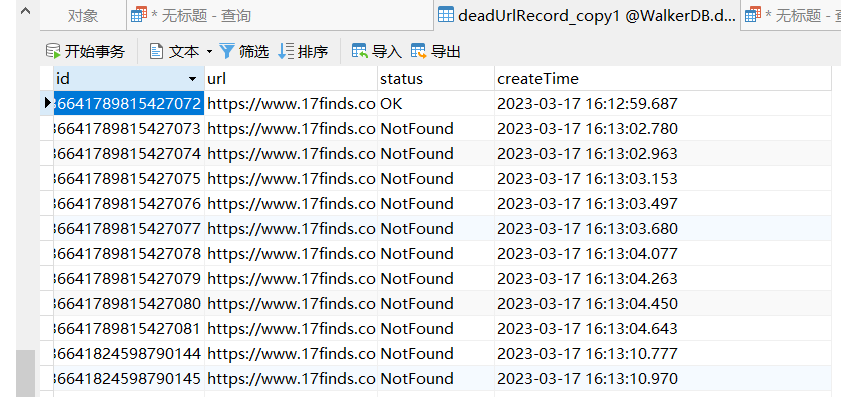
這個表存在一個問題,url列有一部分是重複的。用group by語句可以查出來,有挺多重複的,那麼,如何刪除多餘的資料,只保留一條呢?
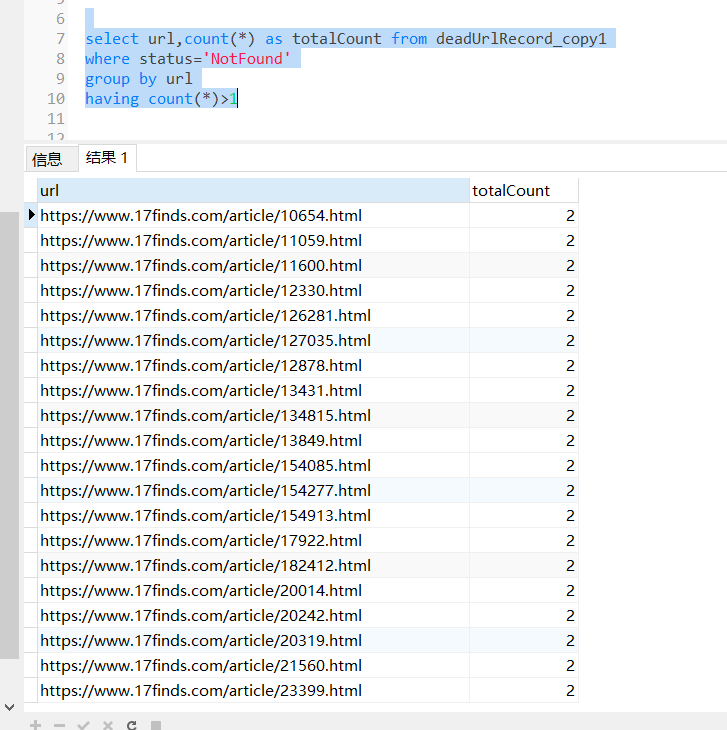
這就要採用文章開頭給出的語句了。
WITH cte AS (
SELECT url,
ROW_NUMBER() OVER (PARTITION BY url ORDER BY url) AS rn
FROM deadUrlRecord_copy1
WHERE status = 'NotFound'
)
DELETE FROM cte WHERE rn > 1;乍一看一臉懵逼,但是執行發現竟然成功刪除了重複資料,達到了預期效果,為什麼呢?
這要解釋下這一行程式碼:
ROW_NUMBER() OVER (PARTITION BY url ORDER BY url) AS rn 這是一種 SQL 語法,用於對一個查詢結果集的行進行編號,並且可以根據特定列來分組編號。
具體來說,ROW_NUMBER() 是一個視窗函數,它會為查詢結果集中每一行計算一個行號。而 OVER 子句則是指定如何定義視窗(window),也就是要給哪些行計算行號。在這個例子中,PARTITION BY url 表示按照 url 這一列進行分組,也就是說對於每個不同的 url 分別計算行號;ORDER BY url 則表示按照 url 這一列進行排序,這樣同一個 url 中的行就會按照 url 的值依次排列。最後,AS rn 則是給這個新的行號列起個名字,即 rn。
例如,假設有如下表格:
| id | url |
|---|---|
| 1 | www.example.com |
| 2 | www.example.com |
| 3 | www.example.com/foo |
| 4 | www.example.com/bar |
| 5 | www.google.com |
如果執行以下 SQL 查詢:
SELECT id, url, ROW_NUMBER() OVER (PARTITION BY url ORDER BY url) AS rn FROM my_table;則會得到以下結果:
| id | url | rn |
|---|---|---|
| 1 | www.example.com | 1 |
| 2 | www.example.com | 2 |
| 3 | www.example.com/foo | 1 |
| 4 | www.example.com/bar | 1 |
| 5 | www.google.com | 1 |
其中,同一個 url 中的行擁有相同的行號,同時這個行號是按照 url 的值進行排序的。
然後執行剛才那段程式碼的片段試一下,可能更好理解:
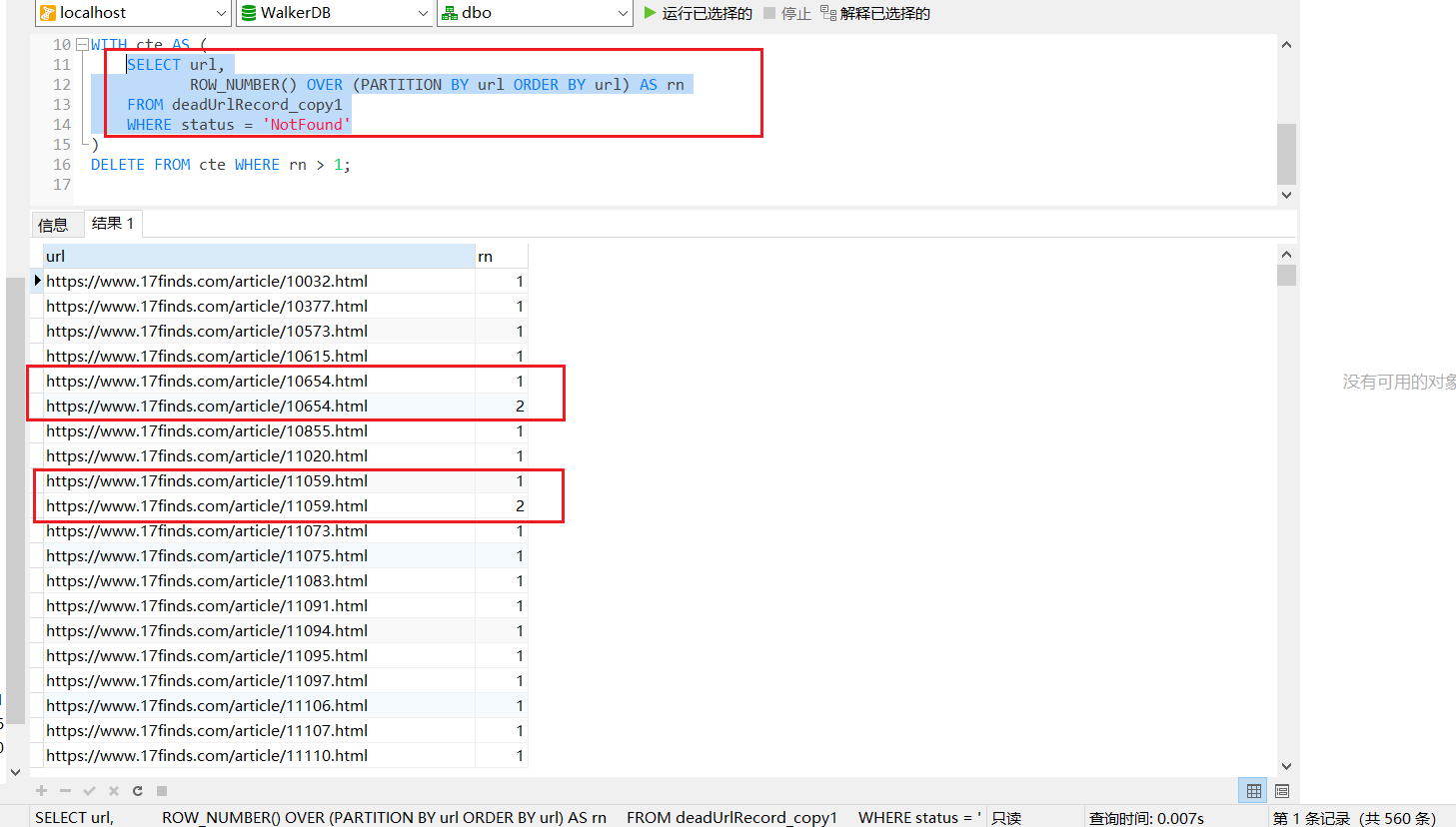
url不同的,行號都是1。相同的,會從1開始排序,所有就出現了2.
然後用 DELETE FROM cte WHERE rn > 1; 刪除行號>1的資料,就成功把多餘的資料刪除了,非常巧妙。