全網最詳細中英文ChatGPT介面檔案(四)30分鐘快速入門ChatGPT——Models模型
@

Models
Overview 概述
The OpenAI API is powered by a diverse set of models with different capabilities and price points. You can also make limited customizations to our original base models for your specific use case with fine-tuning.
OpenAI API由一組具有不同功能和價位的模型提供支援。您還可以通過微調針對您的特定使用情形對我們的原始基本模型進行有限的自定義。

We have also published open source models including Point-E, Whisper, Jukebox, and CLIP.
我們還發布了開源模型,包括Point-E、Whisper、Jukebox和CLIP。
Visit our model index for researchers to learn more about which models have been featured in our research papers and the differences between model series like InstructGPT and GPT-3.5.
請存取我們的模型索引,以瞭解更多關於我們的研究論文中介紹了哪些模型,以及InstructGPT和GPT-3.5等模型系列之間的差異。
GPT-4 Limited beta
GPT-4 is a large multimodal model (accepting text inputs and emitting text outputs today, with image inputs coming in the future) that can solve difficult problems with greater accuracy than any of our previous models, thanks to its broader general knowledge and advanced reasoning capabilities. Like gpt-3.5-turbo, GPT-4 is optimized for chat but works well for traditional completions tasks.
GPT-4是一個大型的多模態模型(今天接受文字輸入並輸出文字,未來會有影象輸入),由於其更廣泛的一般知識和先進的推理能力,它可以比我們以前的任何模型更準確地解決難題。與 gpt-3.5-turbo 一樣,GPT-4也針對聊天進行了優化,但也適用於傳統的完成任務。
GPT-4 is currently in a limited beta and only accessible to those who have been granted access. Please join the waitlist to get access when capacity is available.
GPT-4目前處於有限的測試階段,只有那些被授予存取許可權的人才能存取。請加入等待名單,以便在容量可用時獲得存取許可權。

For many basic tasks, the difference between GPT-4 and GPT-3.5 models is not significant. However, in more complex reasoning situations, GPT-4 is much more capable than any of our previous models.
對於許多基本任務,GPT-4和GPT-3. 5模型之間的差異並不顯著。然而,在更復雜的推理情況下,GPT-4比我們以前的任何模型都要強大得多。
GPT-3.5
GPT-3.5 models can understand and generate natural language or code. Our most capable and cost effective model in the GPT-3.5 family is gpt-3.5-turbo which has been optimized for chat but works well for traditional completions tasks as well.
GPT-3.5模型可以理解並生成自然語言或程式碼。GPT-3.5系列中功能最強大、最具成本效益的模型是 gpt-3.5-turbo ,它已針對聊天進行了優化,但也適用於傳統的完成任務。

We recommend using gpt-3.5-turbo over the other GPT-3.5 models because of its lower cost.
我們建議使用 gpt-3.5-turbo 而不是其他GPT-3.5模型,因為它的成本更低。
OpenAI models are non-deterministic, meaning that identical inputs can yield different outputs. Setting temperature to 0 will make the outputs mostly deterministic, but a small amount of variability may remain.
OpenAI模型是不確定的,這意味著相同的輸入可能產生不同的輸出。將溫度設定為0將使輸出基本上具有確定性,但可能仍存在少量變化。
Feature-specific models 特定功能的模型
While the new gpt-3.5-turbo model is optimized for chat, it works very well for traditional completion tasks. The original GPT-3.5 models are optimized for text completion.
雖然新的 gpt-3.5-turbo 模型針對聊天進行了優化,但它對傳統的完成任務也非常有效。原始GPT-3.5模型針對文字完成進行了優化。
Our endpoints for creating embeddings and editing text use their own sets of specialized models.
我們用於建立嵌入和編輯文字的端點使用它們自己的專用模型集。
Finding the right model 尋找合適的模型
Experimenting with gpt-3.5-turbo is a great way to find out what the API is capable of doing. After you have an idea of what you want to accomplish, you can stay with gpt-3.5-turbo or another model and try to optimize around its capabilities.
試驗 gpt-3.5-turbo 是瞭解API功能的好方法。當你對你想要完成的事情有了一個想法之後,你可以繼續使用 gpt-3.5-turbo 或其他模型,並嘗試圍繞它的功能進行優化。
You can use the GPT comparison tool that lets you run different models side-by-side to compare outputs, settings, and response times and then download the data into an Excel spreadsheet.
您可以使用GPT比較工具,該工具允許您並行執行不同的模型,以比較輸出、設定和響應時間,然後將資料下載到Excel電子試算表中。
DALL·E Beta
DALL·E is a AI system that can create realistic images and art from a description in natural language. We currently support the ability, given a prommpt, to create a new image with a certain size, edit an existing image, or create variations of a user provided image.
DALL·E是一個人工智慧系統,可以從自然語言的描述中創造出逼真的影象和藝術。我們目前支援的能力,給予提示,以建立一個新的影象與一定的大小,編輯現有的影象,或建立一個使用者提供的影象的變化。
The current DALL·E model available through our API is the 2nd iteration of DALL·E with more realistic, accurate, and 4x greater resolution images than the original model. You can try it through the our Labs interface or via the API.
通過我們的API提供的當前DALL·E模型是DALL·E的第二次迭代,具有比原始模型更真實、更準確和解析度高4倍的影象。您可以通過我們的實驗室介面或通過API進行嘗試。
Whisper Beta
Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification. The Whisper v2-large model is currently available through our API with the whisper-1 model name.
Whisper是一種通用的語音識別模型。它是在一個大的資料集上訓練的,並且是一個多工模型,可以執行多語言語音識別以及語音翻譯和語言識別。Whisper v2-large模型目前可通過我們的API獲得,模型名稱為 whisper-1 。
Currently, there is no difference between the open source version of Whisper and the version available through our API. However, through our API, we offer an optimized inference process which makes running Whisper through our API much faster than doing it through other means. For more technical details on Whisper, you can read the paper.
目前,Whisper的開源版本和通過我們的API提供的版本之間沒有區別。然而,通過我們的API,我們提供了一個優化的推理過程,這使得通過我們的API執行Whisper比通過其他方式快得多。想了解更多關於Whisper的技術細節,你可以閱讀報紙。
Embeddings 嵌入
Embeddings are a numerical representation of text that can be used to measure the relateness between two pieces of text. Our second generation embedding model, text-embedding-ada-002 is a designed to replace the previous 16 first-generation embedding models at a fraction of the cost. Embeddings are useful for search, clustering, recommendations, anomaly detection, and classification tasks. You can read more about our latest embedding model in the announcement blog post.
嵌入是文字的數位表示,可用於度量兩段文字之間的相關性。我們的第二代嵌入模型 text-embedding-ada-002 旨在以很小的成本取代之前的16個第一代嵌入模型。嵌入對於搜尋、聚類、推薦、異常檢測和分類任務非常有用。您可以在公告部落格中閱讀更多關於我們最新嵌入模型的資訊。
Codex Limited beta
The Codex models are descendants of our GPT-3 models that can understand and generate code. Their training data contains both natural language and billions of lines of public code from GitHub. Learn more.
Codex模型是GPT-3模型的後代,可以理解和生成程式碼。他們的訓練資料既包含自然語言,也包含來自GitHub的數十億行公共程式碼。 瞭解更多資訊。
They’re most capable in Python and proficient in over a dozen languages including JavaScript, Go, Perl, PHP, Ruby, Swift, TypeScript, SQL, and even Shell.
他們最擅長Python,精通十幾種語言,包括JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL,甚至Shell。
We currently offer two Codex models:
我們目前提供兩種Codex模型:

For more, visit our guide on working with Codex.
欲瞭解更多資訊,請存取我們的Codex使用指南。
Moderation 稽核
The Moderation models are designed to check whether content complies with OpenAI's usage policies. The models provide classification capabilities that look for content in the following categories: hate, hate/threatening, self-harm, sexual, sexual/minors, violence, and violence/graphic. You can find out more in our moderation guide.
稽核模型被設計用來檢查內容是否符合OpenAI的使用策略。這些模型提供了分類功能,可按以下類別查詢內容:仇恨、仇恨/威脅、自殘、性、性/未成年人、暴力和暴力/圖形。您可以在我們的稽核指南中找到更多資訊。
Moderation models take in an arbitrary sized input that is automatically broken up to fix the models specific context window.
稽核模型接受任意大小的輸入,這些輸入被自動分解以修復模型特定的上下文視窗。

GPT-3
GPT-3 models can understand and generate natural language. These models were superceded by the more powerful GPT-3.5 generation models. However, the original GPT-3 base models (davinci, curie, ada, and babbage) are current the only models that are available to fine-tune.
GPT-3模型能夠理解和生成自然語言。這些型號被更強大的GPT-3.5代模型所取代。但是,原始GPT-3基本模型(davinci、 curie 、 ada 和 babbage )是當前唯一可進行微調的模型。

Model endpoint compatibility 模型端點相容性

This list does not include our first-generation embedding models nor our DALL·E models.
此列表不包括我們的第一代嵌入模型和DALL·E模型。
Continuous model upgrades 持續模型升級
With the release of gpt-3.5-turbo, some of our models are now being continually updated. In order to mitigate the chance of model changes affecting our users in an unexpected way, we also offer model versions that will stay static for 3 month periods. With the new cadence of model updates, we are also giving people the ability to contribute evals to help us improve the model for different use cases. If you are interested, check out the OpenAI Evals repository.
隨著 gpt-3.5-turbo 的釋出,我們的一些模型現在正在不斷更新。為了減少模型更改以意外方式影響使用者的可能性,我們還提供了將在3個月內保持靜態的模型版本。隨著模型更新的新節奏,我們還讓人們能夠貢獻評估,以幫助我們針對不同的用例改進模型。如果您感興趣,請檢視OpenAI Evals儲存庫。
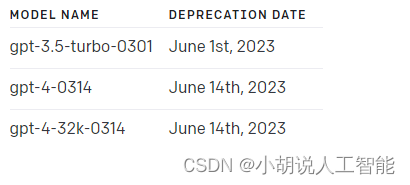
The following models are the temporary snapshots that will be deprecated at the specified date. If you want to use the latest model version, use the standard model names like gpt-4 or gpt-3.5-turbo.
以下模型是將在指定日期棄用的臨時快照。如果要使用最新的模型版本,請使用標準模型名稱,如 gpt-4 或 gpt-3.5-turbo 。
其它資料下載
如果大家想繼續瞭解人工智慧相關學習路線和知識體系,歡迎大家翻閱我的另外一篇部落格《重磅 | 完備的人工智慧AI 學習——基礎知識學習路線,所有資料免關注免套路直接網路硬碟下載》
這篇部落格參考了Github知名開源平臺,AI技術平臺以及相關領域專家:Datawhale,ApacheCN,AI有道和黃海廣博士等約有近100G相關資料,希望能幫助到所有小夥伴們。