乾貨 | BitSail Connector 開發詳解系列一:Source
更多技術交流、求職機會,歡迎關注位元組跳動資料平臺微信公眾號,回覆【1】進入官方交流群
BitSail 是位元組跳動自研的資料整合產品,支援多種異構資料來源間的資料同步,並提供離線、實時、全量、增量場景下全域資料整合解決方案。本系列聚焦 BitSail Connector 開發模組,為大家帶來詳細全面的開發方法與場景範例,本篇將主要介紹 Source 介面部分。
持續關注,BitSail Connector 開發詳解將分為四篇呈現。
-
BitSail Connector 開發詳解系列一:Source
-
BitSail Connector 開發詳解系列二:SourceSplitCoordinator
-
BitSail Connector 開發詳解系列三:SourceReader
-
BitSail Connector 開發詳解系列四:Sink、Writer
Source Connector
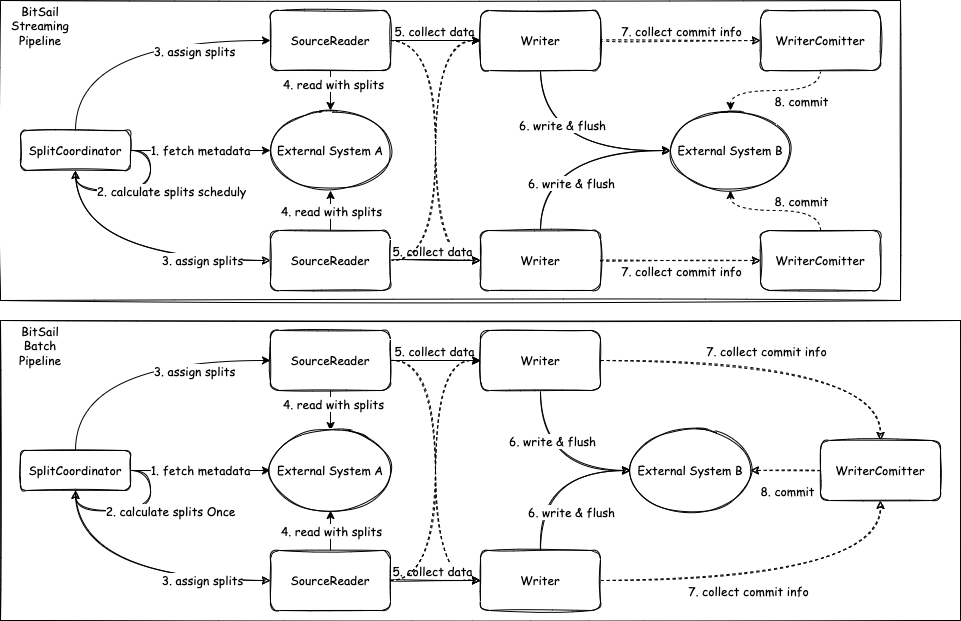
本文將主要介紹 Source 介面部分:
-
Source: 參與資料讀取元件的生命週期管理,主要負責和框架的互動,構架作業,不參與作業真正的執行。
-
SourceSplit: 資料讀取分片,巨量資料處理框架的核心目的就是將大規模的資料拆分成為多個合理的 Split 並行處理。
-
State:作業狀態快照,當開啟 checkpoint 之後,會儲存當前執行狀態。
Source
資料讀取元件的生命週期管理,主要負責和框架的互動,構架作業,它不參與作業真正的執行。
以 RocketMQSource 為例:Source 方法需要實現 Source 和 ParallelismComputable 介面。
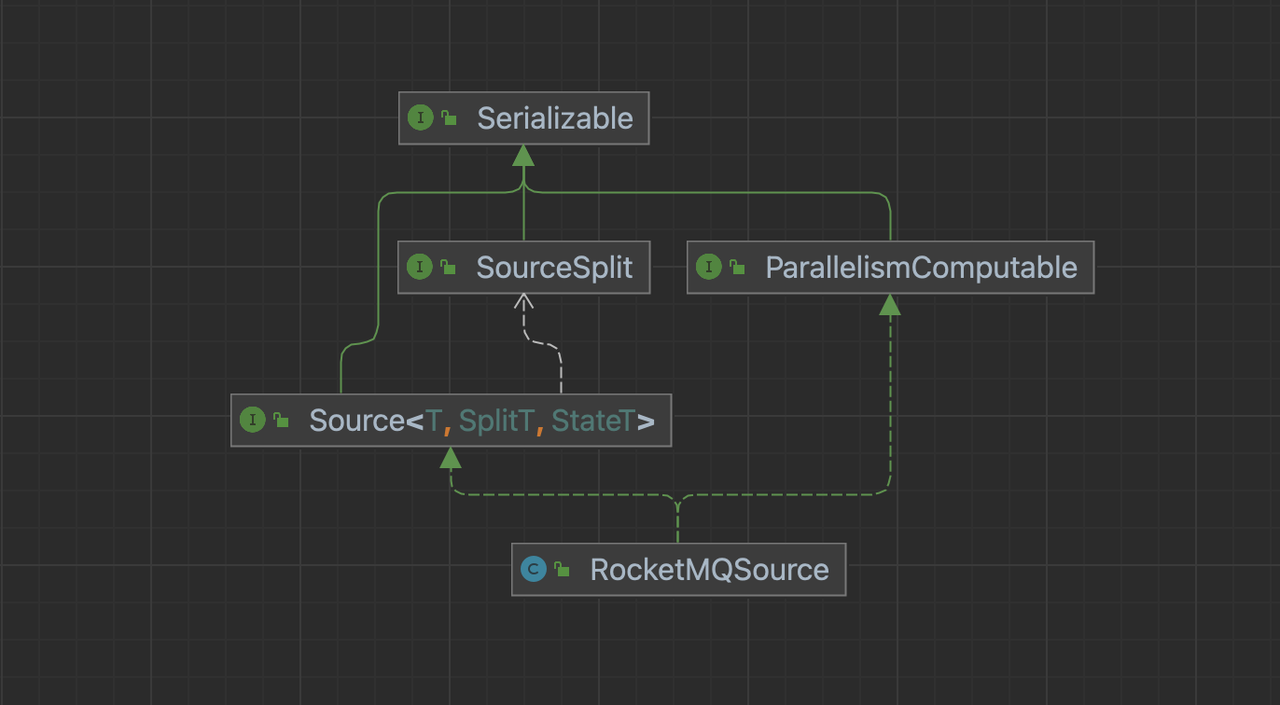
Source 介面
public interface Source<T, SplitT extends SourceSplit, StateT extends Serializable> extends Serializable, TypeInfoConverterFactory { /** * Run in client side for source initialize; */ void configure(ExecutionEnviron execution, BitSailConfiguration readerConfiguration) throws IOException; /** * Indicate the Source type. */ Boundedness getSourceBoundedness(); /** * Create Source Reader. */ SourceReader<T, SplitT> createReader(SourceReader.Context readerContext); /** * Create split coordinator. */ SourceSplitCoordinator<SplitT, StateT> createSplitCoordinator(SourceSplitCoordinator.Context<SplitT, StateT> coordinatorContext); /** * Get Split serializer for the framework,{@link SplitT}should implement from {@link Serializable} */ default BinarySerializer<SplitT> getSplitSerializer() { return new SimpleBinarySerializer<>(); } /** * Get State serializer for the framework, {@link StateT}should implement from {@link Serializable} */ default BinarySerializer<StateT> getSplitCoordinatorCheckpointSerializer() { return new SimpleBinarySerializer<>(); } /** * Create type info converter for the source, default value {@link BitSailTypeInfoConverter} */ default TypeInfoConverter createTypeInfoConverter() { return new BitSailTypeInfoConverter(); } /** * Get Source' name. */ String getReaderName(); }
configure 方法
主要去做一些使用者端的設定的分發和提取,可以操作執行時環境 ExecutionEnviron 的設定和 readerConfiguration 的設定。
範例
@Override public void configure(ExecutionEnviron execution, BitSailConfiguration readerConfiguration) { this.readerConfiguration = readerConfiguration; this.commonConfiguration = execution.getCommonConfiguration(); }
getSourceBoundedness 方法
設定作業的處理方式,是採用流式處理方法、批式處理方法,或者是流批一體的處理方式,在流批一體的場景中,我們需要根據作業的不同型別設定不同的處理方式。
具體對應關係如下:
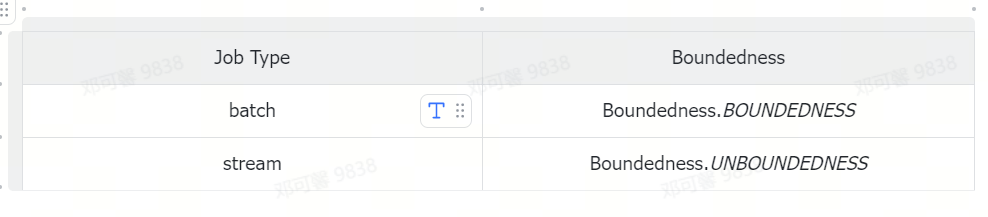
流批一體場景範例
@Override public Boundedness getSourceBoundedness() { return Mode.BATCH.equals(Mode.getJobRunMode(commonConfiguration.get(CommonOptions.JOB_TYPE))) ? Boundedness.BOUNDEDNESS : Boundedness.UNBOUNDEDNESS; }
流批一體場景範例
@Override public Boundedness getSourceBoundedness() { return Mode.BATCH.equals(Mode.getJobRunMode(commonConfiguration.get(CommonOptions.JOB_TYPE))) ? Boundedness.BOUNDEDNESS : Boundedness.UNBOUNDEDNESS; }
createTypeInfoConverter 方法
用於指定 Source 聯結器的型別轉換器;我們知道大多數的外部資料系統都存在著自己的型別定義,它們的定義與 BitSail 的型別定義不會完全一致;為了簡化型別定義的轉換,我們支援了通過組態檔來對映兩者之間的關係,進而來簡化組態檔的開發。
在行為上表現為對任務描述 Json 檔案中reader部分的columns的解析,對於columns中不同欄位的 type 會根據上面描述檔案從ClickhouseReaderOptions.COLUMNS欄位中解析到readerContext.getTypeInfos()中。
實現
-
BitSailTypeInfoConverter預設的
TypeInfoConverter,直接對ReaderOptions.COLUMNS欄位進行字串的直接解析,COLUMNS欄位中是什麼型別,TypeInfoConverter中就是什麼型別。 -
FileMappingTypeInfoConverter會在 BitSail 型別系統轉換時去繫結
{readername}-type-converter.yaml檔案,做資料庫欄位型別和 BitSail 型別的對映。ReaderOptions.COLUMNS欄位在通過這個對映檔案轉換後才會對映到TypeInfoConverter中。
範例
FileMappingTypeInfoConverter
通過 JDBC 方式連線的資料庫,包括 MySql、Oracle、SqlServer、Kudu、ClickHouse 等。這裡資料來源的特點是以java.sql.ResultSet的介面形式返回獲取的資料,對於這類資料庫,我們往往將TypeInfoConverter物件設計為FileMappingTypeInfoConverter,這個物件會在 BitSail 型別系統轉換時去繫結{readername}-type-converter.yaml檔案,做資料庫欄位型別和 BitSail 型別的對映。
@Override public TypeInfoConverter createTypeInfoConverter() { return new FileMappingTypeInfoConverter(getReaderName()); }
對於{readername}-type-converter.yaml檔案的解析,以clickhouse-type-converter.yaml為例。
# Clickhouse Type to BitSail Type engine.type.to.bitsail.type.converter: - source.type: int32 target.type: int - source.type: float64 target.type: double - source.type: string target.type: string - source.type: date target.type: date.date - source.type: null target.type: void # BitSail Type to Clickhouse Type bitsail.type.to.engine.type.converter: - source.type: int target.type: int32 - source.type: double target.type: float64 - source.type: date.date target.type: date - source.type: string target.type: string
這個檔案起到的作用是進行 job 描述 json 檔案中reader部分的columns的解析,對於columns中不同欄位的 type 會根據上面描述檔案從ClickhouseReaderOptions.COLUMNS欄位中解析到readerContext.getTypeInfos()中。
"reader": { "class": "com.bytedance.bitsail.connector.clickhouse.source.ClickhouseSource", "jdbc_url": "jdbc:clickhouse://localhost:8123", "db_name": "default", "table_name": "test_ch_table", "split_field": "id", "split_config": "{\"name\": \"id\", \"lower_bound\": 0, \"upper_bound\": \"10000\", \"split_num\": 3}", "sql_filter": "( id % 2 == 0 )", "columns": [ { "name": "id", "type": "int64" }, { "name": "int_type", "type": "int32" }, { "name": "double_type", "type": "float64" }, { "name": "string_type", "type": "string" }, { "name": "p_date", "type": "date" } ] },
這種方式不僅僅適用於資料庫,也適用於所有需要在型別轉換中需要引擎側和 BitSail 側進行型別對映的場景。
BitSailTypeInfoConverter
通常採用預設的方式進行型別轉換,直接對ReaderOptions.COLUMNS欄位進行字串的直接解析。
@Override public TypeInfoConverter createTypeInfoConverter() { return new BitSailTypeInfoConverter(); }
以 Hadoop 為例:
"reader": { "class": "com.bytedance.bitsail.connector.hadoop.source.HadoopSource", "path_list": "hdfs://127.0.0.1:9000/test_namespace/source/test.json", "content_type":"json", "reader_parallelism_num": 1, "columns": [ { "name":"id", "type": "int" }, { "name": "string_type", "type": "string" }, { "name": "map_string_string", "type": "map<string,string>" }, { "name": "array_string", "type": "list<string>" } ] }
createSourceReader 方法
書寫具體的資料讀取邏輯,負責資料讀取的元件,在接收到 Split 後會對其進行資料讀取,然後將資料傳輸給下一個運算元。
具體傳入構造 SourceReader 的引數按需求決定,但是一定要保證所有引數可以序列化。如果不可序列化,將會在 createJobGraph 的時候出錯。
範例
public SourceReader<Row, RocketMQSplit> createReader(SourceReader.Context readerContext) { return new RocketMQSourceReader( readerConfiguration, readerContext, getSourceBoundedness()); }
createSplitCoordinator 方法
書寫具體的資料分片、分片分配邏輯,SplitCoordinator 承擔了去建立、管理 Split 的角色。
具體傳入構造 SplitCoordinator 的引數按需求決定,但是一定要保證所有引數可以序列化。如果不可序列化,將會在 createJobGraph 的時候出錯。
範例
public SourceSplitCoordinator<RocketMQSplit, RocketMQState> createSplitCoordinator(SourceSplitCoordinator .Context<RocketMQSplit, RocketMQState> coordinatorContext) { return new RocketMQSourceSplitCoordinator( coordinatorContext, readerConfiguration, getSourceBoundedness()); }
ParallelismComputable 介面
public interface ParallelismComputable extends Serializable { /** * give a parallelism advice for reader/writer based on configurations and upstream parallelism advice * * @param commonConf common configuration * @param selfConf reader/writer configuration * @param upstreamAdvice parallelism advice from upstream (when an operator has no upstream in DAG, its upstream is * global parallelism) * @return parallelism advice for the reader/writer */ ParallelismAdvice getParallelismAdvice(BitSailConfiguration commonConf, BitSailConfiguration selfConf, ParallelismAdvice upstreamAdvice) throws Exception; }
getParallelismAdvice 方法
用於指定下游 reader 的並行數目。一般有以下的方式:
可以選擇selfConf.get(ClickhouseReaderOptions.READER_PARALLELISM_NUM)來指定並行度。
也可以自定義自己的並行度劃分邏輯。
範例
比如在 RocketMQ 中,我們可以定義每 1 個 reader 可以處理至多 4 個佇列DEFAULT_ROCKETMQ_PARALLELISM_THRESHOLD= 4
通過這種自定義的方式獲取對應的並行度。
public ParallelismAdvice getParallelismAdvice(BitSailConfiguration commonConfiguration, BitSailConfiguration rocketmqConfiguration, ParallelismAdvice upstreamAdvice) throws Exception { String cluster = rocketmqConfiguration.get(RocketMQSourceOptions.CLUSTER); String topic = rocketmqConfiguration.get(RocketMQSourceOptions.TOPIC); String consumerGroup = rocketmqConfiguration.get(RocketMQSourceOptions.CONSUMER_GROUP); DefaultLitePullConsumer consumer = RocketMQUtils.prepareRocketMQConsumer(rocketmqConfiguration, String.format(SOURCE_INSTANCE_NAME_TEMPLATE, cluster, topic, consumerGroup, UUID.randomUUID() )); try { consumer.start(); Collection<MessageQueue> messageQueues = consumer.fetchMessageQueues(topic); int adviceParallelism = Math.max(CollectionUtils.size(messageQueues) / DEFAULT_ROCKETMQ_PARALLELISM_THRESHOLD, 1); return ParallelismAdvice.builder() .adviceParallelism(adviceParallelism) .enforceDownStreamChain(true) .build(); } finally { consumer.shutdown(); } } }
SourceSplit
資料來源的資料分片格式,需要我們實現 SourceSplit 介面。
SourceSplit 介面
要求我們實現一個實現一個獲取 splitId 的方法。
public interface SourceSplit extends Serializable { String uniqSplitId(); }
對於具體切片的格式,開發者可以按照自己的需求進行自定義。
範例
JDBC 類儲存
一般會通過主鍵,來對資料進行最大、最小值的劃分;對於無主鍵類則通常會將其認定為一個 split,不再進行拆分,所以 split 中的引數包括主鍵的最大最小值,以及一個布林型別的readTable,如果無主鍵類或是不進行主鍵的切分則整張表會視為一個 split,此時readTable為true,如果按主鍵最大最小值進行切分,則設定為false。
以 ClickhouseSourceSplit 為例:
@Setter public class ClickhouseSourceSplit implements SourceSplit { public static final String SOURCE_SPLIT_PREFIX = "clickhouse_source_split_"; private static final String BETWEEN_CLAUSE = "( `%s` BETWEEN ? AND ? )"; private final String splitId; /** * Read whole table or range [lower, upper] */ private boolean readTable; private Long lower; private Long upper; public ClickhouseSourceSplit(int splitId) { this.splitId = SOURCE_SPLIT_PREFIX + splitId; } @Override public String uniqSplitId() { return splitId; } public void decorateStatement(PreparedStatement statement) { try { if (readTable) { lower = Long.MIN_VALUE; upper = Long.MAX_VALUE; } statement.setObject(1, lower); statement.setObject(2, upper); } catch (SQLException e) { throw BitSailException.asBitSailException(CommonErrorCode.RUNTIME_ERROR, "Failed to decorate statement with split " + this, e.getCause()); } } public static String getRangeClause(String splitField) { return StringUtils.isEmpty(splitField) ? null : String.format(BETWEEN_CLAUSE, splitField); } @Override public String toString() { return String.format( "{\"split_id\":\"%s\", \"lower\":%s, \"upper\":%s, \"readTable\":%s}", splitId, lower, upper, readTable); } }
訊息佇列
一般按照訊息佇列中 topic 註冊的 partitions 的數量進行 split 的劃分,切片中主要應包含消費的起點和終點以及消費的佇列。
以 RocketMQSplit 為例:
@Builder @Getter public class RocketMQSplit implements SourceSplit { private MessageQueue messageQueue; @Setter private long startOffset; private long endOffset; private String splitId; @Override public String uniqSplitId() { return splitId; } @Override public String toString() { return "RocketMQSplit{" + "messageQueue=" + messageQueue + ", startOffset=" + startOffset + ", endOffset=" + endOffset + '}'; } }
檔案系統
一般會按照檔案作為最小粒度進行劃分,同時有些格式也支援將單個檔案拆分為多個子 Splits。檔案系統 split 中需要包裝所需的檔案切片。
以 FtpSourceSplit 為例:
public class FtpSourceSplit implements SourceSplit { public static final String FTP_SOURCE_SPLIT_PREFIX = "ftp_source_split_"; private final String splitId; @Setter private String path; @Setter private long fileSize; public FtpSourceSplit(int splitId) { this.splitId = FTP_SOURCE_SPLIT_PREFIX + splitId; } @Override public String uniqSplitId() { return splitId; } @Override public boolean equals(Object obj) { return (obj instanceof FtpSourceSplit) && (splitId.equals(((FtpSourceSplit) obj).splitId)); } }
特別的,在 Hadoop 檔案系統中,我們也可以利用對org.apache.hadoop.mapred.InputSplit類的包裝來自定義我們的 Split。
public class HadoopSourceSplit implements SourceSplit { private static final long serialVersionUID = 1L; private final Class<? extends InputSplit> splitType; private transient InputSplit hadoopInputSplit; private byte[] hadoopInputSplitByteArray; public HadoopSourceSplit(InputSplit inputSplit) { if (inputSplit == null) { throw new NullPointerException("Hadoop input split must not be null"); } this.splitType = inputSplit.getClass(); this.hadoopInputSplit = inputSplit; } public InputSplit getHadoopInputSplit() { return this.hadoopInputSplit; } public void initInputSplit(JobConf jobConf) { if (this.hadoopInputSplit != null) { return; } checkNotNull(hadoopInputSplitByteArray); try { this.hadoopInputSplit = (InputSplit) WritableFactories.newInstance(splitType); if (this.hadoopInputSplit instanceof Configurable) { ((Configurable) this.hadoopInputSplit).setConf(jobConf); } else if (this.hadoopInputSplit instanceof JobConfigurable) { ((JobConfigurable) this.hadoopInputSplit).configure(jobConf); } if (hadoopInputSplitByteArray != null) { try (ObjectInputStream objectInputStream = new ObjectInputStream(new ByteArrayInputStream(hadoopInputSplitByteArray))) { this.hadoopInputSplit.readFields(objectInputStream); } this.hadoopInputSplitByteArray = null; } } catch (Exception e) { throw new RuntimeException("Unable to instantiate Hadoop InputSplit", e); } } private void writeObject(ObjectOutputStream out) throws IOException { if (hadoopInputSplit != null) { try ( ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream) ) { this.hadoopInputSplit.write(objectOutputStream); objectOutputStream.flush(); this.hadoopInputSplitByteArray = byteArrayOutputStream.toByteArray(); } } out.defaultWriteObject(); } @Override public String uniqSplitId() { return hadoopInputSplit.toString(); } }
State
在需要做 checkpoint 的場景下,通常我們會通過 Map 來保留當前的執行狀態
流批一體場景
在流批一體場景中,我們需要儲存狀態以便從異常中斷的流式作業恢復
以 RocketMQState 為例:
public class RocketMQState implements Serializable { private final Map<MessageQueue, String> assignedWithSplitIds; public RocketMQState(Map<MessageQueue, String> assignedWithSplitIds) { this.assignedWithSplitIds = assignedWithSplitIds; } public Map<MessageQueue, String> getAssignedWithSplits() { return assignedWithSplitIds; } }
批式場景
對於批式場景,我們可以使用EmptyState不儲存狀態,如果需要狀態儲存,和流批一體場景採用相似的設計方案。
public class EmptyState implements Serializable { public static EmptyState fromBytes() { return new EmptyState(); } }