Kakao Brain 的開源 ViT、ALIGN 和 COYO 文字-圖片資料集
最近 Kakao Brain 在 Hugging Face 釋出了一個全新的開源影象文字資料集 COYO,包含 7 億對影象和文字,並訓練了兩個新的視覺語言模型 ViT 和 ALIGN ViT 和 ALIGN。
這是 ALIGN 模型首次公開發布供開源使用,同時 ViT 和 ALIGN 模型的釋出都附帶有訓練資料集。
Google 的 ViT 和 ALIGN 模型都使用了巨大的資料集 (ViT 訓練於 3 億張影象,ALIGN 訓練於 18 億個影象 - 文字對) 進行訓練,因為資料集不公開導致無法復現。Kakao Brain 的 ViT 和 ALIGN 模型採用與 Google 原始模型相同的架構和超引數,不同的是其在開源 COYO 資料集上進行訓練。對於想要擁有資料並復現視覺語言模型的研究人員有很大的價值。詳細的 Kakao ViT 和 ALIGN 模型資訊可以參照:
- COYO 資料集倉庫地址: https://github.com/kakaobrain/coyo-dataset
- Kakao Brain 檔案地址: https://hf.co/kakaobrain
這篇部落格將介紹新的 COYO 資料集、Kakao Brain 的 ViT 和 ALIGN 模型,以及如何使用它們!以下是主要要點:
- 第一個開源的 ALIGN 模型!
- 第一個在開源資料集 COYO 上訓練的開源 ViT 和 ALIGN 模型。
- Kakao Brain 的 ViT 和 ALIGN 模型表現與 Google 版本相當。
- ViT 模型在 HF 上可演示!您可以使用自己的影象樣本線上體驗 ViT!
效能比較
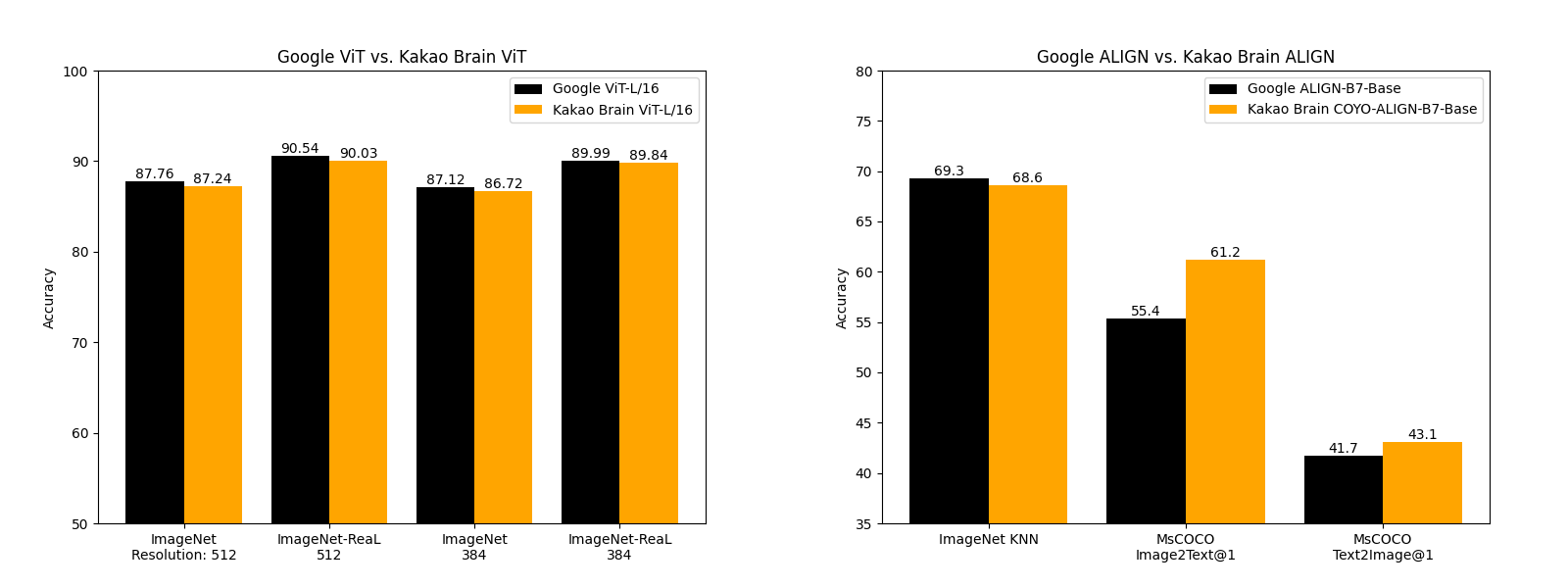
Kakao Brain 釋出的 ViT 和 ALIGN 模型與 Google 的模型表現相當,某些方面甚至更好。Kakao Brain 的 ALIGN-B7-Base 模型雖然訓練的資料對少得多 ( 7 億 VS 1.8 億),但在影象 KNN 分類任務上表現與 Google 的 ALIGN-B7-Base 相當,在 MS-COCO 影象 - 文字檢索、文字 - 影象檢索任務上表現更好。Kakao Brain 的 ViT-L/16 在 384×512 的 ImageNet 和 ImageNet-ReaL 資料上的表現與 Google 的 ViT-L/16 相當。這意味著同行可以使用 Kakao Brain 的 ViT 和 ALIGN 模型來複現 Google 的 ViT 和 ALIGN ,尤其是當用戶需要訓練資料時。所以我們很高興開源這些與現有技術相當的模型!
COYO 資料集

本次釋出的模型特別之處在於都是基於開源的 COYO 資料集訓練的。COYO 資料集包含 7 億影象 - 文字對,類似於 Google 的 ALIGN 1.8B影象 - 文字資料集,是從網頁上收集的「嘈雜」的 html 文字 (alt-text) 和影象對。 COYO-700M 和 ALIGN 1.8B都是「嘈雜」的,只使用了適當的清洗處理。 COYO 類似於另一個開源的影象–文字資料集 LAION,但有一些區別。儘管 LAION 2B是一個更大的資料集,包含 20 億個英語配對,但 COYO的附帶有更多後設資料,為使用者提供更多靈活性和更細粒度的使用。以下表格顯示了它們之間的區別: COYO所有資料對都提供了美感評分,更健壯的水印評分和麵部計數資訊 (face count data)。
| COYO | LAION 2B | ALIGN 1.8B |
|---|---|---|
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | Google Cloud API |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English | 1.8 billion |
| From CC 2020 Oct - 2021 Aug | From CC 2014-2020 | NA |
| Aesthetic Score | Aesthetic Score Partial | NA |
| More robust Watermark score | Watermark Score | NA |
| Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
ViT 和 ALIGN 是如何工作的
這些模型是幹什麼的?讓我們簡要討論一下 ViT 和 ALIGN 模型的工作原理。
ViT—Vision Transformer 是谷歌於 2020 年提出的一種視覺模型,類似於文字 Transformer 架構。這是一種與折積神經網路不同的視覺方法 (AlexNet 自 2012 年以來一直主導視覺任務)。同樣表現下,它的計算效率比 CNN 高達四倍,且具有域不可知性 (domain agnostic)。ViT 將輸入的影象分解成一系列影象塊 (patch),就像文字 Transformer 輸入文字序列一樣,然後為每個塊提供位置嵌入以學習影象結構。ViT 的效能尤其在於具有出色的效能 - 計算權衡。谷歌的一些 ViT 模型是開源的,但其訓練使用的 JFT-300 百萬影象 - 標籤對資料集尚未公開發布。Kakao Brain 的訓練模型是基於公開發布的 COYO-Labeled-300M 進行訓練,對應的 ViT 模型在各種任務上具有相似表現,其程式碼、模型和訓練資料 (COYO-Labeled-300M) 完全公開,以便能夠進行復現和科學研究。

谷歌在 2021 年推出了 ALIGN,它是一種基於「嘈雜」文字–影象資料訓練的視覺語言模型,可用於各種視覺和跨模態任務,如文字 - 影象檢索。ALIGN 採用簡單的雙編碼器架構,通過對比損失函數學習影象和文字對,ALIGN 的「嘈雜」訓練語料特點包括用語料規模彌補其噪音以及強大的魯棒性。之前的視覺語言表示學習都是在手動標註的大規模資料集上進行訓練,這就需要大量的預先處理和成本。ALIGN 的語料庫使用 HTML 文字 (alt-text) 資料作為影象的描述,導致資料集不可避免地嘈雜,但更大的資料量 (18 億對) 使 ALIGN 能夠在各種任務上表現出 SoTA 水平。Kakao Brain 的模型是第一個 ALIGN 開源版本,它在 COYO 資料集上訓練,表現比谷歌的結果更好。

如何使用 COYO 資料集
我們可以使用 Hugging Face