TCP 三次握手,給我長臉了噢
大家好,我是小富~
個人資源分享網站:FIRE
本文收錄在 Springboot-Notebook 面試錦集
前言
之前有個小夥伴在技術交流群裡諮詢過一個問題,我當時還給提供了點排查思路,是個典型的八股文轉實戰分析的案例,我覺得挺有意思,趁著中午休息簡單整理出來和大家分享下,有不嚴謹的地方歡迎大家指出。
問題分析
我們先來看看他的問題,下邊是他在群裡對這個問題的描述,我大致的總結了一下。
他們有很多的 IOT 裝置與伺服器端建立連線,當增加裝置並行請求變多,TCP連線數在接近1024個時,可用TCP連線數會降到200左右並且無法建立新連線,而且分析應用服務的GC和記憶體情況均未發現異常。

從他的描述中我提取了幾個關鍵值,1024、200、無法建立新連線。
看到這幾個數值,直覺告訴我大概率是TCP請求溢位了,我給的建議是先直接調大全連線佇列和半連線佇列的閥值試一下效果。
那為什麼我會給出這個建議?
半連線佇列和全連線佇列又是個啥玩意?
弄明白這些回顧下TCP的三次握手流程,一切就迎刃而解了~
回顧TCP
TCP三次握手,熟悉吧,面試八股裡經常全文背誦的題目。
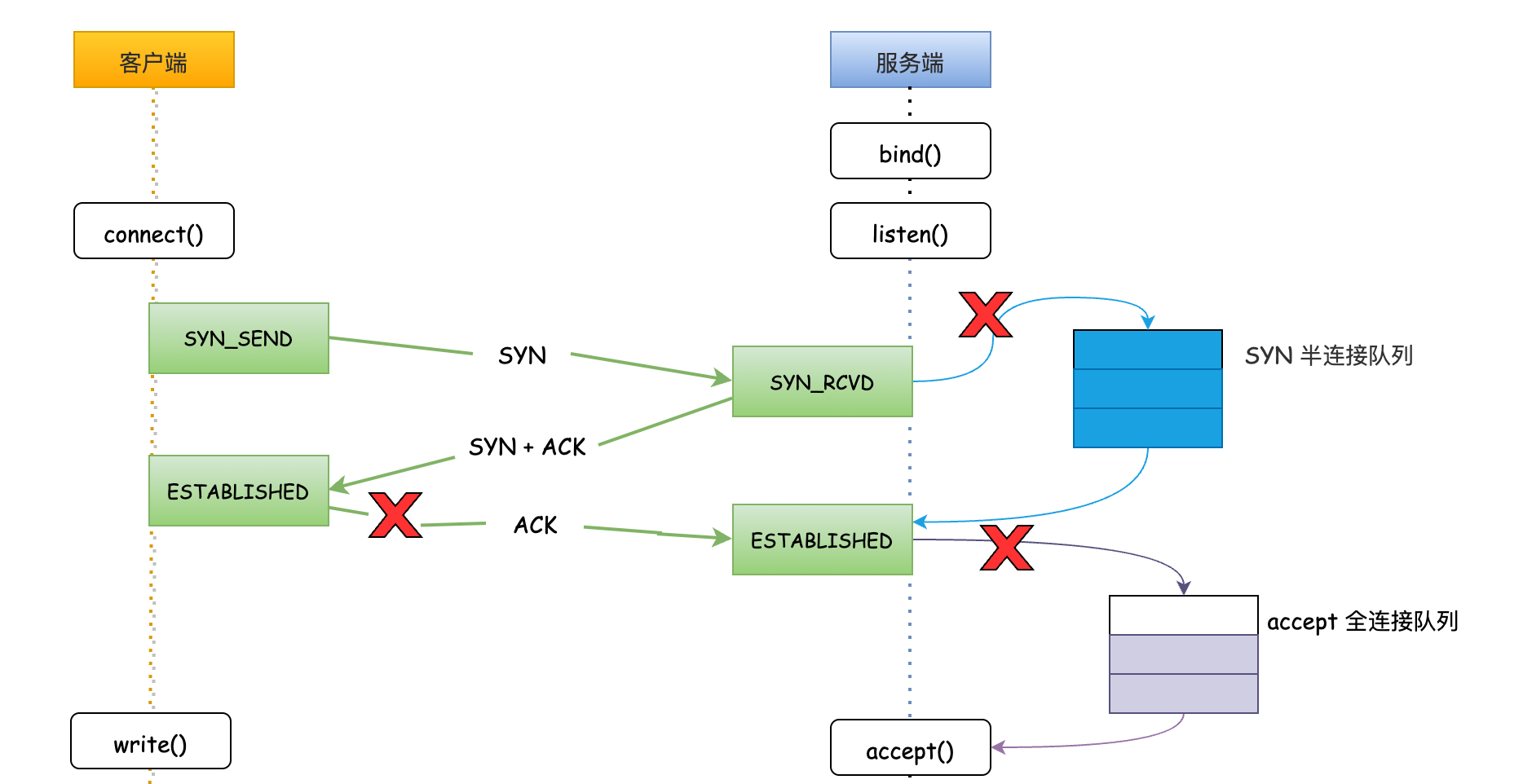
話不多說先上一張圖,看明白TCP連線的整個過程。
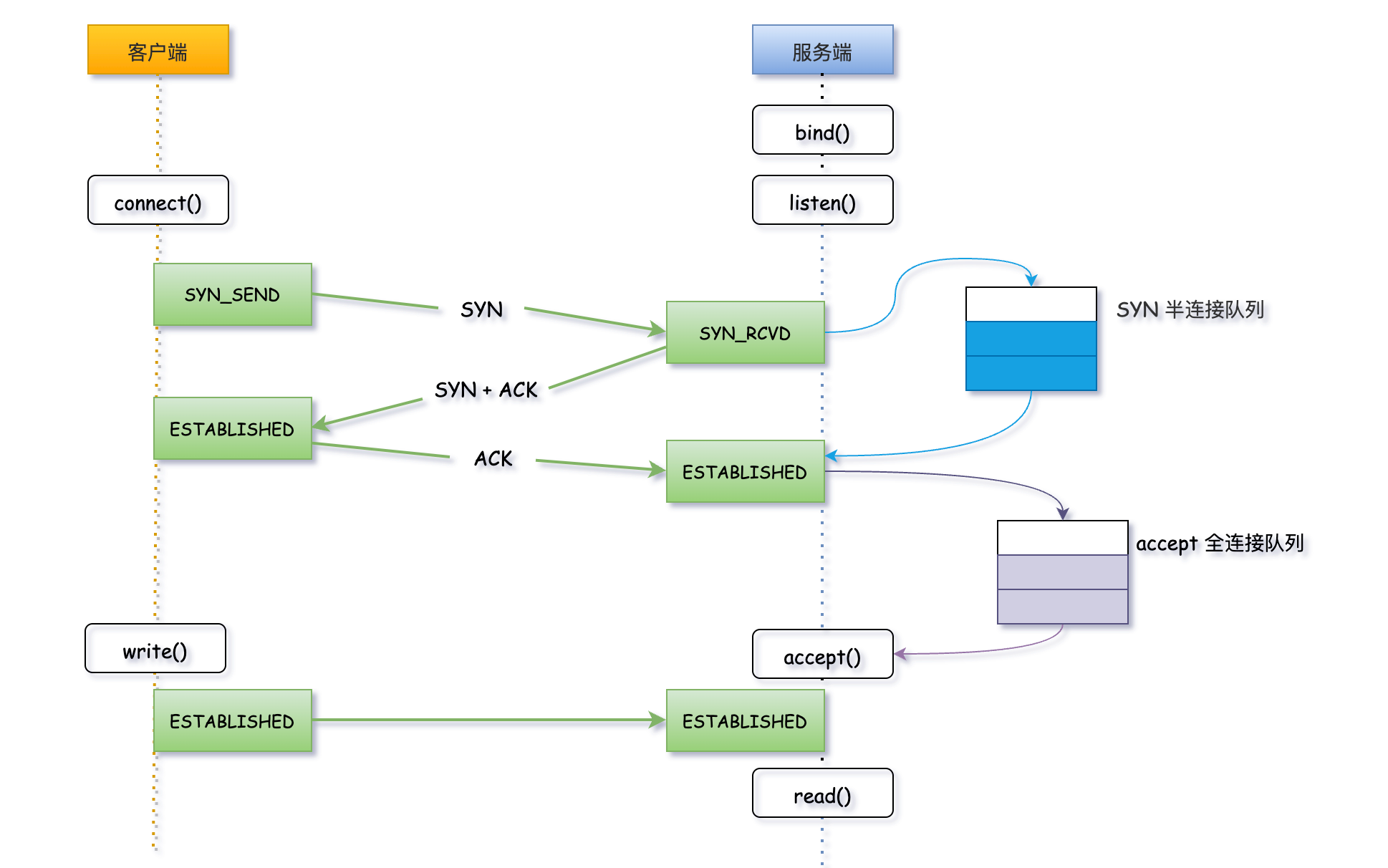
第一步:使用者端發起SYN_SEND連線請求,伺服器端收到使用者端發起的SYN請求後,會先將連線請求放入半連線佇列;
第二步:伺服器端向用戶端響應SYN+ACK;
第三步:使用者端會返回ACK確認,伺服器端收到第三次握手的 ACK 後標識連線成功。如果這時全連線佇列沒滿,核心會把連線從半連線佇列移除,建立新的連線並將其新增到全連線佇列,等待使用者端呼叫accept()方法將連線取出來使用;
TCP協定三次握手的過程,Linux核心維護了兩個佇列,SYN半連線佇列和accepet全連線佇列。即然叫佇列,那就存在佇列被壓滿的時候,這種情況我們稱之為佇列溢位。
當半連線佇列或全連線佇列滿了時,伺服器都無法接收新的連線請求,從而導致使用者端無法建立連線。
全連線佇列
佇列資訊
全連線佇列溢位時,首先要檢視全連線佇列的狀態,伺服器端通常使用 ss 命令即可檢視,ss 命令獲取的資料又分為 LISTEN狀態 和 非LISTEN兩種狀態下,通常只看LISTEN狀態資料就可以。
LISTEN狀態
Recv-Q:當前全連線佇列的大小,表示上圖中已完成三次握手等待可用的 TCP 連線個數;
Send-Q:全連線最大佇列長度,如上監聽8888埠的TCP連線最大全連線長度為128;
# -l 顯示正在Listener 的socket
# -n 不解析服務名稱
# -t 只顯示tcp
[root@VM-4-14-centos ~]# ss -lnt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 100 :::8888 :::*
非LISTEN 狀態下Recv-Q、Send-Q欄位含義有所不同
Recv-Q:已收到但未被應用程序讀取的位元組數;
Send-Q:已傳送但未收到確認的位元組數;
# -n 不解析服務名稱
# -t 只顯示tcp
[root@VM-4-14-centos ~]# ss -nt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 100 :::8888 :::*
佇列溢位
一般在請求量過大,全連線佇列設定過小會發生全連線佇列溢位,也就是LISTEN狀態下 Send-Q < Recv-Q 的情況。接收到的請求數大於TCP全連線佇列的最大長度,後續的請求將被伺服器端丟棄,使用者端無法建立新連線。
# -l 顯示正在Listener 的socket
# -n 不解析服務名稱
# -t 只顯示tcp
[root@VM-4-14-centos ~]# ss -lnt | grep 8888
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 200 100 :::8888 :::*
如果發生了全連線佇列溢位,我們可以通過netstat -s命令查詢溢位的累計次數,若這個times持續的增長,那就說明正在發生溢位。
[root@VM-4-14-centos ~]# netstat -s | grep overflowed
7102 times the listen queue of a socket overflowed #全連線佇列溢位的次數
拒絕策略
在全連線佇列已滿的情況,Linux提供了不同的策略去處理後續的請求,預設是直接丟棄,也可以通過tcp_abort_on_overflow設定來更改策略,其值 0 和 1 表示不同的策略,預設設定 0。
# 檢視策略
[root@VM-4-14-centos ~]# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow = 0:全連線佇列已滿時,伺服器端直接丟棄使用者端傳送的 ACK,此時伺服器端仍然是 SYN_RCVD 狀態,在該狀態下伺服器端會重試幾次向用戶端推播 SYN + ACK。
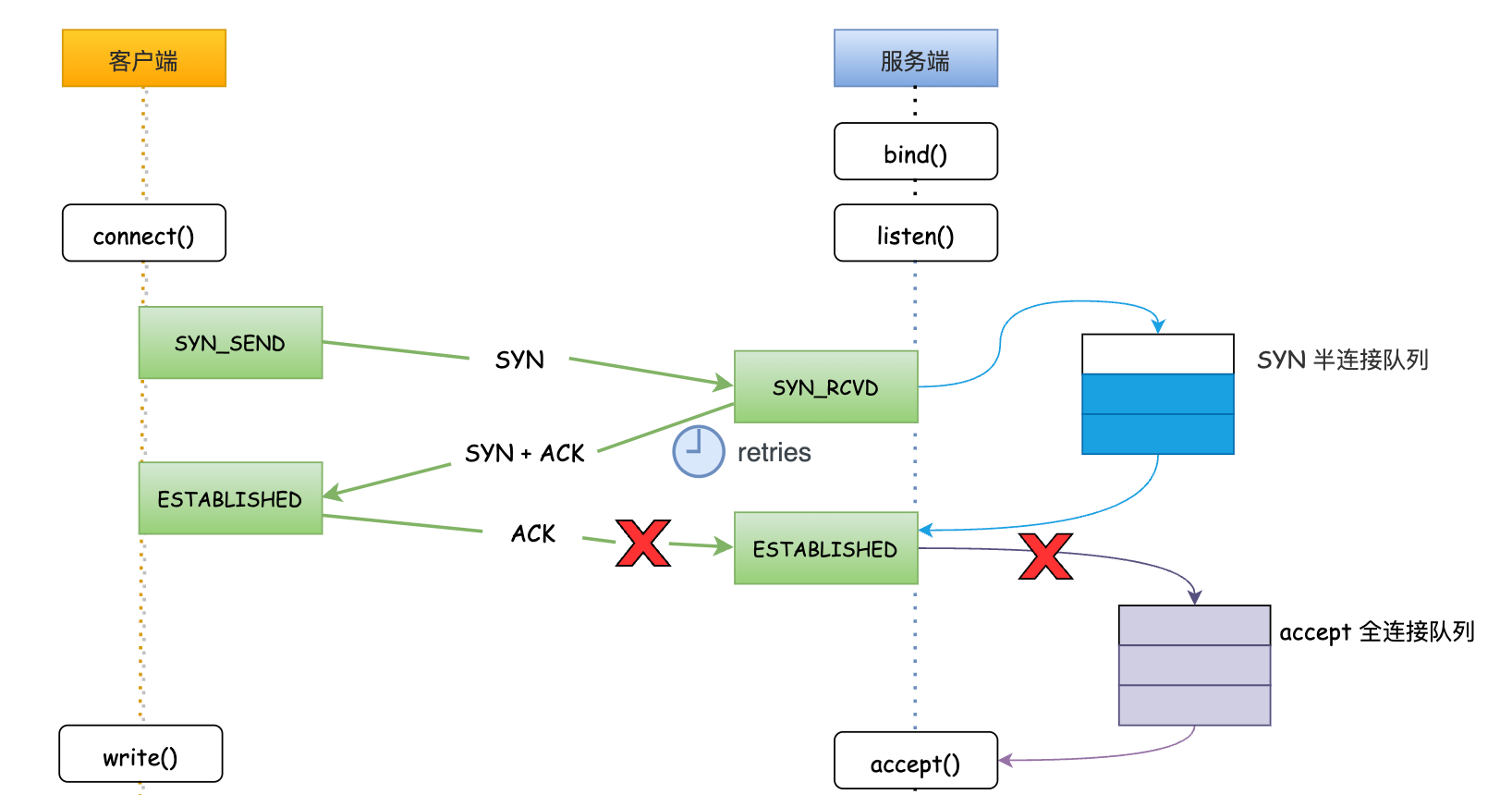
重試次數取決於tcp_synack_retries設定,重試次數超過此設定後後,伺服器端不在重傳,此時使用者端傳送資料,伺服器端直接向用戶端回覆RST復位報文,告知使用者端本次建立連線已失敗。
RST: 連線 reset 重置訊息,用於連線的異常關閉。常用場景例如:伺服器端接收不存在埠的連線請求;使用者端或者伺服器端異常,無法繼續正常的連線處理,傳送 RST 終止連線操作;長期未收到對方確認報文,經過一定時間或者重傳嘗試後,傳送 RST 終止連線。
[root@VM-4-14-centos ~]# cat /proc/sys/net/ipv4/tcp_synack_retries
0
tcp_abort_on_overflow = 1:全連線佇列已滿時,伺服器端直接丟棄使用者端傳送的 ACK,直接向用戶端回覆RST復位報文,告知使用者端本次連線終止,使用者端會報錯提示connection reset by peer。
佇列調整
解決全連線佇列溢位我們可以通過調整TCP引數來控制全連線佇列的大小,全連線佇列的大小取決於 backlog 和 somaxconn 兩個引數。
這裡需要注意一下,兩個引數要同時調整,因為取的兩者中最小值
min(backlog,somaxconn),經常發生只挑調大其中一個另一個值很小導致不生效的情況。
backlog 是在socket 建立的時候 Listen() 函數傳入的引數,例如我們也可以在 Nginx 設定中指定 backlog 的大小。
server {
listen 8888 default backlog = 200
server_name fire100.top
.....
}
somaxconn 是個 OS 級別的引數,預設值是 128,可以通過修改 net.core.somaxconn 設定。
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 128
[root@localhost core]# sysctl -w net.core.somaxconn=1024
net.core.somaxconn = 1024
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 1024
如果伺服器端處理請求的速度跟不上連線請求的到達速度,佇列可能會被快速填滿,導致連線超時或丟失。應該及時增加佇列大小,以避免連線請求被拒絕或超時。
增大該引數的值雖然可以增加佇列的容量,但是也會佔用更多的記憶體資源。一般來說,建議將全連線佇列的大小設定為伺服器處理能力的兩倍左右。
半連線佇列
佇列資訊
上邊TCP三次握手過程中,我們知道伺服器端SYN_RECV狀態的TCP連線存放在半連線佇列,所以直接執行如下命令檢視半連線佇列長度。
[root@VM-4-14-centos ~] netstat -natp | grep SYN_RECV | wc -l
1111
佇列溢位
半連線佇列溢位最常見的場景就是,使用者端沒有及時向伺服器端回ACK,使得伺服器端有大量處於SYN_RECV狀態的連線,導致半連線佇列被佔滿,得不到ACK響應半連線佇列中的 TCP 連線無法移動全連線佇列,以至於後續的SYN請求無法建立。這也是一種常見的DDos攻擊方式。
檢視TCP半連線佇列溢位情況,可以執行netstat -s命令,SYNs to LISTEN前的數值表示溢位的次數,如果反覆查詢幾次數值持續增加,那就說明半連線佇列正在溢位。
[root@VM-4-14-centos ~]# netstat -s | egrep 「listen|LISTEN」
1606 times the listen queue of a socket overflowed
1606 SYNs to LISTEN sockets ignored
佇列調整
可以修改 Linux 核心設定 /proc/sys/net/ipv4/tcp_max_syn_backlog來調大半連線佇列長度。
[root@VM-4-14-centos ~]# echo 2048 > /proc/sys/net/ipv4/tcp_max_syn_backlog
為什麼建議
看完上邊對兩個佇列的粗略介紹,相信大家也能大致明白,為啥我會直接建議他去調大佇列了。
因為從他的描述中提到了兩個關鍵值,TCP連線數增加至1024個時,可用連線數會降至200以內,一般centos系統全連線佇列長度一般預設 128,半連線佇列預設長度 1024。所以佇列溢位可以作為第一嫌疑物件。
全連線佇列預設大小 128
[root@localhost core]# sysctl -a | grep net.core.somaxconn
net.core.somaxconn = 128
半連線佇列預設大小 1024
[root@iZ2ze3ifc44ezdiif8jhf7Z ~]# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
總結
簡單分享了一點TCP全連線佇列、半連線佇列的相關內容,講的比較淺顯,如果有不嚴謹的地方歡迎留言指正,畢竟還是個老菜鳥。
全連線佇列、半連線佇列溢位是比較常見,但又容易被忽視的問題,往往上線會遺忘這兩個設定,一旦發生溢位,從CPU、執行緒狀態、記憶體看起來都比較正常,偏偏連線數上不去。
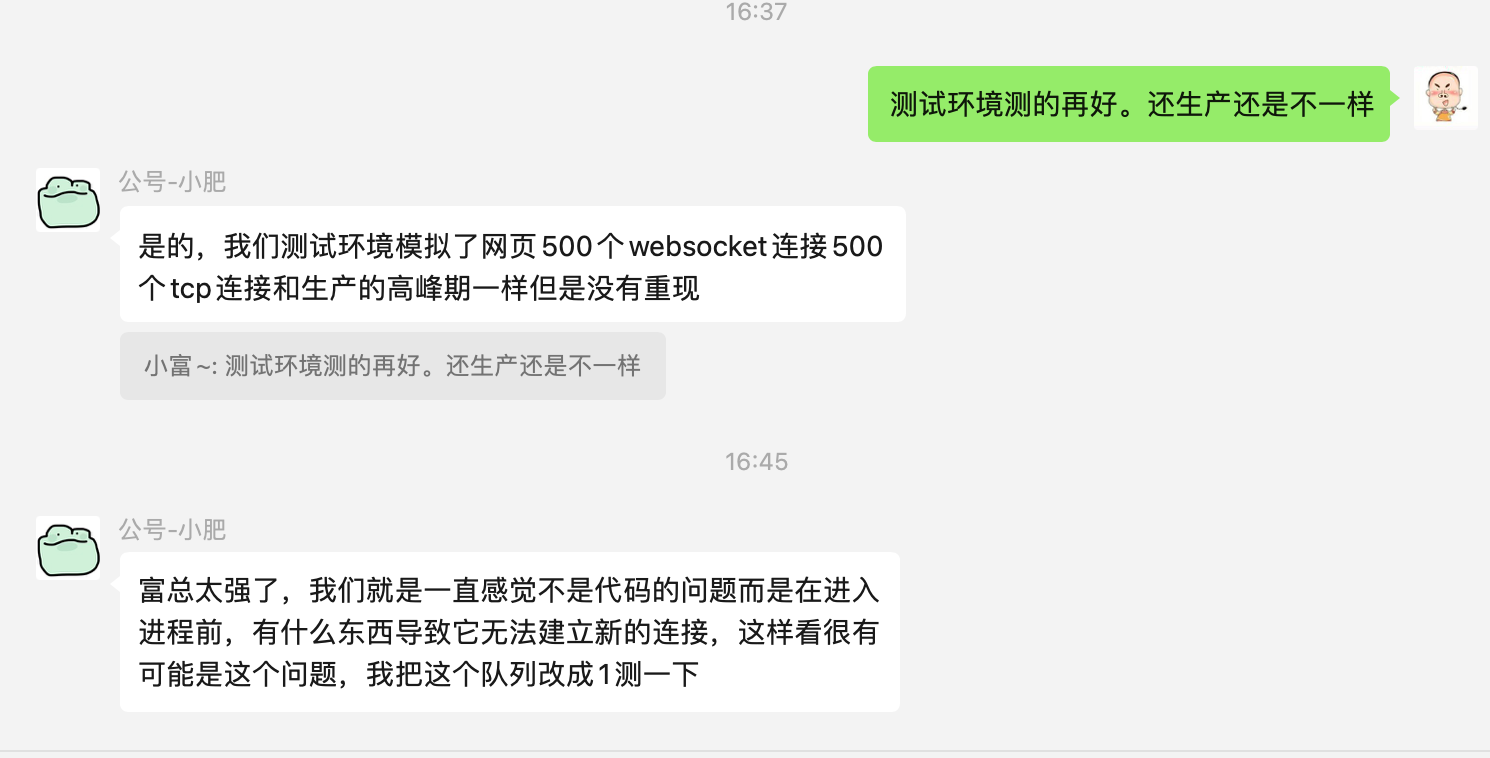
定期對系統壓測是可以暴露出更多問題的,不過話又說回來,就像我和小夥伴聊的一樣,即便測試環境程式跑的在穩定,到了線上環境也總會出現各種奇奇怪怪的問題。
我是小富,下期見~
技術交流,歡迎關注公眾號:程式設計師小富