【NLP 系列】Bert 詞向量的空間分佈
2023-03-16 12:01:28
作者:京東零售 彭馨
1. 背景
我們知道Bert 預訓練模型針對分詞、ner、文字分類等下游任務取得了很好的效果,但在語意相似度任務上,表現相較於 Word2Vec、Glove 等並沒有明顯的提升。有學者研究發現,這是因為 Bert 詞向量存在各向異性(不同方向表現出的特徵不一致),高頻詞分佈在狹小的區域,靠近原點,低頻詞訓練不充分,分佈相對稀疏,遠離原點,詞向量整體的空間分佈呈現錐形,如下圖,導致計算的相似度存在問題。
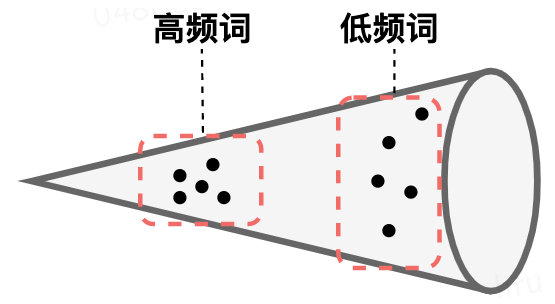
2. 問題分析
為什麼Bert詞向量會呈現圓錐形的空間分佈且高頻詞更靠近原點?

查了一些論文發現,除了這篇 ICLR 2019 的論文《Representation Degeneration Problem in Training Natural Language Generation Models》給出了一定的理論解釋,幾乎所有提及到 Bert 詞向量空間分佈存在問題的論文,都只是在參照該篇的基礎上,直接將詞向量壓縮到二維平面上進行觀測統計(肉眼看的說服力明顯不夠