工業控制應用程式二進位制的祕密
本文系原創,轉載請說明出處
Please Subscribe Wechat Official Account:信安科研人,獲取更多的原創安全資訊
原始碼:
原論文:
一 研究背景
到2019年為止,沒人研究PLC控制應用程式二進位制檔案的逆向工程問題。
為什麼要逆向工程這個PLC的控制應用程式二進位制檔案?有以下幾個意義:
1)在發生攻擊事件後能夠迅速調查取證
就是說網路攻擊調查團隊可以通過逆向分析惡意控制應用程式的二進位制檔案來看看這個惡意檔案到底乾的啥事情。
2)可以實現惡意的ICS 攻擊程式碼的動態生成
這個點就是說,我可以利用二進位制檔案中特定欄位對應特定功能的特性,自動化的構建惡意程式碼,不需要通過C&C這種資訊保安領域的通訊與控制方法去與我的惡意程式碼通訊並執行命令。
為什麼儘量避免通訊呢?因為攻擊者一般是在IT層面,而惡意軟體一般會放在OT層面,OT和IT層之間基本上都會有一個防禦層,普渡模型將之稱為DMZ,如果攻擊者長時間與惡意軟體通訊,會增加暴露的風險。
那麼如果攻擊者的惡意二進位制檔案在OT裡面不需要通訊就能一次性幹完所有的惡意操作,那這個是非常有意義的一件事。
3)IT領域的二進位制逆向工具一般是沒法子逆向工程OT領域的二進位制
為什麼?因為用的編譯器不一樣,比如西門子plc採用SIMATIC STEP 7程式設計,Allen-Bradley plc採用Studio 5000 Logix Designer程式設計,大多數其他ICS供應商採用CODESYS框架程式設計,這些程式設計軟體的編譯器和傳統軟體的編譯器如gcc根本就不一樣,逆向工程就更別談了。
二 技術背景
2.1 控制應用程式的開發語言種類和執行機理
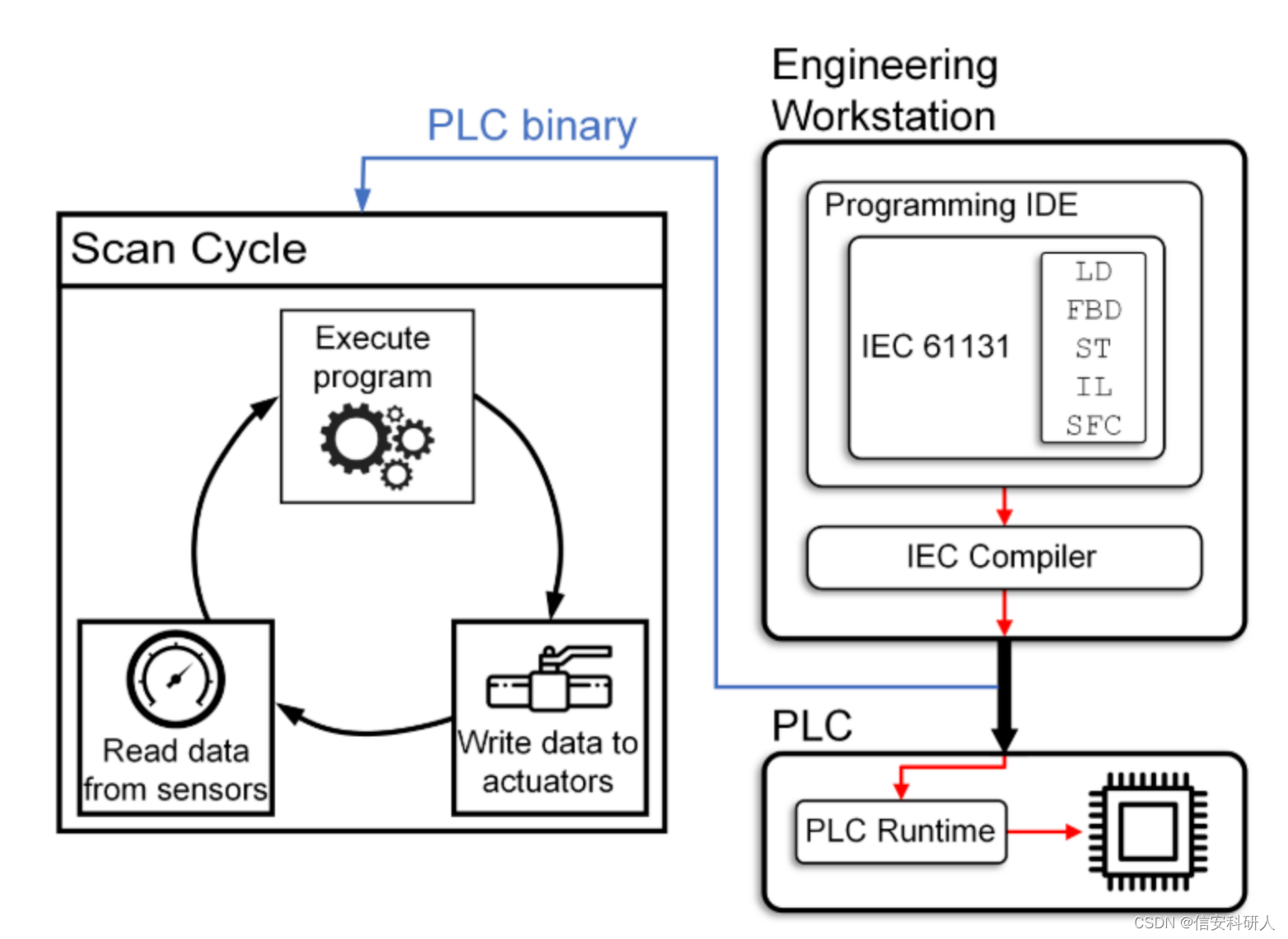
PLC軟體開發過程如上圖所示:
1、工程師在工程工作站開發PLC邏輯。工程工作站配備了供應商提供的符合IEC 61131-3標準的整合式開發環境(ide)和工廠中使用的特定PLC型號的編譯器。用於控制物理過程的PLC邏輯是使用上面列出的一種或多種IEC 61131-3語言開發的,然後使用IEC編譯器進行編譯。
IEC 61131-3描述了以下用於plc的圖形和文字程式語言:
•梯形圖(LD)、圖形
•結構化文字(ST)、文字
•功能框圖(FBD)、圖形
•順序功能圖(SFC)、圖形
•指令列表(IL)、文字(已棄用)
2、二進位制檔案被傳輸到PLC,這個過程在ICS術語中稱為程式下載,PLC的runtime處理二進位制檔案的載入和執行,執行實時要求,並啟用PLC二進位制執行的偵錯和監控。
3、在正常執行期間,二進位制檔案被載入到PLC的快速、易失性記憶體中(比如記憶體)並從中執行。
4、為了確保在停機時快速恢復,PLC二進位制檔案還儲存在非易失性記憶體中。
2.2 PLC二進位制和傳統二進位制的對比
執行模型:
常規二進位制和PLC二進位制的執行模型也有所不同。
非plc語言的二進位制檔案,如傳統的C語言編寫的程式,通常遵循工作單元的順序執行(例如,C程式語言的;-分隔語句)。
相反,PLC二進位制的執行模型是由掃描週期決定的,無限地執行它的三個組成步驟。
阻礙點:這可能會妨礙對整個PLC二進位制檔案的動態分析,因為它們具有無限執行的特性,需要為單個動態分析劃分出適當的程式碼段。
I/O操作:
大多數傳統二進位制檔案也依賴I/O操作來獲取輸入變數併產生相應的輸出,但I/O操作對於PLC二進位制檔案的重要性要高得多。
在PLC二進位制檔案中,I/O操作是其功能的關鍵和必要部分,佔據了三分之二的掃描週期。
檔案格式:
常規的作業系統(os)編譯的二進位制檔案通常遵循良好的檔案格式,例如Linux的可執行和可連結格式(ELF)和Windows的可移植可執行格式(PE)。這些格式的可執行檔案由各自作業系統的載入器處理。
相反,PLC二進位制檔案的載入通常由專有的載入程式(例如CODESYS執行時)處理,PLC二進位制檔案的格式是自定義的,且未知。
編譯器優化:
由於需要保證生產的穩定和實時執行的時限,PLC二進位制的編譯器通常只進行非常保守的優化。
相反,不控制物理世界的傳統二進位制檔案通常會使用非常優秀的編譯器優化技術。
三 PLC二進位制程式逆向工程方法
方法架構——兩個階段:平臺確定階段和自動化二進位制分析階段。
3.1 逆向的目標平臺確定階段
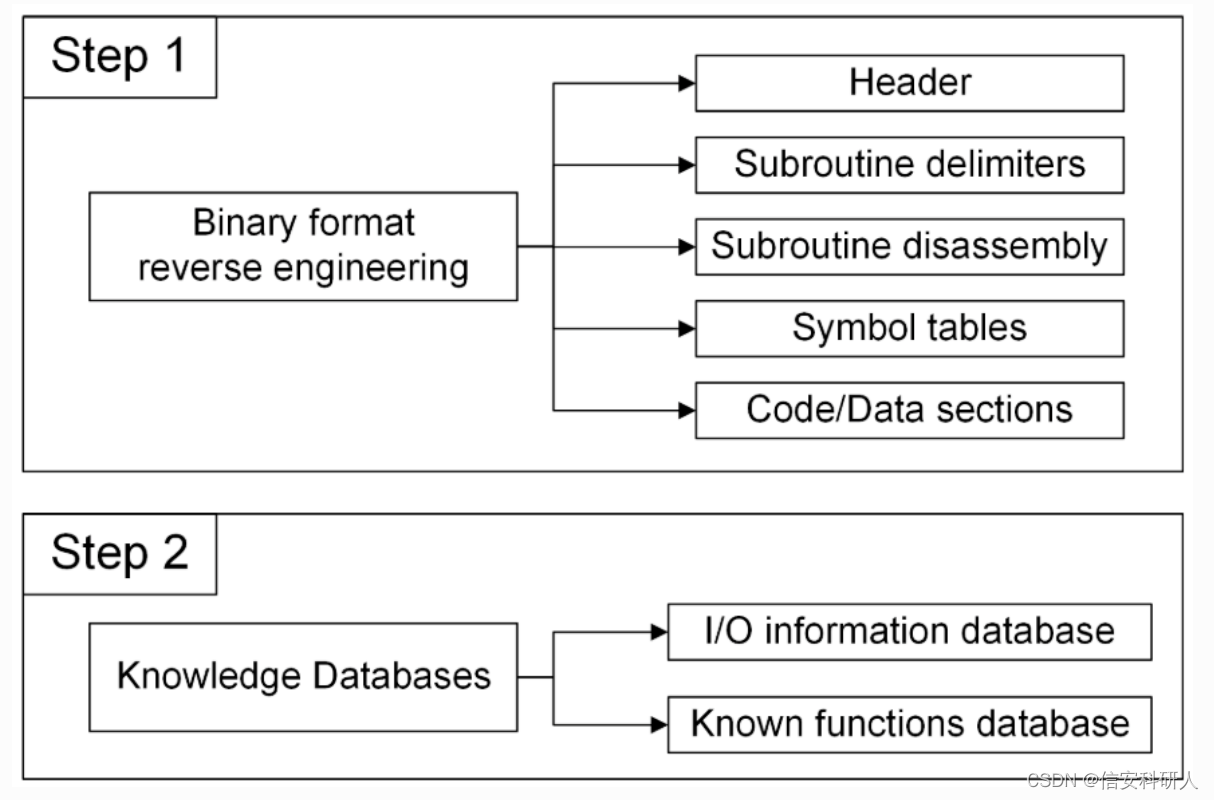
階段目標:提取不同平臺對應的PLC二進位制檔案資訊。
方法:1)逆向工程並收集基於不同平臺的PLC二進位制程式的通用格式;2)構建知識資料庫,這個資料庫包含I/O資訊、已知的函數資訊。
3.1.1 逆向工程獲取二進位制格式
方法:有很多現有的嵌入式系統或檔案逆向工程方法可以參考{原文的參考文獻[8],[41],[48],[11],這裡mark一下}。
難點一:PLC二進位制的格式私有。
難點二:PLC二進位制的執行模型。由於掃描週期的無限特性,動態分析不能對整個PLC二進位制進行,而只能對適當的指令序列進行分析。然而,在PLC二進位制檔案中缺乏編譯優化可能有利於這一步,因為不可變的編譯結果,可以更容易地逆向工程。
結果:一般來說,二進位制格式逆向工程步驟的結果應該包括header內容的資訊,子例程(subroutine)是如何分隔的,子例程的提取及其反組合清單,符號表和動態連結函數的標識,以及程式碼和資料段的資訊。
Subroutine(又稱子程式)是一段可以重複使用的程式程式碼,可以被多次呼叫並執行。在計算機程式設計中,Subroutine通常用來完成特定的任務,它可以接收一些引數、執行一些計算、修改一些變數的值,然後返回結果。Subroutine也被稱為子例程、過程、函數等,不同的程式語言可能會有不同的術語。
Subroutine的優點是可以提高程式碼的可讀性和可維護性。如果程式中有多處需要重複使用的程式碼,將這些程式碼封裝成一個Subroutine,就可以避免程式碼重複,並且在需要修改時也只需要修改一處程式碼。Subroutine還可以使程式結構更加清晰,便於程式碼組織和管理。
3.1.2 知識資料庫
目的:加速逆向工程
包含:
1)二進位制的I/O操作資訊資料庫。這個I/O資訊資料庫應該包括二進位制檔案如何從物理I/O讀寫的資訊、在記憶體對映外設的常見情況下,這些I/O外設的對應地址應該被標識幷包含在資料庫中。
2)已知庫函數和程式碼片段的簽名。這些簽名可以將一些已知的子例程進行指紋化,從而加速逆向工程。有點抽象,簡單的說就是比如MODBUS中處理網路通訊的F/FB表示一般來說是固定的,將這段固定的程式碼記下來形成指紋,下次逆向工程就能「一眼看出」。
3.2 自動化二進位制分析階段
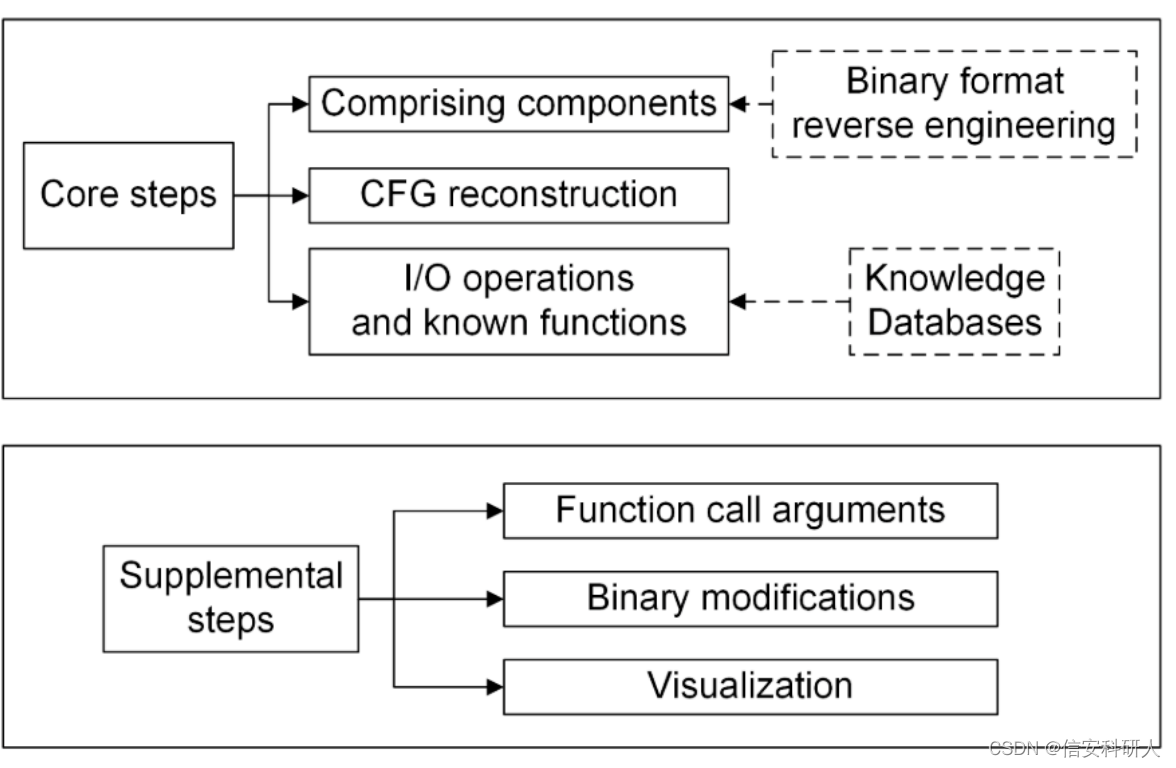
核心步驟:
第一步:利用前一階段的二進位制檔案格式資訊,分析二進位制檔案及其組成元件。在這一步中,所有的子例程都被分解,並且標識出描述動態連結函數的程式碼/資料節和符號表。
第二步:通過查詢和解析分支的目標來重建一個儘可能完整的CFG圖。
第三步:識別I/O操作的指令,並利用知識資料庫對已知函數進行指紋識別。
補充步驟:
第一步:使用動態二進位制分析和符號執行技術,自動化提取傳遞給函數呼叫的引數,這一步可以提取PLC所控制的物理環境的語意資訊,比如一些I/O引數。
第二步:二進位制檔案修改。這一步允許動態的payload生成,或者注入基於host的防禦。當然,修改檔案是需要考慮CRC校驗問題的。
第三步:視覺化。
四 CODESYS 控制應用程式二進位制檔案格式與機制
先使用codesys ide按照IEC61131-3程式語言的所有種類寫控制應用程式。
請注意!作者是面向WAGO 750-881所採用的ARM體系結構編寫程式,得到相應的PLC二進位制檔案(WAGO Codesys二進位制副檔名為PRG)。
4.1 格式
4.1.1 HEADER

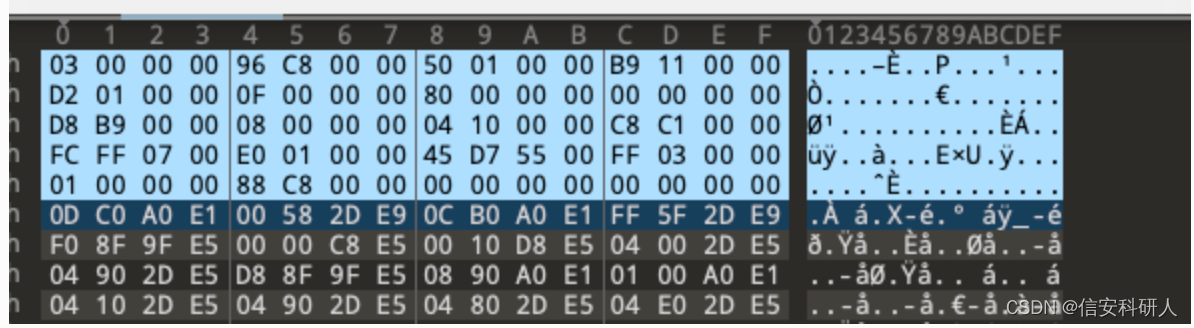
PRG二進位制檔案的前80個位元組構成包含一般資訊的報頭。 見表二:

報頭內偏移量0x20處後推4位元組的值,加0x18,得到的值是程式的入口點,結果值是記憶體初始化子例程的位置。 作者發現,只對頭的一部分進行逆向工程就足以實現自動化分析。
將github上PRG檔案放入010editor進行分析,80位元組有這麼多:
![]()
比較重要的幾個資訊有(下面幾張圖為從ICSREF的資料集中2.PRG檔案的分析):
1)程式入口點
![]()
該值減去0x18,就是程式入口點,這裡涉及到一個大端小端序的問題,論文裡作者沒給出來,下面我會討論一下可能性
2)棧大小
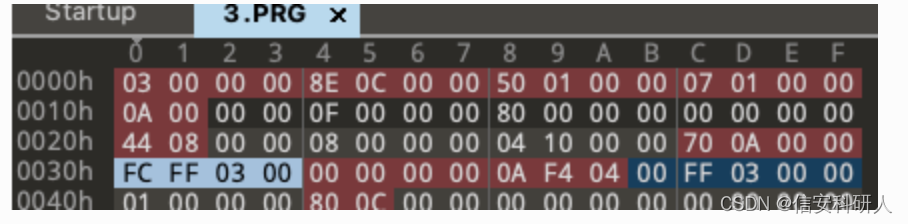
![]()
我嘗試從作者的程式碼中尋找答案,找到如下的程式碼:

![]()
第三個引數bigendian為false,可以確認作者在處理檔案時使用的是小端序。
4.1.2 子例程分隔符
一個子例程的開始指令:

![]()
子例程退出的指令:
LDMDB R11, {R11, SP, PC}
LDMDB R11, {R11, SP, PC}是一個ARM組合指令,用於從記憶體中載入多個暫存器的值,其中R11暫存器儲存了記憶體地址。具體來說,該指令會從記憶體地址R11處開始,依次將4個暫存器R11、SP、PC的值載入到對應的暫存器中,並將R11的值加上16,以便下次操作時從正確的記憶體地址開始。因此,該指令實現了從記憶體中載入多個暫存器的值,並更新了R11暫存器的值。在ARM組合中,LDMDB指令的含義為「Load Multiple Decremented Before」,表示在載入多個暫存器的值之前先將地址遞減。
4.1.3 全域性變數和通用子例程的初始化
Global INIT子例程是所有PRG檔案的第一個子例程,起始於0x50的偏移處(HEADER一共80位元組,0x50是80),也就是緊隨HEADER。
Global INIT功能:
設定常數、變數,初始化IEC 61131-3程式的VAR_GLOBAL section中定義的函數。
VAR_GLOBAL section:
codesys IDE裡面VAR_GLOBAL section長這樣

![]()
PLC程式設計師通常使用本節來定義與控制下的物理環境有關的程式範圍內的常數(例如,縮放因子、PID增益、定時常數)。
在Global INIT子例程之後,觀察到三個較短的支援子例程,每個PRG檔案都有。 接著後面是一個偵錯程式處理程式子程式(SYSDEBUG),它支援從IDE進行動態偵錯。
4.1.4 靜態連結庫和使用者自定義的函數塊
偵錯程式處理程式之後是匯入庫F/FBS的子程式。
每個靜態連結的F/FB(function block)由兩個子例程組成:一個子例程執行其主要功能(staticlib),另一個子例程初始化其本地記憶體(staticlib init)。
與PLC程式設計器直接開發的程式碼相對應的使用者自定義F/FB以類似的方式放置在每個F/FB的靜態連結庫之後 :首先是執行其主要功能的子程式(FB),然後是其初始化子程式(FB INIT)。
倒數第二個子例程是主函數,在Codesys中名為PLC_PRG。 此子程式必須存在,並作為掃描週期的起點。
![]()
4.1.5 Memory INIT
對於二進位制中的子例程目標(例如靜態連結的庫F/FB或使用者定義的F/FB),呼叫表由CODESYS執行時執行最後一個子例程Memory INIT之後構建的。
這個子例程的功能,也是二進位制的入口點,有兩個功能:
首先,將二進位制所需的記憶體空間初始化為零;
其次,計算呼叫所有包含在二進位制檔案中的子例程所需的索引偏移量,建立相應的呼叫表。
這為重構CFG圖帶來了極大的便利,作者用angr重構CFG。
4.1.6 符號表
簡單的標準函數,例如對 REAL 型別變數的數學運算,在 CODESYS 二進位制檔案中動態連結。有關這些函數的資訊包含在符號表中。

符號表包含一組NullTerminated字串識別符號,後跟兩個位元組的資料,如下所示:
DCB "real_add", 0 DCW 0x82 DCB "real_sub", 0 DCW 0x83
這兩個資料位元組「0x82」、「0x83」被執行時用來計算呼叫相應函數所需的跳轉偏移量(具體計算細節我還未了解)。
4.2 控制應用程式二進位制的機制
4.2.1 I/O機制
為什麼有I/O機制,or I/O機制的功能是什麼?
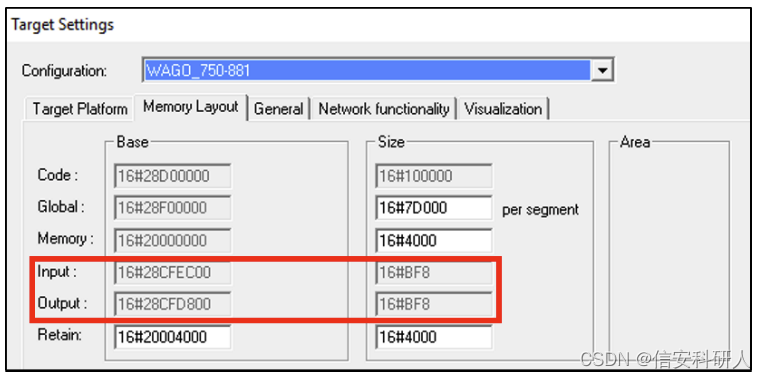
I/O機制是PLC和物理環境通訊介面,在PLC中,尤其是基於codesys runtime的PLC,物理I/O模組(接到wago PLC上的幾個I/O板子)會記憶體對映到PLC記憶體中的特定地址。在codesys v2.3 IDE中建立新專案的時候會有如下介面:
![]()
例如,在 WAGO 750-881 PLC 的中,每當二進位制程式中的記憶體load操作,即從 0x28CFEC00 - 0x28CFF7F8 範圍內的記憶體地址執行讀取操作時,它本質上是查詢感測器,並且每當記憶體儲存操作向 0x28CFD800 - 0x28CFE3F8 範圍內寫時,本質上是更新執行器。
如何從PLC二進位制程式中提取這些值?
人工地從每個PLC控制應用二進位制程式中提取很枯燥無味且很沒意義,通過觀察IDE安裝目錄,作者發現,每個PLC硬體的所有架構選項都包含在目標(TRG檔案格式)檔案中,位於IDE的安裝目錄中。
TRG檔案使用了特定的壓縮編碼方法:
將檔案內容按照2048bit為單位分塊,將每個塊與一個重複使用的2048bit的固定序列進行XOR互斥或操作,這個固定序列在所有TRG檔案中都是相同的,不受PLC供應商和目標PLC的影響。
通過該方案,可以快速、準確地解析TRG檔案,提取PLC模型的I/O記憶體對映,自動填充I/O資料庫,從而節省人工操作的時間和成本。
4.2.2 二進位制程式的函數對應程式碼
二進位制程式中靜態連結的函數的操作碼對應codesys中FB的特定功能,如形成資料庫,將方便逆向工程。方法如圖:
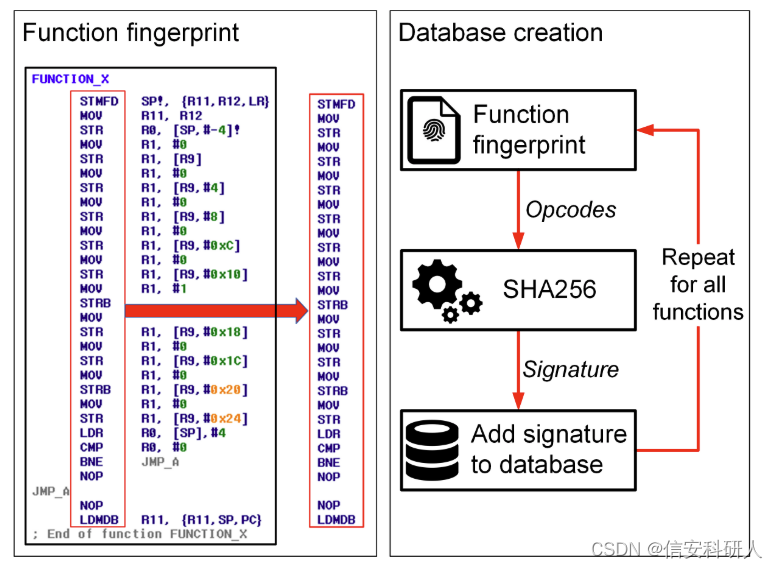
圖左是function_x對應的組合指令集合,作者刪除了操作指令後面的引數,因為引數是可變,指令不會變,然後將集合sha256編碼,形成簽名,存入資料庫。
5 ICSREF
這個工具功能:
- 二進位制檔案按成分分割:首先,它解析標頭檔案並提取其中的資訊。然後,它掃描二進位制檔案,搜尋子例程分隔符,並使用它們來切割出所有子例程,並使用radare2生成它們的反組合列表。最後,它提取符號表並識別任何動態連結的函數。
- CFG重構:PRG二進位制檔案僅包含從一個子程式到另一個子程式或到一個動態連結函數的呼叫的間接跳轉,而所有這些間接分支目標的位置都完全包含在二進位制檔案中,因此可以得到100%重構的控制流程圖。
- I/O操作和已知函數匹配:作者使用了angr進行符號執行,並執行每個子程式以檢測記憶體對映的I/O範圍內的讀/寫操作。此外,為了將二進位制子程式與已知的庫函數/函數塊進行匹配,作者計算了每個子程式的簽名,並查詢已知函數資料庫以進行匹配。
CFG是指程式的控制流程圖(Control Flow Graph),它用圖形化的方式表示程式中程式碼塊(Basic Block)之間的控制流轉移關係。CFG常常被用來進行程式分析和優化。在程式中,基本塊是一組沒有跳轉或者只有從頭到尾的跳轉語句的程式碼集合,因此CFG可以將程式劃分為一系列的基本塊,並表示它們之間的控制流轉移關係
6 初體驗
6.1.1 檔案下載與安裝
第一步,下下來:
git clone https://github.com/momalab/ICSREF.git && cd ICSREF第二步,給你的主機安裝相關的庫依賴:
sudo apt install git python-pip libcapstone3 python-dev libffi-dev build-essential virtualenvwrapper graphviz libgraphviz-dev graphviz-dev pkg-config以及上文提到的radare2:
wget https://github.com/radareorg/radare2/archive/refs/tags/3.1.3.zip
unzip 3.1.3.zip && cd radare2-3.1.3
./sys/install.sh && cd ..第三步,建立環境,作者用的是:
mkvirtualenv icsref然而因為python的玄學環境,我的mkvir一直報錯,之前偵錯過一次,太麻煩,這裡我直接用conda直接建立環境了,看到作者使用python 2.7 寫的,所以:
conda create --name icsref python=2.7
然後直接切換到這icsref環境裡:
conda activate icsref
然後去ICSREF的目錄中,安裝所需要的python 庫即可:
pip install --no-index --find-links=wheelhouse -r requirements.txt最後,建立bash偏好:
echo -e "\n# ICSREF alias\nalias icsref='workon icsref && python `pwd`/icsref/icsref.py'\n" >> ~/.bash_aliases && source ~/.bashrc6.1.2 使用
conda activate icsref
然後跳轉到ICSREF/icsref目錄下,輸入
我要測試237.PRG,也就是專案檔案中ICSREF/samples/ PRG_binaries中的檔案,請注意,在輸入python icsref.py後,如果需要使用Linux的命令,則需要在命令前加上!,如ls就是!ls
首先輸入help看看有什麼功能:

![]()
先使用analyze 分析一下檔案:
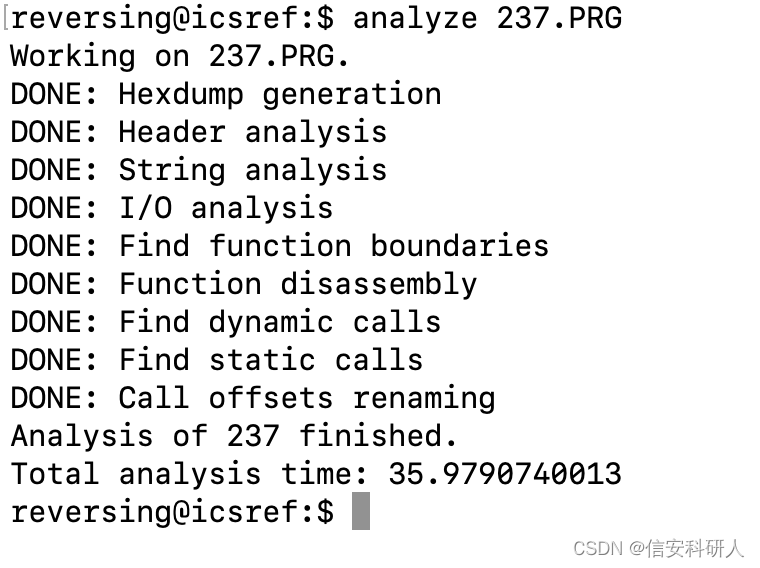
分析完後,開啟results資料夾:

![]()
輸入hashmatch,匹配hash資料庫中指定的函數:

![]()
輸入graphbuilder,獲得了以svg結尾的圖,開啟如下:
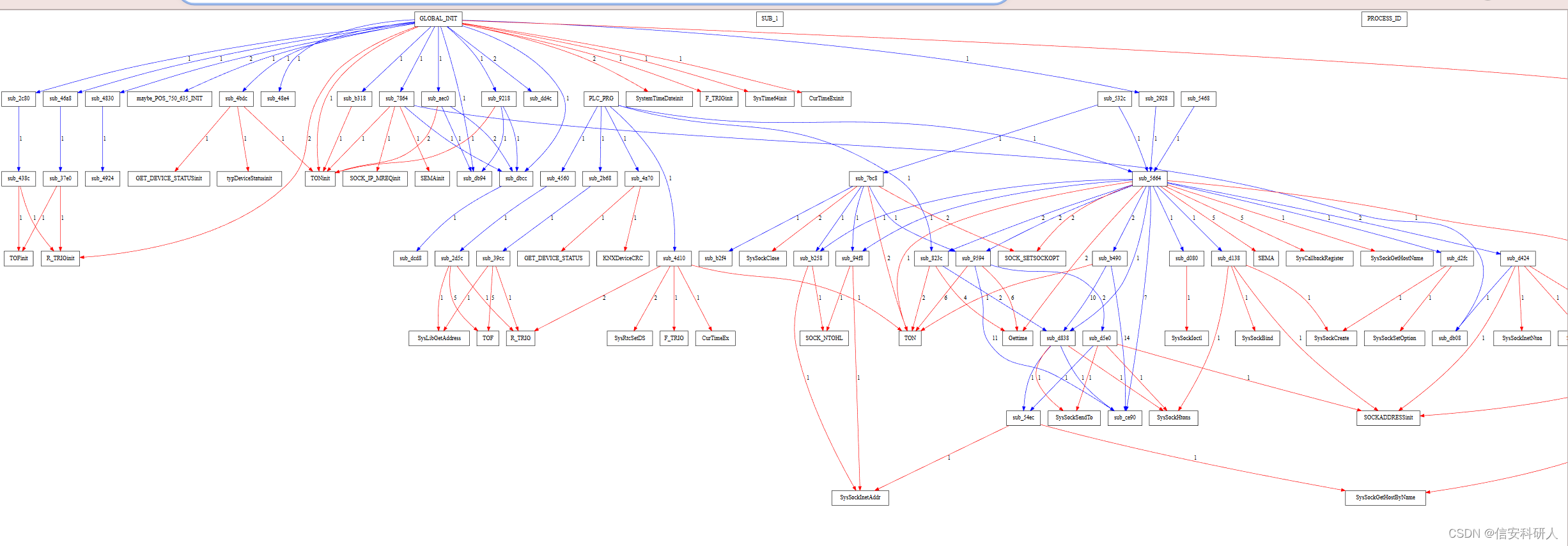
![]()