14.AQS的前世,從1990年的論文說起
大家好,我是王有志。關注王有志,一起聊技術,聊遊戲,聊在外漂泊的生活。
鴿了這麼久怪不好意思的,因此送一本《多處理器程式設計的藝術》,快點選此處參加吧。另外歡迎大家加入「共同富裕的Java人」互助群。
今天的主題是AbstractQueuedSynchronizer,即AQS。作為java.util.concurrent的基礎,AQS在工作中的重要性是毋庸置疑的。通常在面試中也會有兩道「必考」題等著你
-
原理相關:AQS是什麼?它是怎樣實現的?
-
設計相關:如何使用AQS實現Mutex?
原理相關的問題幾乎會出現在每場Java面試中,是面試中的「明槍」,是必須要準備的內容;而設計相關的問題更多的是對技術深度的考察,算是「暗箭」,要尤為謹慎的去應對。
我和很多小夥伴交流關於AQS的問題時發現,大部分都只是為了應付面試而「背」了AQS的實現過程。為了全面地理解AQS的設計,今天我們會從1990年T.E.Anderson引入排隊的思想萌芽開始,到Mellor-Crummey和Scott提出的MCS鎖,以及Craig,Landin和Hagersten設計的CLH鎖。
AQS的內容整體規劃了4個部分:
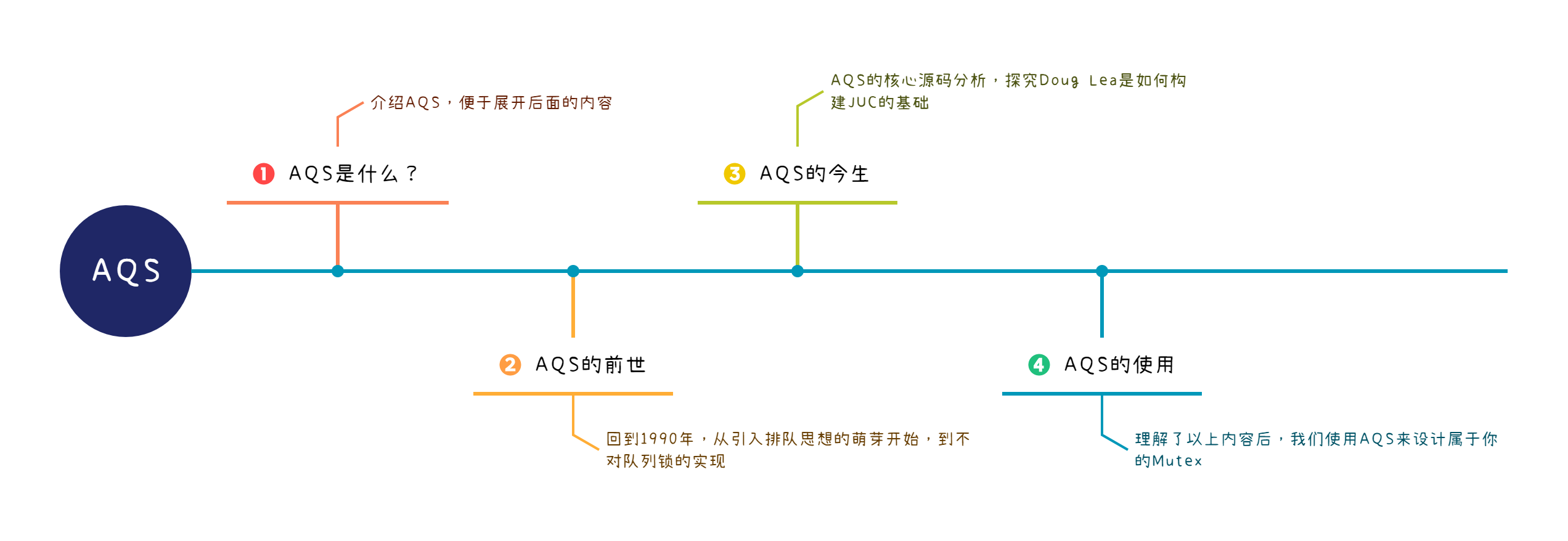
今天我們一起學習前兩個部分,瞭解AQS的前世。
Tips:本文基於Java 11完成,與Java 8存在部分差異,請注意區分原始碼之間的差異。
AQS是什麼?
通常我們按照類名將AbstractQueuedSynchronizer翻譯為抽象佇列同步器。單從類名來看,我們就已經可以得到3個重要資訊:
-
Abstract:抽象類,通常無法直接使用;
-
Queued:佇列,藉助佇列實現功能;
-
Synchronizer:同步器,用於控制並行。
原始碼中的註釋也對AQS做了全面的概括:
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues.
提供了依賴於FIFO等待佇列用於實現阻塞鎖和同步器(號誌,事件等)的框架。這段描述恰好印證了我們通過類名得到的資訊,我們來看Java中有哪些AQS的實現:

可以看到,JUC中有大量的同步工具內部都是通過繼承AQS來實現的,而這也正是Doug Lea對AQS的期望:成為大部分同步工具的基礎元件。
Tips:至少在Java 8中,FutureTask已經不再依賴AQS實現了(未考證具體版本)。
接著我們來看註釋中提到的「rely on first-in-first-out (FIFO) wait queues」,這句話指出AQS依賴了FIFO的等待佇列。那麼這個佇列是什麼?我們可以在註釋中找到答案:
The wait queue is a variant of a "CLH" (Craig, Landin, and Hagersten) lock queue. CLH locks are normally used for spinlocks.
AQS中使用的等待佇列時CLH佇列的變種。那麼CLH佇列是什麼呢?AQS做了哪些改變呢?
AQS的前世
AQS明確揭示了它使用CLH佇列的變種,因此我從CLH佇列的相關論文入手:
-
Craig於1993年發表的《Building FIFO and priority-queueing spin locks from atomic swap》
-
Landin和Hagersten於1994年發表的《Efficient Software Synchronization on Large Cache Coherent Multiprocessors》
這兩篇文章都參照了T.E.Anderson於1990年發表的的《The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors》,因此我們以這篇文章中提出的基於陣列的自旋鎖設計作為切入點。
Tips:
-
《Efficient Software Synchronization on Large Cache Coherent Multiprocessors》的作者有3個人~~
-
Landin和Hagersten的《Efficient Software Synchronization on Large Cache Coherent Multiprocessors》中參照了Craig的《Building FIFO and priority-queueing spin locks from atomic swap》,Craig率先提出了CLH鎖的結構,不知道為什麼學術界以他們3人進行命名;
-
由於論文是很多年前收集的,現在去查詢原始網站較為困難,只能提供下載連結了,對不起各位祖師爺~~
-
T.E.Anderson The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors 1990
-
Mellor Crummey,Scott Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors 1991
-
Craig Building FIFO and priority-queueing spin locks from atomic swap 1993
-
Landin, Hagersten Efficient Software Synchronization on Large Cache Coherent Multiprocessors 1994
-
Doug Lea The java.util.concurrent Synchronizer Framework 2004
-
-
《多處理器程式設計的藝術》中第7章詳細討論了佇列鎖的設計,包括基於陣列的設計,MCS鎖,CLH鎖。
基於陣列的自旋鎖
1990年T.E.Anderson發表了《The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors》,文章討論了基於CPU原子指令自旋鎖的效能瓶頸,並提出了基於陣列的自旋鎖設計。
基於原子指令的自旋鎖
第一種設計(SPIN ON TEST-AND-SET),即TASLock,使用CPU提供的原子指令test-and-set嘗試更新鎖標識:

初始化鎖標識為CLEAR,獲取鎖時嘗試更新鎖標識為BUSY,更新成功則獲取到鎖,釋放時將鎖標識更新為CLEAR。
設計非常簡單,競爭並不激烈的場景下效能也是完全沒問題,但是一旦CPU的核心數增多,問題就出現了:
-
持有者在釋放鎖時要和其它正在自旋的競爭者爭奪鎖標識記憶體的獨佔存取許可權,因為test-and-set是原子寫操作;
-
在使用匯流排的體系結構中,無論test-and-set指令是否成功,它都會消耗一次匯流排事務,會使匯流排變得擁堵。
因此提出了第二種設計(SPIN ON READ),即TTASLock,加入test指令,避免頻繁的:

該設計中,在執行test-and-set指令前,先進行鎖標識狀態的判斷,處於BUSY狀態,直接進入自旋邏輯(或運算的短路特性),跳過test-and-set指令的執行。
額外一次讀取操作,避免了頻繁的test-and-set指令造成的記憶體爭搶,也減少了匯流排事務,競爭者只需要自旋在自己的快取上即可,只有鎖標識發生改變時,才會執行test-and-set指令。
這種設計依舊有些效能問題無法解決:
-
如果頻繁鎖標識頻繁的發生改變,CPU的快取會頻繁的失效,重新讀取;
-
持有者釋放鎖時,會導致所有CPU的快取失效,必須重新在記憶體或匯流排中競爭。
T.E.Anderson對兩種設計進行了測試,計算了在不同數量的CPU上執行了100萬次操作的耗時,執行等待鎖,執行臨界區,釋放鎖和延遲一段時間。
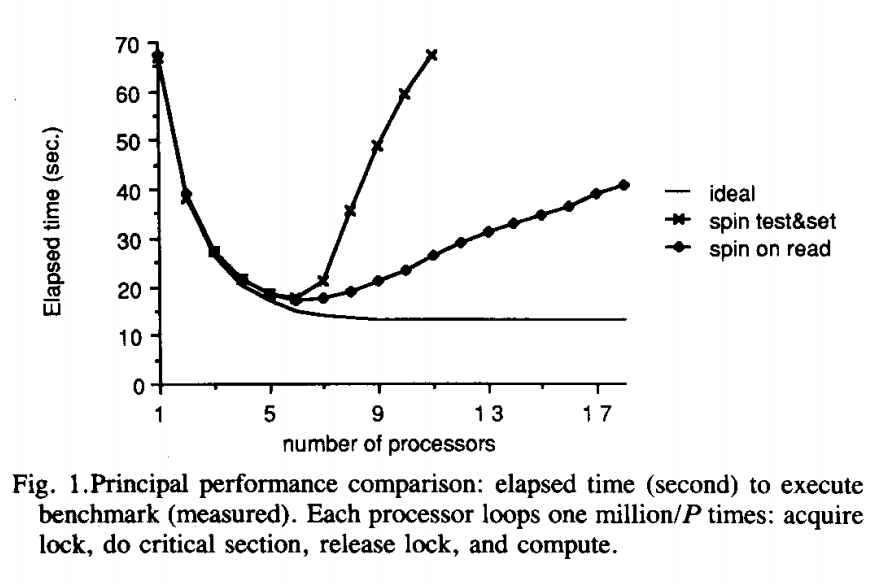
可以看到SPIN ON READ的設計隨著CPU數量的增多效能確實得到了改善,但距離理想的效能曲線仍有著不小的差距。
除了這兩種設計外,T.E.Anderson還考慮了在自旋邏輯中引入延遲來減少衝突:

此時需要考慮設定合理的延遲時間,選擇合適的退避(backoff)演演算法來減少競爭。
Tips:Java版TASLock和TTASLock,供大家參考。
基於陣列的自旋鎖
前面的設計中,自旋鎖的效能問題是由多個CPU同時爭搶記憶體存取許可權產生的,那麼讓它們按順序排隊是不是就解決了這個問題?T.E.Anderson引入了佇列的設計:

初始化
-
建立長度為CPU數量P的陣列flags[P]
-
flags[0]標識為HAS_LOCK(擁有鎖),其餘標記為MUST_WAIT(等待鎖)
-
初始化queueLast為0,標識當前佇列位置
加鎖
-
CPU通過ReadAndIncrement指令讀取queueLast後儲存為自己的myPlace
- ReadAndIncrement指令,先讀取,後自增
-
CPU判斷自己的flags[myPlace mod P]上的標記來決定持有鎖或進入自旋
- 取模操作讓陣列變成了頭尾相連的「環狀」陣列
解鎖
-
將當前CPU在佇列中的位置flags[myPlace]更新為MUST_WAIT
-
將flags[(myPlace + 1) mod P]更新為HAS_LOCK,標識下一個CPU獲取鎖
每個CPU只存取自己的鎖標識(myPlace),避免了爭搶記憶體存取的許可權,另外鎖會直接釋放給佇列中的下一個CPU,避免了通過競爭獲取,減少了從釋放鎖到獲取鎖的時間。
當然缺點也很明顯,僅從虛擬碼的行數上也能看出來,基於佇列的自旋鎖設計更復雜,當競爭並不激烈時,它的效能會更差。T.E.Anderson也給出了他的測試結果:
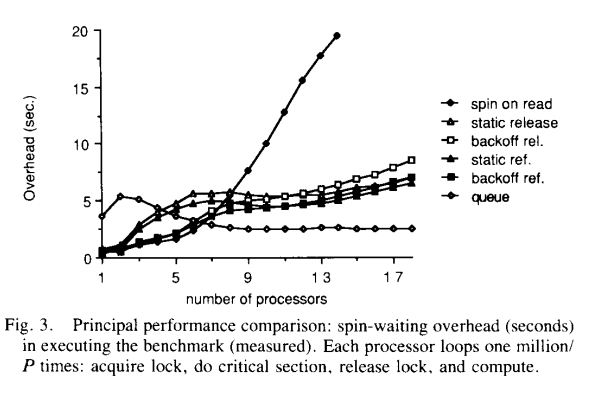
很明顯,在競爭激烈的場景中,引入佇列後的自旋鎖效能更加優秀,並沒有過多的額外開銷。
Tips:
-
T.E.Anderson的論文就介紹到這裡,除了對自旋鎖的討論,文章中還討論了在自旋鎖引入退避演演算法和靜態延遲(static delays)的優劣,就留給大家自行閱讀了;
-
Java版TEALock,供大家參考(名字是我自己起的~)。
MCS鎖的設計
基於陣列的自旋鎖是排隊思想的實現,T.E.Anderson的論文發表後,又湧現出了許多使用排隊思想鎖,例如:Mellor-Crummey和Scott於1991年在論文《Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors》中提出的MCS鎖,也是基於排隊思想實現,只不過在資料結構上選擇了單向連結串列。
描述MCS鎖的初始化與加解鎖的原理,我使用經過「在地化」的Java實現版本的MCS鎖:
MCS鎖的初始化
public class MCSLock {
AtomicReference<QNode> lock;
ThreadLocal<QNode> myNode;
public MCSLock() {
this.lock = new AtomicReference<>(null);
this.myNode = ThreadLocal.withInitial(QNode::new);
}
private static class QNode {
private boolean locked;
private QNode next;
}
}
-
宣告單向連結串列的節點QNode,locked表示鎖是否被前驅節點獲取;
-
建立QNode節點lock,表示當前鎖的位置,實際上也是連結串列的尾節點。
MCS鎖的加鎖
public void lock() {
QNode I = this.myNode.get();
QNode predecessor = this.lock.getAndSet(I);
if (predecessor != null) {
I.locked = true;
predecessor.next = I;
while (I.locked) {
System.out.println("自旋,可以加入退避演演算法");
}
}
}
-
為每個執行緒初始化QNode,命名為
I; -
通過原子指令獲取
I的前驅節點lock命名為predecessor,並將I設定為lock(取出當前lock,並設定新的lock);-
當
predecessor == null時,表示佇列為空,可以直接返回,代表獲取到鎖; -
當
predecessor != null時,表示前驅節點已經獲取到鎖;-
更新locked,表示鎖已經被前驅節點獲取;
-
更新predecessor的後繼節點為
I,否則predecessor無法喚醒I; -
I進入自旋邏輯。
-
-
MCS鎖的解鎖
public void unlock() {
QNode I = this.I.get();
if (I.next == null) {
if (lock.compareAndSet(I, null)) {
return;
}
while (I.next == null) {
System.out.println("自旋");
}
}
I.next.locked = false;
I.next = null;
}
-
獲取當前執行緒的QNode命名為
I; -
如果
I.next == null,佇列中無其它節點,即不存在鎖競爭的場景;-
嘗試通過CAS更新lock為null,保證下次加鎖時
predecessor == null,成功則直接返回; -
如果失敗,表示此時有執行緒開始競爭鎖,此時進入自旋,保證競爭者成功執行
predecessor.next = I;
-
-
如果
I.next != null,佇列中有其他節點,鎖存在競爭;-
更新後繼節點的locked標識,使其跳出自旋;
-
更新自己的後繼節點指標,斷開聯絡。
-
MCS鎖的邏輯並不複雜,不過有些細節設計的非常巧妙,提個問題供大家思考下:加鎖過程中I.locked = true和predecessor.next = I的順序可以調整嗎?
MCS鎖的整體設計思路到這裡就結束了,Mellor-Crummey和Scott給出了MCS鎖的4個優點:
-
FIFO保證了公平性,避免了鎖飢餓;
-
自旋標識是執行緒自身的變數,避免了共用記憶體的存取衝突;
-
每個鎖的建立只需要極短的時間(requires a small constant amount of space per lock);
-
無論是否採用一致性快取架構, 每次獲取鎖只需要$ O(1)$ 級別的通訊開銷。
除此之外,相較於T.E.Anderson的設計,MCS鎖在記憶體空間上是按需分配,並不需要初始化固定長度陣列,避免了記憶體浪費。
Tips:
-
本文只簡單的介紹MCS鎖的原理,想要深入學習的可以閱讀以下內容:
-
《Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors》
-
《多處理器程式設計的藝術》第7章
-
CLH鎖的設計
1993年Craig發表了《Building FIFO and priority-queueing spin locks from atomic swap》,文章中描述了另一種基於排隊思想的佇列鎖,即CLH 鎖(我覺得稱為Craig Lock更合適)的雛形,它和MCS鎖很相似,但有一些差異:
-
CLH旋轉在佇列前驅節點的鎖標識上;
-
CLH鎖使用了一種「隱式」的連結串列結果。
我們帶著這兩個差異來看CLH的鎖的設計,原文使用Pascal風格的虛擬碼,這裡我們使用《多處理器程式設計的藝術》中提供的Java版本,與論文中的差異較大,重點理解實現思路即可。
CLH鎖的初始化
public class CLHLock {
AtomicReference<Node> tail;
ThreadLocal<Node> myPred;
ThreadLocal<Node> myNode;
public CLHLock() {
this.tail = new AtomicReference<>(new Node());
this.myNode = ThreadLocal.withInitial(Node::new);
this.myPred = new ThreadLocal<>();
}
private static class Node {
private volatile boolean locked = false;
}
}
Craig的設計中,請求鎖的佇列節點有兩種狀態,在實現中可以使用布林變數代替:
-
PENDING,表示獲取到鎖或者等待獲取鎖,可以使用true;
-
GRANTED,表示釋放鎖,可以使用false。
另外CLHLock的初始化中,this.tail = new AtomicReference<>(new QNode())新增了預設節點,該節點的locked預設為false,這是借鑑了連結串列處理時常用到技巧虛擬頭節點。
CLH鎖的加鎖
public void lock() {
Node myNode = this.myNode.get();
myNode.locked = true;
Node pred = this.tail.getAndSet(myNode);
this.myPred.set(pred);
while(myPred.locked) {
System.out.println("自旋,可以加入退避演演算法");
}
}
實現中巧妙的使用了兩個ThreadLocal變數來構建出了邏輯上的連結串列,和傳統意義的單向連結串列不同,CLH的連結串列從尾節點開始指向頭部。
另外,CLH鎖中的節點只關心自身前驅節點的狀態,當前驅節點釋放鎖的那一刻,節點就知道輪到自己獲取鎖了。
CLH鎖的解鎖
public void unlock() {
Node myNode = this.myNode.get();
myNode.locked = false;
this.myNode.set(this.myPred.get());
}
解鎖的邏輯也非常簡單,只需要更新自身的鎖標識即可。但是你可能會疑問this.myNode.set(this.myPred.get())是用來幹嘛的?刪除會產生什麼影響嗎?
Tips:Java版CLHLock,供大家參考,程式碼有詳細的註釋。
單執行緒場景
在單執行緒場景中,完成CLH鎖的初始化後,鎖的內部結構是如下:
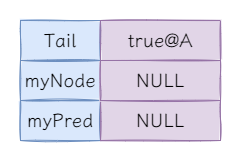
Tips:@後表示Node節點的地址。
第一次加鎖後狀態如下:

這時前驅節點的鎖標記為false,表示當前節點可以直接獲取鎖。
第一次解鎖後狀態如下:
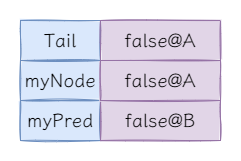
到目前為止一切都很正常,但是當我們再次加鎖時會發現,好像沒辦法加鎖了,我們來逐行程式碼分析鎖的狀態。當獲取myNode後並更新鎖標識,即執行如下程式碼後:
Node myNode = this.myNode.get();
myNode.locked = true;
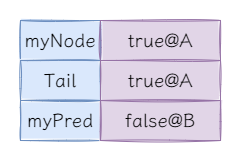
當獲取並更新tail和myPred後,即執行如下程式碼後:
Node pred = this.tail.getAndSet(myNode);
this.myPred.set(pred);
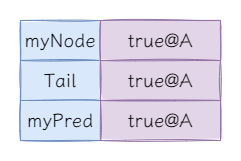
這時候問題出現了,myNode == myPred,導致永遠無法獲取鎖。this.myNode.set(this.myPred.get())相當於在連結串列中移除當前節點,使獲取鎖的節點的直接前驅節點永遠是初始化時鎖標識為false的預設節點。
多執行緒場景
再來考慮多執行緒的場景,假設有執行緒t1和執行緒t2爭搶鎖,此時t1率先獲取到鎖:
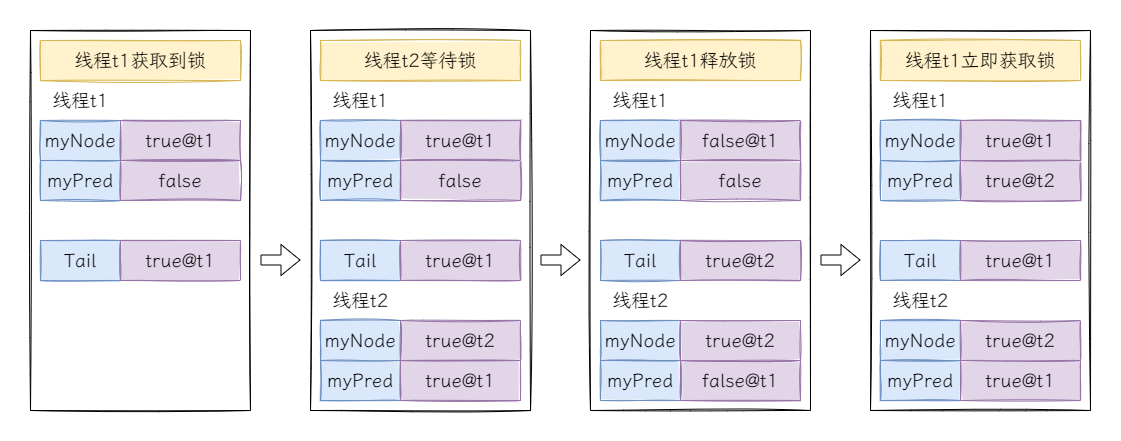
執行緒t1釋放後再次立即獲取是有可能出現的,最典型的情況是如果為自旋邏輯新增了退避演演算法,當執行緒t2多次自旋後再次進入自旋邏輯,此時執行緒t1釋放鎖後立即嘗試獲取鎖,先更新執行緒t1的鎖標記為true,接著從tail節點中獲取前驅節點執行緒t2,然後再更新tail節點,此時執行緒t1線上程t2的鎖標記上自旋,執行緒t2線上程t1的鎖標記上自旋,涼涼~~
留個思考題,為什麼this.myNode.set(this.myPred.get())可以避免這種情況?
CLH鎖和MCS鎖的對比
首先是程式碼實現上,CLH鎖的實現非常簡單,除了自旋的部分其餘全是平鋪直敘,反觀MCS鎖,分支,巢狀,從實現難度上來看CLH鎖更勝一籌(難點在於逆向思維,讓當前節點自旋在直接前驅節點的鎖標識上)。另外,CLH鎖只在加鎖時使用了一次原子指令,而MCS鎖的加解鎖中都需要使用原子指令,效能上也略勝一籌。
那麼CLH鎖是全面超越了MCS鎖嗎?不是的,在NUMA架構下,CLH鎖的自旋效能非常差。先來看NUMA架構的示意圖:
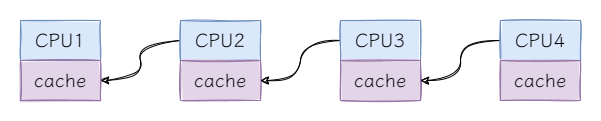
NUMA架構中,每個CPU有自己快取,存取不同CPU快取的成本較高,在需要頻繁進入自旋的場景中CLH鎖自旋的效能較差,而在需要頻繁解鎖更新其他CPU鎖標識的場景中MCS鎖的效能較差。
結語
到目前為止,我們一起學習了3種基於排隊思想的自旋鎖設計,作為AQS的「前世」,理解它們的設計能夠幫助我們理解AQS的原理。當然並非只有這3種基於排隊思想的自旋鎖,還有如RHLock,HCLHLock等,感興趣的可以自行探索,這裡提供論文連結:
好了,今天就到這裡了,Bye~~