Apache Kafka教學--Kafka新手入門
Apache Kafka教學--Kafka新手入門
Kafka Assistant 是一款 Kafka GUI 管理工具——管理Broker,Topic,Group、檢視消費詳情、監控伺服器狀態、支援多種訊息格式。
摘要
今天,我們開始了我們的新旅程,這就是Apache Kafka教學。在這個Kafka教學中,我們將看到什麼是Kafka,Apache Kafka的歷史,為什麼是Kafka。此外,我們還將學習Kafka架構、Kafka的元件和Kafka分割區。此外,我們還將討論Kafka的各種比較和Kafka的使用案例。除此之外,我們將在這個Kafka教學中看到各種術語,如Kafka Broker、Kafka Cluster、Kafka Consumer、Kafka Topics等。
那麼,讓我們開始學習Apache Kafka教學吧。
什麼是Kafka?
當涉及到使用基於訊息的主題實現生產者和消費者之間的通訊時,我們使用Apache Kafka。Apache Kafka是一個快速、可延伸、容錯、釋出-訂閱的訊息傳遞系統。基本上,它為高階的新一代分散式應用設計了一個平臺。同時,它允許大量的永久性或臨時性的消費者。Kafka的一個最好的特點是,它具有高度的可用性和對節點故障的彈性,並支援自動恢復。這個特點使得Apache Kafka成為現實世界資料系統中大規模資料系統元件之間的理想通訊和整合工具。
此外,這項技術取代了傳統的訊息 Broker,能夠像JMS、AMQP等一樣給出更高的吞吐量、可靠性和複製。此外,Kafka提供了一個Kafka Broker、一個Kafka Producer和一個Kafka Consumer。Kafka Broker是Kafka叢集上的一個節點,它的作用是堅持和複製資料。Kafka生產者將訊息推播到稱為Kafka Topic的訊息容器中。而Kafka消費者則從Kafka Topic中提取訊息。
在繼續學習Kafka教學之前,讓我們先了解一下Kafka中Messaging System這一術語的實際含義。
Kafka中的訊息傳遞系統
當我們將資料從一個應用程式轉移到另一個應用程式時,我們使用了訊息傳遞系統。它的結果是,不用擔心如何分享資料,應用程式可以只關注資料。分散式訊息傳遞是建立在可靠的訊息佇列上。雖然,訊息在使用者端應用程式和訊息傳遞系統之間是非同步排隊的。有兩種型別的訊息傳遞模式,即對等和釋出-訂閱(pub-sub)訊息傳遞系統。然而,大多數的訊息傳遞模式都遵循pub-sub。
-
對等訊息傳遞系統
在這裡,訊息被儲存在一個佇列中。雖然,一個特定的訊息最多隻能被一個消費者消費,即使一個或多個消費者可以訂閱佇列中的訊息。同時,它確保一旦消費者閱讀了佇列中的訊息,它就會從該佇列中消失。
-
釋出-訂閱訊息系統
在這裡,訊息被持久化在一個主題中。在這個系統中,Kafka消費者可以訂閱一個或多個主題並消費該主題中的所有訊息。此外,訊息生產者是指釋出者,訊息消費者是指訂閱者。
Apache Kafka的歷史
此前,LinkedIn面臨著的問題是,將網站上的大量資料低延遲地輸入到一個能夠處理實時事件的lambda架構中。作為一個解決方案,Apache Kafka在2010年被開發出來,因為之前沒有一個解決方案可以處理這個問題。
然而,有一些技術可用於批次處理,但這些技術的部署細節是與下游使用者共用的。因此,當涉及到實時處理時,這些技術並不適合。然後,在2011年,Kafka被開源了。
為什麼我們要使用Apache Kafka叢集?
我們都知道,巨量資料中存在著巨大的資料量。而且,當涉及到巨量資料時,有兩個主要挑戰。一個是收集大量的資料,而另一個是分析收集到的資料。因此,為了克服這些挑戰,我們需要一個訊息傳遞系統。那麼Apache Kafka已經證明了它的效用。Apache Kafka有許多好處,例如:
- 通過儲存/傳送實時程序的事件來跟蹤網路活動。
- 提醒和報告業務指標。
- 將資料轉換為標準格式。
- 連續處理串流媒體資料。
因此,由於其廣泛的使用,這項技術正在給一些最流行的應用程式,如ActiveMQ、RabbitMQ、AWS等帶來激烈的競爭。
Kafka教學 - 先決條件
在繼續學習Apache Kafka教學之前,你必須對Java和Linux環境有良好的瞭解。
Kafka架構
下面我們將在這個Apache Kafka教學中討論四個核心API。
-
Kafka Producer API
這個Kafka Producer API允許一個應用程式將訊息釋出到一個或多個Kafka主題。
-
Kafka Consumer API
為了訂閱一個或多個主題並處理應用程式中產生的訊息,我們使用這個Kafka Consumer API。
-
Kafka Streams API
為了充當流處理器,從一個或多個主題消費輸入流,並向一個或多個輸出主題產生輸出流,同時有效地將輸入流轉化為輸出流,這個Kafka Streams API給應用程式提供了便利。
-
Kafka Connector API
這個Kafka聯結器API允許構建和執行可重用的生產者或消費者,將Kafka主題連線到現有的應用程式或資料系統。例如,一個連線到關係型資料庫的聯結器可能會捕獲一個表的每一個變化。
Kafka元件
利用以下元件,Kafka實現了資訊傳遞。
-
Kafka主題
基本上,訊息的集合就是Topic。此外,我們還可以對Topic進行復制和劃分。這裡,複製指的是拷貝,劃分指的是分割區。另外,把它們想象成紀錄檔,Kafka在其中儲存訊息。然而,這種複製和劃分主題的能力是實現Kafka的容錯性和可延伸性的因素之一。

-
Kafka生產者
它將訊息釋出到一個Kafka主題。
-
Kafka消費者
這個元件訂閱一個(多個)主題,讀取和處理來自該主題的訊息。
-
Kafka Broker
Kafka Broker管理主題中的訊息儲存。如果Kafka有一個以上的Broker,這就是我們所說的Kafka叢集。
-
Kafka Zookeeper
為了給Broker提供關於系統中執行的程序的後設資料,並促進健康檢查和Broker領導權的選舉,Kafka使用Kafka zookeeper。
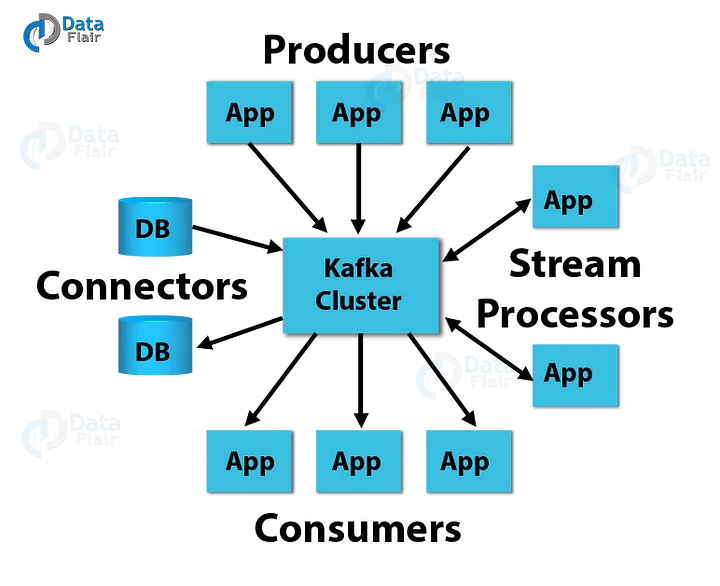
Kafka教學--紀錄檔剖析
在這個Kafka教學中,我們將紀錄檔視為分割區。基本上,一個資料來源會向紀錄檔寫訊息。其中一個好處是,在任何時候,一個或多個消費者從他們選擇的紀錄檔中讀取。在這裡,下圖顯示了資料來源正在寫紀錄檔,而消費者在不同的偏移點上正在讀取紀錄檔。
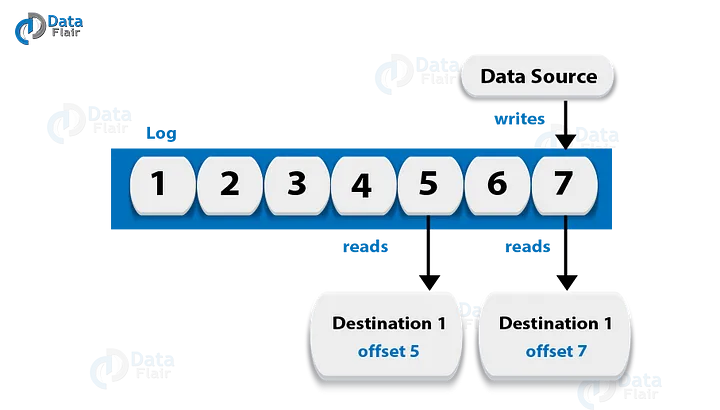
Kafka教學 - 資料紀錄檔
通過Kafka,訊息被保留了相當長的時間。而且,消費者可以根據自己的方便來閱讀。然而,如果Kafka被設定為保留訊息24小時,而消費者的停機時間超過24小時,消費者就會丟失訊息。而且,如果消費者的停機時間只有60分鐘,那麼可以從最後的已知偏移量讀取訊息。Kafka並不保留消費者從一個主題中讀取的狀態。
消費者會向一個叫作 __consumer_offset 的主題傳送
訊息,訊息裡包含每個分割區的偏移量。如果消費者一直處於執行狀態,那麼偏移量就沒有
什麼實際作用。但是,如果消費者發生崩潰或有新的消費者加入群組,則會觸發再均衡。
再均衡完成之後,每個消費者可能會被分配新的分割區,而不是之前讀取的那個。為了能夠
繼續之前的工作,消費者需要讀取每個分割區最後一次提交的偏移量,然後從偏移量指定的
位置繼續讀取訊息。
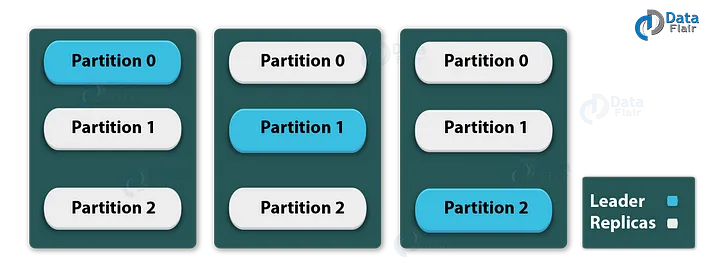
Kafka教學 - Kafka的分割區
每個Kafka Broker中都有幾個分割區。此外,每個分割區可以是一個領導者,也可以是一個主題的副本。此外,隨著新資料對副本的更新,領導者負責對一個主題的所有寫和讀。如果領導者以某種方式失敗了,副本就會作為新的領導者接管。
Java在Apache Kafka中的重要性
Apache Kafka是用純Java編寫的,Kafka的本地API也是java。然而,許多其他語言如C++、Python、.Net、Go等也支援Kafka。不過,一個不需要使用第三方庫的平臺還是Java。另外,我們可以說,用Java以外的語言寫程式碼,會有一點開銷。
此外,如果我們需要Kafka上標準的高處理率,我們可以使用Java語言。同時,Java為Kafka消費者使用者端提供了良好的社群支援。因此,用Java實現Kafka是一個正確的選擇。
Kafka使用案例
有幾個Kafka的使用案例,顯示了我們為什麼實際使用Apache Kafka。
-
訊息代理
對於一個比較傳統的訊息代理,Kafka可以很好的作為一個替代品。我們可以說Kafka有更好的吞吐量,內建的分割區、複製和容錯功能,這使得它成為大規模訊息處理應用的良好解決方案。
-
運營監測
對於運營監測資料,Kafka找到了很好的應用。它包括聚合來自分散式應用的統計資料,以產生集中式的運營資料反饋。
-
事件源
由於它支援非常大的儲存紀錄檔資料,這意味著Kafka是一個優秀的事件源應用的後端。
Kafka教學 - Kafka的比較
許多應用程式提供了與Kafka相同的功能,如ActiveMQ、RabbitMQ、Apache Flume、Storm和Spark。那你為什麼要選擇Apache Kafka而不是其他呢?
讓我們來看看下面的比較。
Apache Kafka 和 Apache Flume 對比
-
工具的型別
Apache Kafka- 對於多個生產者和消費者來說,它是一個通用的工具。Apache Flum- 而對於特定的應用來說,它是一個特殊用途的工具。
-
複製功能
Apache Kafka-使用攝入管道,它複製事件。 Apache Flum-它不復制事件。
RabbitMQ 和 Apache Kafka 對比
最重要的Apache Kafka替代品之一是RabbitMQ。因此,讓我們看看它們之間有什麼不同。
-
特點
Apache Kafka - 基本上,Kafka是分散式的。同時,在保證耐久性和可用性的情況下,資料被共用和複製。RabbitMQ - 它對這些功能的支援相對較少。
-
效能
Apache Kafka--它的效能率很高,達到100,000條訊息/秒的程度。RabbitMQ - 而RabbitMQ的效能率約為20,000訊息/秒。
-
處理
Apache Kafka - 它允許可靠的紀錄檔分散式處理。此外,Kafka流中還內建了流處理語意。RabbitMQ - 在這裡,消費者只是基於FIFO,從HEAD中讀取並逐一處理。
傳統訊息佇列系統與Apache Kafka的對比
-
資訊保留
傳統的佇列系統--大多數佇列系統在訊息被處理後通常會從佇列的末端刪除。Apache Kafka - 在這裡,訊息即使在被處理後也會持續存在。它們不會在消費者收到它們時被刪除。
-
基於邏輯的處理
傳統的佇列系統--它不允許基於類似訊息或事件的邏輯處理。Apache Kafka - 它允許根據類似的訊息或事件來處理邏輯。
所以,這就是關於Apache Kafka教學的全部內容。希望你喜歡我們的解釋。
參考資料: