kubernetes整合GPU原理
這裡以Nvidia GPU裝置如何在Kubernetes中管理排程為例研究, 工作流程分為以下兩個方面:
- 如何在容器中使用GPU
- Kubernetes 如何排程GPU
容器中使用GPU
想要在容器中的應用可以操作GPU, 需要實兩個目標:
- 容器中可以檢視GPU裝置
- 容器中執行的應用,可以通過Nvidia驅動操作GPU顯示卡
在應用程式中使用 GPU,由於需要安裝 nvidia driver, Docker 引擎並沒有原生支援。因此也就無法直接在容器中存取 GPU 資源。
為了解決容器中無法存取 GPU 資源的問題,有以下方案:
1、無nvidia-docker
在早期的時候,沒有nvidia-docker,可以通過在容器內再部署一遍nvidia GPU驅動解決。同理,其他裝置如果想在容器裡使用,也可以採用在容器裡重新安裝一遍驅動解決。
2、nvidia-docker1.0
nvidia-docker是英偉達公司專門用來為docker容器使用nvidia GPU而設計的,設計方案就是把宿主機的GPU驅動檔案對映到容器內部使用,可以通過tensorflow生成GPU驅動資料夾。
3、nvidia-docker2.0
nvidia-docker2.0對nvidia-docker1.0進行了很大的優化,不用再對映宿主機GPU驅動了,直接把宿主機的GPU執行時對映到容器即可。啟動方式範例:
nvidia-docker run -d -e NVIDIA_VISIBLE_DEVICES=all --name nvidia_docker_test nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
4、安裝docker19.03及以上版本,已經內建了nvidia-docker,無需再單獨部署nvidia-docker了。安裝方式如下:
安裝docker:
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --enable docker-ce-nightly
yum-config-manager --enable docker-ce-test
yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
安裝nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit
sudo systemctl restart docker
啟動容器:
docker run --gpus all nvidia/cuda:10.0-base /bin/sh -c "while true; do echo hello world; sleep 1; done"
進入容器並輸入nvidia-smi驗證。
在容器中重新安裝 nvidia driver,容器啟動的時候將 nvidia gpu 作為符號裝置傳遞進來。這種方案的問題在於宿主機和容器內安裝的 nvidia driver 版本可能不一致,因此 docker image 無法在多機間共用。這就喪失了 docker 的主要優勢。
因此,為了在保持 docker image 遷移性的同時可以方便的使用 gpu,nvidia 提出了 nvidia docker 的方案。
參考文獻:https://developer.nvidia.com/blog/gpu-containers-runtime/
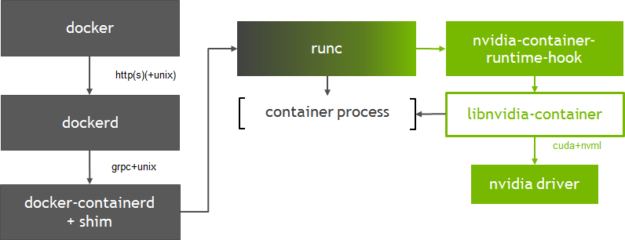
容器啟動流程大致為:docker --> dockerd --> docker-containerd-shim --> nvidia-container-runtime-hook --> libnvidia-container--> nvidia-driver。
docker使用者端將建立容器的請求傳送給dockerd, 當dockerd收到請求任務之後將請求傳送給docker-containerd-shim,nvidia-container-runtime建立容器時,先執行nvidia-container-runtime-hook這個hook去檢查容器是否需要使用GPU(通過環境變數NVIDIA_VISIBLE_DEVICES來判斷)。如果需要則呼叫libnvidia-container來暴露GPU給容器使用。否則則走預設的runc邏輯。
Nvidia-docker
專案地址:https://github.com/NVIDIA/nvidia-docker
Nvidia提供Nvidia-docker專案,它是通過修改Docker的Runtime為nvidia runtime工作,當我們執行 nvidia-docker create 或者 nvidia-docker run 時,它會預設加上 --runtime=nvidia 引數。將runtime指定為nvidia。
nvidia-docker是在docker的基礎上做了一層封裝,通過 nvidia-docker-plugin把硬體裝置在docker的啟動命令上新增必要的引數。
gpu-containers-runtime
gpu-containers-runtime 是一個NVIDIA維護的容器 Runtime,它在runc的基礎上,維護了一份 Patch, 在容器啟動前,注入一個 prestart 的hook 到容器的Spec中(hook的定義可以檢視 OCI規範 )。這個hook 的執行時機是在容器啟動後(Namespace已建立完成),容器自定義命令(Entrypoint)啟動前。
gpu-containers-runtime-hook
gpu-containers-runtime-hook 是一個簡單的二進位制包,定義在Nvidia container runtime的hook中執行。 目的是將當前容器中的資訊收集並處理,轉換為引數呼叫 nvidia-container-cli 。主要處理以下引數:
- 根據環境變數
NVIDIA_VISIBLE_DEVICES判斷是否會分配GPU裝置,以及掛載的裝置ID。如果是未指定或者是void,則認為是非GPU容器,不做任何處理。 否則呼叫nvidia-container-cli, GPU裝置作為--devices引數傳入 - 環境環境變數
NVIDIA_DRIVER_CAPABILITIES判斷容器需要被對映的 Nvidia 驅動庫。 - 環境變數
NVIDIA_REQUIRE_*判斷GPU的約束條件。 例如cuda>=9.0等。 作為--require=引數傳入 - 傳入容器程序的Pid
gpu-containers-runtime-hook 做的事情,就是將必要的資訊整理為引數,傳給 nvidia-container-cli configure 並執行。
nvidia-container-cli
專案地址:https://github.com/NVIDIA/libnvidia-container,基於c語言
nvidia-container-cli 是一個命令列工具,用於設定Linux容器對GPU 硬體的使用。支援
- list: 列印 nvidia 驅動庫及路徑
- info: 列印所有Nvidia GPU裝置
- configure: 進入給定程序的名稱空間,執行必要操作保證容器內可以使用被指定的GPU以及對應能力(指定 Nvidia 驅動庫)。 configure是我們使用到的主要命令,它將Nvidia 驅動庫的so檔案 和 GPU裝置資訊, 通過檔案掛載的方式對映到容器中。
docker 19.03之後,預設支援NVIDIA GPU。
kubernetes中使用GPU
參考資源:https://kubernetes.io/zh/docs/tasks/manage-gpus/scheduling-gpus/
Kubernetes 提供了Device Plugin 的機制,用於異構裝置的管理場景。原理是會為每個特殊節點上啟動一個針對某個裝置的DevicePlugin pod, 這個pod需要啟動grpc服務, 給kubelet提供一系列介面。
整個 Device Plugin 的工作流程可以分成兩個部分:
- 一個是啟動時刻的資源上報;
- 另一個是使用者使用時刻的排程和執行。
Device Plugin 的開發主要包括最關注與最核心的兩個事件方法:
- 其中 ListAndWatch 對應資源的上報,同時還提供健康檢查的機制。當裝置不健康的時候,可以上報給 Kubernetes 不健康裝置的 ID,讓 Device Plugin Framework 將這個裝置從可排程裝置中移除;
- 而 Allocate 會被 Device Plugin 在部署容器時呼叫,傳入的引數核心就是容器會使用的裝置 ID,返回的引數是容器啟動時,需要的裝置、資料卷以及環境變數。
Nvidia GPU Device Plugin
為了能夠在Kubernetes中管理和排程GPU, Nvidia提供了Nvidia GPU的Device Plugin。
專案地址:https://github.com/NVIDIA/k8s-device-plugin
主要功能如下:
- 支援ListAndWatch 介面,上報節點上的GPU數量。
- 支援Allocate介面, 支援分配GPU的行為。
排程流程
整個Kubernetes排程GPU的過程如下:
- GPU Device plugin 部署到GPU節點上,通過
ListAndWatch介面,上報註冊節點的GPU資訊和對應的DeviceID。 - 當有宣告
nvidia.com/gpu的GPU Pod建立出現,排程器會綜合考慮GPU裝置的空閒情況,將Pod排程到有充足GPU裝置的節點上。 - 節點上的kubelet 啟動Pod時,根據request中的宣告呼叫各個Device plugin 的 allocate介面, 由於容器宣告了GPU。 kubelet 根據之前
ListAndWatch介面收到的Device資訊,選取合適的裝置,DeviceID 作為引數,呼叫GPU DevicePlugin的Allocate介面。 - GPU DevicePlugin ,接收到呼叫,將DeviceID 轉換為
NVIDIA_VISIBLE_DEVICES環境變數,返回kubelet。 - kubelet將環境變數注入到Pod, 啟動容器。
- 容器啟動時,
gpu-container-runtime呼叫gpu-containers-runtime-hook。 gpu-containers-runtime-hook根據容器的NVIDIA_VISIBLE_DEVICES環境變數,轉換為--devices引數,呼叫nvidia-container-cli prestart。nvidia-container-cli根據--devices,將GPU裝置對映到容器中。 並且將宿主機的Nvidia Driver Lib 的so檔案也對映到容器中。 此時容器可以通過這些so檔案,呼叫宿主機的Nvidia Driver。
在k8s中啟用GPU支援
必要條件:
- NVIDIA 驅動程式 ~= 384.81
- nvidia-docker 版本 > 2.0
- docker 設定為 nvidia 作為預設執行時。
- Kubernetes 版本 >= 1.10
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.11.0/nvidia-device-plugin.yml
執行GPU作業
部署守護程式後,可以使用nvidia.com/gpu資源型別請求 NVIDIA GPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:9.0-devel
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
- name: digits-container
image: nvcr.io/nvidia/digits:20.12-tensorflow-py3
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPUs
AMD GPU Device Plugin
專案地址:https://github.com/RadeonOpenCompute/k8s-device-plugin
在k8s中啟用GPU支援
必要條件:
- 支援 ROCm 的機器
- ROCm 核心(安裝指南)或最新的 AMD GPU Linux 驅動程式(安裝指南)
--allow-privileged=true對於 kube-apiserver 和 kubelet(僅當裝置外掛通過 DaemonSet 部署時才需要,因為裝置外掛容器需要特權安全上下文才能存取/dev/kfd裝置健康檢查)
部署 AMD 裝置外掛:
kubectl create -f https://raw.githubusercontent.com/RadeonOpenCompute/k8s-device-plugin/r1.10/k8s-ds-amdgpu-dp.yaml
k8s 共用GPU方案
在kubernetes中執行GPU程式,通常都是將一個GPU卡分配給一個容器。這可以實現比較好的隔離性,確保使用GPU的應用不會被其他應用影響;對於深度學習模型訓練的場景非常適合;
但是如果對於模型開發和模型預測的場景就會比較浪費。很多訴求是能夠讓更多的預測服務共用同一個GPU卡上,進而提高叢集中Nvidia GPU的利用率。
阿里雲開源了一個gpushare專案,實現多個pod共用同一塊gpu卡。
核心模組:
- GPU Share Scheduler Extender: 利用Kubernetes的排程器擴充套件機制,負責在全域性排程器Filter和Bind的時候判斷節點上單個GPU卡是否能夠提供足夠的GPU Mem,並且在Bind的時刻將GPU的分配結果通過annotation記錄到Pod Spec以供後續Filter檢查分配結果。
- GPU Share Device Plugin: 利用Device Plugin機制,在節點上被Kubelet呼叫負責GPU卡的分配,依賴scheduler Extender分配結果執行。
工作流程(gpushare):
1)GPU Share Device Plugin利用nvml庫查詢到GPU卡的數量和每張GPU卡的視訊記憶體, 通過ListAndWatch()將節點的GPU總視訊記憶體(數量 *視訊記憶體)作為另外Extended Resource彙報給Kubelet; Kubelet進一步彙報給Kubernetes API Server。
2)Kubernetes預設排程器在進行完所有過濾(filter)行為後會通過http方式呼叫GPU Share Scheduler Extender的filter方法,找出單卡滿足排程條件的節點和卡。
3)當排程器找到滿足條件的節點,就會委託GPU Share Scheduler Extender的bind方法進行節點和Pod的繫結。
4)當Pod和節點繫結的事件被Kubelet接收到後,Kubelet就會在節點上建立真正的Pod實體,在這個過程中, Kubelet會呼叫GPU Share Device Plugin的Allocate方法, Allocate方法的引數是Pod申請的gpu-mem。