區域性異常因子(Local Outlier Factor, LOF)演演算法詳解及實驗
區域性異常因子(Local Outlier Factor, LOF)通過計算樣本點的區域性相對密度來衡量這個樣本點的異常情況,可以算是一類無監督學習演演算法。下面首先對演演算法的進行介紹,然後進行實驗。
LOF演演算法
下面介紹LOF演演算法的每個概念,以樣本點集合中的樣本點$P$為例。下面的概念名稱中都加了一個k-,實際上部分名稱原文沒有加,但是感覺這樣更嚴謹一些。
k-鄰近距離(k-distance):樣本點$P$與其最近的第$k$個樣本點之間的距離,表示為$d_k(P)$。其中距離可以用各種方式度量,通常使用歐氏距離。
k-距離鄰域:以$P$為圓心,$d_k(P)$為半徑的鄰域,表示為$N_k(P)$。
k-可達距離:$P$到某個樣本點$O$的k-可達距離,取$d_k(O)$或$P$與$O$之間距離的較大值,表示為
$reach\_dist_k(P,O)=\max\{d_k(O),d(P,O)\}$
也就是說,如果$P$在$N_k(O)$內部,$reach\_dist_k(P,O)$取$O$的k-鄰近距離$d_k(O)$,在$N_k(O)$外部則取$P$與$O$之間距離$d(P,O)$。需要注意k-可達距離不是對稱的。
k-區域性可達密度(local reachability density, lrd):$P$的k-區域性可達密度表示為
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}reach\_dist_k(P,O)}{|N_k(P)|}\right)^{-1}$
括號內,分子計算了$P$到其k-距離鄰域內所有樣本點$O$的k-可達距離之和,然後除以$P$的k-距離鄰域內部的樣本點個數進行平均。再加一個倒數,表示為密度,即$P$到每個點的平均距離越小,密度越大。可以推理出,如果$P$在所有$O$的k-鄰域內部,其區域性可達密度即為
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d_k(O)}{|N_k(P)|}\right)^{-1}$
可以看出,如果$P$是一個離群點,那麼它不太可能存在於$N_k(P)$中各點的k-距離鄰域內,從而導致其區域性可達密度偏小;如果$P$不是離群點,其區域性可達密度最大取為上式。
實際上我有點奇怪為什麼要用一個最大值來將距離作一個限制,也就是使用k-可達距離,而不是直接使用距離,即定義區域性密度為下式
$\displaystyle ld_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d(O,P)}{|N_k(P)|}\right)^{-1}$
k-區域性異常因子(Local Outlier Factor, LOF):$P$的k-區域性異常因子表示為
$\displaystyle LOF_k(P)=\frac{\frac{1}{|N_k(P)|}\sum\limits_{O\in N_k(P)}lrd_k(O)}{lrd_k(P)}$
從直覺上理解:當$LOF_k(P)\le1$時,表明$P$處密度比其周圍點大或相當,則$P$是內點;當$LOF_k(P)>1$時,表明$P$處密度比其周圍點小,可以判別為離群(異常)點。
實驗
LOF演演算法實現
實驗設定樣本維度為2以便視覺化。由於樣本點只包含連續值,實驗預設設定$|N_k(P)|=k$。設定$k=5$,並將閾值設為1.2,即將LOF大於1.2的樣本點視作異常。函數定義、抽樣、計算以及視覺化程式碼如下。
#%% 定義函數 import torch import matplotlib.pyplot as plt #計算所有樣本點[N, M]之間的距離,得到[N, N] def get_dists(points:torch.Tensor): x = torch.sum(points**2, 1).reshape(-1, 1) y = torch.sum(points**2, 1).reshape(1, -1) dists = x + y - 2 * torch.mm(points, points.permute(1,0)) #數值計算問題,防止對角線小於0 dists = dists - torch.diag_embed(torch.diag(dists)) return torch.sqrt(dists) #計算所有樣本點到其k-鄰域點的k-可達距離 def get_LOFs(dists:torch.Tensor, k): #距離排序,獲取所有樣本點的k-臨近距離 sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False) k_dists = sorted_dists[:, k] neighbor_inds = sorted_inds[:, 1:k+1].reshape(-1) neighbor_k_dists = k_dists[neighbor_inds].reshape(-1, k) neighbor_k_reach_dists = torch.max(neighbor_k_dists, dists[:, 1:k+1]) lrds = (neighbor_k_reach_dists.sum(1)/k)**-1 neighbor_lrds = lrds[neighbor_inds].reshape(-1, k) LOFs = neighbor_lrds.sum(1)/k/lrds return LOFs #%% 隨機生成聚集點和異常點 from torch.distributions import MultivariateNormal torch.manual_seed(0) crowd_mu_covs = [ [[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10], [[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10], [[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50], [[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50], [[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50], [[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10], [[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100], ]#正態分佈點的均值和方差 outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #異常點 points = [] for i in crowd_mu_covs: mu = torch.tensor(i[0]) cov = torch.tensor(i[1]) ps = MultivariateNormal(mu, cov).sample([i[2]]).to('cuda') points.append(ps) for o in outliers: points.append(torch.tensor([o]).to('cuda')) points = torch.cat(points) #%% 計算LOFs並視覺化視覺化 k, threshold = 5, 1.2 dists = get_dists(points) LOFs = get_LOFs(dists, k) for i, p in enumerate(points.cpu().numpy()): shape, color = '.', 'black' if len(points) - i <= len(outliers): shape = '^' plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1])) if LOFs[i] > threshold: color = 'red' plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue') plt.plot(p[0], p[1], shape, color=color) plt.show()
實驗視覺化結果如下圖所示,其中紅色點表示被標為異常的點,三角點表示實驗設定的真實異常點。可以看出LOF的確能有效將異常離群點找出。但是,發現下面三個人眼看來非常離群的點的LOF值還不到1.5,比上面異常點的LOF低得多,這說明演演算法還有些不合理之處。
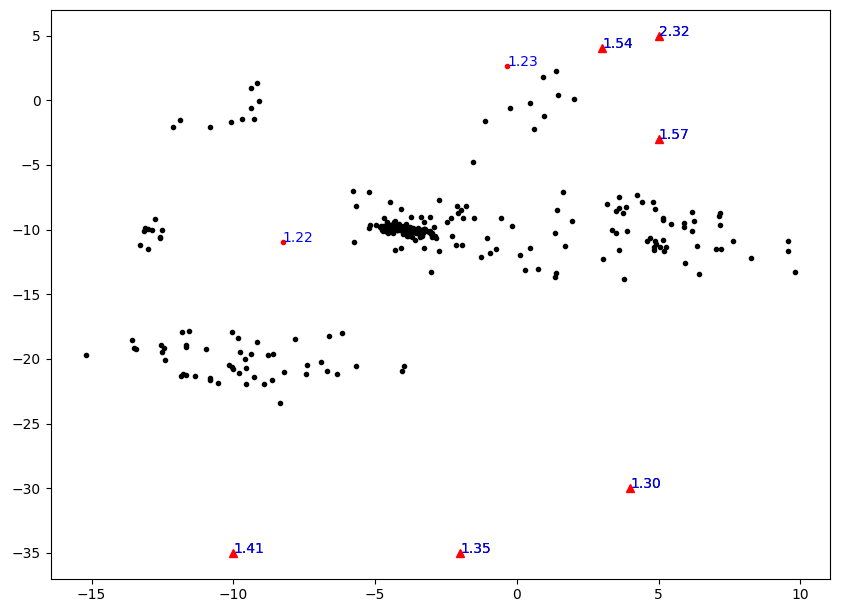
距離代替區域性可達距離
根據前面的疑問,用距離代替區域性可達距離進行相應實驗。僅在get_LOFs函數處做了相關改動,並將閾值threshold改為2。程式碼如下。
#%% 定義函數 import torch import matplotlib.pyplot as plt #計算所有樣本點[N, M]之間的距離,得到[N, N] def get_dists(points:torch.Tensor): x = torch.sum(points**2, 1).reshape(-1, 1) y = torch.sum(points**2, 1).reshape(1, -1) dists = x + y - 2 * torch.mm(points, points.permute(1,0)) #數值計算問題,防止對角線小於0 dists = dists - torch.diag_embed(torch.diag(dists)) return torch.sqrt(dists) #計算所有樣本點到其k-鄰域點的k-可達距離 def get_LOFs(dists:torch.Tensor, k): #距離排序,獲取所有樣本點的k-臨近距離 sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False) densities = (sorted_dists[:, 1:k+1].sum(1)/k)**-1 neighbor_inds = sorted_inds[:, 1:k+1].reshape(-1) neighbor_densities = densities[neighbor_inds].reshape(-1, k) LOFs = neighbor_densities.sum(1)/k/densities return LOFs #%% 隨機生成聚集點和異常點 from torch.distributions import MultivariateNormal torch.manual_seed(0) crowd_mu_covs = [ [[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10], [[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10], [[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50], [[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50], [[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50], [[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10], [[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100], ]#正態分佈點的均值和方差 outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #異常點 points = [] for i in crowd_mu_covs: mu = torch.tensor(i[0]) cov = torch.tensor(i[1]) ps = MultivariateNormal(mu, cov).sample([i[2]]).to('cuda') points.append(ps) for o in outliers: points.append(torch.tensor([o]).to('cuda')) points = torch.cat(points) #%% 計算LOFs並視覺化視覺化 k, threshold = 5, 2 dists = get_dists(points) LOFs = get_LOFs(dists, k) for i, p in enumerate(points.cpu().numpy()): shape, color = '.', 'black' if len(points) - i <= len(outliers): shape = '^' plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1])) if LOFs[i] > threshold: color = 'red' plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue') plt.plot(p[0], p[1], shape, color=color) plt.show()
視覺化結果如下圖所示。
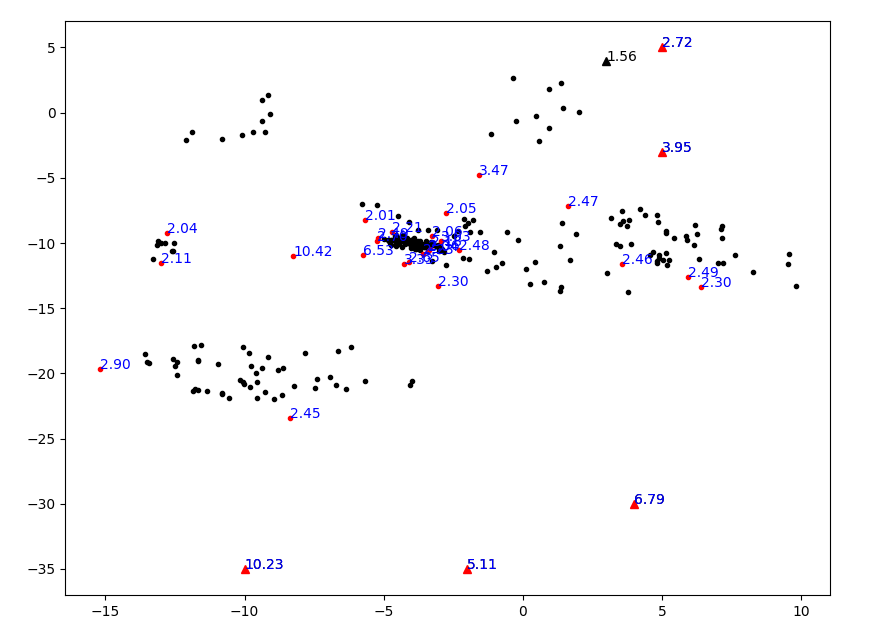
部分離群點的確能被有效找出,但是看起來似乎這個演演算法對「相對」的概念太顯著了,導致一個聚集的點群裡面也有很多不是那麼聚集的點被劃分為離群點。看來用距離代替區域性可達距離是不行的。但是如何從理論上來解釋,本文不再作深究,歡迎前來討論。