架構師日記-軟體高可用實踐那些事兒
作者:京東零售 劉慧卿
一 前言
關於軟體的高可用,是一個老生常談的話題。「高可用性」(High Availability)通常來描述一個系統經過專門的設計,從而減少停工時間,而保持其服務的高度可用性。其計算公式是:可用率=(總時間-不可用時間)/總時間。
本文重點從落地實踐的視角作為切入點,帶領大家從共同作業效率,技術落地和運營規範幾個方面來展現高可用的實施步驟和落地細節。為了方便理解,先來統一語言話術,看一下軟體交付過程中的各個階段,如下圖:
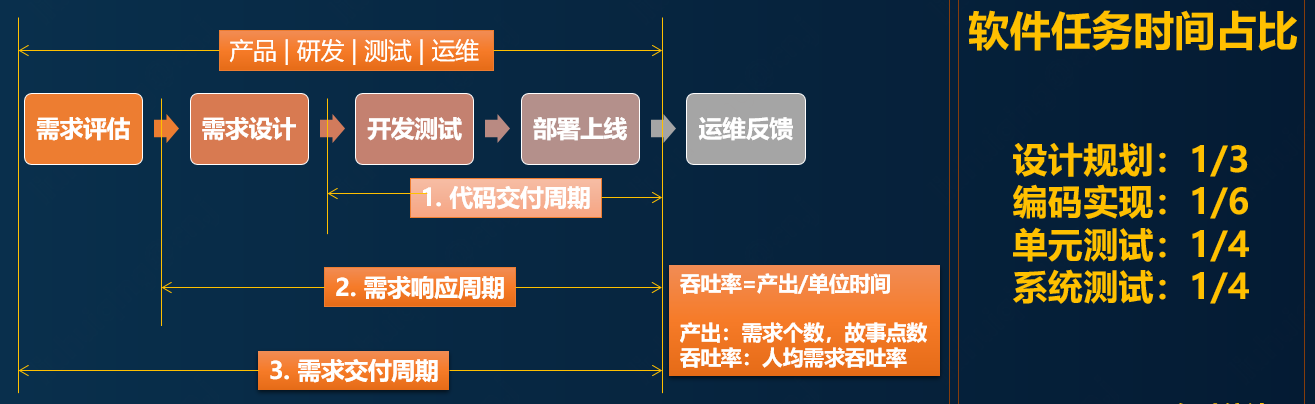
為什麼說軟體的高可用會面臨著諸多挑戰呢?
◦ 從需求交付鏈路來看,要完成目標交付,需要產品,研發,測試,運維,運營等多方利益相關者的密切配合。有些專案需求,合作者有時能夠達到上百人,每個人職責分工各不相同,但卻相互配合依賴,任何一個環節出現紕漏,可用率就有可能受到影響;
◦ 從時間角度來看,如果要達到全年99.99%的可用率,就意味著一年當中,允許有故障的時間為:365*24*60*(100%-99.99%)=52分鐘,如果要達到5個9的可用率,允許故障的時間僅為5分鐘,這差不多是我們發現問題後,重啟應用的耗時;
◦ 從迭代效率來看,不迭代,不上線,問題出現的概率一定會小很多。軟體的迭代效率和可用率之間存在著負相關的關係,平衡好兩者之間的關係,也會面臨著不小的挑戰。
總結一下,我們具體面臨的問題如下:
◦ 如何解決需求交付相關共同作業者多,鏈路長的問題?
◦ 如何應對故障時間容忍度低的問題?
◦ 如何在頻繁需求迭代的現狀下,保持可用率不受到大的衝擊問題?
二 共同作業效率保障
認知誤區
從整個需求交付鏈路我們可以發現,隨著鏈路的逐級遞增,資訊的傳遞鏈路分支就會越多,傳遞層級就會越深。這會導致兩個問題:
-
資訊傳遞效率降低;
-
資訊準確性變差。
這兩個問題最終導致的結果,就是共同作業效率的降低。

一個沒有實戰經驗的同學往往會認為增加人數,就會提高需求交付效率。其實這種想法不完全正確,具體關係參考下圖:

這就像蓋樓房,如果一個人按部就班的建設,需要100天完成。如果請了100個人來幫忙,能否用1天的時間完成房子建設呢?答案是否定的。
這裡面有共同作業的成本,比如:團隊默契(設計師,瓦工,泥工,水電工),崗位匹配,風險控制;
這裡面有流程的依賴,比如:施工依賴於設計,軟裝總在硬裝之後;
這裡面有成本預算,比如:整個組織的人才梯度,規模大小(承建方,代理商,承包商);
以上這些,都不是簡單的通過人力鋪設來解決的。
流程規範
提高共同作業效率的底層邏輯是通過減少交付鏈路層級,縮簡訊息傳遞鏈路,進而保證資訊的準確性和傳遞效率。(組織建設層面的內容這裡不做展開)
這就要求具有今日事,今日畢的行動力。組織層面這叫流程規範,個人層面這叫做事方法,責任心。
儘量避免將當下的事情拖延到下一個環節,否則就會影響後續鏈路的排期計劃和交付效率,極端情況甚至會出現返工的情形。簡言之,考慮清楚,不埋坑。產品需求對研發,研發設計對測試,測試用例對產品等各個交付節點都是如此,交付物一定是靠譜的。
三 技術落地保障
在需求響應週期中,高質量的落實架構設計,編碼實現,安全上線,部署運營等生產階段,是軟體高可用落地保障的前提和基礎。
架構設計
架構設計往往影響著系統的前期實現成本(即ROI)和後續運維難度,屬於軟體的頂層設計,這裡面既包含宏觀的設計方案,也包含落地細節裡的正規化約束。
• 流程保障
邀請架構師參與:核心交易節點、重大需求改動邀請架構師參與,這是閉坑最直接有效的方式;
重視設計檔案:方案描述清楚了,並取得相關利益者的認可,是走在正確道路上的前提。
• 設計保障
容災設計:要預留後路,提前想清楚,做好容災設計。可回滾,可熔斷,可重試,可降級。
魯棒性設計:無狀態設計,防重設計,冪等設計,資料一致性設計
編碼實現
如果說架構設計是骨架,那麼編碼實現就是神經,血管和肌肉。前者決定了能走多穩,走多久,後者決定著走多快,走多遠。落實到編碼層面,就是程式碼的衰老腐敗程度。
• 流程規範
程式碼評審機制:程式碼評審不僅僅是發現系統中存在的問題這麼簡單。它是一種長期行為,是進行組織文化貫徹和傳承的一種形式和載體。評審的過程中,明確了業務職責邊界,設計與編碼共識,優秀的標準導向等研發共識。相當於通過具象化的案例,給出針對性的指導,這些都是保證團隊戰鬥力的基石。
研發過程中的很多問題,通過程式碼評審機制可以被發現和解決,比如:
◦ 如何對待臨時需求的設計與實現?
◦ 如何看待「Hello World!」的N中寫法?
◦ 如何理解設計模式和過度設計的邊界?
◦ 如何評價當前階段的交付物?
◦ 是否有必要引入單元測試?
• 編碼規範
◦ 有沒有對錯誤進行處理?對於呼叫的外部服務,是否檢查了返回值或處理了異常?
◦ 設計是否遵從已知的設計模式或專案中常用的模式?
◦ 開發者新寫的程式碼能否用已有的SDK/Framework中的功能實現?在本專案中是否存在類似的功能可以呼叫而不用全部重新實現?
◦ 工程中是否引入了無用的,功能重複的,不同版本的jar包依賴?(json類庫,各種utils)
◦ 有沒有無用的程式碼可以清除?
◦ 程式碼可讀性如何?有沒有足夠的註釋?
◦ 引數傳遞有無錯誤,有沒有使用斷言(Assert)或判斷來保證我們認為不變的條件真的得到滿足?
◦ 邊界條件是如何處理的? switch語句的default分支是如何處理的?迴圈有沒有可能出現死迴圈?
◦ 對資源的利用,是在哪裡申請,在哪裡釋放的?有無可能存在資源洩漏(包括超時時間,記憶體、檔案、物件參照,大物件,執行緒數等)?有沒有優化的空間?
◦ 程式碼的效能如何?最壞的情況是怎樣的?
◦ 程式碼中,特別是迴圈中是否有明顯可優化的部分(string的操作是否能用StringBuilder來優化)?
◦ 對於系統和網路的呼叫是否會超時?如何處理?
◦ 程式碼是否易於測試(方法行數,圈複雜度,出入參定義是否合理)?
◦ 改動是否影響到舊版本、歷史資料、上游能否相容?
◦ 介面設計是否有考慮冪等、並行、越權,降級等問題?
◦ 是否存在快取、資料庫效能問題以及多資料來源資料一致性的問題?
◦ 上線方案是否考慮了灰度方案,資料狀態不一致問題?
安全上線
線上70%的故障都是由某種變更而觸發的,其中相當一部分佔比是不規範的上線引起的。所以安全上線這一環節至關重要。
• 流程規範
◦ 嚴禁頻繁上線:比如,每週不大於2次;
◦ 嚴禁高峰期上線:降低問題影響範圍;
◦ 嚴禁私自上線:有改動,必須通過測試驗證,產品迴歸確認;
• 過程規範
◦ 摘流量:選擇第一批機器jsf下線/np摘流量(選為冷備);
◦ 看紀錄檔:觀察紀錄檔確認摘除機器無流量;
◦ 服務預熱:確認機器啟動成功,核心業務介面需要介面預熱;
◦ 掛流量:掛載上線機器流量;
◦ 看指標:觀察上線機器mdc指標是否異常(cpu、記憶體、負載)、紀錄檔是否有異常
部署運營
實現高可用的一個很重要的手段就是能力冗餘。下面給出方向和思路,具體落地細節和策略,可以根據具體情況各自延展。
• 網路
◦ 運營商層面,聯通,電信,移動等;
◦ 鏈路節點方面,VIP,CDN,路由器/交換機,反向代理,使用者端,瀏覽器等;
• 儲存
◦ 無論是資料庫主從架構,還是ES的副本架構,都是實現儲存高可用的手段,重要資料要利用好相關特性;
◦ 在進行資料結構設計時,同樣也需要做好分流策略,容量規劃,資料拆分或異構。比如:避免快取熱key,資料庫表吞吐量瓶頸,資料庫連線數限制等各種影響高可用的問題出現。
• 服務
◦ 橫向擴容:服務要保證可以通過新增資源的方式進行能力擴容,這一點非常重要;
◦ 服務分組:按照業務方或使用場景,對服務進行不同粒度的隔離,防止極端情況導致服務相互影響;
◦ 極限策略:主要是一些極端異常情況下的防禦策略,目的是意外發生後,儘量保持服務的可靠性。比如:限流,熔斷,重試,快速失敗等;
◦ 灰度策略:新功能上線,往往是最容易出現問題的時候,擁有成熟的流量灰度能力,是控制問題影響範圍的關鍵;
四 運營規範保障
運營規範
-
可監控:系統執行狀況
-
可報警:異常情況能夠通知到系統相關人員
-
可定位:出現問題後,能夠快速定位問題原因
-
可修復:出現異常情況,能夠在第一時間進行問題修復;
應急預案
高可用意味著對故障時間的容忍性差,意味著沒有時間進行故障排查和修復,更沒有時間開啟程式碼進行漏洞排查。這就要求我們有一套完備的應急預案,這套預案能夠解決大部分可預見的故障問題。
• 流程規範
◦ 恢復生產第一;
◦ 排查問題第二;
詳細事故應急處理手冊,可以參照下圖:

• 過程規範
◦ 網路,服務,儲存分三個維度制定對應方案,並將應急預案清單(檔名:checklist)填寫到自己的程式碼庫中,保持內容傳承和更新;
◦ 可預見性,即問題觸發場景要寫清楚。舉例:按照當前進度(1萬/天),隨著資料庫資料的增加,預計10個月後,資料庫表(xxx表名)會出現慢查詢;
◦ 可執行性,能夠消除問題的解決方案。舉例:啟動歷史資料歸檔任務(xxxWorker),將歷史資料進行轉移到歸檔資料庫中;
規範達標
再好的流程和規範都需要有對應的機制來貫徹執行,否則就是鏡中花,水中月,看著美好,實則沒用。可執行,能度量,是按照目標變好的前提。所以這裡給出一個《高可用達標定期自查表》的工具,輔助規範落地。
| 高可用達標定期自查表 |
| 規範分類 | 指標分類 | 指標項說明 | 達標 | 未達標原因 |
| 健康達標 | 靜態程式碼掃描 | block個數和超高圈複雜度個數為0 | | |
| 故障診斷 | 應用已接入鏈路跟蹤 | | |
| 各項監控指標正常 | | |
| 應用健康度 | 98分以上 | | |
| 儲存 | 系統所用儲存,具有主從容災,多機房的特性 | | |
| 安全 | web後門工具必須有許可權認證 | | |
| 應急預案 | 系統中是否存在checklist檔案 | | |
| 中介軟體達標 | 紀錄檔列印 | 使用slf4j元件 | | |
| 紀錄檔輸出需要引數化 | | |
| 存在紀錄檔級別動態調整開關 | | |
| log組態檔,屬性設定了additivity=false | | |
| JDOS紀錄檔設定定時清理 | | |
| worker | 設定了呼叫次數的UMP異常監控報警 | | |
| 兩週內,不存在排程異常的任務 | | |
| 依賴jar包版本,是否最新版本3.3.2 | | |
| 執行緒組和執行緒數設定是否合理(執行緒組<=32) | | |
| JSF | JSF版本>=1.7.4、序列化方式=hession | | |
| 多機房部署 | | |
| 各分組啟動指令碼設定一致 | | |
| 同組下IP流量效能均衡 | | |
| 不存在預釋出和線上跨環境呼叫問題 | | |
| 研發工具擁有token授權驗證機制 | | |
| 核心介面設定了限流策略 | | |
| 方法呼叫次數>高峰期2報警 | | |
| consumer消費超時,建議值小於2000ms | | |
| 資料庫 | 連線數檢查,小於最大連線數0.8 | | |
| cpu使用率檢查,小於90% | | |
| 系統負載檢查,小於cpu核數2 | | |
| 慢SQL檢查 | | |
| 索引合理性檢查 | | |
| 自增ID是否bigint型別檢查 | | |
| 單表資料量<1000萬檢查 | | |
| 監控預警 | 網路 | 域名多VIP且分佈在不同機房 | | |
| 內網存取域名系結的VIP不能有外網存取許可權 | | |
| 域名系結的服務IP有效性檢查,不能錯掛,漏掛 | | |
| 機器監控 | 域名連通性報警 | | |
| IP維度的監控報警 | | |
| 記憶體使用率>90%報警 | | |
| 磁碟使用率>85%報警 | | |
| 系統負載>cpu核數2報警 | | |
| TCP重傳數>5報警 | | |
| JVM監控 | FullGC報警,2小時<2次 | | |
| 執行緒數<日常峰值1.2報警 | | |
| CPU使用率一分鐘激增監控預警(預設5分鐘) | | |
| MQ監控 | 設定積壓和重試報警 | | |
| 快取監控 | QPS>快取分片數2萬報警 | | |
| 記憶體使用率>80%報警 | | |
| 熱key檢查 | | |
| 慢紀錄檔檢查 | | |
| 效能監控檢查 | | |
| 資料分片均勻檢查 | | |
| 應用方法監控 | 所有api介面有呼叫次數和可用率監控預警 | | |
| 所有依賴的rpc介面要有次數和可用率監控預警 | | |
| 是否設定了系統存活監控預警 | | |
五 總結
本文從「高可用為什麼存在著很大挑戰?」的問題展開探討,強調了需求交付過程中,共同作業效率的重要性,並指出了為什麼要遵從「今日事,今日畢」的工作原則。又從架構設計,編碼實現,安全上線,部署運營等幾個方面,詳細介紹了技術落地保障相關的指導規範和落地細節。最後又從上線後運營的角度,給出了應急預案三板斧,規範達標定期自查表等比較實用的運營保障工具。希望能夠給讀者帶來幫助。