sql處理重複的列,更好理清分組和分割區
一、分組統計、分割區排名
1、語法和含義:
如果查詢結果看得有疑惑,看第二部分-sql處理重複的列,更好理清分組和分割區,有建表插入資料的sql語句
分組統計:GROUP BY 結合 統計/聚合函數一起使用
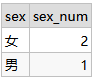
-- 舉例子: 按照性別統計男生、女生的人數
select sex,count(distinct id) sex_num from student_score group by sex;
分割區排名:ROW_NUMBER() OVER(PARTITION BY 分割區的欄位 ORDER BY 升序/降序欄位 [DESC])
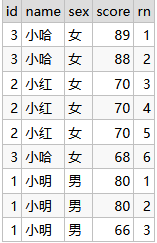
-- 舉例子: 按照性別-男生、女生進行分割區,按照成績進行降序
select id,name,sex,score,
ROW_NUMBER() OVER(PARTITION BY sex ORDER BY score DESC) rn
from student_score;
2、使用注意事項:
▷ 排名函數row_number() 需要的mysql 版本需要8及以上!
▷ 對於分組統計 group by 容易出現的報錯問題:
因為規定要求 select 列表的欄位非聚合欄位,必須出現在group by後面進行分組。
報錯:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column '資料庫.表.欄位' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
SELECT列表的表示式-不在GROUP BY子句中,並且包含非聚合列'資料庫.表.欄位'。
▷ 對於排名函數ROW_NUMBER,容易出現的報錯問題:
- 一般是你的分割區欄位寫得有問題,可以堅持一下分割區欄位!比如在hive中,分割區欄位為 get_json_object(map_col,'$.title'),但是漏掉了一個'
報錯:Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular dependencies.
未能將視窗呼叫分解為組。至少 1 個組必須僅依賴於輸入列。還要檢查迴圈依賴。
二、sql處理重複的列,更好理清分組和分割區
1、sql語句-建表、插入資料的語句
DROP TABLE IF EXISTS `student_score`;
CREATE TABLE `student_score` (
`id` int(6),
`name` varchar(255),
`sex` varchar(255),
`subject` varchar(30),
`score` float
) ENGINE = InnoDB;
INSERT INTO `student_score` VALUES (1, '小明', '男','語文', 80);
INSERT INTO `student_score` VALUES (2, '小紅', '女','語文', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','語文', 88);
INSERT INTO `student_score` VALUES (1, '小明', '男','數學', 66);
INSERT INTO `student_score` VALUES (2, '小紅', '女','數學', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','數學', 89);
INSERT INTO `student_score` VALUES (1, '小明', '男','英語', 80);
INSERT INTO `student_score` VALUES (2, '小紅', '女','英語', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','英語', 68);
2、查詢所有學生的成績:
- select * from student_score;
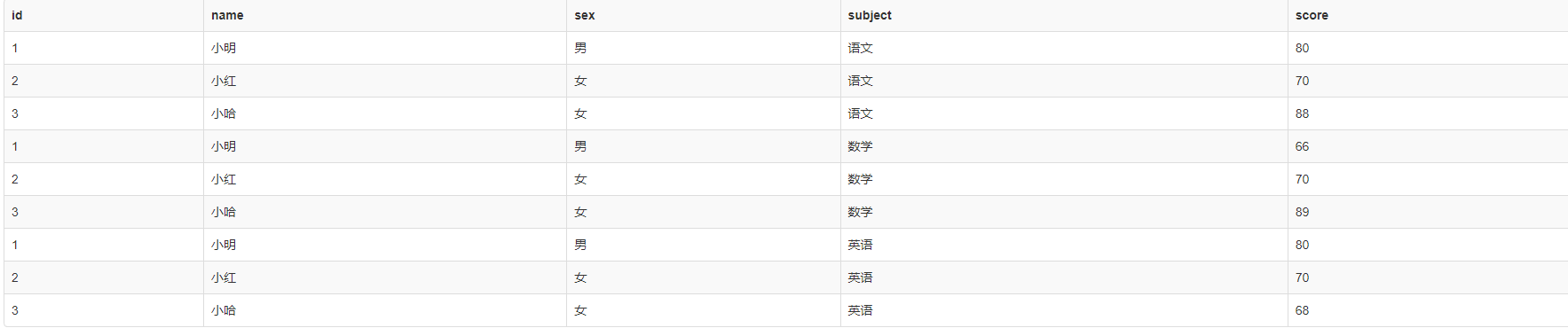
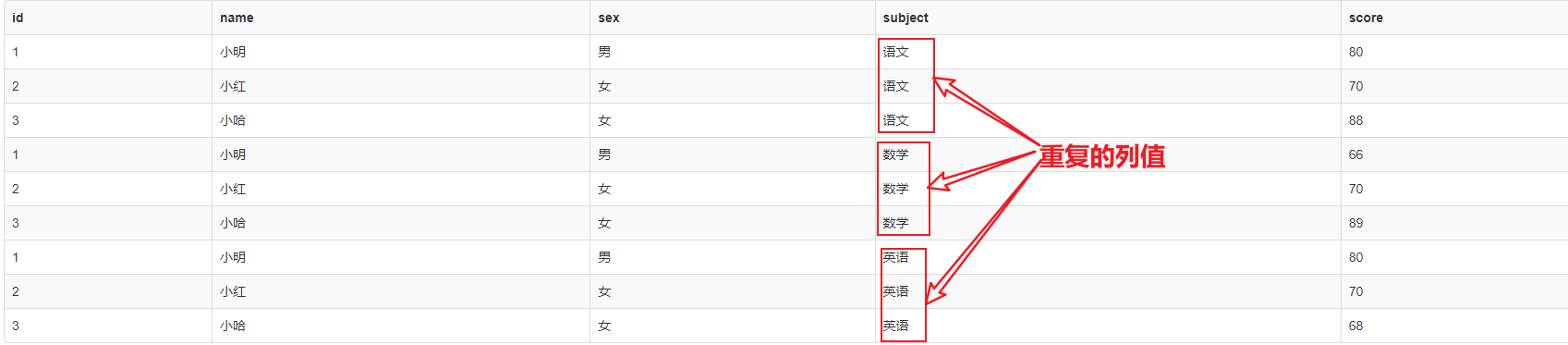
3、結果,有重複的列值
相應的成績對應的學科名稱是以列的形式展示的,造成了語文、語文、語文的重複
4-1、處理重複的列-方式1-合併去除重複的列值[列轉行]
對應到常見的sql應用場景,統計各個學生的各科成績,實現方式有兩種,一種是分組統計的方式,一種是分割區排名的方式
分組統計:
select id,name,sex,
max(case when subject='語文' then score else 0 end) as chinese,
max(case when subject='英語' then score else 0 end) as english,
max(case when subject='數學' then score else 0 end) as math
from student_score
group by id
order by score desc
- 結果:

按成績降序排序,可以看到預設選擇第一門學科-語文的成績進行降序排序。
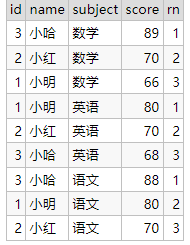
4-2、處理重複的列-方式2-對重複的列值進行排名
分割區排名
select id,name,subject,score,
row_number() over(partition by subject order by score desc) rn
from student_score;
三、總結分組、分割區的區別
例如按學科分組或按學科分割區,那麼,分組得到的是一個列值(一條記錄資料)的結果,分割區是多個列值(多條記錄資料)的結果。
分組-一條記錄

分割區-多條記錄

如果本文對你有幫助的話記得給一樂點個贊哦,感謝!
本文來自部落格園,作者:一樂樂,轉載請註明原文連結:https://www.cnblogs.com/shan333/p/17206824.html