Hadoop-HA節點介紹
2023-03-11 06:00:44
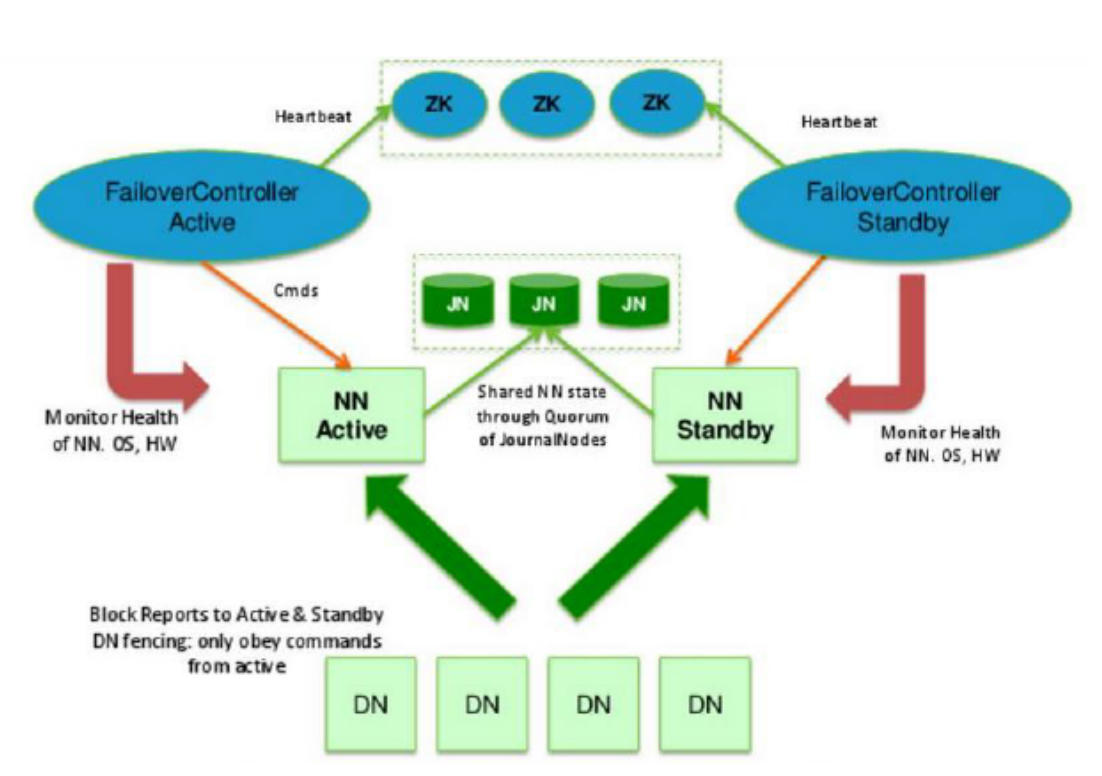
設計思想
- hadoop2.x啟用了主備節點切換模式(1主1備)
- 當主節點出現異常的時候,叢集直接將備用節點切換成主節點
- 要求備用節點馬上就要工作
- 主備節點記憶體幾乎同步
- 有獨立的執行緒對主備節點進行監控健康狀態
- 需要有一定的選舉機制,幫助我們確定主從關係
- 我們需要實時儲存紀錄檔的中介軟體
ActiveNameNode(ANN)
- Active NameNode 的功能和原理的NN的功能是一樣的
- 接受使用者端請求,查詢資料塊DN資訊
- 儲存資料的後設資料資訊
- 資料檔案:Block:DN的對映關係
- 工作
- 啟動時:接受DN的block彙報
- 執行時:和DN保持心跳(3s,10m30s)
- 儲存媒介
- 完全基於記憶體
- 優點:資料處理效率高
- 缺點:資料的持久化(紀錄檔edits+快照fsimage)
StandbyNameNode(SNN)
- Standby NameNode:NN的備用節點
- 他和主節點做同樣的工作,但是它不會發出任何指令
- 儲存:資料的後設資料資訊
- 資料檔案:Block:DN的對映關係
- 它的記憶體資料和主節點記憶體資料幾乎是一致的
- 工作:
- 啟動時:接受DN的block彙報
- 執行時:和DN保持心跳(3s,10m30s)
- 儲存媒介
- 完全基於記憶體
- 優點:資料處理效率高
- 缺點:資料的持久化
- 合併紀錄檔檔案和映象
- 當搭建好叢集的時候,格式化主備節點的時候,ANN和SNN都會會預設建立
- fsimage_000000000000000
- 當我們操作HDFS的時候ANN會產生紀錄檔資訊
- edits_inprogress_0000000000001
- 主節點會將紀錄檔檔案中新增的資料同步到JournalNode叢集上
- 所以只需要snn有操作的紀錄檔資訊,就可以合併fsImage與edits資訊,理論上是一直在合併資料
- fsimage -->初始化建立
- edits-->從JournalNode叢集上定時同步
- 只要同步到edits檔案,就開始於fsimage合併
- 當達到閾值的時候,直接拍攝快照即可
- SNN將合併好的Fsimage傳送給ANN,ANN驗證無誤後,存放到自己的目錄中
- 當搭建好叢集的時候,格式化主備節點的時候,ANN和SNN都會會預設建立
DataNode (DN)
- 儲存
- 檔案的Block資料
- 媒介
- 硬碟
- 啟動時:同時向兩個NN彙報Block資訊
- 執行中同時和兩個NN節點保持心跳機制
Quorum JournalNode Manager (QJM)

- Quorum JournalNode Manager 共用儲存系統,NameNode通過共用儲存系統實現紀錄檔資料同
步。 - JournalNode是一個獨立的小叢集,它的實現原理和Zookeeper的一致( Paxos)
- ANN產生紀錄檔檔案的時候,就會同時傳送到 JournalNode的叢集中每個節點上
- JournalNode不要求所有的jn節點都接收到紀錄檔,只要有半數以上的(n/2+1)節點接受收到日
志,那麼本條紀錄檔就生效 - SNN每間隔一段時間就去QJM上面取回最新的紀錄檔
- SNN上的紀錄檔有可能不是最新的
- HA叢集的狀態正確至關重要,一次只能有一個NameNode處於活動狀態。
- JournalNode只允許單個NameNode成為作者。在故障轉移期間,將變為活動狀態的NameNode
將承擔寫入JournalNodes的角色,這將有效地防止另一個NameNode繼續處於活動狀態,從而使 新的Active節點可以安全地進行故障轉移。
Zookeeper Failover Controler(ZFKC)
- Failover Controller(故障轉移控制器)
- 對 NameNode 的主備切換進行總體控制,能及時檢測到 NameNode 的健康狀況
- 在主 NameNode 故障時藉助 Zookeeper 實現自動的主備選舉和切換
- 為了防止因為NN的GC失敗導致心跳受影響,ZKFC作為一個deamon程序從NN分離出來

- 啟動時:
- 當叢集啟動時,主備節點的概念是很模糊的
- 當ZKFC只檢查到一個節點是健康狀態,直接將其設定為主節點
- 當zkfc檢查到兩個NN節點是的健康狀態,發起投票機制
- 選出一個主節點,一個備用節點,並修改主備節點的狀態
- 執行時:
- 由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 這 3 個元件來協同實現主備切換
- ZKFailoverController啟動的時候會建立 HealthMonitor 和 ActiveStandbyElector 這兩
個主要的內部元件 - HealthMonitor 主要負責檢測 NameNode 的健康狀態
- ActiveStandbyElector 主要負責完成自動的主備選舉,內部封裝了 Zookeeper 的處理邏
輯
- ZKFailoverController啟動的時候會建立 HealthMonitor 和 ActiveStandbyElector 這兩
- 由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 這 3 個元件來協同實現主備切換
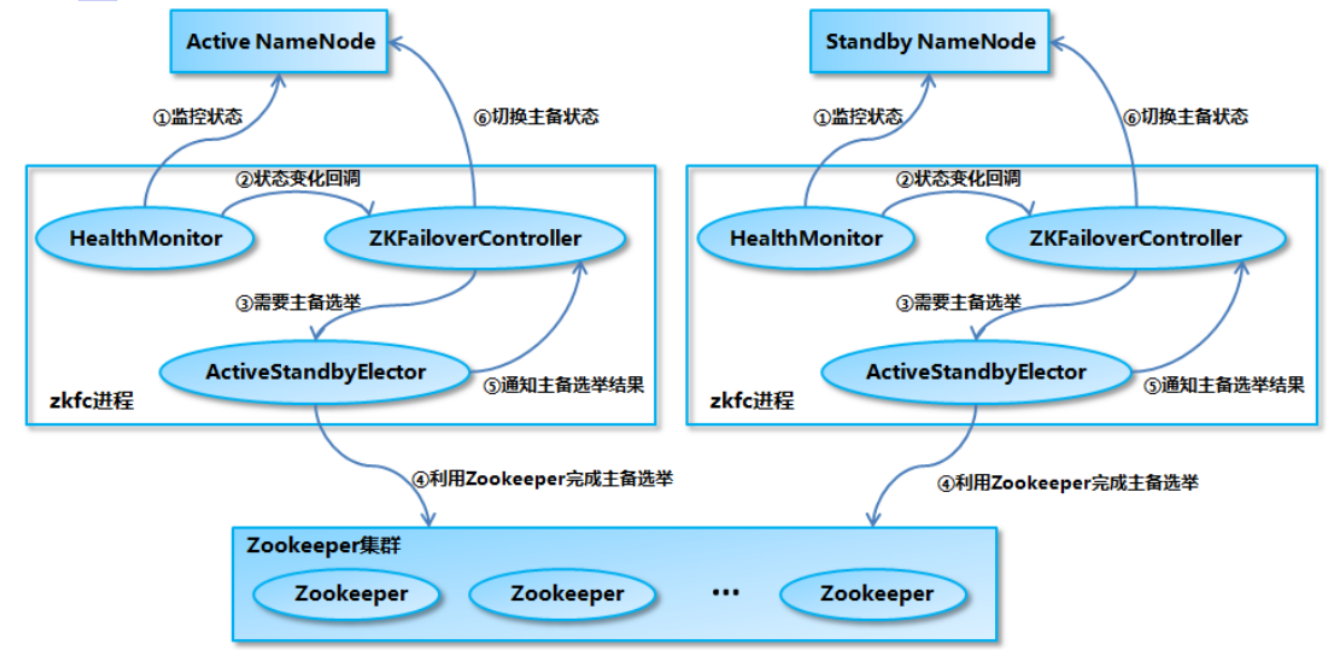
- 主備節點正常切換
- NameNode 在選舉成功後,ActiveStandbyElector會在 zk 上建立一個
ActiveStandbyElectorLock 臨時節點,而沒有選舉成功的備 NameNode 中的
ActiveStandbyElector會監控這個節點 - 如果 Active NameNode 對應的 HealthMonitor 檢測到 NameNode 的狀態異常時,
ZKFailoverController 會主動刪除當前在 Zookeeper 上建立的臨時節點
ActiveStandbyElectorLock - 如果是 Active 狀態的 NameNode 所在的機器整個宕掉的話,那麼跟zookeeper連線的客戶
端執行緒也掛了,對談結束,那麼根據 Zookeepe的臨時節點特性,ActiveStandbyElectorLock 節點會自動被刪除,從而也會自動進行一次主備切換 - 處於 Standby 狀態的 NameNode 的 ActiveStandbyElector 註冊的監聽器就會收到這個節點
的 NodeDeleted 事件,並建立 ActiveStandbyElectorLock 臨時節點,本來處於 Standby 狀
態的 NameNode 就選舉為Active NameNode 並隨後開始切換為 Active 狀態。
- NameNode 在選舉成功後,ActiveStandbyElector會在 zk 上建立一個
Zookeeper
- 為主備切換控制器提供主備選舉支援。
- 輔助投票
- 和ZKFC保持心跳機制,確定ZKFC的存活
腦裂 Brain-split
- 定義
- 腦裂是Hadoop2.X版本後出現的全新問題,實際執行過程中很有可能出現兩個namenode同
時服務於整個叢集的情況,這種情況稱之為腦裂。
- 腦裂是Hadoop2.X版本後出現的全新問題,實際執行過程中很有可能出現兩個namenode同
- 原因
- 腦裂通常發生在主從namenode切換時,由於ActiveNameNode的網路延遲、裝置故障等問
題,另一個NameNode會認為活躍的NameNode成為失效狀態,此時StandbyNameNode會
轉換成活躍狀態,此時叢集中將會出現兩個活躍的namenode。因此,可能出現的因素有網
絡延遲、心跳故障、裝置故障等。、
- 腦裂通常發生在主從namenode切換時,由於ActiveNameNode的網路延遲、裝置故障等問
- 腦裂場景
- NameNode 可能會出現這種情況,NameNode 在垃圾回收(GC)時,可能會在長時間內整 個系統無響應
- zkfc使用者端也就無法向 zk 寫入心跳資訊,這樣的話可能會導致臨時節點掉線,備NameNode 會切換到 Active 狀態
- 這種情況可能會導致整個叢集會有同時有兩個Active NameNode
- 腦裂問題的解決方案是隔離(Fencing)
- 第三方共用儲存:任一時刻,只有一個 NN 可以寫入
- DataNode:需要保證只有一個 NN 發出與管理資料副本有關的命令
- Client需要保證同一時刻只有一個 NN 能夠對 Client 的請求發出正確的響應。
- 每個NN改變狀態的時候,向DN傳送自己的狀態和一個序列號。
- DN在執行過程中維護此序列號,當failover時,新的NN在返回DN心跳時會返回自己
的active狀態和一個更大的序列號。DN接收到這個返回是認為該NN為新的active。 - 如果這時原來的active(比如GC)恢復,返回給DN的心跳資訊包含active狀態和原來
的序列號,這時DN就會拒絕這個NN的命令。
- 解決方案
- ActiveStandbyElector為了實現 fencing,當NN成為ANN之後建立Zookeeper臨時節點
ActiveStandbyElectorLock,建立ActiveBreadCrumb 的持久節點,這個節點裡面儲存了這個Active NameNode的地址資訊(node-01) - Active NameNode的 ActiveStandbyElector在正常的狀態下關閉 Zookeeper Session 的時
候,會一起刪除這個持久節點 - 但如果 ActiveStandbyElector在異常的狀態下關閉,那麼由於 /hadoop-
ha/${dfs.nameservices}/ActiveBreadCrumb 是持久節點,會一直保留下來,後面當另一個
NameNode 選主成功之後,會注意到上一個 Active NameNode 遺留下來的這個節點,從而
會回撥 ZKFailoverController的方法對舊的 Active NameNode 進行 fencing。- 首先嚐試呼叫這個舊 Active NameNode 的 HAServiceProtocol RPC 介面的
transitionToStandby 方法,看能不能把它轉換為 Standby 狀態 - 如果 transitionToStandby 方法呼叫失敗,那麼就執行 Hadoop 組態檔之中預定義的
隔離措施- sshfence:通過 SSH 登入到目標機器上,執行命令 fuser 將對應的程序殺死
- shellfence:執行一個使用者自定義的 shell 指令碼來將對應的程序隔離
- 首先嚐試呼叫這個舊 Active NameNode 的 HAServiceProtocol RPC 介面的
- 在成功地執行完成 fencing 之後,選主成功的 ActiveStandbyElector 才會回撥
ZKFailoverController 的 becomeActive 方法將對應的 NameNode 轉換為 Active 狀態,開始 對外提供服務
- ActiveStandbyElector為了實現 fencing,當NN成為ANN之後建立Zookeeper臨時節點