Java
一、說明
在JDBC中,executeBatch這個方法可以將多條dml語句批次執行,效率比單條執行executeUpdate高很多,這是什麼原理呢?在mysql和oracle中又是如何實現批次執行的呢?本文將給大家介紹這背後的原理。
二、實驗介紹
本實驗將通過以下三步進行
a. 記錄jdbc在mysql中批次執行和單條執行的耗時
b. 記錄jdbc在oracle中批次執行和單條執行的耗時
c. 記錄oracle plsql批次執行和單條執行的耗時
相關java和資料庫版本如下:Java17,Mysql8,Oracle11G
三、正式實驗
在mysql和oracle中分別建立一張表
create table t ( -- mysql中建立表的語句
id int,
name1 varchar(100),
name2 varchar(100),
name3 varchar(100),
name4 varchar(100)
);
create table t ( -- oracle中建立表的語句
id number,
name1 varchar2(100),
name2 varchar2(100),
name3 varchar2(100),
name4 varchar2(100)
);
在實驗前需要開啟資料庫的審計
mysql開啟審計:
set global general_log = 1;
oracle開啟審計:
alter system set audit_trail=db, extended;
audit insert table by scott; -- 實驗採用scott使用者批次執行insert的方式
java程式碼如下:
import java.sql.*;
public class JdbcBatchTest {
/**
* @param dbType 資料庫型別,oracle或mysql
* @param totalCnt 插入的總行數
* @param batchCnt 每批次插入的行數,0表示單條插入
*/
public static void exec(String dbType, int totalCnt, int batchCnt) throws SQLException, ClassNotFoundException {
String user = "scott";
String password = "xxxx";
String driver;
String url;
if (dbType.equals("mysql")) {
driver = "com.mysql.cj.jdbc.Driver";
url = "jdbc:mysql://ip/hello?useServerPrepStmts=true&rewriteBatchedStatements=true";
} else {
driver = "oracle.jdbc.OracleDriver";
url = "jdbc:oracle:thin:@ip:orcl";
}
long l1 = System.currentTimeMillis();
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, user, password);
connection.setAutoCommit(false);
String sql = "insert into t values (?, ?, ?, ?, ?)";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
for (int i = 1; i <= totalCnt; i++) {
preparedStatement.setInt(1, i);
preparedStatement.setString(2, "red" + i);
preparedStatement.setString(3, "yel" + i);
preparedStatement.setString(4, "bal" + i);
preparedStatement.setString(5, "pin" + i);
if (batchCnt > 0) {
// 批次執行
preparedStatement.addBatch();
if (i % batchCnt == 0) {
preparedStatement.executeBatch();
} else if (i == totalCnt) {
preparedStatement.executeBatch();
}
} else {
// 單條執行
preparedStatement.executeUpdate();
}
}
connection.commit();
connection.close();
long l2 = System.currentTimeMillis();
System.out.println("總條數:" + totalCnt + (batchCnt>0? (",每批插入:"+batchCnt) : ",單條插入") + ",一共耗時:"+ (l2-l1) + " 毫秒");
}
public static void main(String[] args) throws SQLException, ClassNotFoundException {
exec("mysql", 10000, 50);
}
}
程式碼中幾個注意的點,
- mysql的url需要加入useServerPrepStmts=true&rewriteBatchedStatements=true引數。
- batchCnt表示每次批次執行的sql條數,0表示單條執行。
首先測試mysql
exec("mysql", 10000, batchCnt);
代入不同的batchCnt值看執行時長
batchCnt=50 總條數:10000,每批插入:50,一共耗時:4369 毫秒
batchCnt=100 總條數:10000,每批插入:100,一共耗時:2598 毫秒
batchCnt=200 總條數:10000,每批插入:200,一共耗時:2211 毫秒
batchCnt=1000 總條數:10000,每批插入:1000,一共耗時:2099 毫秒
batchCnt=10000 總條數:10000,每批插入:10000,一共耗時:2418 毫秒
batchCnt=0 總條數:10000,單條插入,一共耗時:59620 毫秒
檢視general log
batchCnt=50
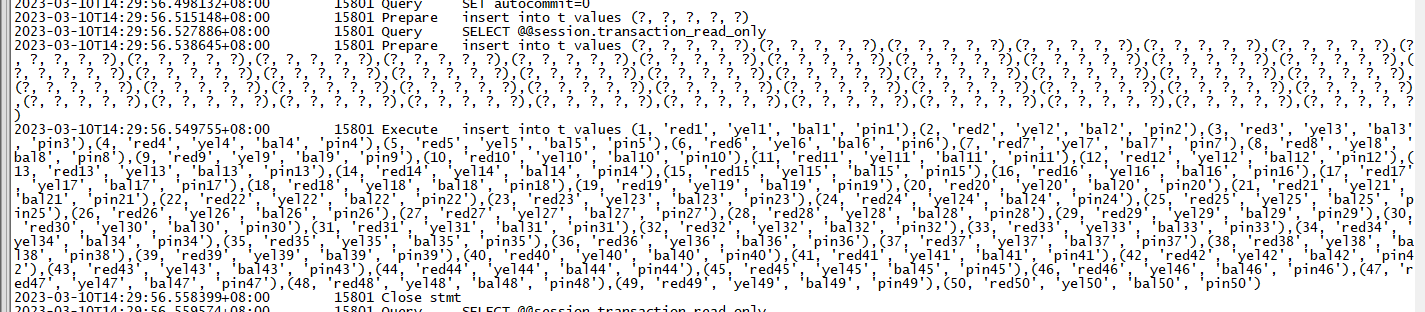
batchCnt=0
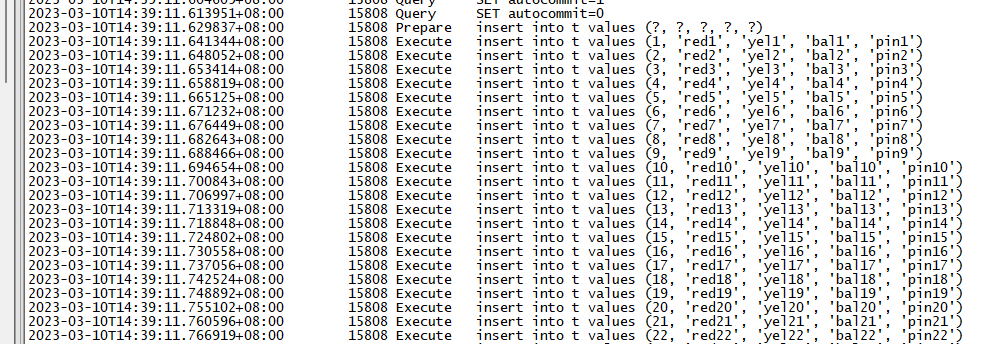
可以得出幾個結論:
- 批次執行的效率相比單條執行大大提升。
- mysql的批次執行其實是改寫了sql,將多條insert合併成了insert xx values(),()...的方式去執行。
- 將batchCnt由50改到100的時候,時間基本上縮短了一半,但是再擴大這個值的時候,時間縮短並不明顯,執行的時間甚至還會升高。
分析原因:
當執行一條sql語句的時候,使用者端傳送sql文字到資料庫伺服器,資料庫執行sql再將結果返回給使用者端。總耗時 = 資料庫執行時間 + 網路傳輸時間。使用批次執行減少往返的次數,即降低了網路傳輸時間,總時間因此降低。但是當batchCnt變大,網路傳輸時間並不是最主要耗時的時候,總時間降低就不會那麼明顯。特別是當batchCnt=10000,即一次性把1萬條語句全部執行完,時間反而變多了,這可能是由於程式和資料庫在準備這些入參時需要申請更大的記憶體,所以耗時更多(我猜的)。
再來說一句,batchCnt這個值是不是能無限大呢,假設我需要插入的是1億條,那麼我能一次性批次插入1億條嗎?當然不行,我們不考慮undo的空間問題,首先你電腦就沒有這麼大的記憶體一次性把這1億條sql的入參全部儲存下來,其次mysql還有個引數max_allowed_packet限制單條語句的長度,最大為1G位元組。當語句過長的時候就會報"Packet for query is too large (1,773,901 > 1,599,488). You can change this value on the server by setting the 'max_allowed_packet' variable"。
接下來測試oracle
exec("oracle", 10000, batchCnt);
代入不同的batchCnt值看執行時長
batchCnt=50 總條數:10000,每批插入:50,一共耗時:2055 毫秒
batchCnt=100 總條數:10000,每批插入:100,一共耗時:1324 毫秒
batchCnt=200 總條數:10000,每批插入:200,一共耗時:856 毫秒
batchCnt=1000 總條數:10000,每批插入:1000,一共耗時:785 毫秒
batchCnt=10000 總條數:10000,每批插入:10000,一共耗時:804 毫秒
batchCnt=0 總條數:10000,單條插入,一共耗時:60830 毫秒
可以看到oracle中執行的效果跟mysql中基本一致,批次執行的效率相比單條執行都大大提升。問題就來了,oracle中並沒有這種insert xx values(),()..語法呀,那它是怎麼做到批次執行的呢?
檢視當執行batchCnt=50的審計檢視dba_audit_trail
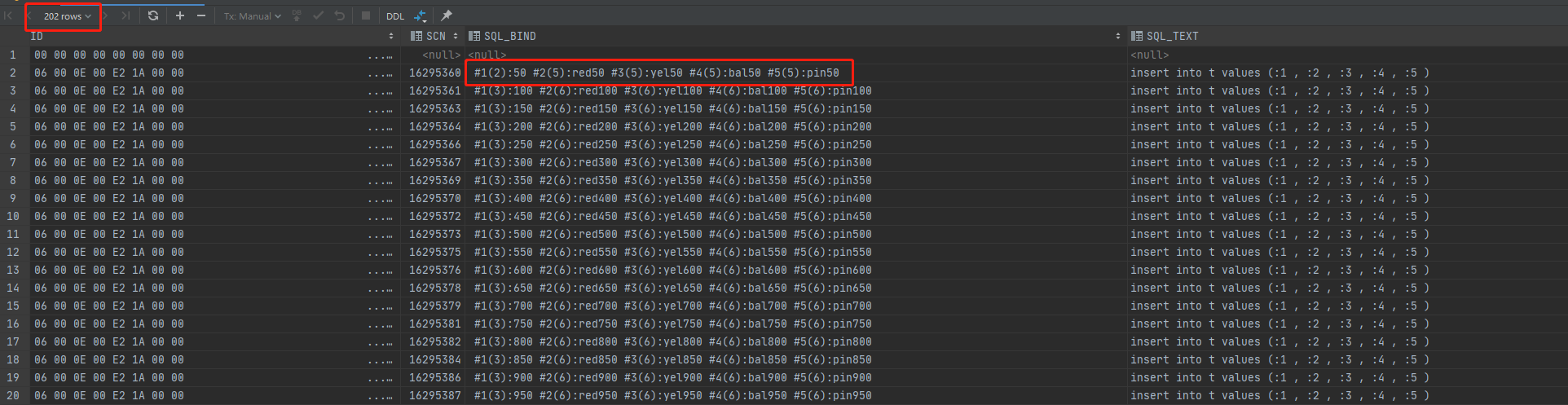
從審計的結果中可以看到,batchCnt=50的時候,審計記錄只有200條(扣除登入和登出),也就是sql只執行了200次。sql_text沒有發生改寫,仍然是"insert into t values (:1 , :2 , :3 , :4 , :5 )",而且sql_bind只記錄了批次執行的最後一個引數,即50的倍數。從awr報告中也能看出的確是只執行了200次(限於篇幅,awr截圖省略)。那麼oracle是怎麼做到只執行200次但插入1萬條記錄的呢?我們來看看oracle中使用儲存過程的批次插入。
四、儲存過程
準備資料:
首先將t表清空 truncate table t;
用java往t表灌10萬資料 exec("oracle", 100000, 1000);
建立t1表 create table t1 as select * from t where 1 = 0;
以下兩個procudure的目的相同,都是將t表的資料灌到t1表中。nobatch是單次執行,usebatch是批次執行。
create or replace procedure nobatch is
begin
for x in (select * from t)
loop
insert into t1 (id, name1, name2, name3, name4)
values (x.id, x.name1, x.name2, x.name3, x.name4);
end loop;
commit;
end nobatch;
/
create or replace procedure usebatch (p_array_size in pls_integer)
is
type array is table of t%rowtype;
l_data array;
cursor c is select * from t;
begin
open c;
loop
fetch c bulk collect into l_data limit p_array_size;
forall i in 1..l_data.count insert into t1 values l_data(i);
exit when c%notfound;
end loop;
commit;
close c;
end usebatch;
/
執行上述儲存過程
SQL> exec nobatch;
Elapsed: 00:00:32.92
SQL> exec usebatch(50);
Elapsed: 00:00:00.77
SQL> exec usebatch(100);
Elapsed: 00:00:00.47
SQL> exec usebatch(1000);
Elapsed: 00:00:00.19
SQL> exec usebatch(100000);
Elapsed: 00:00:00.26
儲存過程批次執行效率也遠遠高於單條執行。檢視usebatch(50)執行時的審計紀錄檔,sql_bind也只記錄了批次執行的最後一個引數,即50的倍數。跟前面jdbc使用executeBatch批次執行時的記錄內容一樣。由此可知jdbc的executeBatch跟儲存過程的批次執行應該是採用的同樣的方法。
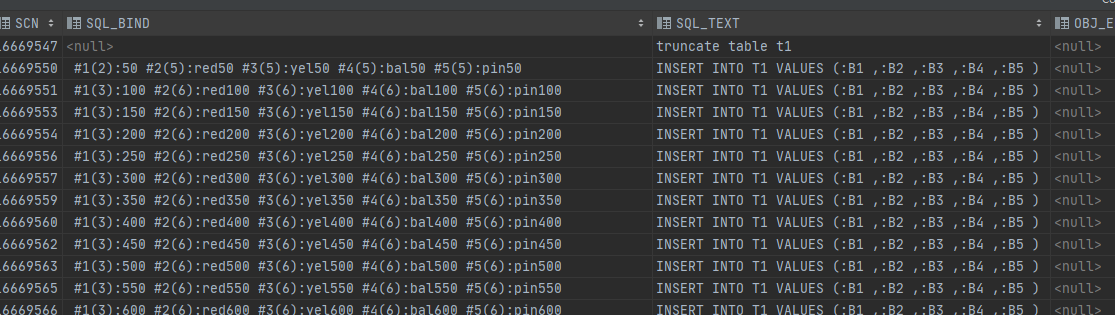
儲存過程的這個關鍵點就是forall。查閱相關檔案。
The FORALL statement runs one DML statement multiple times, with different values in the VALUES and WHERE clauses.
The different values come from existing, populated collections or host arrays. The FORALL statement is usually much faster than an equivalent FOR LOOP statement.
The FORALL syntax allows us to bind the contents of a collection to a single DML statement, allowing the DML to be run for each row in the collection without requiring a context switch each time.
翻譯過來就是forall很快,原因就是不需要每次執行的時候等待引數。
五、總結
- mysql的批次執行就是改寫sql。
- oracle的批次執行就是用的forall。
- 選擇一個合適批次值。
參考:
https://docs.oracle.com/en/database/oracle/oracle-database/19/lnpls/FORALL-statement.html
https://oracle-base.com/articles/9i/bulk-binds-and-record-processing-9i
https://www.akadia.com/services/ora_bulk_insert.html