解密Prompt系列3. 凍結LM微調Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
這一章我們介紹在下游任務微調中固定LM引數,只微調Prompt的相關模型。這類模型的優勢很直觀就是微調的引數量小,能大幅降低LLM的微調引數量,是輕量級的微調替代品。和前兩章微調LM和全部凍結的prompt模板相比,微調Prompt正規化最大的區別就是prompt模板都是連續型(Embedding),而非和Token對應的離散型模板。核心在於我們並不關心prompt本身是否是自然語言,只關心prompt作為探針能否引匯出預訓練模型在下游任務上的特定能力。
固定LM微調Prompt的正規化有以下幾個優點
- 價效比高!微調引數少,凍結LM只微調prompt部分的引數
- 無人工參與!無需人工設計prompt模板,依賴模型微調即可
- 多工共用模型!因為LM被凍結,只需訓練針對不同任務的prompt即可。因此可以固定預訓練模型,拔插式加入Prompt用於不同下游任務
Prefix-Tuning
- Paper: 2021.1 Optimizing Continuous Prompts for Generation
- Github:https://github.com/XiangLi1999/PrefixTuning
- Prompt: Continus Prefix Prompt
- Task & Model:BART(Summarization), GPT2(Table2Text)
最早提出Prompt微調的論文之一,其實是可控文字生成領域的延伸,因此只針對摘要和Table2Text這兩個生成任務進行了評估。
先嘮兩句可控文字生成,哈哈其實整個Prompt正規化也是通用的可控文字生成不是,只不過把傳統的Topic控制,文字情緒控制,Data2Text等,更進一步泛化到了不同NLP任務的生成控制~~
Prefix-Tuning可以理解是CTRL[1]模型的連續化升級版,為了生成不同領域和話題的文字,CTRL是在預訓練階段在輸入文字前加入了control code,例如好評前面加'Reviews Rating:5.0',差評前面加'Reviews Rating:1.0', 政治評論前面加‘Politics Title:’,把語言模型的生成概率,優化成了基於文字主題的條件概率。
Prefix-Tuning進一步把control code優化成了虛擬Token,每個NLP任務對應多個虛擬Token的Embedding(prefix),對於Decoder-Only的GPT,prefix只加在句首,對於Encoder-Decoder的BART,不同的prefix同時加在編碼器和解碼器的開頭。在下游微調時,LM的引數被凍結,只有prefix部分的引數進行更新。不過這裡的prefix引數不只包括embedding層而是虛擬token位置對應的每一層的activation都進行更新。

對於連續Prompt的設定,論文還討論了幾個細節如下
- prefix矩陣分解
作者發現直接更新多個虛擬token的引數效果很不穩定,因此作者在prefix層加了MLP,分解成了更小的embedding層 * 更大的MLP層。原始的Embedding層引數是n_prefix * emb_dim, 調整後變為n_prefix * n_hidden + n_hidden * emb_dim。訓練完成後這部分就不再需要只保留MLP輸出的引數進行推理即可
個人感覺MLP的加入是為了增加多個虛擬token之間的共用資訊,因為它們和常規的連續文字存在差異,需要被作為一個整體考慮,可能對prefix位置編碼進行特殊處理也闊以??
- prefix長度
prefix部分到底使用多少個虛擬token,直接影響模型微調的引數量級,以及處理長文字的能力。預設的prefix長度為10,作者在不同任務上進行了微調,最優引數如下。整體上prompt部分的引數量都在原模型的~0.1%
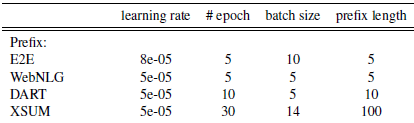
- 其他:作者還對比了把prefix放在不同位置,以及使用任務相關的Token來初始化prefix embedding的設定,前者侷限性較大,後者在後面的paper做了更詳細的消融實驗
效果上在Table2Text任務上,只有0.1%引數量級的prompt tuning效果要優於微調,
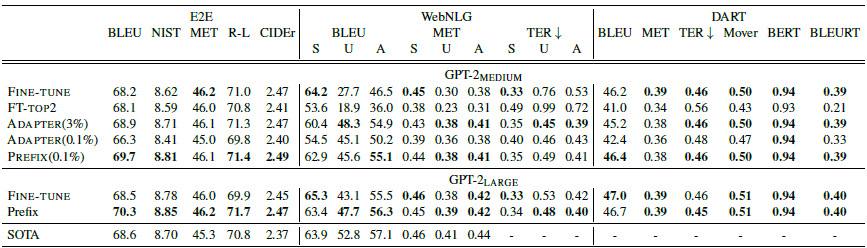
在Xsum摘要任務上,prompt的效果要略差於微調。

Prompt-Tunning
- Paper: 2021.4 The Power of Scale for Parameter-Efficient Prompt Tuning
- prompt:Continus Prefix Prompt
- Github: https://github.com/google-research/prompt-tuning
- Task: SuperGLUE NLU任務
- Model: T5 1.1(在原T5上進行了細節優化)
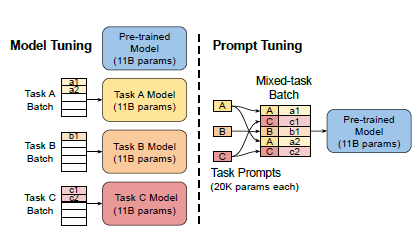
Prompt-Tunning是以上prefix-Tunning的簡化版本,面向NLU任務,進行了更全面的效果對比,並且在大模型上成功打平了LM微調的效果~
簡化
對比Prefix-Tunning,prompt-tuning的主要差異如下,
論文使用100個prefix token作為預設引數,大於以上prefix-tuning預設的10個token,不過差異在於prompt-Tunning只對輸入層(Embedding)進行微調,而Prefix是對虛擬Token對應的上游layer全部進行微調。因此Prompt-Tunning的微調引數量級要更小,且不需要修改原始模型結構,這是「簡化」的來源。相同的prefix長度,Prompt-Tunning(<0.01%)微調的引數量級要比Prefix-Tunning(0.1%~1%)小10倍以上,如下圖所示

為什麼上面prefix-tuning只微調embedding層效果就不好,放在prompt-tuning這裡效果就好了呢?因為評估的任務不同無法直接對比,個人感覺有兩個因素,一個是模型規模,另一個是繼續預訓練,前者的可能更大些,在下面的消融實驗中會提到
效果&消融實驗
在SuperGLUE任務上,隨著模型引數的上升,PromptTunning快速拉近和模型微調的效果,110億的T5模型(上面prefix-tuning使用的是15億的GPT2),已經可以打平在下游多工聯合微調的LM模型,並且遠遠的甩開了Prompt Design(GPT3 few-shot)

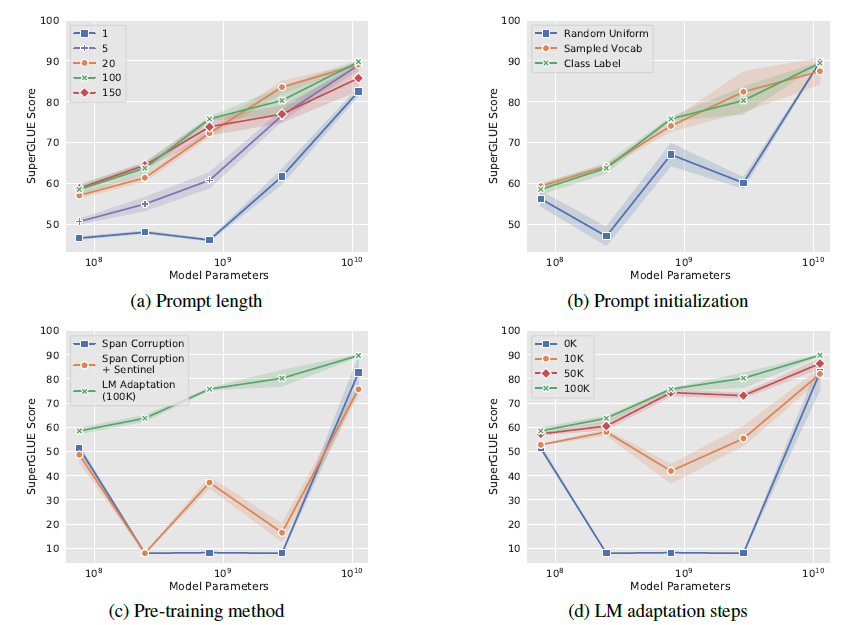
作者也做了全面的消融實驗,包括以下4個方面,最核心的感受就是只要模型足夠夠大一切都好說
- prompt長度(a):固定其他引數,作者嘗試了{1,5,20,100,150}, 當模型規模到百億後,只要prompt長度大於1,更長的prompt並不能帶來效果提升
- Prompt初始化(b): 作者嘗試了隨機uniform初始化,用標籤文字空間初始化,和用Top5K高頻詞取樣初始化,在10^8規模,標籤詞初始化效果最好。作者發現預測label也會在對應prompt空間內。不過到百億規模後,初始化帶來的影響就會消失
- T5繼續預訓練(c):作者認為T5本身的Span Corruption預訓練目標和掩碼詞,並不適合凍結LM的場景,因為在微調中模型可以調整預訓練目標和下游目標的差異,而只使用prompt可能無法彌合差異。其實這裡已經能看出En-Dn框架在生成場景下沒有GPT這樣的Decoder來的自然。因此作者基於LM目標對T5進行繼續預訓練
- 繼續預訓練step(d):以上的繼續預訓練steps,繼續預訓練步數越高,模型效果在不同模型規模上越單調。
可解釋
考慮Prompt-Tunning使用Embedding來表徵指令,可解釋性較差。作者使用cosine距離來搜尋prompt embedding對應的Top5近鄰。發現
- embedding的近鄰出現語意相似的cluster,例如{ Technology / technology / Technologies/ technological / technologies }, 說明連續prompt實際可能是相關離散prompt詞的聚合語意
- 當連續prompt較長(len=100), 存在多個prompt token的KNN相同:個人認為這和prefix-tuning使用MLP那裡我的猜測相似,prompt應該是一個整體
- 使用標籤詞初始化,微調後標籤詞也大概率會出現在prompt的KNN中,說明初始化可以提供更好的prior資訊加速收斂
P-Tuning
- Paper: 2021.3, GPT Understands, Too
- prompt:Continus Prefix Prompt
- Task: NLU任務, 知識探測任務
- github: https://github.com/THUDM/P-tuning
- Model: GPT2 & BERT
P-Tuning和Prompt-Tuning幾乎是同時出現,思路也是無比相似。不過這個在prompt綜述中被歸類為LM+Prompt同時微調的正規化,不過作者其實兩種都用了。因此還是選擇把p-tuning也放到這一章,畢竟個人認為LM+Prompt的微調正規化屬實有一點不是太必要。。。
論文同樣是連續prompt的設計。不過針對上面提到的Prompt的整體性問題進行了優化。作者認為直接通過虛擬token引入prompt存在兩個問題
- 離散性:如果用預訓練詞表的embedding初始化,經過預訓練的詞在空間分佈上較稀疏,微調的幅度有限,容易陷入區域性最優。這裡到底是區域性最優還是有效資訊prior其實很難分清
- 整體性:多個token的連續prompt應該相互依賴作為一個整體,不謀而合了!
針對這兩個問題,作者使用雙向LSTM+2層MLP來對prompt進行表徵, 這樣LSTM的結構提高prompt的整體性,Relu啟用函數的MLP提高離散型。這樣更新prompt就是對應更新整個lstm+MLP部分的Prompt Encoder。下面是p-tuning和離散prompt的對比
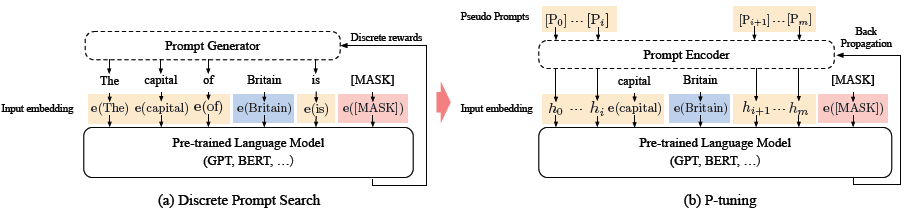
作者分別對LAMA知識探測和SuperGLUE文字理解進行了評測。針對知識抽取,作者構建的prompt模板如下,以下3是虛擬prompt詞的數量,對應prompt encoder輸出的embedding數
- BERT:(3, sub,3,obj,3)
- GPT(3,sub,3,obj)
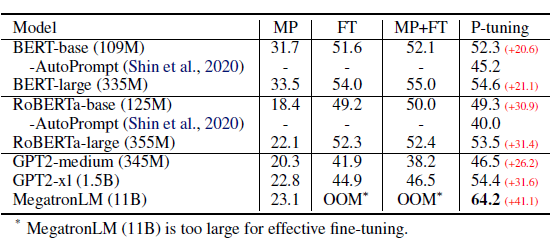
在知識探測任務中,預設是固定LM只微調prompt。效果上P-tuning對GPT這類單項語言模型的效果提升顯著,顯著優於人工構建模板和直接微調,使得GPT在不擅長的知識抽取任務中可以基本打平BERT的效果。
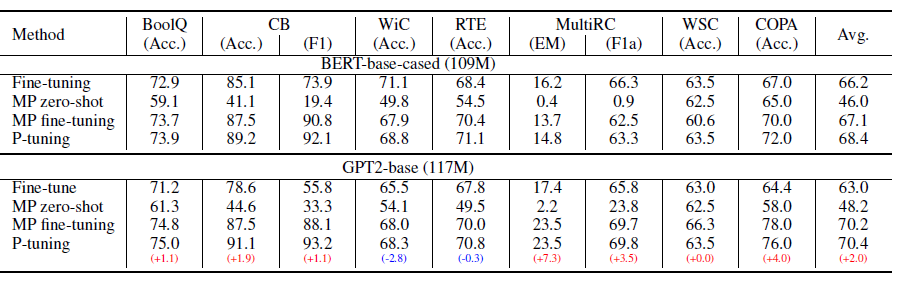
針對SuperGLUE作者是做了LM+Prompt同時微調的設定。個人對LM+prompt微調的邏輯不是認同,畢竟1+1<2,同時微調它既破壞了預訓練的語言知識,也沒節省微調的引數量級,感覺邏輯上不是非常講的通(哈哈坐等之後被打臉)。結論基本和以上知識探測相似
開頭說優點,結尾說下侷限性
- 可解釋性差:這是所有連續型prompt的統一問題
- 收斂更慢: 更少的引數想要撬動更大的模型,需要更復雜的空間搜尋
- 可能存在過擬合:只微調prompt,理論上是作為探針,但實際模型是否真的使用prompt部分作為探針,而不是直接去擬合任務導致過擬合是個待確認的問題
- 微調可能存在不穩定性:prompt-tuning和p-tuning的github裡都有提到結果在SuperGLUE上無法復現的問題
更多Prompt相關論文,AIGC相關玩法戳這裡DecryptPrompt
Reference
- CTRL: A CONDITIONAL TRANSFORMER LANGUAGE MODEL FOR CONTROLLABLE GENERATION。可以當做prefix-tuning的前導文來看
- WRAP: Word-level Adversarial ReProgramming。介於Prefix-Tunning和Prompt-Tunning之間,這裡就不細說了
- 蘇神https://kexue.fm/archives/8295