生產環境Java應用服務記憶體漏失分析與解決
有個生產環境CRM業務應用服務,情況有些奇怪,監控資料顯示記憶體異常。記憶體使用率99.%多。通過生產監控看板發現,CRM記憶體超配或記憶體漏失的現象,下面分析一下這個問題過程記錄。
伺服器設定情況:
生產伺服器採用阿里雲ECS機器,設定是4HZ、8GB,單個應用服務獨佔,CRM應用獨立部署,即單臺伺服器僅部署一個java應用服務。
用了4個節點4臺機器,每臺機器都差不多情況。
監控看板如下:


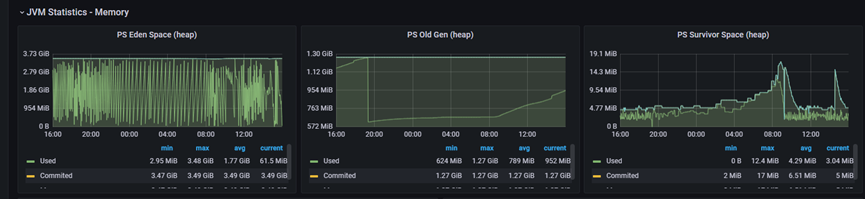

記憶體分佈統計:
從監控看板的資料來看,我們簡單統計一下記憶體分配資料情況。
應用啟動設定引數:
/usr/bin/java
-javaagent:/home/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=xx-crm
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/xx-crm.hprof
-Dspring.profiles.active=prod
-server -Xms4884m -Xmx4884m -Xmn3584m
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=128m
-jar /home/xxs-crm.jar
堆記憶體 4.8G左右,其中新生代3.5G左右,
非堆記憶體:(Metaspace)512M+(CompressedClassSpace)128M+(Code Cache)240M約等1G左右.
堆記憶體(heap)+非堆記憶體(non-Heap)=5.8G,8GB實體記憶體除去作業系統本身佔用大概500M,起碼至少還有1~2GB空閒才合理呀!怎麼竟然佔了99%多,就意味著有1~2G不知道誰佔去了,有點詭異!
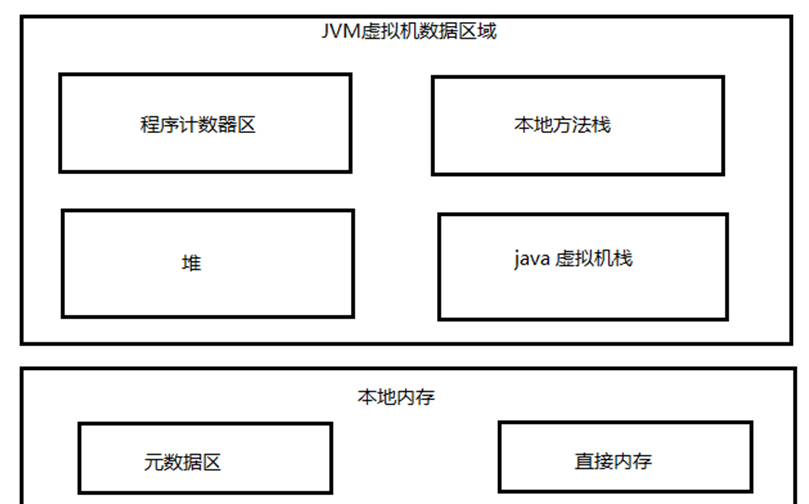
先看一下JVM記憶體模型,環境是使用JDK8
JVM記憶體資料分割區:
堆heap結構:
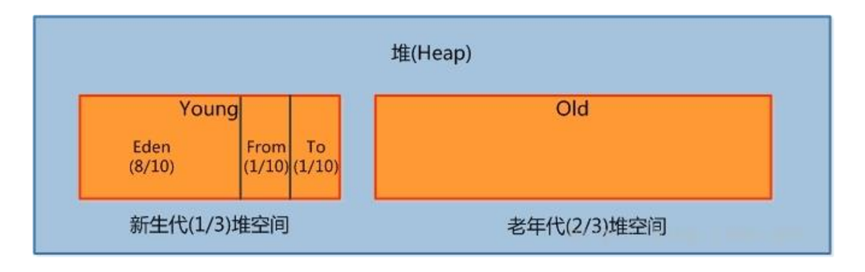
堆大家都比較容易理解的,也是java程式接觸得最多的一塊,不存在什麼資料上統計錯誤,或佔用不算之類的。
那說明額外佔用也非堆裡面,只不過沒有統計到非堆裡面去,曾經一度懷疑監控prometheus展示的資料有誤。
先看一下dump檔案資料,這裡使用MAT工具(一個開源免費的記憶體分析工具,個人認為比較好用,推薦大家使用)。
通過下載記憶體dump映象觀察到
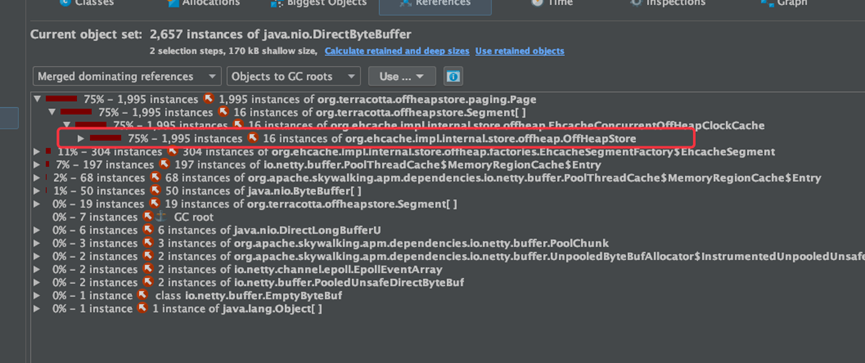
有個offHeapStore,這個東西堆外記憶體,可以初步判斷是 ehcahe引起的。
通過ehcahe原始碼分析,發現ehcache裡面也使用了netty的NIO方法記憶體,ehcache磁碟快取寫資料時會用到DirectByteBuffer。
DirectByteBuffer是使用非堆記憶體,不受GC影響。
當有檔案需要暫存到ehcache的磁碟快取時,使用到了NIO中的FileChannel來讀取檔案,預設ehcache使用了堆內的HeapByteBuffer來給FileChannel作為讀取檔案的緩衝,FileChannel讀取檔案使用的IOUtil的read方法,針對HeapByteBuffer底層還用到一個臨時的DirectByteBuffer來和作業系統進行直接的互動。
ehcache使用HeapByteBuffer作為讀檔案緩衝:

IOUtil對於HeapByteBuffer實際會用到一個臨時的DirectByteBuffer來和作業系統進行互動。

DirectByteBuffer洩漏根因分析
預設情況下這個臨時的DirectByteBuffer會被快取在一個ThreadLocal的bufferCache裡不會釋放,每一個bufferCache有一個DirectByteBuffer的陣列,每次當前執行緒需要使用到臨時DirectByteBuffer時會取出自己bufferCache裡的DirectByteBuffer資料,選取一個不小於所需size的,如果bufferCache為空或者沒有符合的,就會呼叫Bits重新建立一個,使用完之後再快取到bufferCache裡。
這裡的問題在於 :這個bufferCache是ThreadLocal的,意味著極端情況下有N個呼叫執行緒就會有N組 bufferCache,就會有N組DirectByteBuffer被快取起來不被釋放,而且不同於在IO時直接使用DirectByteBuffer,這N組DirectByteBuffer連GC時都不會回收。我們的檔案服務在讀寫ehcache的磁碟快取時直接使用的tomcat的worker執行緒池,
這個worker執行緒池的設定上限是2000,我們的設定中心上的設定的引數:

所以,這種隱藏的問題影響所有使用到HeapByteBuffer的地方而且很隱祕,由於在CRM服務中大量使用了ehcache存在較大的sizeIO且呼叫執行緒比較多的場景下容易暴露出來。
獲取臨時DirectByteBuffer的邏輯:

bufferCache從ByteBuffer陣列裡選取合適的ByteBuffer:

將ByteBuffer回種到bufferCache:

NIO中的FileChannel、SocketChannel等Channel預設在通過IOUtil進行IO讀寫操作時,除了會使用HeapByteBuffer作為和應用程式的對接緩衝,但在底層還會使用一個臨時的DirectByteBuffer來和系統進行真正的IO互動,為提高效能,當使用完後這個臨時的DirectByteBuffer會被存放到ThreadLocal的快取中不會釋放,當直接使用HeapByteBuffer的執行緒數較多或者IO操作的size較大時,會導致這些臨時的DirectByteBuffer佔用大量堆外直接記憶體造成洩漏。
那麼除了減少直接呼叫ehcache讀寫的執行緒數有沒有其他辦法能解決這個問題?並行比較高的場景下意味著減少業務執行緒數並不是一個好辦法。
在Java1.8_102版本開始,官方提供一個引數jdk.nio.maxCachedBufferSize,這個引數用於限制可以被快取的DirectByteBuffer的大小,對於超過這個限制的DirectByteBuffer不會被快取到ThreadLocal的bufferCache中,這樣就能被GC正常回收掉。唯一的缺點是讀寫的效能會稍差一些,畢竟建立一個新的DirectByteBuffer的代價也不小,當然通過測試驗證對比分析,效能也沒有數量級的差別。
增加引數:
-XX:MaxDirectMemorySize=1600m
-Djdk.nio.maxCachedBufferSize=500000 ---注意不能帶單位
就是調整了-Djdk.nio.maxCachedBufferSize=500000(注意這裡是位元組數,不能用m、k、g等單位)。
增加調整引數之後,執行一段時間,持續觀察整體DirectByteBuffer穩定控制在1.5G左右,效能也幾乎沒有衰減。一切恢復正常,再看監控看板沒有看到佔滿記憶體告警。
業務系統調整後的啟動命令引數如下:
java
-javaagent:/home/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=xx-crm
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/xx-crm.hprof
-Dspring.profiles.active=prod
-server -Xms4608m -Xmx4608m -Xmn3072m
-XX:MetaspaceSize=300m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=64m
-XX:MaxDirectMemorySize=1600m
-Djdk.nio.maxCachedBufferSize=500000
-jar /home/xx-crm.jar
參考文章《Troubleshooting Problems With Native (Off-Heap) Memory in Java Applications》