專案中多級快取設計實踐總結
快取的重要性
簡而言之,快取的原理就是利用空間來換取時間。通過將資料存到存取速度更快的空間裡以便下一次存取時直接從空間裡獲取,從而節省時間。
我們以CPU的快取體系為例:
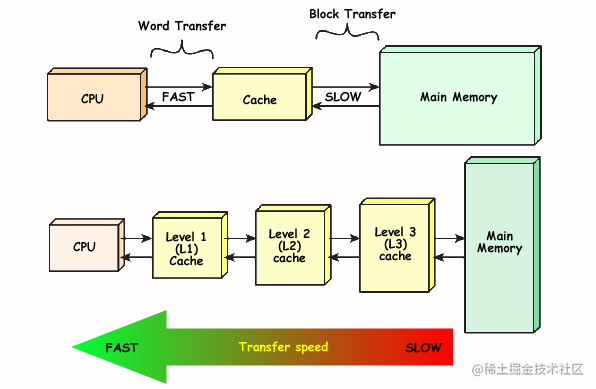
CPU快取體系是多層級的。分成了CPU -> L1 -> L2 -> L3 -> 主記憶體。我們可以得到以下啟示。
- 越頻繁使用的資料,使用的快取速度越快
- 越快的快取,它的空間越小
而我們專案的快取設計可以借鑑CPU多級快取的設計。
關於多級快取體系實現在開源專案中:https://github.com/valarchie/AgileBoot-Back-End
快取分層
首先我們可以給快取進行分層。在Java中主流使用的三類快取主要有:
- Map(原生快取)
- Guava/Caffeine(功能更強大的記憶體快取)
- Redis/Memcached(快取中介軟體)
在一些專案中,會一刀切將所有的快取都使用Redis或者Memcached中介軟體進行存取。
使用快取中介軟體避免不了網路請求成本和使用者態和核心態的切換。 更合理的方式應該是根據資料的特點來決定使用哪個層級的快取。
Map(一級快取)
專案中的字典型別的資料比如:性別、型別、狀態等一些不變的資料。我們完全可以存在Map當中。
因為Map的實現非常簡單,效率上是非常高的。由於我們存的資料都是一些不變的資料,一次性存好並不會再去修改它們。所以不用擔心記憶體溢位的問題。 以下是關於字典資料使用Map快取的簡單程式碼實現。
/**
* 本地一級快取 使用Map
*
* @author valarchie
*/
public class MapCache {
private static final Map<String, List<DictionaryData>> DICTIONARY_CACHE = MapUtil.newHashMap(128);
static {
initDictionaryCache();
}
private static void initDictionaryCache() {
loadInCache(BusinessTypeEnum.values());
loadInCache(YesOrNoEnum.values());
loadInCache(StatusEnum.values());
loadInCache(GenderEnum.values());
loadInCache(NoticeStatusEnum.values());
loadInCache(NoticeTypeEnum.values());
loadInCache(OperationStatusEnum.values());
loadInCache(VisibleStatusEnum.values());
}
public static Map<String, List<DictionaryData>> dictionaryCache() {
return DICTIONARY_CACHE;
}
private static void loadInCache(DictionaryEnum[] dictionaryEnums) {
DICTIONARY_CACHE.put(getDictionaryName(dictionaryEnums[0].getClass()), arrayToList(dictionaryEnums));
}
private static String getDictionaryName(Class<?> clazz) {
Objects.requireNonNull(clazz);
Dictionary annotation = clazz.getAnnotation(Dictionary.class);
Objects.requireNonNull(annotation);
return annotation.name();
}
@SuppressWarnings("rawtypes")
private static List<DictionaryData> arrayToList(DictionaryEnum[] dictionaryEnums) {
if(ArrayUtil.isEmpty(dictionaryEnums)) {
return ListUtil.empty();
}
return Arrays.stream(dictionaryEnums).map(DictionaryData::new).collect(Collectors.toList());
}
}
Guava(二級快取)
專案中的一些自定義資料比如角色,部門。這種型別的資料往往不會非常多。而且請求非常頻繁。比如介面中經常要校驗角色相關的許可權。我們可以使用Guava或者Caffeine這種記憶體框架作為二級快取使用。
Guava或者Caffeine的好處可以支援快取的過期時間以及快取的淘汰,避免記憶體溢位。
以下是利用模板設計模式做的GuavaCache模板類。
/**
* 快取介面實現類 二級快取
* @author valarchie
*/
@Slf4j
public abstract class AbstractGuavaCacheTemplate<T> {
private final LoadingCache<String, Optional<T>> guavaCache = CacheBuilder.newBuilder()
// 基於容量回收。快取的最大數量。超過就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU佇列recencyQueue來進行容量淘汰
.maximumSize(1024)
// 基於容量回收。但這是統計佔用記憶體大小,maximumWeight與maximumSize不能同時使用。設定最大總權重
// 沒寫存取下,超過5秒會失效(非自動失效,需有任意put get方法才會掃描過期失效資料。但區別是會開一個非同步執行緒進行重新整理,重新整理過程中存取返回舊資料)
.refreshAfterWrite(5L, TimeUnit.MINUTES)
// 移除監聽事件
.removalListener(removal -> {
// 可做一些刪除後動作,比如上報刪除資料用於統計
log.info("觸發刪除動作,刪除的key={}, value={}", removal.getKey(), removal.getValue());
})
// 並行等級。決定segment數量的引數,concurrencyLevel與maxWeight共同決定
.concurrencyLevel(16)
// 開啟快取統計。比如命中次數、未命中次數等
.recordStats()
// 所有segment的初始總容量大小
.initialCapacity(128)
// 用於測試,可任意改變當前時間。參考:https://www.geek-share.com/detail/2689756248.html
.ticker(new Ticker() {
@Override
public long read() {
return 0;
}
})
.build(new CacheLoader<String, Optional<T>>() {
@Override
public Optional<T> load(String key) {
T cacheObject = getObjectFromDb(key);
log.debug("find the local guava cache of key: {} is {}", key, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
public T get(String key) {
try {
if (StrUtil.isEmpty(key)) {
return null;
}
Optional<T> optional = guavaCache.get(key);
return optional.orElse(null);
} catch (ExecutionException e) {
log.error("get cache object from guava cache failed.");
e.printStackTrace();
return null;
}
}
public void invalidate(String key) {
if (StrUtil.isEmpty(key)) {
return;
}
guavaCache.invalidate(key);
}
public void invalidateAll() {
guavaCache.invalidateAll();
}
/**
* 從資料庫載入資料
* @param id
* @return
*/
public abstract T getObjectFromDb(Object id);
}
我們將getObjectFromDb方法留給子類自己去實現。以下是例子:
/**
* @author valarchie
*/
@Component
@Slf4j
@RequiredArgsConstructor
public class GuavaCacheService {
@NonNull
private ISysDeptService deptService;
public final AbstractGuavaCacheTemplate<SysDeptEntity> deptCache = new AbstractGuavaCacheTemplate<SysDeptEntity>() {
@Override
public SysDeptEntity getObjectFromDb(Object id) {
return deptService.getById(id.toString());
}
};
}
Redis(三級快取)
專案中會持續增長的資料比如使用者、訂單等相關資料。這些資料比較多,不適合放在記憶體級快取當中,而應放在快取中介軟體Redis當中去。Redis是支援持久化的,當我們的伺服器重新啟動時,依然可以從Redis中載入我們原先儲存好的資料。
但是使用Redis快取還有一個可以優化的點。我們可以自己本地再做一個區域性的快取來快取Redis中的資料來減少網路IO請求,提高資料存取速度。 比如我們Redis快取中有一萬個使用者的資料,但是一分鐘之內可能只有不到1000個使用者在請求資料。我們便可以在Redis中嵌入一個區域性的Guava快取來提供效能。以下是RedisCacheTemplate.
/**
* 快取介面實現類 三級快取
* @author valarchie
*/
@Slf4j
public class RedisCacheTemplate<T> {
private final RedisUtil redisUtil;
private final CacheKeyEnum redisRedisEnum;
private final LoadingCache<String, Optional<T>> guavaCache;
public RedisCacheTemplate(RedisUtil redisUtil, CacheKeyEnum redisRedisEnum) {
this.redisUtil = redisUtil;
this.redisRedisEnum = redisRedisEnum;
this.guavaCache = CacheBuilder.newBuilder()
// 基於容量回收。快取的最大數量。超過就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU佇列recencyQueue來進行容量淘汰
.maximumSize(1024)
.softValues()
// 沒寫存取下,超過5秒會失效(非自動失效,需有任意put get方法才會掃描過期失效資料。
// 但區別是會開一個非同步執行緒進行重新整理,重新整理過程中存取返回舊資料)
.expireAfterWrite(redisRedisEnum.expiration(), TimeUnit.MINUTES)
// 並行等級。決定segment數量的引數,concurrencyLevel與maxWeight共同決定
.concurrencyLevel(64)
// 所有segment的初始總容量大小
.initialCapacity(128)
.build(new CacheLoader<String, Optional<T>>() {
@Override
public Optional<T> load(String cachedKey) {
T cacheObject = redisUtil.getCacheObject(cachedKey);
log.debug("find the redis cache of key: {} is {}", cachedKey, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
}
/**
* 從快取中獲取物件 如果獲取不到的話 從DB層面獲取
* @param id
* @return
*/
public T getObjectById(Object id) {
String cachedKey = generateKey(id);
try {
Optional<T> optional = guavaCache.get(cachedKey);
// log.debug("find the guava cache of key: {}", cachedKey);
if (!optional.isPresent()) {
T objectFromDb = getObjectFromDb(id);
set(id, objectFromDb);
return objectFromDb;
}
return optional.get();
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 從快取中獲取 物件, 即使找不到的話 也不從DB中找
* @param id
* @return
*/
public T getObjectOnlyInCacheById(Object id) {
String cachedKey = generateKey(id);
try {
Optional<T> optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 從快取中獲取 物件, 即使找不到的話 也不從DB中找
* @param cachedKey 直接通過redis的key來搜尋
* @return
*/
public T getObjectOnlyInCacheByKey(String cachedKey) {
try {
Optional<T> optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
public void set(Object id, T obj) {
redisUtil.setCacheObject(generateKey(id), obj, redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public void delete(Object id) {
redisUtil.deleteObject(generateKey(id));
guavaCache.refresh(generateKey(id));
}
public void refresh(Object id) {
redisUtil.expire(generateKey(id), redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public String generateKey(Object id) {
return redisRedisEnum.key() + id;
}
public T getObjectFromDb(Object id) {
return null;
}
}
以下是使用方式:
/**
* @author valarchie
*/
@Component
@RequiredArgsConstructor
public class RedisCacheService {
@NonNull
private RedisUtil redisUtil;
public RedisCacheTemplate<SysUserEntity> userCache;
@PostConstruct
public void init() {
userCache = new RedisCacheTemplate<SysUserEntity>(redisUtil, CacheKeyEnum.USER_ENTITY_KEY) {
@Override
public SysUserEntity getObjectFromDb(Object id) {
ISysUserService userService = SpringUtil.getBean(ISysUserService.class);
return userService.getById((Serializable) id);
}
};
}
}
快取Key以及過期時間
我們可以通過一個列舉類來統一集中管理各個快取的Key以及過期時間。以下是例子:
/**
* @author valarchie
*/
public enum CacheKeyEnum {
/**
* Redis各類快取集合
*/
CAPTCHAT("captcha_codes:", 2, TimeUnit.MINUTES),
LOGIN_USER_KEY("login_tokens:", 30, TimeUnit.MINUTES),
RATE_LIMIT_KEY("rate_limit:", 60, TimeUnit.SECONDS),
USER_ENTITY_KEY("user_entity:", 60, TimeUnit.MINUTES),
ROLE_ENTITY_KEY("role_entity:", 60, TimeUnit.MINUTES),
ROLE_MODEL_INFO_KEY("role_model_info:", 60, TimeUnit.MINUTES),
;
CacheKeyEnum(String key, int expiration, TimeUnit timeUnit) {
this.key = key;
this.expiration = expiration;
this.timeUnit = timeUnit;
}
private final String key;
private final int expiration;
private final TimeUnit timeUnit;
public String key() {
return key;
}
public int expiration() {
return expiration;
}
public TimeUnit timeUnit() {
return timeUnit;
}
}
統一的使用門面
一般來說,我們在專案中設計好快取之後就可以讓其他同事寫業務時直接呼叫了。但是讓開發者去判斷這個屬於二級快取還是三級快取的話,存在心智負擔。我們應該讓開發者自然地從業務角度去選擇某個快取。比如他正在寫部門相關的業務邏輯,就直接使用deptCache。
此時我們可以新建一個CacheCenter來統一按業務劃分快取。以下是例子:
/**
* 快取中心 提供全域性存取點
* @author valarchie
*/
@Component
public class CacheCenter {
public static AbstractGuavaCacheTemplate<String> configCache;
public static AbstractGuavaCacheTemplate<SysDeptEntity> deptCache;
public static RedisCacheTemplate<String> captchaCache;
public static RedisCacheTemplate<LoginUser> loginUserCache;
public static RedisCacheTemplate<SysUserEntity> userCache;
public static RedisCacheTemplate<SysRoleEntity> roleCache;
public static RedisCacheTemplate<RoleInfo> roleModelInfoCache;
@PostConstruct
public void init() {
GuavaCacheService guavaCache = SpringUtil.getBean(GuavaCacheService.class);
RedisCacheService redisCache = SpringUtil.getBean(RedisCacheService.class);
configCache = guavaCache.configCache;
deptCache = guavaCache.deptCache;
captchaCache = redisCache.captchaCache;
loginUserCache = redisCache.loginUserCache;
userCache = redisCache.userCache;
roleCache = redisCache.roleCache;
roleModelInfoCache = redisCache.roleModelInfoCache;
}
}
以上就是關於專案中多級快取的實現。 如有不足懇請評論指出。