明解資料庫------資料庫儲存演變史
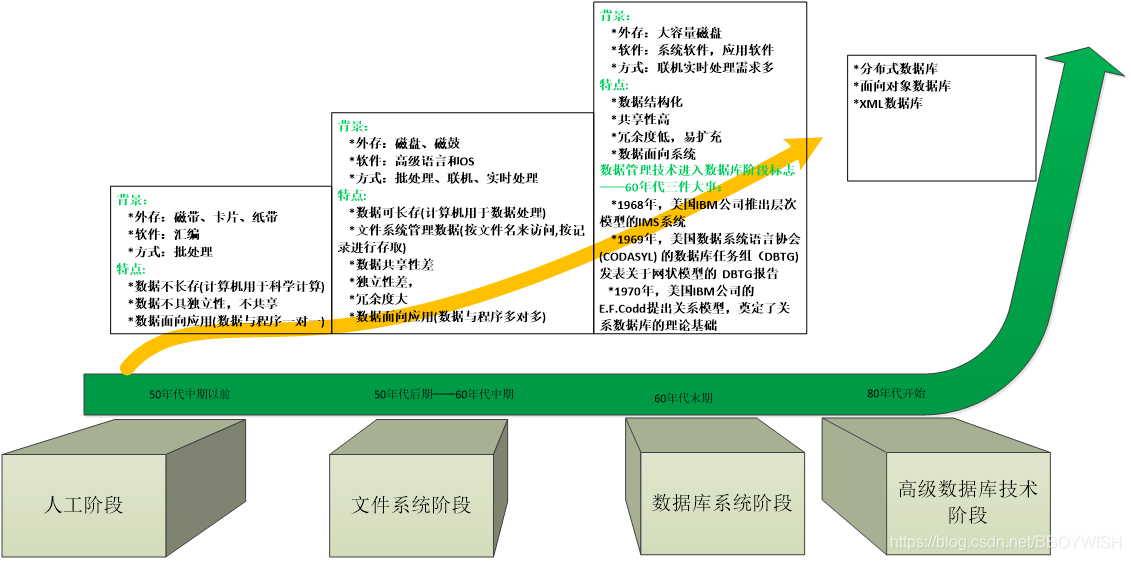
一、檔案系統儲存
計算機剛開始出現的時候,那時候沒有硬碟,只有記憶體,資料不會進行儲存,一般只用於科技計算,計算完輸出結果後,程式就撤出記憶體了。後來隨著技術發展,有了硬碟、檔案,在檔案的基礎上有了檔案系統。檔案系統可以滿足資料存放和查詢的需求。
檔案系統作為資料庫用了一段時間,當資料越來越多、規模越來越大後,資料查詢特別麻煩。資料很容易重複(冗餘)、佔用儲存空間多,資料結構化被迫推進。
- 資料庫在狹義層面上來說:指的是處理資料的底層程式
- 資料庫在廣義層面上來說:指的是操作這些底層程式的便捷應用軟體
總的來說,資料庫顧名思義其實就是存取資料的地方;另外隨著時間線的發展產生了不同種類的資料庫,但本質技術提升的本質都是為了提升業務效能!

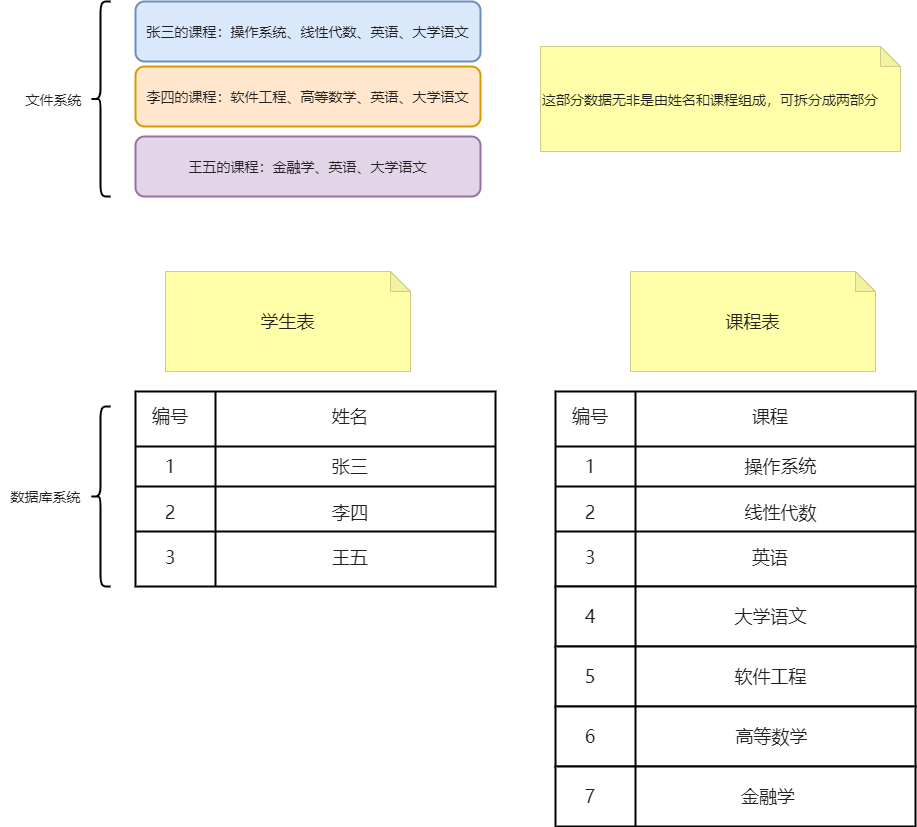
二、關係型資料庫儲存
關係型資料庫也被稱為RDBMS,顧名思義就是資訊遵循一種利用表或關係的結構化方法,是一種儲存和操作歷史資料的經典方法。
SQL這個詞既是一種語言,也是資料庫的型別。SQL代表結構化查詢語言,是資料庫設計理念的先驅。自80年代中期以來,SQL一直是管理和查詢關係資料集的標準;然而,關係模型的早期雛形可以追溯到60年代和70年代,當時出現了區分應用資料和應用程式碼的迫切需求,使開發人員能夠專注於程式開發的其他方面,如存取和操作手頭的資料。IBM的IMS是第一個功能齊全的關係型資料庫,儘管設計的目的不同,是為了組織阿波羅太空探索計劃的資料。關聯式資料庫是各種程度的時間變化的、規範化的關係的集合。可以做出以下直觀的對應。
-
關聯式資料庫管理系統 (RDBMS) 支援關係(面向二維表)資料模型,表(table)
- RDBMS 中的資料儲存在稱為表的資料庫物件中
-
表的架構(關係架構)由表名和具有固定資料型別的固定數量的屬性/欄位定義,列(column)
- 需要預先定義架構,即需要提前知道所有列及其相關聯的資料型別,以便於應用將資料寫入資料庫
- 一個關係就是一個檔案,每個檔案只包含一種記錄型別
-
記錄(實體)對應於表中的一行,由每個屬性的值組成,行(row)
-
表架構是通過資料建模過程中的規範化生成的
-
可以儲存通過鍵連結多個表的資訊,從而建立跨多個表的關係
-
在簡單的用例中,鍵用於檢索特定行以便於進行檢查或修改
-
結構化查詢語言,允許使用者存取和操作高度結構化表中的資料
-
記錄沒有特定的順序
-
每個欄位都是單值的
-
記錄有一個唯一的識別欄位或複合欄位,稱為主鍵欄位
特性:ACID
原子性、一致性、隔離性、永續性以保持交易的可靠性。
- 原子性:整體完成交易或完全不完成交易
- 一致性:保證資料庫的穩定狀態,無論有無變化
- 隔離性:多個事務不會相互干擾
- 永續性:變化對資料庫的永久影響
正規化設計
一個設計高效資料庫的過程
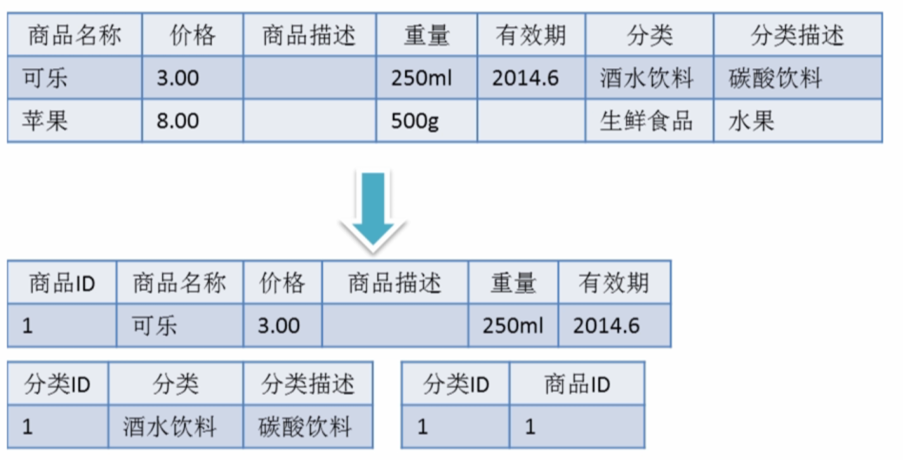
- 1NF:通過分離重複和不重複的屬性來分割表。所有的域都是簡單的,所有的元素都是原子性的。
- 2NF:移除屬性之間的部分依賴關係。任何屬性都不應該在功能上依賴於聚合主鍵的一個部分。
- 3NF:移除表屬性之間的傳遞性依賴。沒有首要屬性在功能上依賴於非首要屬性。
可延伸性
資料庫處理不斷增長的資料量的能力。垂直擴充套件有助於增強資料庫伺服器的現有能力。大多數SQL資料庫支援垂直擴充套件。然而,他們可以擴大規模,而不是縮小規模。
從使用角度來說使用者不直接接觸資料庫,而是通過我們的應用程式與資料庫進行互動。
如果使用者比較多,發出的請求多了之後,由於我們的資料庫是放置在磁碟,而磁碟的效能是比較低的,所以會導致Web應用程式每次到與資料庫進行互動之後,使用者的響應速度會變慢!

解決方案:池化技術,實現資源的複用(降低資源建立銷燬的開銷)

以上是Web應用與資料庫連線層面的優化,至於在資料庫本身我們也可以進行優化,以提升效能。
- 升級伺服器硬體
- 資料庫索引
- SQL執行計劃
- 慢查詢
- 減少互動次數
- 減少應用到資料庫傳輸的資料量
- 資料庫進行分庫分表、讀寫分離
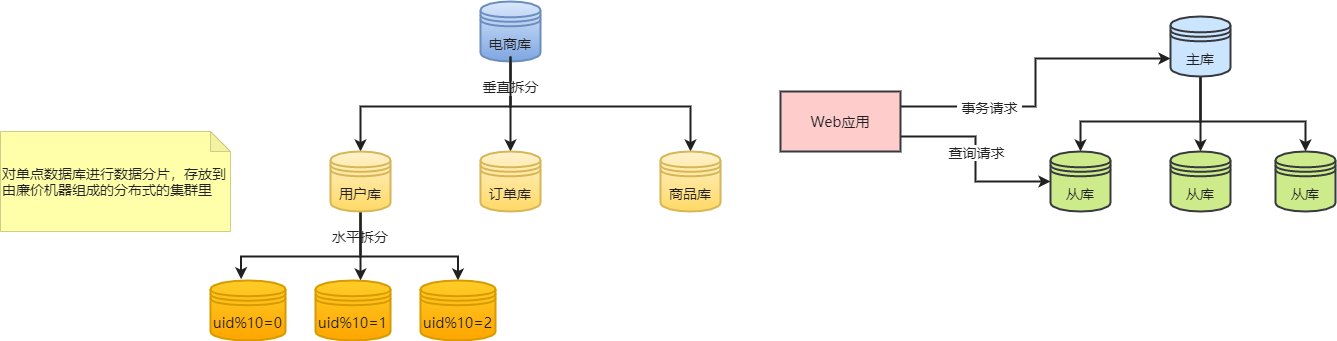
資料分片,使用分散式叢集結構等雖然提高了可延伸性更好了,但也帶來了新的麻煩
1、以前在一個庫裡的資料,現在跨了多個庫,應用系統不能自己去多個庫中操作,需要使用資料庫分片中介軟體
2、分片中介軟體做簡單的資料操作時還好,但涉及到跨庫join、跨庫事務時就很頭疼了,很多人乾脆自己在業務層處理,複雜度較高
關係型資料庫劣勢
資料建模的僵化
關係型資料庫最大的限制之一是將資料組織到表和關係的特定結構中的僵硬性。由於所有的資料都不能方便地裝入表格,因此這種方法不能應用於所有的自然資料,也不能以樹和圖的形式儲存,但是,RDBMS通過以父子關係的規範化方式對這些資料進行建模來解決這個限制,這仍然是不夠的。
多樣性
資料的複雜性也給關係型資料庫帶來了限制。這些資料庫是按共同特徵來組織資料的。複雜的數位、影象和多媒體資料很難儲存、存取和處理。
空間使用效率低下
當我們定義關係的模式時,我們定義所有屬性的大小。不是所有的記錄都有使用全部空間的資料。一些有很短的長度。每條記錄不一定又適合給定的資料型別,造成了空間浪費。
沉重的變化
一個記錄所需的任何改變都需要應用於所有的記錄。因此造成了重量級的改變。根據當時存在的記錄的大小和數量,這些改變可能是昂貴的,不可行的。因此,改變一個已經存在的資料庫的模式是一個挑戰。
對巨量資料來說效率低下
SQL不適合數量大、速度快、種類多的資料,使得它在基於雲的應用中效率很低。
總結:隨著巨量資料時代的到來,結構化的方法已經無法滿足巨大的資訊處理需求,這些資訊往往是非結構化的。隨著時間的推移,SQL已經經歷了許多迭代,以支援大量的資料處理和管道。然而,對於期望快速響應和最高可延伸性的巨量資料系統來說,它仍然是低效的。
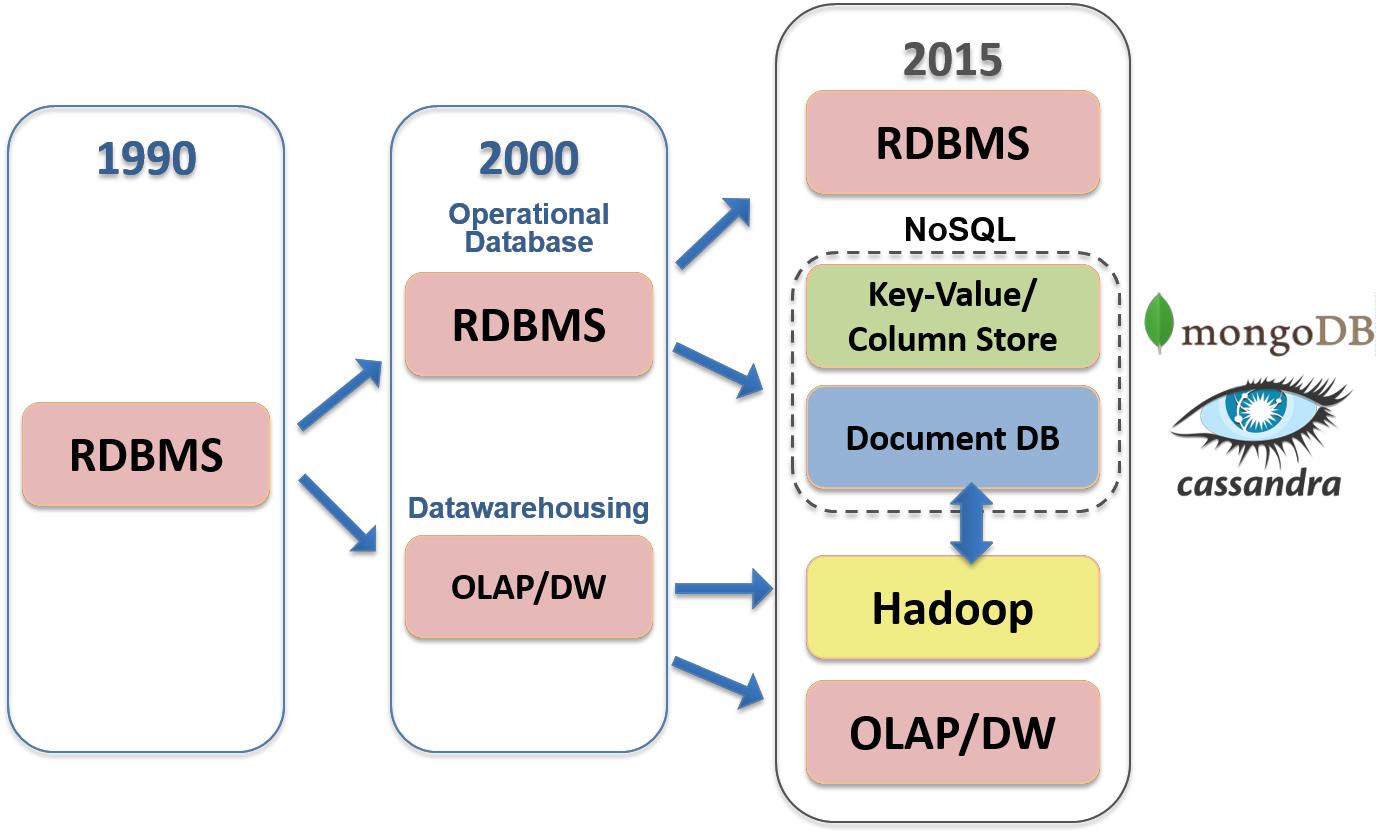
三、非關係型資料庫儲存
關聯式資料庫近期還是非常廣泛使用的模型,它們仍然在許多企業得到了廣泛採用。然而,面對當今多樣化、高速和海量的資料,有時需要用一個高度不同的資料庫來補充關聯式資料庫。這促進了 NoSQL 資料庫在某些領域的採用,該資料庫也稱為「非關聯式資料庫」。由於支援快速橫向擴充套件,因此非關聯式資料庫可以處理高流量,這也使其具有很強的適應性。非關係型資料庫也即NoSQL(Not Only SQL),目的總結就是高效能,提升可延伸性!
優勢:
- 靈活性:SQL 資料庫將資料儲存在更加嚴格的預定義結構中。NoSQL 則以更加自由的方式來儲存資料,而無需嚴格的模式。這種設計可支援創新和快速應用開發。開發人員可以專注於建立系統來改善客戶服務,無需擔心模式。NoSQL 資料庫可以輕鬆處理任何資料格式,例如單一資料儲存中的結構化、半結構化和非結構化資料。
- 可延伸性:NoSQL 資料庫可以通過商用硬體來實現橫向擴充套件,而不需要通過新增更多伺服器來進行擴充套件。這可以支援流量增長,從而滿足零停機需求。通過橫向擴充套件,NoSQL 資料庫可以擴充容量和處理能力,因此成為支援不斷變化的資料集的首選方案。
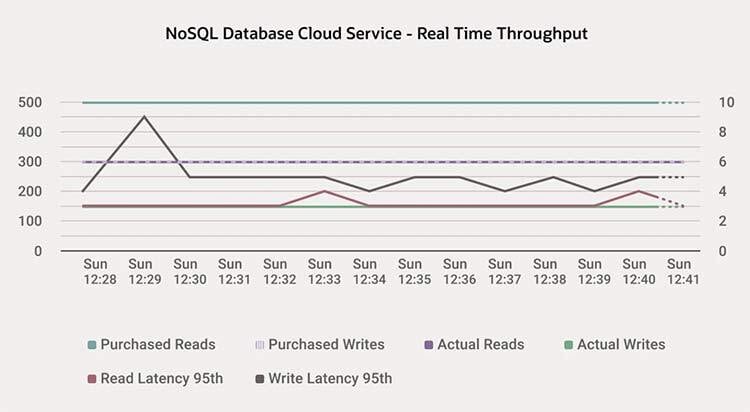
- 高效能:當資料量或流量增長時,NoSQL 資料庫的橫向擴充套件架構的優勢尤為明顯。如下圖所示,該架構可實現快速、可預測的個位數毫秒級響應能力。NoSQL 資料庫還可以攝取資料並快速可靠地交付資料,因此 NoSQL 資料庫可支援應用每天收集 TB 級資料,同時實現高度互動的使用者體驗。如下圖所示,每秒 300 次讀取的傳入速率(藍線)的第 95 次延遲在 3-4 毫秒範圍內,而每秒 150 次寫入的傳入速率(綠線)的第 95 次延遲在 4-5 毫秒範圍內。
- 可用性:NoSQL 資料庫可自動跨多個伺服器、資料中心或雲資源複製資料。而這又可以大幅減少使用者延遲,而不受其地理位置的限制。此特性還有助於減輕資料庫管理的負擔,從而騰出時間專注於其他優先事項。
- 功能強大:NoSQL 資料庫專為具有超高資料儲存需求的分散式資料儲存而設計。這使得 NoSQL 成為巨量資料、實時 Web 應用、360 度客戶檢視、線上購物、線上遊戲、物聯網、社群網路和線上廣告應用的理想方案。
不推薦NoSQL的場景:
- 要求資料規範化:NoSQL 資料庫通常依賴於非規範化資料,可支援使用較少表(或容器)的應用型別,並且其資料關係不是使用參照建模,而是作為嵌入式記錄(或檔案)。財務、會計和企業資源規劃中的許多經典後臺業務應用均依賴高度規範化的資料來防止資料異常和資料重複。這些應用型別通常不適用於 NoSQL 資料庫。
- 查詢複雜性:NoSQL 資料庫在查詢單個表時效能出眾。然而,隨著查詢複雜性的增加,關聯式資料庫則是更好的選擇。NoSQL 資料庫通常不會在 WHERE 子句中提供複雜的聯接、子查詢和查詢巢狀。
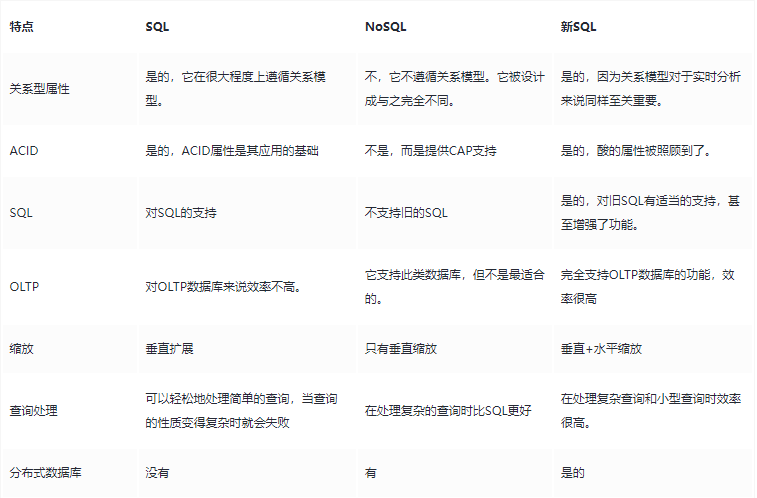
NoSQL VS RDBMS
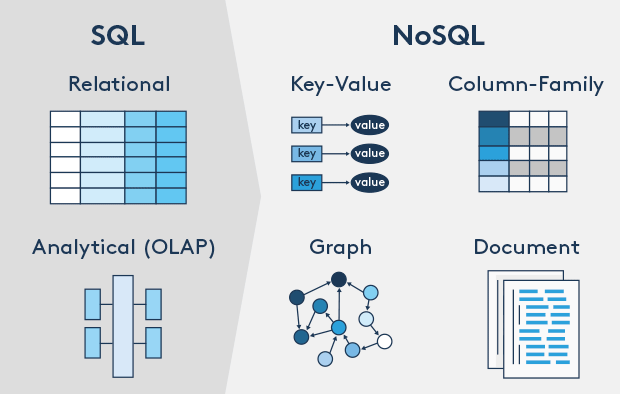
RDBMS
- 高度組織化結構化資料
- 結構化查詢語言(SQL)
- 資料和關係都儲存在單獨的表中
- 資料操縱語言,資料定義語言
- 嚴格的一致性,也稱作強一致性
- 嚴格的事務特性
NoSQL
-
不僅僅是SQL
-
沒有宣告性查詢語言
-
沒有預定義的模式
-
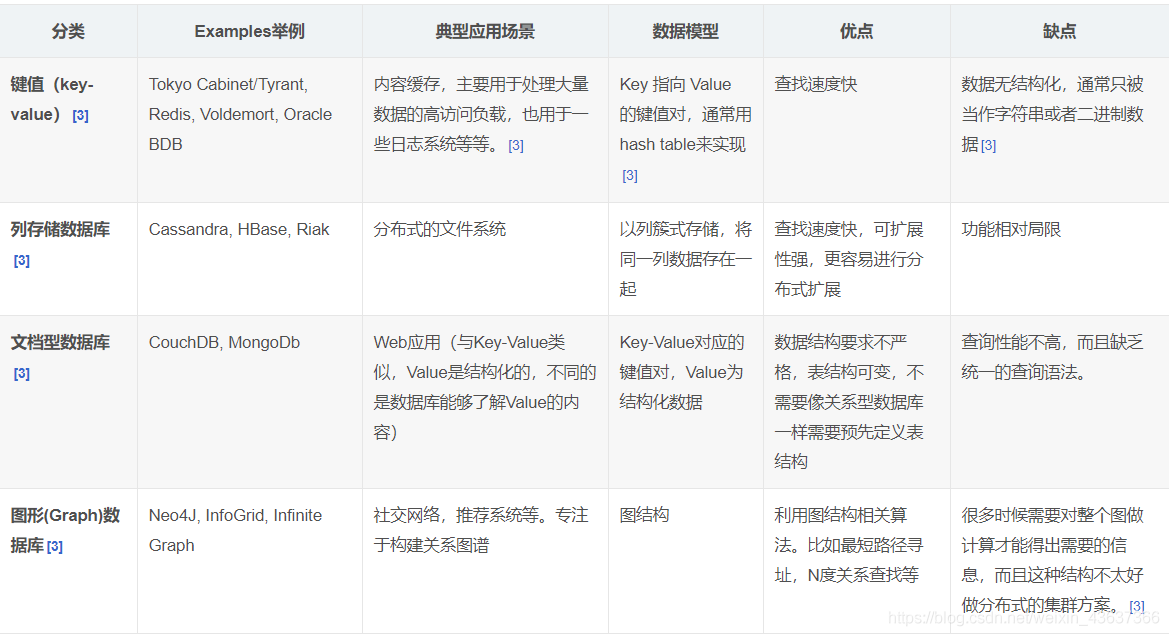
鍵 - 值對儲存,列儲存,檔案儲存,圖形資料庫
-
最終一致性,而非ACID屬性
-
非結構化和不可預知的資料
-
CAP定理

-
BASE原則
-
高效能,高可用性和可伸縮性
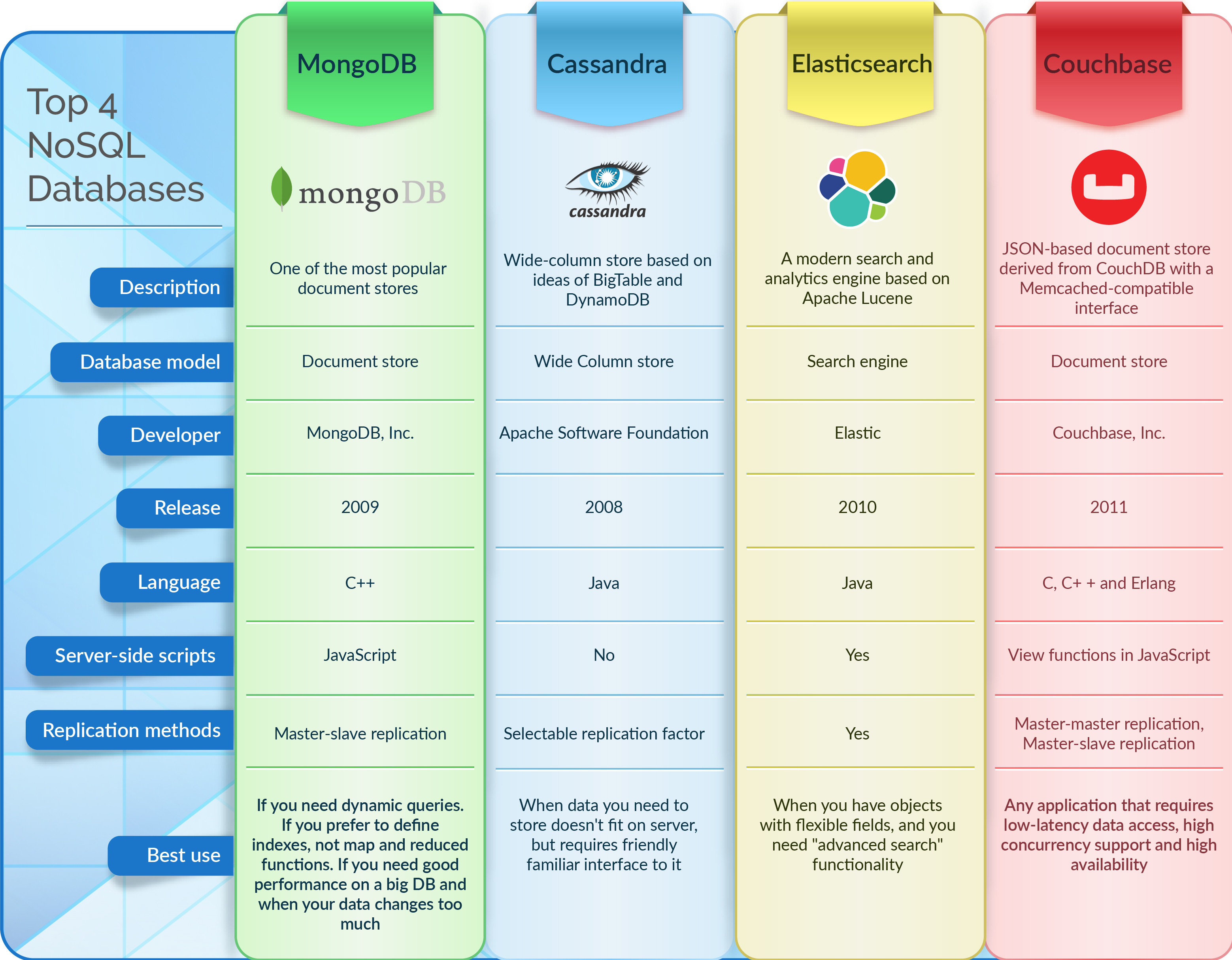
主要型別
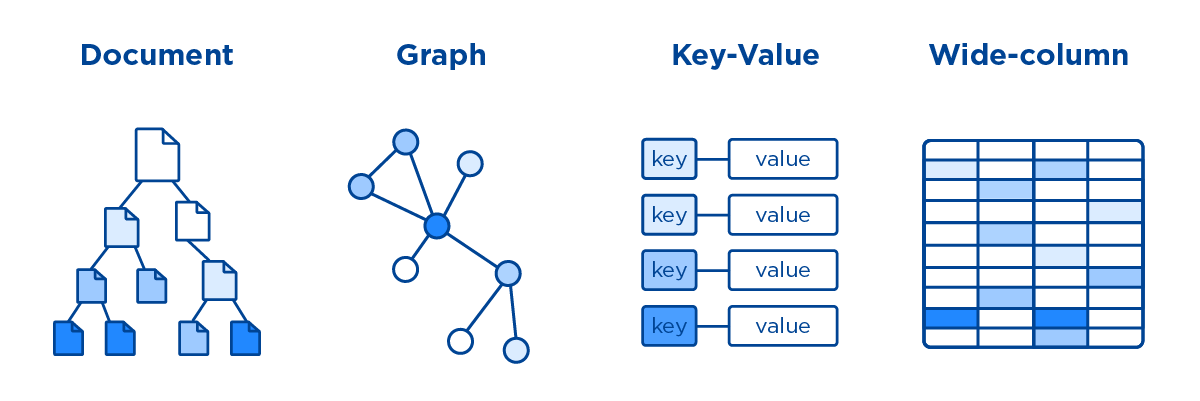
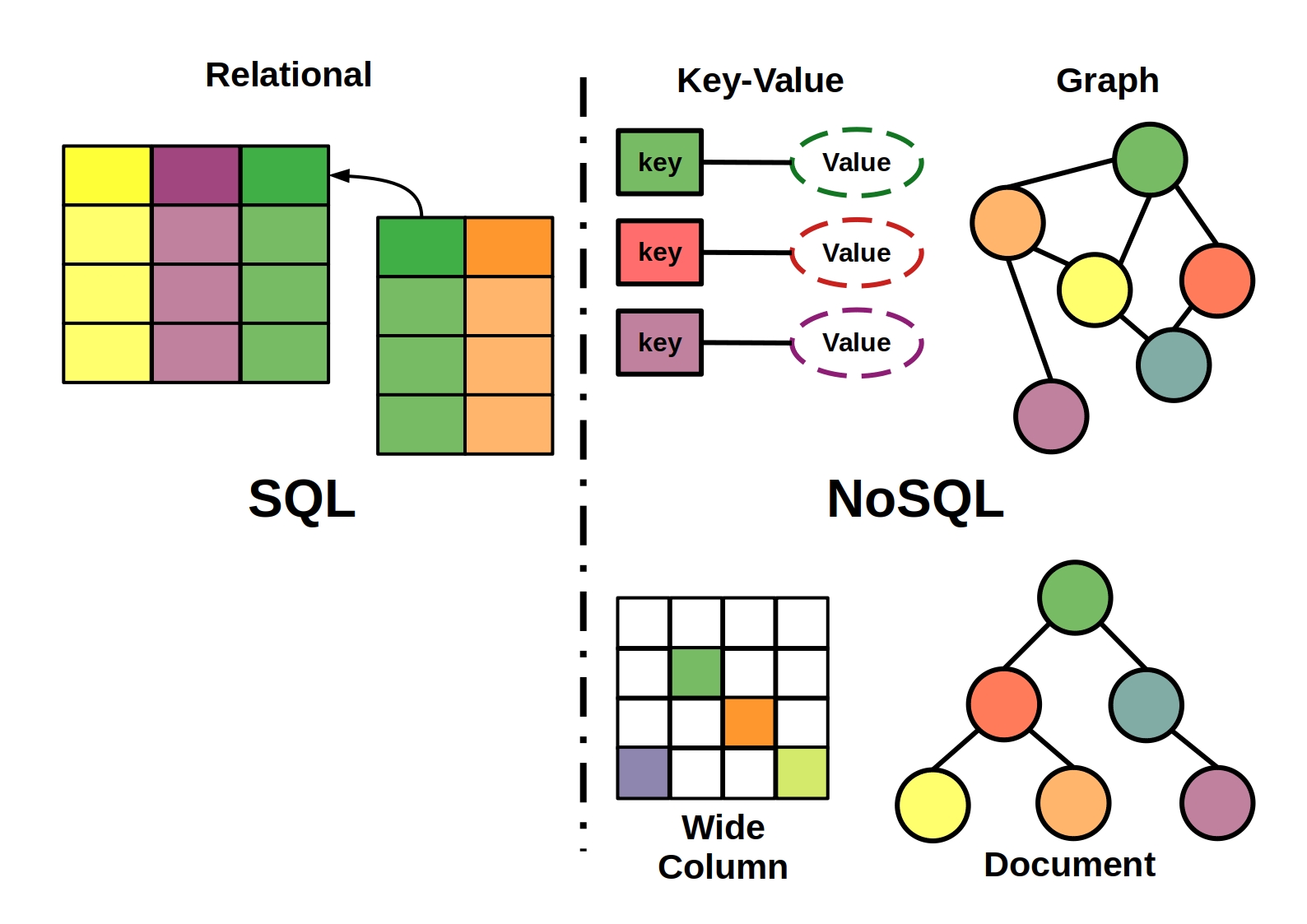
鍵值儲存型別
這是極為靈活的 NoSQL 資料庫型別,因為應用可以完全控制 value 欄位中儲存的內容,沒有任何限制!
典型代表:MemcacheDB、Redis
特點:
- 通過 Key-Value 鍵值的方式來儲存資料,通過key快速查詢到value
- Key 和 Value 可以是簡單的物件,也可以是複雜的物件
- 一般作為快取使用,故我們也稱作為故也稱作為快取資料庫

檔案儲存型別
也稱為檔案儲存或面向檔案的資料庫,這些資料庫用於儲存、檢索和管理半結構化資料。無需指定檔案將包含哪些欄位。
典型代表:MongoDB、CouchDB
特點:
- 此類資料庫可存放並獲取檔案,可以是XML、JSON等格式
- 在資料庫中檔案作為處理資訊的基本單位,一個檔案就相當於一條記錄
- 檔案資料庫所存放的檔案,就相當於鍵值資料庫所存放的「值」
- 可以對某些欄位建立索引,實現關聯式資料庫的某些功能

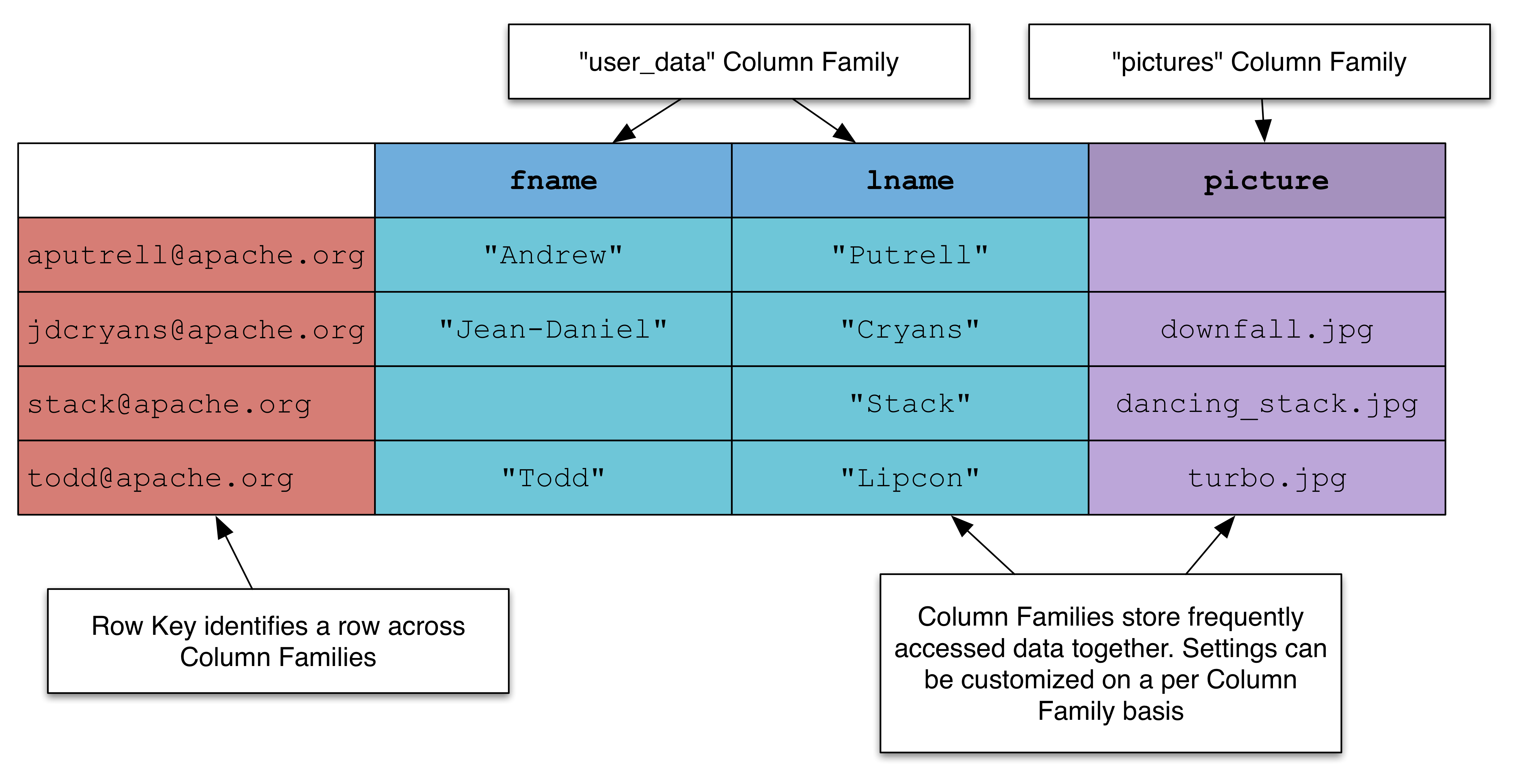
列式儲存型別
這些資料庫以表、行和列的形式來儲存和管理資料。它們廣泛部署於需要用列格式來捕獲無模式資料的應用中。
典型代表:Hbase、Cassandra、Hypertable
特點:將資料按照列進行儲存,最大的特點是方便儲存結構化和半結構化資料,方便做資料壓縮,對針對某一列或者某幾列的查詢有著極大的IO優勢
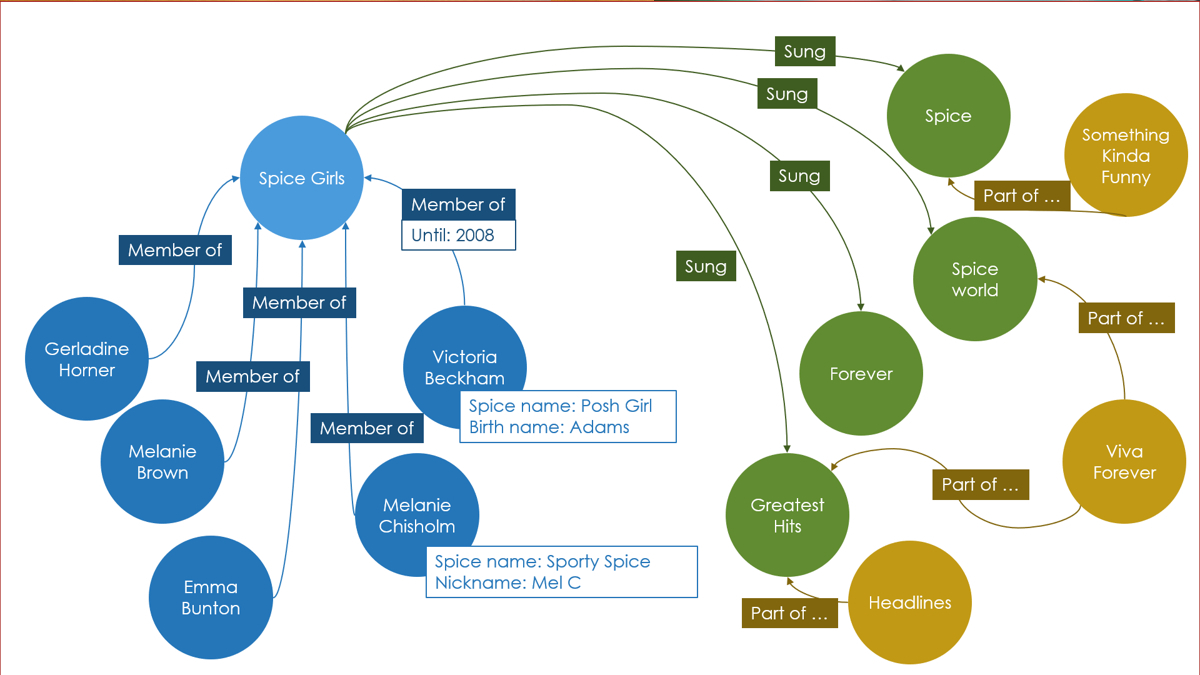
圖形儲存型別
此資料庫將資料組織為節點和關係,這將顯示節點之間的連線。這支援更加豐富和完整的資料表示。圖形資料庫應用於社群網路、預訂系統和欺詐檢測。
典型代表:Neo4J、FlockDB
特點:
- 利用了圖這種資料結構儲存了實體(物件)之間的關係
最典型的例子就是社群網路中人與人的關係,資料模型主要是以節點和邊(關係)來實現,特點在於能高效地解決複雜的關係問題
- 關係型資料用於儲存明確關係的資料,但對於複雜關係的資料儲存就有些不方便
如社群網路中人物之間的關係,如果用關係型資料庫則非常複雜,用圖形資料庫將非常簡單
總結:
- NoSQL介紹:https://www.guru99.com/nosql-tutorial.html
- MongoDB官網介紹:https://www.mongodb.com/zh-cn/nosql-explained
NoSQL缺點
- NoSQL 不保證強一致性,對於普通應用沒問題,但還是有不少像金融一樣的企業級應用有強一致性的需求。
- 缺乏標準化,NoSQL 不支援 SQL 語句,沒有特定的語言,相容性是個大問題,不同的NoSQL 資料庫都有自己的 API 運算元據,比較複雜
四、NewSQL儲存
NewSQL 提供了與 NoSQL 相同的可延伸性,而且仍基於關係模型,還保留了極其成熟的 SQL 作為查詢語言,保證了ACID事務特性。簡單來講,NewSQL就是在傳統關係型資料庫上整合了NoSQL 強大的可延伸性。
傳統的SQL架構設計基因中是沒有分散式的,而NewSQL 生於雲時代,天生就是分散式架構。
NewSQL 的主要特性:
- SQL 支援,支援複雜查詢和巨量資料分析
- 支援 ACID 事務,支援隔離級別
- 彈性伸縮,擴容縮容對於業務層完全透明
- 高可用,自動容災
總的來說資料庫產品演進就是分為三代:
- 第一代資料庫架構產品:傳統的關係型資料庫主導
- 第二代資料庫架構產品:傳統關係型資料庫 + NoSQL多廠家產品配合使用
- 第三代資料庫架構產品:NewSQL(關係型+NoSQL+巨量資料+分散式架構完整解決方案)
主流資料庫產品:
RDBMS:Oracle,MySQL,PG,MSSQL,DB2,SQLLite
NoSQL:MongoDB,Redis,ElasticSearch,Cassandra,Neo4j,Solr
NewSQL: Google Spanner,PinCAP TiDB
雲資料庫:Aliyun RDS,DRDS,PolarDB,騰訊雲 TDSQL
參考文章:
- 通俗理解資料庫:https://www.daimabiji.com/teatime/933.html
- SQL vs NoSQL vs NewSQL:https://juejin.cn/post/6992416728990875662
- NewSQL系統綜述:https://zhuanlan.zhihu.com/p/23866692
---------------------------------------------------------
個性簽名:獨學而無友,則孤陋而寡聞。做一個靈魂有趣的人!
如果覺得這篇文章對你有小小的幫助的話,記得在右下角點個「推薦」哦,博主在此感謝!
本文內容若有疏漏請多多包涵,如有錯誤麻煩請指正,如有想法交流非常歡迎在下方評論!