Linux系統調優介紹
前言:
Linux伺服器執行了很多應用,在高負載下,伺服器可能會出現效能瓶頸,例如CPU利用率過高、記憶體不足、磁碟I/O瓶頸等,從而導致系統卡頓,服務無法正常執行等問題。所以針對以上問題,可以通過調整核心引數和系統的相關元件,優化應用程式來提高伺服器的效能和穩定性,避免系統崩潰和服務中斷。
Linux系統優化考慮的兩個方面:
- 硬體層面:例如加記憶體、換用企業級SSD、提高頻寬等操作。
- 軟體層面:系統核心引數、硬碟IO以及資源分配方面的設定。
在軟體層面如何進行系統優化:
主要從系統核心引數、CPU、IO、網路、記憶體這幾個方面來進行優化。
- 記憶體調優:優化系統的記憶體使用效率,減少記憶體漏失和記憶體碎片等問題。
- 磁碟調優:提高磁碟的讀寫速度和可靠性,減少資料丟失和損壞的風險。
- CPU調優:優化CPU的利用率,提高系統的效能和穩定性。
- 網路調優:提高網路的效能和穩定性,減少資料傳輸的延遲和丟失。
- 程序和執行緒調優:優化系統的程序排程演演算法、減少程序和執行緒的競爭等,提高系統的並行效能和穩定性。
系統優化的步驟:
1、使用系統監控工具、效能測試工具等,收集系統的效能資料和指標,瞭解系統當前的執行狀態,從而識別系統的瓶頸和優化空間。
2、使用追蹤工具進行追蹤,定位到具體的應用程式和程序。
3、根據定位到的應用程式和程序進行分析,分析導致出問題的原因,從而對記憶體、磁碟、CPU等方面進行優化。
系統效能的相關概念:
IOPS:Input/Output Per Second。是指每秒鐘可以進行的輸入/輸出操作次數,是衡量儲存裝置效能的重要指標之一
吞吐量:Throughput。系統在單位時間內能夠處理的事務數量。
響應時間:Response Time。系統從接收請求到返回結果所需的時間。
頻寬:Bandwidth。資料傳輸的速度,通常以每秒傳輸的位元數(bps)或位元組(Bps)來衡量。
延時:Latency。指從請求發出到收到響應所需的時間。
瓶頸:Bottleneck。作業系統中限制系統效能的關鍵因素或資源。當系統中某個元件的處理能力達到極限,無法滿足其他元件的需求時,就會出現瓶頸。
工作負載:Workload。是指計算機系統中正在執行的應用程式或任務的集合。
快取:cache。快取的作用就是用來提高系統效能的一種技術。
CPU快取::CPU快取是一種硬體裝置,通常是整合在CPU晶片中。CPU快取分為三個級別,包括L1、L2和L3快取,這些級別按照快取大小和存取速度逐漸遞減。用於儲存CPU需要頻繁存取的資料和指令,以便更快地執行計算任務。CPU快取速度非常快,通常比記憶體快取快幾個數量級,因此能夠大大提高計算機的執行速度。
記憶體快取:記憶體快取通常是通過在系統記憶體中劃分出一部分空間來實現的,這部分空間被稱為快取區。快取區是由作業系統核心管理的,它在系統啟動時就被分配出來,並在系統執行期間一直存在。
當應用程式需要存取記憶體中的資料時,記憶體快取會首先檢查快取區中是否已經快取了該資料。如果已經快取,則可以直接從快取區中讀取資料,從而避免了從記憶體中讀取資料的時間和能耗。如果快取區中沒有該資料,則需要從記憶體中讀取,並將資料儲存到快取區中以供下一次存取使用。
緩衝:Buffer。緩衝通常是在記憶體中分配一塊空間來實現的,這些空間被稱為緩衝區。緩衝區是用於臨時儲存資料的區域,資料在這裡被暫時儲存並等待被進一步處理。
如將資料從一個裝置傳輸到另一個裝置時,緩衝可以暫存資料,以防止資料在傳輸過程中丟失或損壞。因為如果傳送方速度太快,接受方不能及時接收就會導致資料丟失。
輸入緩衝區(Input Buffer):用於儲存輸入裝置(例如鍵盤、滑鼠等)傳送過來的資料,等待系統進一步處理。
輸出緩衝區(Output Buffer):用於儲存輸出裝置(例如印表機、螢幕等)接受資料,等待裝置進行處理。
檔案緩衝區(File Buffer):用於儲存檔案資料的記憶體區域,通過將檔案資料快取到記憶體中,可以減少存取磁碟的次數,提高檔案讀寫的效率。
磁碟快取(Disk Cache):用於儲存磁碟上的資料,通過將常用的資料快取到記憶體中,可以加速磁碟存取,提高系統的效能。
Linux資源資訊的監控
通過對系統效能引數的監控和收集,瞭解當前系統的負載、CPU使用情況,記憶體使用、IO等資訊。
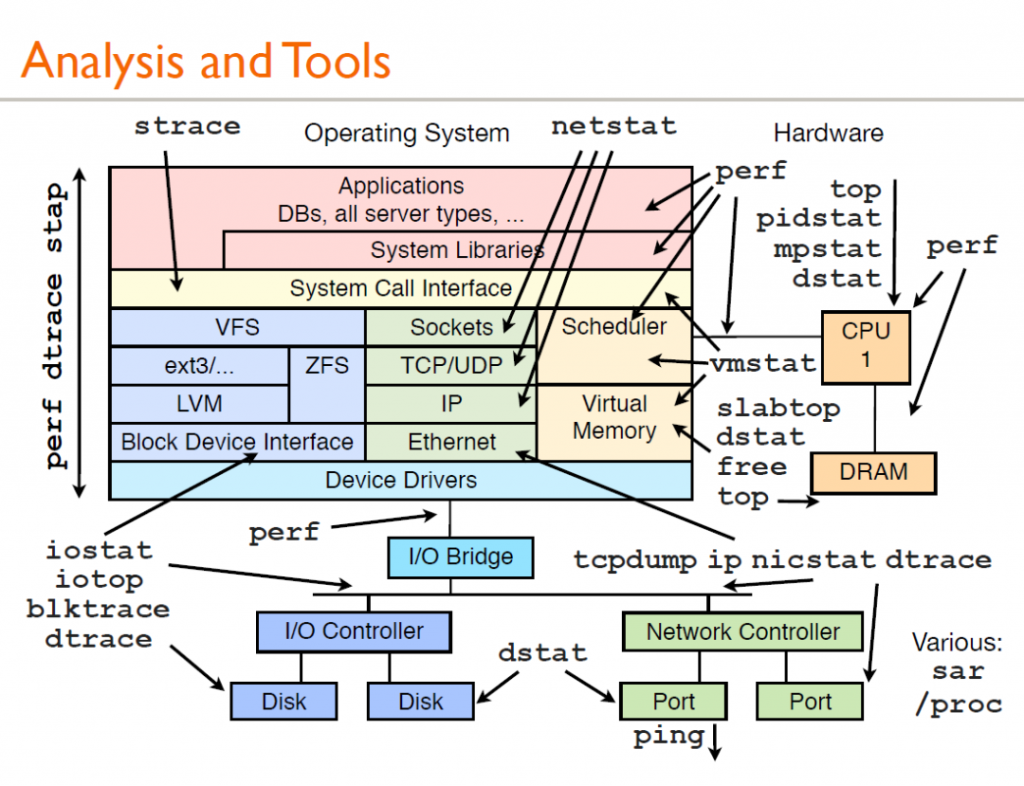
一:檢視系統整體的資訊:
1、vmstat工具
vmstat是系統自帶的一個工具,vmstat主要檢視的是記憶體和程序的使用情況,其它例如程序、系統IO、上下文切換這些資訊也可以檢視。
例如:
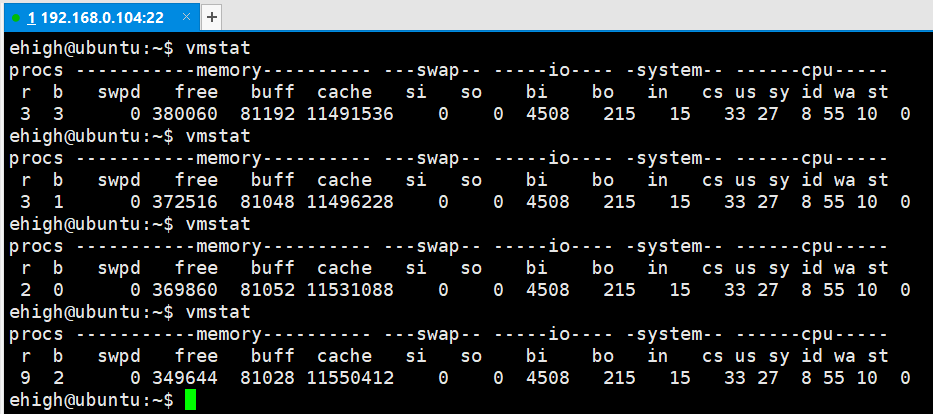
procs:顯示程序的活動情況。
r :正在執行的以及處於排隊狀態的執行緒數,這個值和程序有關係,如果值長期大於cpu的核數(lscpu檢視cpu個數),說明cpu不夠,任務執行的程序太多。
b :程序阻塞的數量,阻塞狀態就是一隻處於排隊狀態。這個值長期大於0就表明cpu資源嚴重不夠了。一直輪不到給你分配cpu
memory:顯示系統的記憶體使用情況。
swap:交換分割區使用了多少。0表示還沒有任何使用,如果已經開始使用交換分割區了,說明記憶體已經不夠用了
buff:緩衝區還剩多少 單位為k,一般是往硬碟裡面寫的時候會佔用這個值。
cache:快取還剩多少 單位也是k
swap:顯示系統的交換空間使用情況。
說明:si和so只要大於0,說明記憶體有問題了。例如記憶體洩露、記憶體不夠等情況。
si:swap input:硬碟到交換分割區的一個大小。
so:swap output:從交換分割區到硬碟的一個大小。
io:顯示系統的磁碟I/O活動情況。
bi:往硬碟裡面寫的一個值
bo:往硬碟裡面讀的一個值。單位是k
說明:如果系統的bi和bo值很大,說明io有問題。
system:顯示系統的CPU使用情況。
in:中斷的數目,
cs:上下文切換的數目
說明:如果系統中存在大量的上下文切換和終端,說明系統可能存在某些問題
cpu:顯示系統的CPU使用率。
us:使用者程序所消耗的時間
sy:系統程序消耗的一個時間
id:系統的空閒時間
wa:硬碟io出現了阻塞,資料太多入口被堵死了。但是寫不進去,所以就開始等待。 如果wa這個值比較大說明cpu的資源夠,但是io有問題導致浪費了cpu。
st:在虛擬化的時候會用到。
2、mpstat工具
mpstat工具和vmstat不同點在於mpstat主要監視CPU使用情況,包括每個CPU的使用率、上下文切換、中斷和軟中斷等資訊。
例如:

CPU:顯示每個CPU的編號,all表示所有的cpu
%usr:顯示使用者空間程序使用CPU的百分比。
說明:如果%usr較高,表示使用者空間程序佔用了大量CPU資源,可能是某個程序出現了問題或者某個程序需要更多的CPU資源。
%nice:顯示優先順序較低的使用者空間程序使用CPU的百分比。
%sys:顯示核心空間程序使用CPU的百分比。
說明:如果%sys較高,表示核心空間程序佔用了大量CPU資源,可能是某個核心模組出現了問題或者某個程序在等待核心資源。
%iowait:顯示CPU等待I/O完成的百分比。
說明:如果%iowait較高,表示CPU正在等待I/O操作完成,可能是磁碟、網路或其他I/O裝置出現了瓶頸。
%irq:顯示CPU處理硬體中斷的百分比。
說明:如果%irq較高,表示CPU正在處理大量硬體中斷,可能是某個硬體裝置出現了問題。
%soft:顯示CPU處理軟體中斷的百分比。
說明:如果%soft較高,表示CPU正在處理大量軟體中斷,可能是某個程序出現了問題或者某個核心模組在處理大量請求。
%steal:顯示被虛擬機器器偷走的CPU時間的百分比。
%guest:顯示虛擬機器器使用CPU的百分比。
%idle:顯示CPU空閒的百分比。
說明:如果%idle較低,表示CPU正在忙碌,可能是系統負載過高或者某個程序佔用了大量CPU資源。
3、iostat工具
iostat主要監視磁碟I/O使用情況,包括每個磁碟的讀寫速度、I/O等待時間、I/O請求佇列長度等,主要使用iostat工具來了解系統磁碟I/O使用情況,識別磁碟I/O瓶頸和瓶頸程序。

Device:sda1
r/s:458.09 # 表示每秒從裝置中讀取的次數。
rkB/s:56330.40 # 每秒讀取的資料量,單位為KB。
rrqm/s:0.63 # 每秒從磁碟發出的讀取請求佇列的長度,單位為請求。
%rrqm:0.14 # 表示從磁碟發出的讀取請求佔總讀取請求的百分比。
r_await:4.17 # 表示讀操作的平均等待時間,單位為毫秒。
rareq-sz:122.97 # 平均每個讀取請求的資料量,單位為磁區
w/s:67.28 # 表示每秒向裝置中寫入的次數。
wkB/s:788.53 # 每秒鐘寫的數量,單位是kb
wrqm/s:54.32 # 每秒從磁碟發出的寫入請求佇列的長度,單位為請求
%wrqm:44.67 # 表示從磁碟發出的寫入請求佔總寫入請求的百分比。
w_await:6.75 # 表示寫操作的平均等待時間,單位為毫秒。
wareq-sz:11.72 # 平均每個寫入請求的資料量,單位為磁區
d/s:0.00
dkB/s:0.00
drqm/s :0.00
%drqm:0.00
d_await:0.00
dareq-sz :0.00
aqu-sz :2.37 # 請求佇列的平均長度。
%util:96.96 # 表示磁碟花費在處理請求的時間百分比 經常超過80%或90%,則說明磁碟正在高負載下執行
總結:
當 r/s 和 w/s、rkB/s 和 wkB/s、r_await 和 w_await 等指標的值都很大,並且 %util 的值也很高時,可以初步判斷磁碟可能存在效能問題。
4、sar工具:
相比於vmstat和pmstat,star工具提供了更全面的系統效能監控和歷史資料分析功能。可以將輸出的資訊重定向到一個檔案裡面,便於後續的分析。
(1)檢視CPU的使用情況:

# %user:使用者空間程序所佔用CPU時間的百分比。
# %nice:被nice值提高的使用者空間程序所佔用CPU時間的百分比。
# %system:核心空間程序所佔用CPU時間的百分比。
# %iowait:CPU等待I/O操作完成所佔用CPU時間的百分比。
# %steal:被虛擬化程式(如VMware)偷走的CPU時間的百分比。
# %idle:CPU空閒時間的百分比。
- 如果
%user和%system佔用率較高,可能表示系統負載較高,需要進一步檢查程序、IO等情況。 - 如果%iowait佔用率較高,可能表示IO瓶頸
- 如果%idle佔用率較高,可能表示系統資源未充分利用
(2)監視記憶體使用情況:

# kbmemfree:可用記憶體大小(單位:KB)
# kbmemused:已用記憶體大小(單位:KB)
# %memused:已用記憶體佔總記憶體的百分比
# kbbuffers:快取的記憶體大小(單位:KB)
# kbcached:快取的檔案系統快取大小(單位:KB)
# kbcommit:提交記憶體大小(單位:KB)
# %commit:提交記憶體佔總記憶體的百分比
# kbactive:活躍記憶體大小(單位:KB)
# kbinact:非活躍記憶體大小(單位:KB)
# kbdirty:髒頁的記憶體大小(單位:KB)
- 如果可用記憶體(
kbmemfree)較少,已用記憶體(kbmemused)和已用記憶體佔總記憶體的百分比(%memused)較高,可能表示記憶體不足 - 如果快取的記憶體(
kbbuffers)和快取的檔案系統快取(kbcached)較高,可能表示系統的檔案系統快取良好 - 如果提交記憶體(
kbcommit)較高,可能表示應用程式提交的記憶體較多 - 如果活躍記憶體(
kbactive)和非活躍記憶體(kbinact)較高,可能表示系統當前執行的應用程式較多
(3)監視磁碟I/O使用情況:
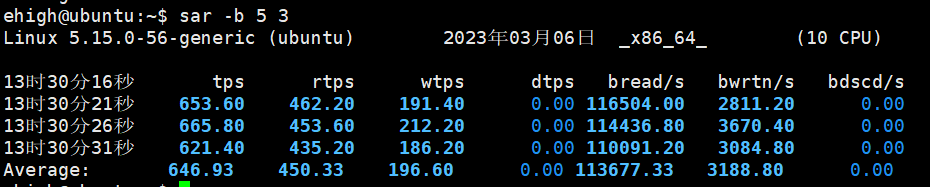
# tps:每秒傳輸的I/O請求數(包括讀寫請求)
# rtps:每秒讀請求傳輸的I/O請求數
# wtps:每秒寫請求傳輸的I/O請求數
# bread/s:每秒讀取的資料塊數量(單位:512位元組)
# bwrtn/s:每秒寫入的資料塊數量(單位:512位元組)
- 如果
tps較高,可能表示磁碟I/O瓶頸 - 如果
rtps或wtps較高,可以進一步確認是讀操作或寫操作的問題 - 如果
bread/s或bwrtn/s較高,可能表示磁碟I/O吞吐量不足
(4)檢視網路的基本資訊:DEV
主要檢視的是接收和傳送封包的速率、接收和傳送資料量的速率
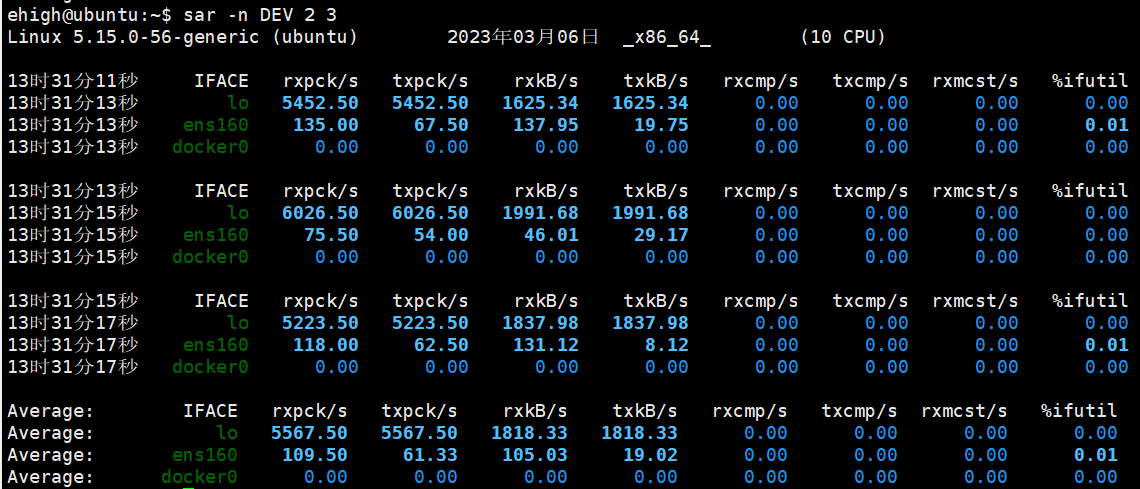
# IFACE:網路介面名稱。
# rxpck/s:每秒接收的封包數量。
# txpck/s:每秒傳送的封包數量。
# rxkB/s:每秒接收的資料量(KB)。
# txkB/s:每秒傳送的資料量(KB)。
# rxcmp/s:每秒接收的壓縮封包數量。
# txcmp/s:每秒傳送的壓縮封包數量。
# rxmcst/s:每秒接收的多播封包數量。
-
如果
rxkB/s和txkB/s非常高,但%ifutil非常低,則可能存在網路擁塞的問題 -
如果
rxcmp/s和txcmp/s非常高,可能存在資料壓縮的問題。 -
如果
rxmcst/s非常高,可能存在多播網路流量的問題。資料壓縮:為了減少資料的傳輸量,可以對資料進行壓縮。壓縮的過程是將原始資料使用某種壓縮演演算法進行編碼,使其佔用更少的頻寬。
(5)檢視網路的錯誤資訊EDEV
可以檢視網路裝置的錯誤和丟包數。
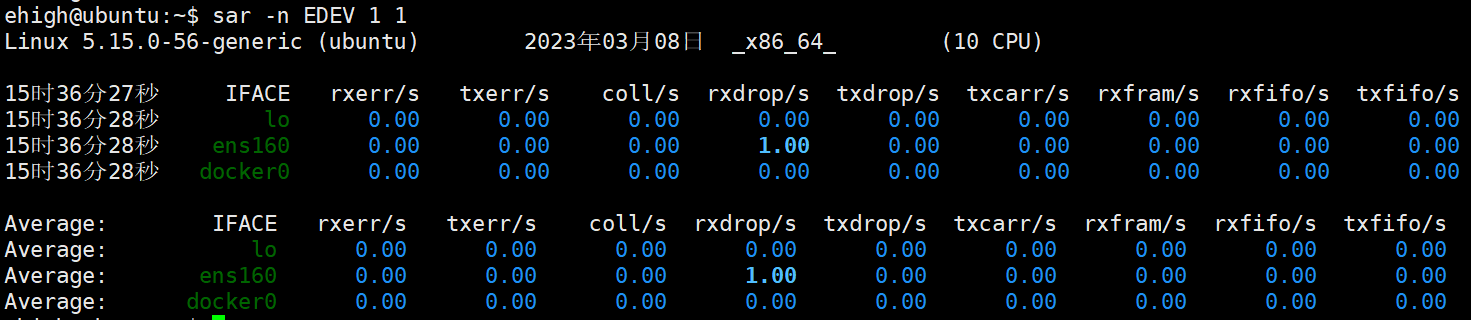
# rxerr/s:每秒接收的錯誤數。
# txerr/s:每秒傳送的錯誤數
# coll/s:每秒發生的衝突數。
# rxdrop/s:每秒接收的丟包數
# txdrop/s:每秒傳送的丟包數。
# txcarr/s:每秒發生的載波錯誤數。
# rxfram/s:每秒接收的幀錯誤數。
# rxfifo/s:每秒鐘由於接收FIFO佇列溢位而丟失的封包數。
# txfifo/s:每秒鐘由於傳送FIFO佇列溢位而丟失的封包數。
rxerr/s或rxdrop/s的值很高,可能存在網路中的接收問題,例如硬體故障或網路擁塞等。txerr/s或txdrop/s的值很高,可能存在網路中的傳送問題,例如硬體故障或網路擁塞等coll/s的值很高,可能存在網路中的衝突問題,例如網路中存在多個裝置嘗試同時傳送封包/
使用場景總結:
- 需要實時監控系統資源,可以使用 vmstat 和 iostat
- 需要對系統歷史效能進行分析,可以使用 sar
- 分散式系統中進行效能分析和監控,則可以選擇 pmstat,因為分散式系統的效能監控比較複雜,pmstat的實時監控功能更靈活。
- 如果只是想看看系統的狀態,以上工具都可以。
二:檢視某個程序的資源佔用資訊:
1、top
用來實時顯示實時地顯示系統中所有程序的資源佔用情況。
在沒有htop工具的情況下檢視系統資源的資訊。
按下 c 快捷鍵將會顯示程序的完整命令列引數。
在top命令中按下快捷鍵盤’c‘之後。
2、ps
主要用來列出系統中所有程序的資訊。
例如:執行了某個指令碼,檢視指令碼是否啟動
# 執行一個測試指令碼
ehigh@ubuntu:~$ bash test.sh &
[1] 21738
# 檢視這個指令碼是否正常啟動
ehigh@ubuntu:~$ ps -ef | grep test.sh
ehigh 21738 14974 0 11:04 pts/19 00:00:00 bash test.sh
3、htop
ttop 命令的一個增強版,可以實時地顯示系統中所有程序的資源佔用情況。
4、pidstat
實時地顯示某個程序的 CPU 使用率、記憶體佔用等。
5、strace
追蹤某個程序的系統呼叫資訊,可以捕獲和列印出應用程式和核心之間發生的所有系統呼叫和訊號,包括傳遞的引數和返回值,以及發生的錯誤。
例如:
# 檢視執行某個命令的系統呼叫資訊
strace `ls -l /tmp`
# 檢視某個程序的系統呼叫:檢視pid為1435這個程序的系統呼叫
sudo strace -p 1435
一般可以使用strace工具來檢視某個程序讀取了哪些檔案,程序執行慢,時間都花費在了哪些地方以及系統的呼叫函數等。
使用場景總結:
- 如果想要檢視系統程序和資源的佔用情況,就使用top或htop。
- 如果想要追蹤某個程序的系統呼叫,呼叫耗時等資訊就是用strace工具
- 如果只是檢視某個程序特定的詳細資訊,就使用ps工具,想要進行深入分析就是用pidstat工具。
系統調優方法
作業系統:作業系統是一個系統軟體,作業系統的作用是管理和控制計算機硬體
核心:核心是作業系統的核心部分,是作業系統管理計算機硬體和軟體資源的核心程式碼。作業系統則由核心和其他系統工具程式共同組成的。例如檔案管理器、使用者介面、裝置驅動程式等。
程式:指的是一組計算機指令和資料,可以被計算機執行。程式是靜態的,通常儲存在硬碟或其他儲存裝置中,需要通過作業系統載入到記憶體中才能執行。
程序:是計算機中正在執行的程式的範例。程序是作業系統中進行資源分配的基本單位。
執行緒:是程序中的一個執行單元,是作業系統排程的最小單位。
核心空間:核心空間是作業系統的核心部分,是作業系統核心執行的地址空間。核心空間是作業系統獨佔的,只有核心才能存取這個地址空間。
使用者空間:是程式執行的地址空間。使用者空間是作業系統分配給應用程式的地址空間,應用程式可以在這個空間中執行和使用系統資源。
程序和程式的關係:首先程式被載入到記憶體中,沒有開始執行的時候,只是一組靜態的程式碼和資料。當程式被作業系統呼叫並開始執行時,就成為了一個程序。一個程序裡面包含了程式程式碼、資料、暫存器等系統資源,所以每個程序都是一個程式的實體,程序是作業系統中進行資源分配和排程的基本單位。
兩個虛擬檔案系統:
在Linux中,/sys和/proc是兩個不同的虛擬檔案系統,裡面的資訊都是動態生成的,因為這兩個目錄中的資料資訊隨著系統狀態的變化而變化。這兩個檔案提供了操作核心資料的介面。
/proc檔案系統:主要用於展示程序相關的資訊,例如可以查詢核心狀態和程序資訊,例如CPU、記憶體、網路、硬體等系統資訊。
/sys檔案系統:則用於展示裝置和核心引數的資訊。/sys中不包含程序的資訊,只有系統的狀態和裝置資訊。
說明:
- 修改了/proc/sys中的引數後可以通過sysctl工具來實現持久化設定。
- 修改了/sys 中的資訊不能使用sysctl工具來持久化設定,需要寫入到/etc/rc.locl這個檔案中實現持久化設定。
例如:echo deadline > /sys/block/sda/queue/scheduler就需要放到/etc/rc.locl中。
一:PAM和Cgroup限制資源
PAM:PAM是一個獨立的動態共用庫,其功能是提供身份驗證、授權和帳戶管理等功能。LInux核心只提供了基本的身份驗證和存取控制功能,PAM模組擴充套件了身份驗證和存取控制的功能,可以通過設定PAM模組來實現使用者身份驗證和存取控制。
在Linux PAM中,每個模組可以設定兩個限制:軟限制和硬限制,用於控制使用者對系統資源的存取。
- 軟限制:超過了限制的值會傳送警告資訊
- 硬限制:超過了限制的值會直接拒絕
Cgroup模組:control group。是 Linux 核心中的一個機制,可以用於限制程序的資源使用(例如 CPU、記憶體、磁碟 I/O 等)和優先順序分配,以實現資源隔離和效能優化。Cgroup 模組是 Linux 系統中的一個核心模組,提供了對 Cgroup 機制的支援。
二:CPU的優化方法
1、設定CPU的親和性
使用場景:系統中的CPU資源較為緊張,或者應用程式的負載不均衡,可以考慮使用CPU親和性設定來優化CPU資源的利用
通過taskset命令進行設定CPU的親和性,該命令可以將程序或執行緒繫結到指定的CPU核心上,以提高程式的效能和可靠性。
例如,以下命令將程序ID為1234的程序繫結到CPU核心0和1上:
taskset -c 0,1 -p 1234
2、調整CPU的排程策略
預設的CFS策略已經能夠滿足日常需求,如果在某些特定的情況下可以改變排程策略來進行優化,例如高負載、需要實時響應等場景。
實現方法:需要編譯核心加上對應的驅動程式,風險極大。
3、調整時間片大小
場景:如果應用程式需要更快的響應時間,可以考慮減小時間片大小。
實現方法:需要編譯核心啟用對cpu時間片大小修改的支援,風險極大。
缺點:會增加系統的開銷,可能會降低系統的整體效能,因為需要增加系統上下文的切換次數。
4、調整CPU的遷移開銷
場景:通過CPU遷移開銷的調整,可以提高系統的負載均衡和響應速度
實現方法:也是需要編譯核心加上對應的驅動程式才可以,通過修改對應的值來調整CPU的遷移開銷。修改核心風險極大。
缺點:減小CPU遷移開銷可能會導致更頻繁的CPU遷移,從而增加系統的開銷和延遲,導致程序的區域性性和快取效率下降,從而降低系統的整體效能。
二:記憶體的優化方法:
1、優化對swap分割區的使用
swap分割區是一塊硬碟空間,用於存放記憶體中不常用的資料。在Linux系統中,合理設定swap分割區的大小可以有效地提高系統的穩定性和效能。因為swap分割區的速度太慢,一般都是直接關閉swap分割區的使用。
關閉swap分割區的方法:
swapoff -a # 臨時關閉
2、調整虛擬記憶體引數
如果一定要使用swap分割區,可以通過調整/proc/sys/vm/swappiness的值為0來確保儘量使用實體記憶體。
# 1. 修改核心引數
ehigh@ubuntu:~$ sudo vim /etc/sysctl.conf
vm.swappiness = 60
# 2. 生效
ehgh@ubuntu:~$ sysctl -p
3、調整髒頁的最大記憶體量
髒頁是指已被修改但尚未寫入磁碟的記憶體頁。核心使用 dirty_bytes 值來確定何時開始重新整理髒頁到磁碟。
調整頁面快取的大小(/proc/sys/vm/dirty_bytes),提高系統的效能。
優化建議:
- 系統有足夠的記憶體和IO資源,可以增加dirty_bytes的值,以減少頻繁寫回磁碟的次數,從而提高效能
- 統資源不足,可以降低dirty_bytes的值,以避免過多的髒頁面積累,從而避免系統效能下降或記憶體耗盡。
優點:增大髒頁資料的值可以減少磁碟 I/O和提高提高記憶體利用率,因為當系統中存在大量可用記憶體時,增加 dirty_bytes 值可以讓核心將更多的髒頁儲存在記憶體中,提高記憶體利用率。
缺點:如果記憶體不足會導致系統效能下降,可能會造成磁碟IO洪水,如果斷電未寫入磁碟的髒頁資料可能會丟失。
例如:將頁面快取得大小改為1G
# 1. 修改核心引數
ehigh@ubuntu:~$ sudo vim /etc/sysctl.conf
vm.dirty_bytes=1073741824 # 將髒頁的記憶體量調整為1G
# 2. 生效
ehigh@ubuntu:~$ sysctl -p
4、使用記憶體快取
tmpfs:tmpfs是一種基於記憶體的檔案系統,tmpfs中的資料不需要將資料寫入硬碟,因此可以獲得更快的檔案讀寫速度。
例如:
# 1. 建立掛載點
mkdir /mnt/cache
# 2. 掛載tmpfs檔案系統
mount -t tmpfs -o size=2G tmpfs /mnt/cache
# 3. 將需要進行快取的檔案或目錄複製到掛載點目錄下
cp -r /path/to/files /mnt/cache
# 4. 應用程式或指令碼中的檔案路徑修改為掛載點目錄下的路徑
# 5. 當檔案讀取或寫入完成後,可以通過rsync等工具將快取中的檔案同步到硬碟上,從而避免資料的丟失。
rsync -a /mnt/cache/ /path/to/files/
記憶體快取適用的場景:
(1)Web伺服器:在Web伺服器中,通常會快取靜態檔案(如CSS、JavaScript、圖片等),以提高網站的效能和響應速度。使用tmpfs作為記憶體快取,可以將這些靜態檔案快取到記憶體中,提高資料讀取速度,減輕磁碟負載。
(2)資料庫伺服器:在資料庫伺服器中,經常需要將一些資料放在記憶體中進行快取,以提高查詢效能。使用tmpfs作為記憶體快取,可以將這些資料快取到記憶體中,避免頻繁的磁碟IO操作,提高查詢效能。
(3)虛擬機器器:在虛擬機器器環境中,可以使用tmpfs作為記憶體快取,以提高虛擬機器器的磁碟IO效能。例如,可以將虛擬機器器的磁碟映象檔案(如vmdk、qcow2等)快取到tmpfs中,避免頻繁的磁碟IO操作。
5、設定大頁
大頁是一種特殊的記憶體頁,它的大小通常是預設頁大小的幾倍,比如 2MB 或者 1GB。
在記憶體充足的情況下,可以提高 Linux 系統的效能。使用大頁可以減少記憶體頁表的大小,從而提高記憶體存取的效率。對於一些需要頻繁存取記憶體的應用程式(比如資料庫),啟用大頁可以顯著提高效能。
例如:執行虛擬機器器的時候設定大頁能顯著提升效能。
如果記憶體小設定大頁會降低系統的效能。
設定實現流程:
# 1. 檢視是否開啟大頁功 預設情況下,已經開啟了透明大頁功能:
root@ubuntu:~# cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never
# 2. 檢視大頁的數目 預設為0
root@ubuntu:~# cat /proc/sys/vm/nr_hugepages
0
# 也可以通過下面的方法檢視
root@ubuntu:~# cat /proc/meminfo | grep -i Hugep
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 0 # 大頁的總數為0
HugePages_Free: 0 # 前可用的大頁數
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
# 3. 設定大頁的數量 表示使用2000個2M大小的大頁
echo 2000 > /proc/sys/vm/nr_hugepages
# 掛載大頁
mount -t hugetlbfs nodev /PATH
# 檢視是否正常掛載
cat /proc/mounts | grep hugetlbfs
6、髒資料的回收
髒資料就是對記憶體中已被修改但尚未寫入磁碟的資料進行回收。
髒資料自動回收:
通過修改vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值來調整髒資料回收的時間間隔。
# 髒資料在記憶體中存留的時間,單位為1/100秒
ehigh@master-1:~$ cat /proc/sys/vm/dirty_expire_centisecs
3000
# 髒資料的寫入間隔時間,單位為1/100秒
ehigh@master-1:~$ cat /proc/sys/vm/dirty_writeback_centisecs
500
髒資料手動回收:
使用sync命令將記憶體中的所有髒資料寫回磁碟,以減少資料丟失或損壞的風險。
sync命令會強制將檔案系統中所有修改過的資料快取寫回磁碟,包括髒資料和後設資料。
如何調整髒資料回收的時間:
- 如果追求系統的效能,可以把
vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值改大,減少磁碟IO的操做。 - 如果追求資料的安全性,可以把
vm.dirty_expire_centisecs和vm.dirty_writeback_centisecs的值改小,防止資料丟失。
7、清除快取
當系統記憶體不足時,需要清除快取來釋放記憶體,以確保系統的正常執行,例如當系統記憶體使用率達到80%以上時,可以考慮清除快取。
注意:清空快取可能會導致系統效能下降,因為需要重新從磁碟讀取資料。因此,在清空快取之前,需要仔細考慮清空快取的必要性,並確保系統有足夠的記憶體來重新快取資料。
清空檔案系統快取:
ehigh@ubuntu:~$ sudo sync && echo 3 > /proc/sys/vm/drop_caches
清空記憶體快取:
ehigh@ubuntu:~$ sudo echo 1 > /proc/sys/vm/drop_caches
三:磁碟的優化方法:
1、掛載引數優化
在掛載硬碟時,使用noatime選項可以避免在每次讀取檔案時更新檔案的存取時間,減少磁碟IO操作,提高硬碟效能。在/etc/fstab檔案中新增noatime選項即可。
2、選擇合適的檔案系統
對於大量小檔案的讀寫,使用 ext4 檔案系統可能比使用 XFS 檔案系統更適合。
3、根據不同的場景選擇磁碟排程演演算法
在Linux系統中,磁碟的三種排程演演算法分別為 CFQ、Deadline 和 NOOP
CFQ排程演演算法
Linux系統預設的磁碟排程演演算法,會根據每個程序的優先順序和歷史I/O請求時間來計算每個佇列的權重,然後按照權重順序排程I/O請求。
使用場景:適合多工環境下的桌面系統和伺服器系統。例如Web伺服器、資料庫伺服器
Deadline排程演演算法
將I/O請求分為兩類:實時I/O請求和普通I/O請求。實時I/O請求是指需要立即響應的請求,例如滑鼠、鍵盤輸入等。普通I/O請求是指需要等待一定時間才能得到響應的請求,例如檔案讀寫操作等。
將實時I/O請求插入到佇列頭部,優先處理;對於普通I/O請求,則會設定一個截止時間(deadline),在此之前儘可能地處理請求。
使用場景:適合需要響應速度較快的應用程式,例如實時音視訊應用、遊戲等。
NOOP排程演演算法
一種簡單的排程演演算法,它不會對I/O請求進行排序或排程,而是按照請求的先後順序依次處理。在高負載的情況下,NOOP排程演演算法可以減少CPU的消耗,但是在磁碟較忙的情況下可能會導致響應時間較長。
使用場景:適合低負載的系統,例如桌面系統或者輕負載的伺服器系統。或者SSD磁碟
修改磁碟排程演演算法:/sys/block/<device>/queue/scheduler檔案
例如:
# 1. 編輯核心引數的組態檔
sudo vim /etc/default/grub
# 2. 找到GRUB_CMDLINE_LINUX_DEFAULT行,並在雙引號中新增要修改的核心引數, elevator=cfq表示排程演演算法設定為cfq
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash elevator=cfq"
# 3. 更新GRUB設定
sudo update-grub
$ 4. 重啟系統
sudo reboot
# 注意:核心引數是區分大小寫,寫排程演演算法名稱的時候需要全部小寫
# 例如:
elevator=deadline
elevator=cfq
elevator=noop
# 檢視當前磁碟使用的排程演演算法
root@ecs-1746-0001:/sys/block# cat /sys/block/vda/queue/scheduler
[mq-deadline] none # 方括號中的演演算法名稱表示當前生效的排程演演算法。
4、設定預讀取資料的大小
預設情況下,Linux 核心會自動根據裝置型別和效能來選擇合適的預讀取大小。
通過設定塊裝置的預讀取資料大小/sys/block/vda/queue/read_ahead_kb,以加快讀取速度。
# 磁碟快取的預設大小是128kb
root@ecs-1746-0001:~# cat /sys/block/vda/queue/read_ahead_kb
128
預讀取大小的設定規則:
一般預讀取大小在 64KB 到 256KB 之間是比較合適,如果太小浪費磁碟IO,太大浪費記憶體資源。高速 SSD 裝置,預讀取的大小頁不要超過 1MB。
5、優化磁碟碎片
磁碟碎片是指硬碟上儲存的檔案在寫入和刪除過程中被分割成不連續的片段,使得檔案在硬碟上的物理位置不再是連續的。所以導致磁碟的讀寫速度變慢。
檢視和清理磁碟碎片:
ext4檔案系統:
# 檢視是否存在磁碟碎片
ehigh@ubuntu:~$ sudo dumpe2fs /dev/sda1
# 清理磁碟碎片 清理sda1的磁碟碎片
ehigh@ubuntu:~$ sudo e4defrag /dev/sda1
xfs檔案系統:
# 檢視是否存在磁碟碎片
ehigh@ubuntu:~$ sudo xfs_db -c frag /dev/sda1
# 清理磁碟碎片
ehigh@ubuntu:~$ sudo xfs_fsr /dev/sda1
四:對網路進行優化:
1、調整TCP/IP引數來優化網路
Linux系統預設的TCP/IP引數適用於多數情況,但是對於高負載或者高流量的應用需要調整TCP視窗大小、最大並行連線數、最大傳輸單元(MTU)等引數。
例如:如果需要處理10000個並行連線,可以將這兩個引數設定為10000:
echo "10000" > /proc/sys/net/ipv4/tcp_max_syn_backlog # TCP最大連線數,預設是1024
echo "10000" > /proc/sys/net/core/somaxconn # 最大同步連線數,預設是1024
2、開啟TCP的快速連線機制
在Linux核心版本3.7及以上,TCP快速開啟已經預設啟用。CP快速開啟可以減少TCP三次握手的時間,從而提高連線速度和效能。
例如:
root@ecs-1746-0001:~# echo "2" > /proc/sys/net/ipv4/tcp_fastopen
# 0:禁用TCP Fast Open功能。
# 1:啟用TCP Fast Open使用者端功能,但不啟用伺服器端功能。這是預設值。
# 2:啟用TCP Fast Open使用者端和伺服器端功能。
3、啟用TCP擁塞控制演演算法
例如,Cubic、Reno、BIC等。選擇適合自己應用的擁塞控制演演算法可以提高網路效能和穩定性。
Cubic演演算法:更為適用於高延遲、高頻寬的網路環境
Reno演演算法:適合傳輸速度相對較快,延遲較低,丟包率也較低的網路環境
# 當前系統中可用的TCP擁塞控制演演算法
root@ecs-1746-0001:~# cat /proc/sys/net/ipv4/tcp_available_congestion_control
reno cubic
# 設定TCP擁塞控制演演算法
root@ecs-1746-0001:~# echo 'cubic' > /proc/sys/net/ipv4/tcp_congestion_control
# 持久化設定
root@ecs-1746-0001:~# vim /etc/sysctl.conf
net.ipv4.tcp_congestion_control=cubic
4、調整網路緩衝區大小
Linux系統預設的網路緩衝區大小適用於大多數情況,但是對於高負載或者高流量的應用,需要調整增大通訊端緩衝區大小、讀寫緩衝區大小等。
例如:如果需要處理大量的網路流量,可以將這些引數設定為較大的值
echo "16777216" > /proc/sys/net/core/wmem_max
echo "16777216" > /proc/sys/net/core/rmem_max
echo "16777216" > /proc/sys/net/core/optmem_max
5、禁用IPv6
如果沒有使用IPv6,禁用IPv6協定,從而減少網路連線的負載。
禁用IPV6:
root@ecs-1746-0001:~# vim /etc/sysctl.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
root@ecs-1746-0001:~# sysctl -p
6、TCP視窗大小
通過修改視窗的大小,提升網路的傳輸速度和網路效能。
例如:
sudo vim /etc/sysctl.conf
net.ipv4.tcp_window_scaling = 1 # 啟用TCP視窗擴充套件功能
net.ipv4.tcp_rmem = 4096 131072 6291456 # 最小值、預設值和最大值
net.ipv4.tcp_wmem = 4096 16384 4194304
7、調整連線佇列和最大連線數
如果TCP的連線佇列太小,就會導致使用者端連線請求被拒絕,如果連線佇列太大,就會佔用過多的記憶體資源
如果TCP的最大連線數設定得太低,會導致系統無法支援足夠的並行連線,從而導致系統響應變慢或者連線超時。
調整TCP的連線佇列和最大連線數:
# 檢視當前系統的最大連線數:
# 檢視當前的TCP最大連線數是否接近系統的最大連線數,如果接近就修改為一個更大的值。
ss -n | grep tcp | grep ESTABLISHED | wc -l
# 檢視TCP的最大連線數 預設TCP的最大連線數是256
ehigh@ubuntu:~$ cat /proc/sys/net/core/somaxconn
256
# 設定TCP的最大連線數
ehigh@ubuntu:~$ sudo sysctl -w net.core.somaxconn=2048
# 設定TCP的連線佇列 一般設定為最大連線數的兩倍
sysctl -w net.core.somaxconn=1024