AI 大戰 AI,一個深度強化學習多智慧體競賽系統
小夥伴們快看過來!這是一款全新打造的 ⚔️ AI vs. AI ⚔️——深度強化學習多智慧體競賽系統。
這個工具託管在 Space 上,允許我們建立多智慧體競賽。它包含三個元素:
- 一個帶匹配演演算法的 Space,使用後臺任務執行模型戰鬥。
- 一個包含結果的 Dataset。
- 一個獲取匹配歷史結果和顯示模型 LEO 的 Leaderboard。
然後,當用戶將一個訓練好的模型推到 Hub 時,它會獲取評估和排名。得益於此,我們可以在多智慧體環境中對你的智慧體與其他智慧體進行評估。
除了作為一個託管多智慧體競賽的有用工具,我們認為這個工具在多智慧體設定中可以成為一個 健壯的評估技術。通過與許多策略對抗,你的智慧體將根據廣泛的行為進行評估。這應該能讓你很好地瞭解你的策略的質量。
讓我們看看它在我們的第一個競賽託管: SoccerTwos Challenge 上是如何工作的。
AI vs. AI是怎麼工作的?
AI vs. AI 是一個在 Hugging Face 上開發的開源工具,對多智慧體環境下強化學習模型的強度進行排名。
其思想是通過讓模型之間持續比賽,並使用比賽結果來評估它們與所有其他模型相比的表現,從而在不需要經典指標的情況下了解它們的策略質量,從而獲得 對技能的相對衡量,而不是客觀衡量。
對於一個給定的任務或環境,提交的智慧體越多,評分就越有代表性。
為了在一個競爭的環境裡基於比賽結果獲得評分,我們決定根據 ELO 評分系統進行排名。
遊戲的核心理念是,在比賽結束後,雙方玩家的評分都會根據比賽結果和他們在比賽前的評分進行更新。當一個擁有高評分的使用者打敗一個擁有低排名的使用者時,他們便不會獲得太多分數。同樣,在這種情況下,輸家也不會損失很多分。
相反地,如果一個低評級的玩家擊敗了一個高評級的玩家,這將對他們的評級產生更顯著的影響。
在我們的環境中,我們儘量保持系統的簡單性,不根據玩家的初始評分來改變獲得或失去的數量。因此,收益和損失總是完全相反的 (例如+10 / -10),平均 ELO 評分將保持在初始評分不變。選擇一個1200 ELO 評分啟動完全是任意的。
如果你想了解更多關於 ELO 的資訊並且檢視一些計算範例,我們在 深度強化學習課程 裡寫了一個解釋。
使用此評級,可以 自動在具有可對比強度的模型之間進行匹配。你可以有多種方法來建立匹配系統,但在這裡我們決定保持它相當簡單,同時保證比賽的多樣性最小,並保持大多數比賽的對手評分相當接近。
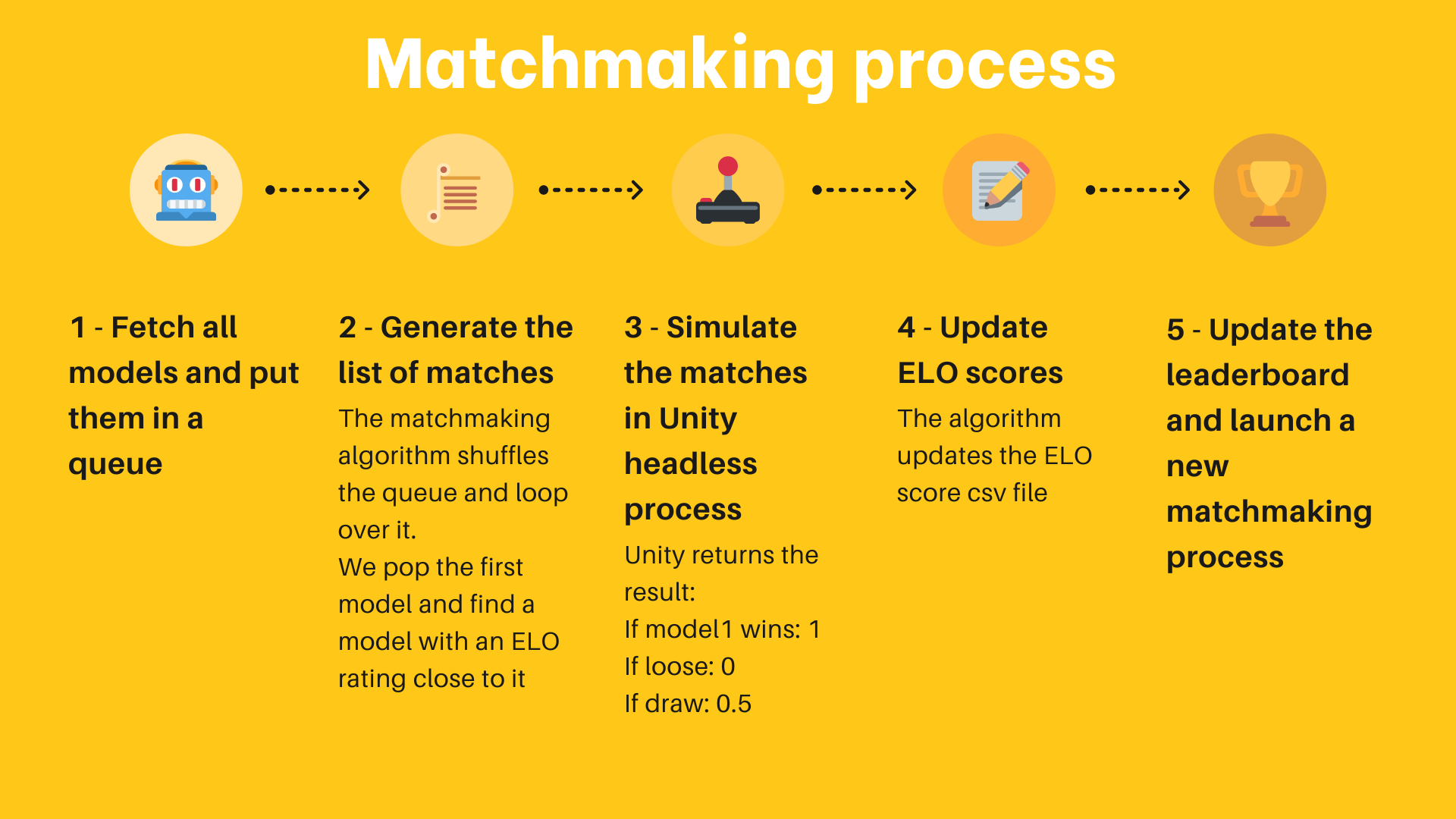
以下是該演演算法的工作原理:
- 從 Hub 上收集所有可用的模型。新模型獲得初始 1200 的評分,其他的模型保持在以前比賽中得到或失去的評分。
- 從所有這些模型建立一個佇列。
- 從佇列中彈出第一個元素 (模型),然後從 n 個模型中隨機抽取另一個與第一個模型評級最接近的模型。
- 通過在環境中 (例如一個 Unity 可執行檔案) 載入這兩個模型來模擬這個比賽,並收集結果。對於這個實現,我們將結果傳送到 Hub上的 Hug Face Dataset。
- 根據收到的結果和 ELO 公式計算兩個模型的新評分。
- 繼續兩個兩個地彈出模型並模擬比賽,直到佇列中只有一個或零個模型。
- 儲存結果評分,回到步驟 1。
為了持續執行這個配對過程,我們使用 免費的 Hug Face Spaces 硬體和一個 Scheduler 來作為後臺任務持續執行這個配對過程。
Space 還用於獲取每個以及比賽過的模型的 ELO 評分,並顯示一個排行榜,每個人都可以檢查模型的進度。
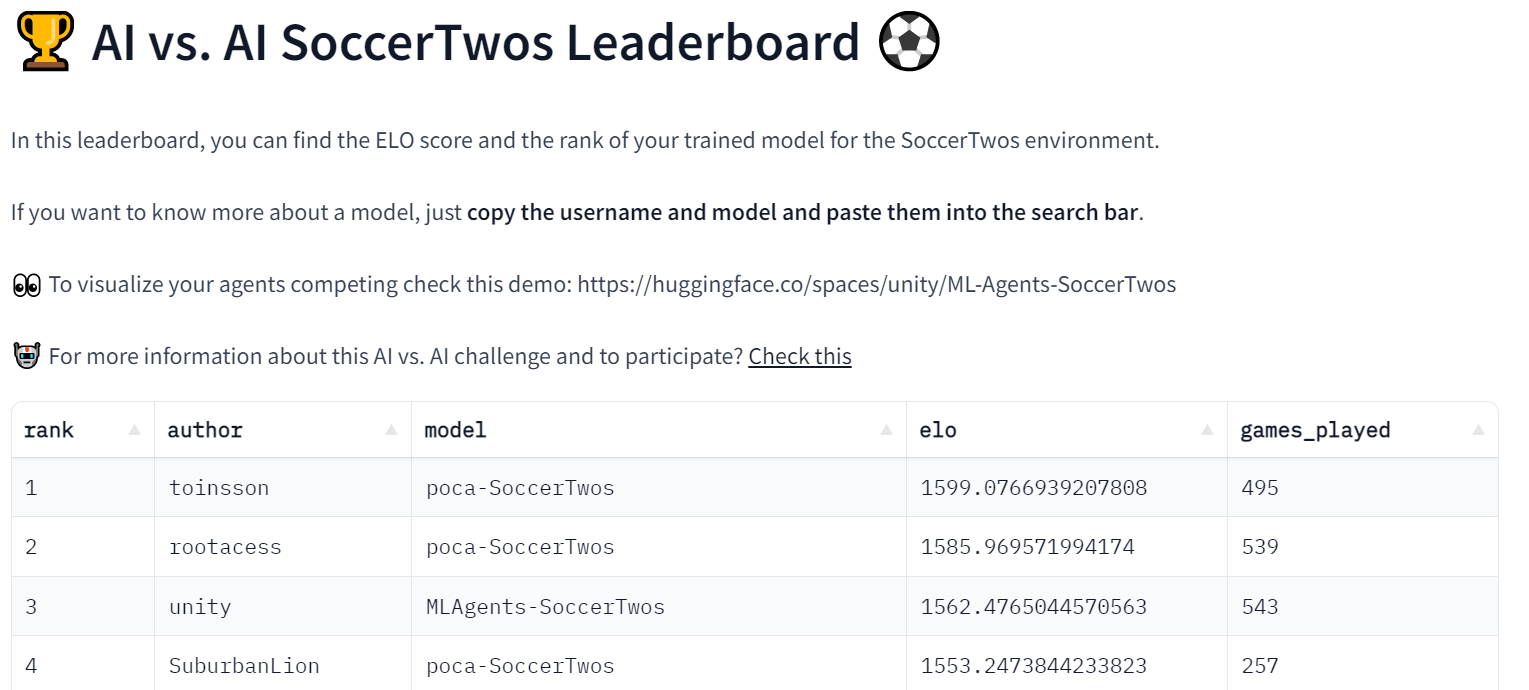
該過程通常使用幾個 Hugging Face Datasets 來提供資料永續性 (這裡是匹配歷史和模型評分)。
因為這個過程也儲存了比賽的歷史,因此可以精確地看到任意給定模型的結果。例如,這可以讓你檢查為什麼你的模型與另一個模型搏鬥,最顯著的是使用另一個演示 Space 來視覺化匹配,就像 這個。
目前,這個實驗是在 MLAgent 環境 SoccerTwos 下進行的,用於 Hugging Face 深度強化學習課程,然而,這個過程和實現通常是 環境無關的,可以用來免費評估廣泛的對抗性多智慧體設定。
當然,需要再次提醒的是,此評估是提交的智慧體實力之間的相對評分,評分本身 與其他指標相比沒有客觀意義。它只表示一個模型與模型池中其他模型相對的好壞。儘管如此,如果有足夠大且多樣化的模型池 (以及足夠多的比賽),這種評估將成為表示模型一般效能的可靠方法。
我們的第一個 AI vs. AI 挑戰實驗: SoccerTwos Challenge ⚽
這個挑戰是我們免費的深度強化學習課程的第 7 單元。它開始於 2 月 1 日,計劃於 4 月 30 日結束。
如果你感興趣,你不必參加課程就可以加入這個比賽。你可以在 這裡 開始
在這個單元,讀者通過訓練一個 2 vs 2 足球隊 學習多智慧體強化學習 (MARL) 的基礎。
用到的環境是 Unity ML-Agents 團隊製作的。這個比賽的目標是簡單的: 你的隊伍需要進一個球。要做到這一點,他們需要擊敗對手的團隊,並與隊友合作。

除了排行榜,我們建立了一個 Space 演示,人們可以 選擇兩個隊伍並視覺化它們的比賽。
這個實驗進展順利,因為我們已經在 排行榜 上有 48 個模型了。
我們也創造了一個叫做 ai-vs-ai-competition 的 discord 頻道,人們可以與他人交流並分享建議。
結論,以及下一步
因為我們開發的這個工具是 環境無關的,在未來我們想用 PettingZoo 舉辦更多的挑戰賽和多智慧體環境。如果你有一些想做的環境或者挑戰賽,不要猶豫,與我們聯絡。
在未來,我們將用我們創造的工具和環境來舉辦多個多智慧體比賽,例如 SnowballFight。
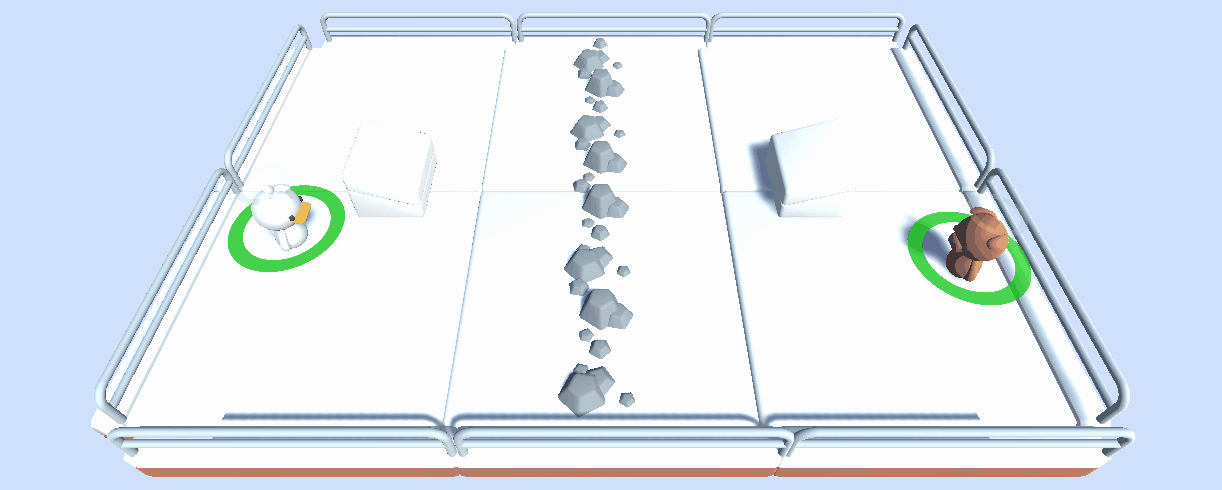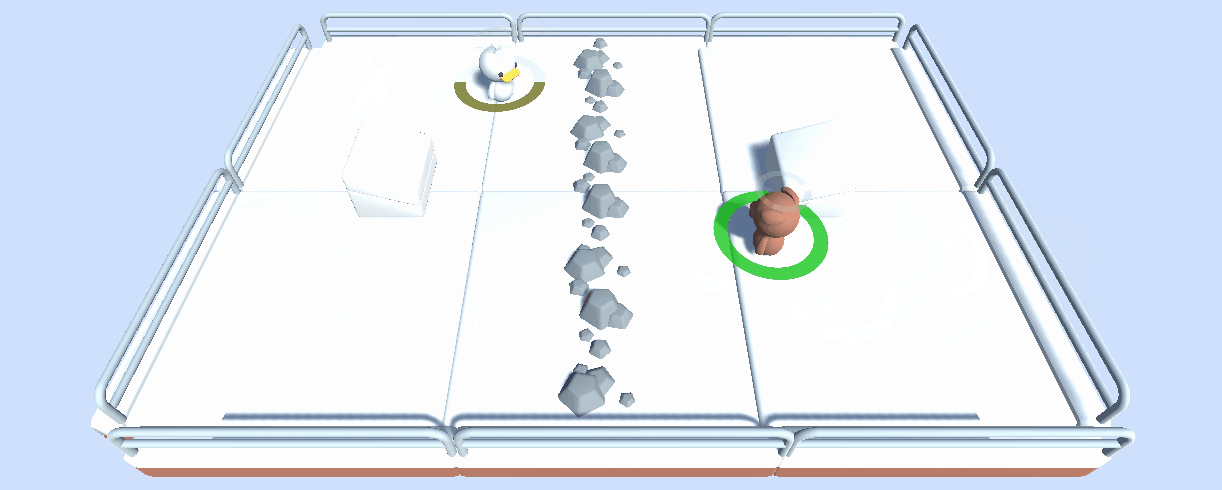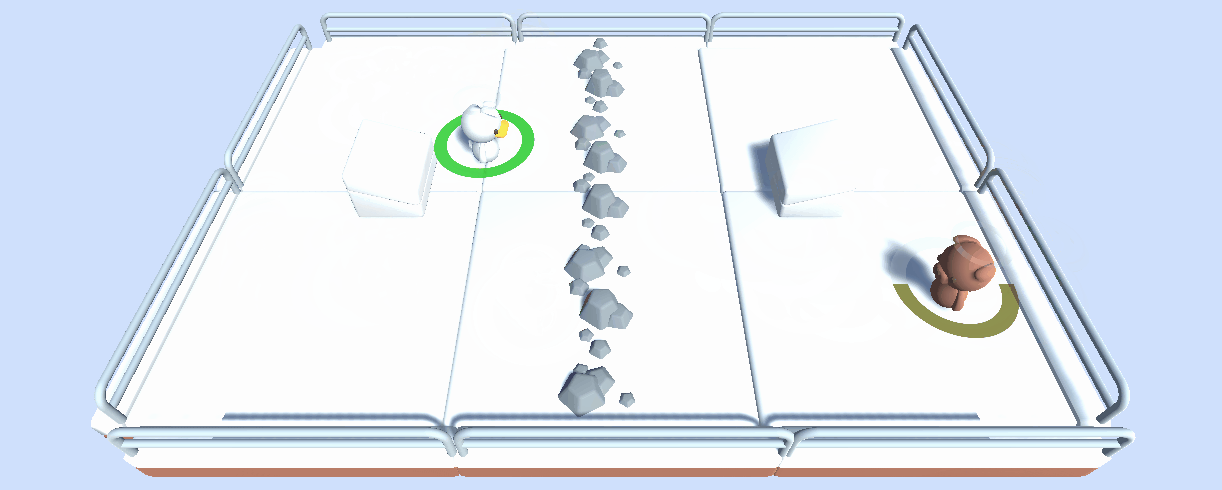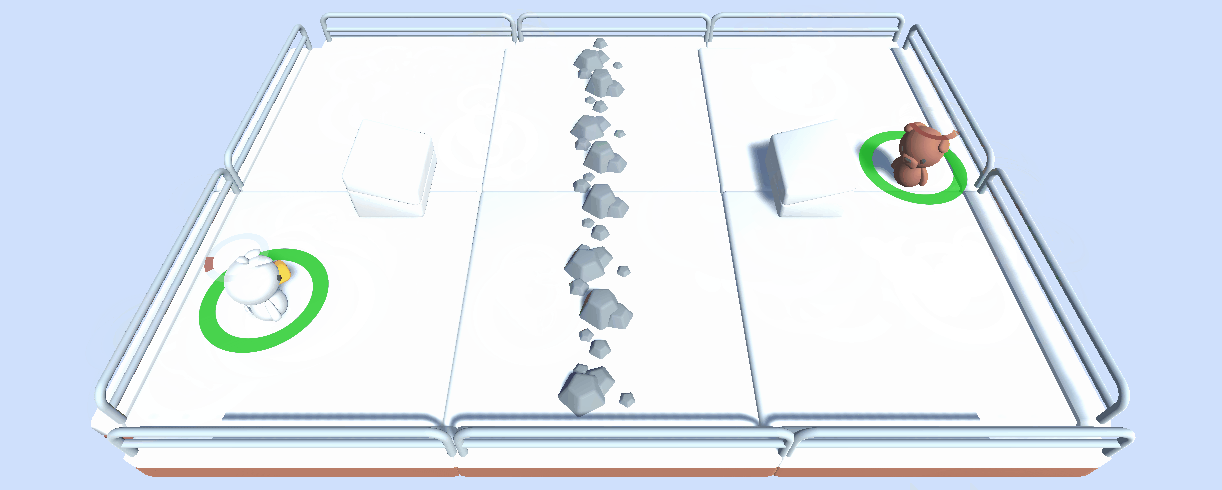
除了稱為一個舉辦多智慧體比賽的有用工具,我們考慮這個工具也可以在多智慧體設定中成為 一項健壯的評估技術: 通過與許多策略對抗,你的智慧體將根據廣泛的行為進行評估,並且你將很好地瞭解你的策略的質量。
保持聯絡的最佳方式是加入我們的 Discord與我們和社群進行交流。
參照
參照: 如果你發現這對你的學術工作是有用的,請考慮參照我們的工作:
Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.
BibTeX 參照:
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}
英文原文: https://huggingface.co/blog/aivsai
作者: Carl Cochet、Thomas Simonini
譯者: AIboy1993 (李旭東)
審校、排版: zhongdongy (阿東)