一次排查某某雲上的redis讀超時經歷
一次排查某某雲上的redis讀超時經歷
問題背景
最近一兩天線上老是偶現的redis讀超時報警,我嗅到了一絲不正常的味道,但由於業務繁忙,只是暫時將超時時間從200ms調變500ms,超時情況減少了,不過還是有發生。趁業務空閒期,於是開始著手排查。
排查思路
查閱 redis 慢查詢紀錄檔
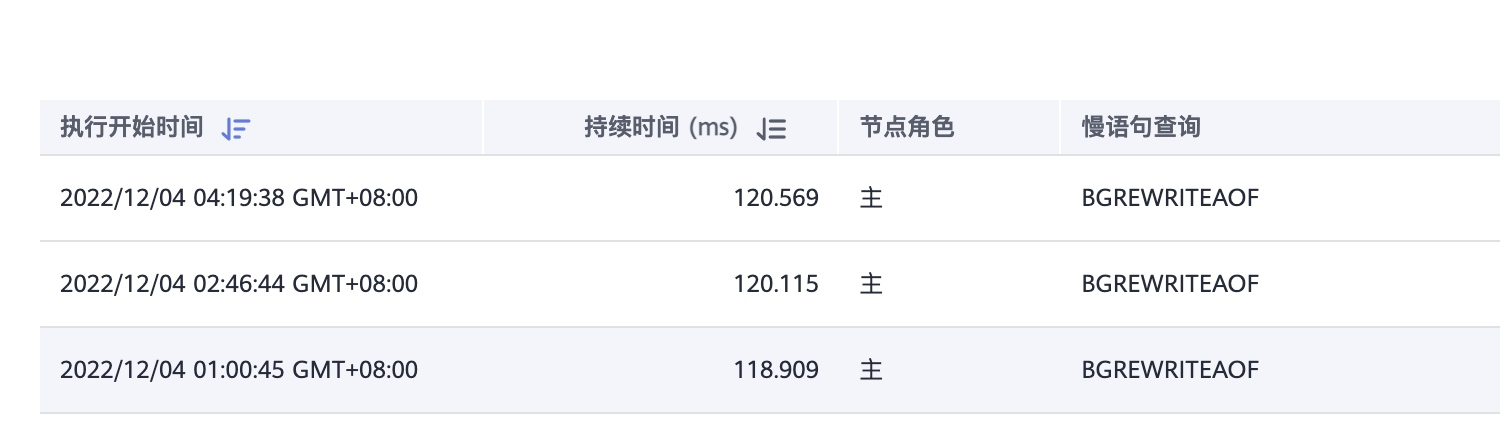
redis的慢查詢閥值是10ms,唯一的慢查詢是備份時的bgrewriteaof語句,慢查詢很正常。
檢查 報警期間 redis 各項負載指標
由於超時報警時,剛好也是我們業務低峰期,看了下各項監控指標,cpu,記憶體,qps等等,毫無意外的正常。
檢查報警期間 ecs伺服器的各項指標資料
cpu,記憶體,頻寬等等也是正常且處於較低水平。
排查到這裡,重新思考慢查詢紀錄檔究竟是什麼?
慢查詢記錄的真的是redis命令執行的所有時間嗎?redis命令完整的執行過程究竟是怎樣的?
慢查詢紀錄檔僅僅是記錄了命令的執行時間,而整個redis命令的生命週期是這樣。
使用者端命令傳送->redis伺服器接收到命令,放入佇列排隊執行->命令執行->返回給使用者端結果
那麼有沒有辦法監控到redis的延遲呢?如何才能知道redis的命令慢不是因為執行慢,而是這個過程當中的其他流程慢導致的呢?
redis 提供了監控延遲的工具
開啟延遲,設定延遲閥值
CONFIG SET latency-monitor-threshold 100
查閱延遲原因
latency latest
但是這個工具真正實踐起來的效果並不能讓我滿意,因為似乎他並不能把網路因素考慮其中,實踐起來的效果它應該是隻能將命令執行過程中可能導致延遲的原因分析出來,但是執行前以及執行後的命令生命週期的階段並沒有考慮進去。
當我開啟這個工具監控線上redis情況,當又有讀超時出現時,latency latest 並沒有返回任何延遲異常。
再思考究竟讀超時是個什麼問題?
使用者端發出去了命令,然後阻塞等待redis伺服器端讀的結果,如果沒有結果返回,就會觸發讀超時發生。在go裡面程式碼是如何實現的。
func (c *baseClient) pipelineProcessCmds(cn *pool.Conn, cmds []Cmder) (bool, error) {
err := cn.WithWriter(c.opt.WriteTimeout, func(wr *proto.Writer) error {
return writeCmd(wr, cmds...)
})
if err != nil {
setCmdsErr(cmds, err)
return true, err
}
// 看到將讀取操作用WithReader裝飾了一下
err = cn.WithReader(c.opt.ReadTimeout, func(rd *proto.Reader) error {
return pipelineReadCmds(rd, cmds)
})
return true, err
}
// 讀取之前設定了超時時間
_ = cn.setReadTimeout(timeout)
return fn(cn.rd)
可以看到,如果在規定時間內,結果沒有全部返回也會導致讀超時的發生,那麼會不會是由於返回結果過多導致讀取耗時驗證呢?
具體的分析了下報警出錯的命令,有些命令比如set命令不需要返回結果都有超時的情況,所以排除掉了返回結果過大的問題。
再次深入思考golang 裡的讀超時觸發過程
go協程在碰到網路讀取時,協程會掛起,等待網路包到達後,由go runtime喚醒,繼續處理,當喚醒時會檢查超時時間,如果到達了超時限制,那麼將直接報讀超時。(這部分可看原始碼自行驗證)
從喚醒到協程被排程執行的這個時間稱為協程的排程延遲,如果這個延遲過高,那麼是有可能發生讀超時的。
如何驗證?
線上用了一個即使看最多最近15min的go協程排程延遲的工具包,github.com/arl/statsviz 可看15分鐘前的go程序cpu,記憶體,協程排程延遲,gc stw造成的延遲時間。
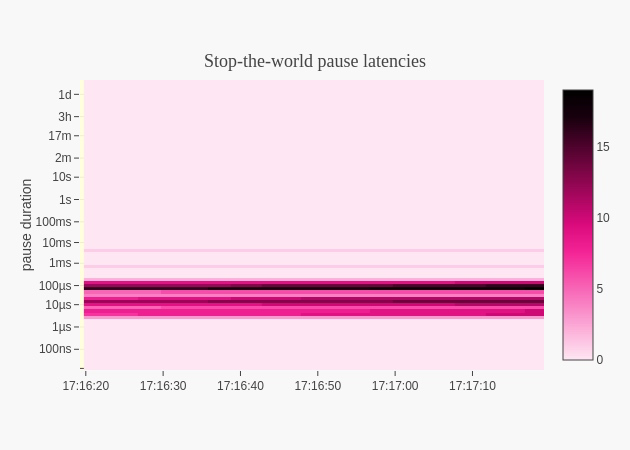
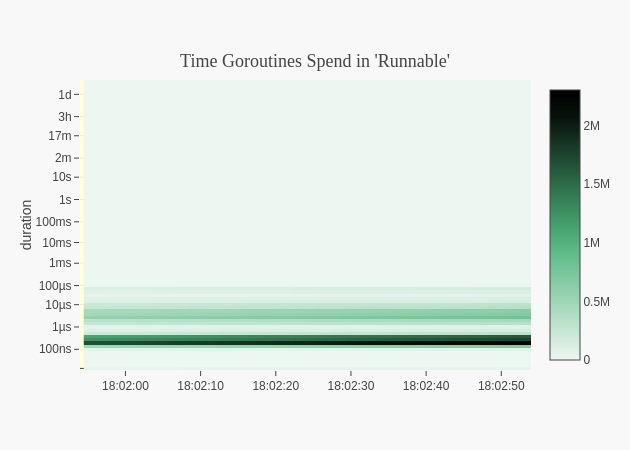 當超時發生時,我看了延遲時間,都在幾ms以內,比起超時設定的500ms,遠遠沒有達到,顯然也不是程式協程排程延遲導致的。
當超時發生時,我看了延遲時間,都在幾ms以內,比起超時設定的500ms,遠遠沒有達到,顯然也不是程式協程排程延遲導致的。
用上終極武器-抓包
以上的思路都行不通了,所以最後我抓包了,為了看看超時究竟是哪些包沒有到達。
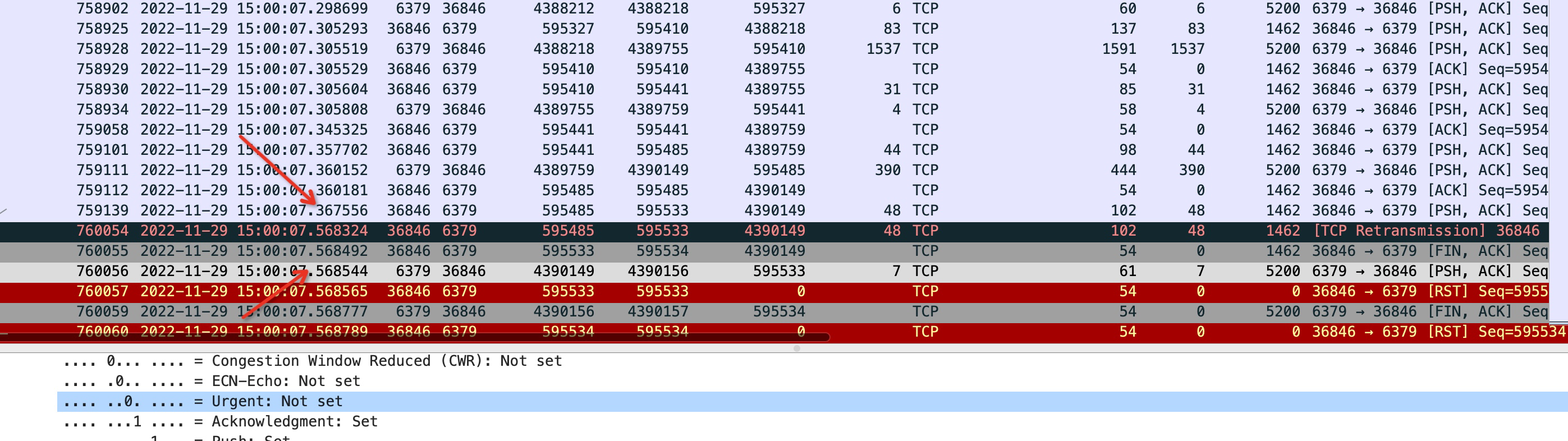
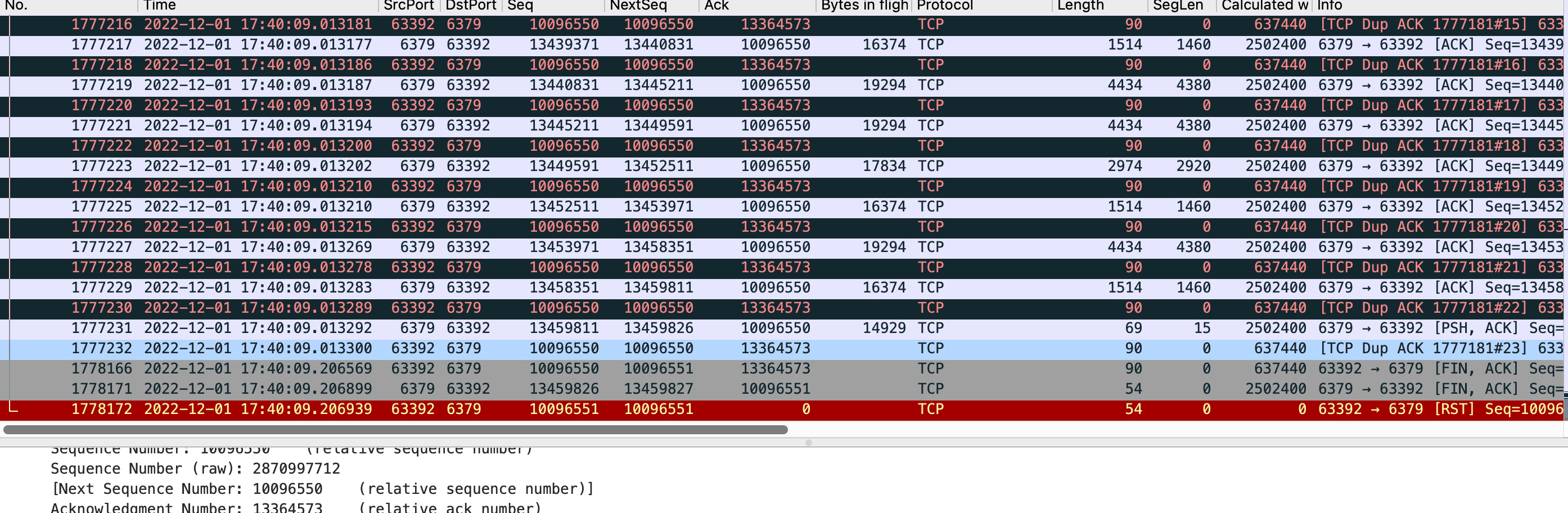
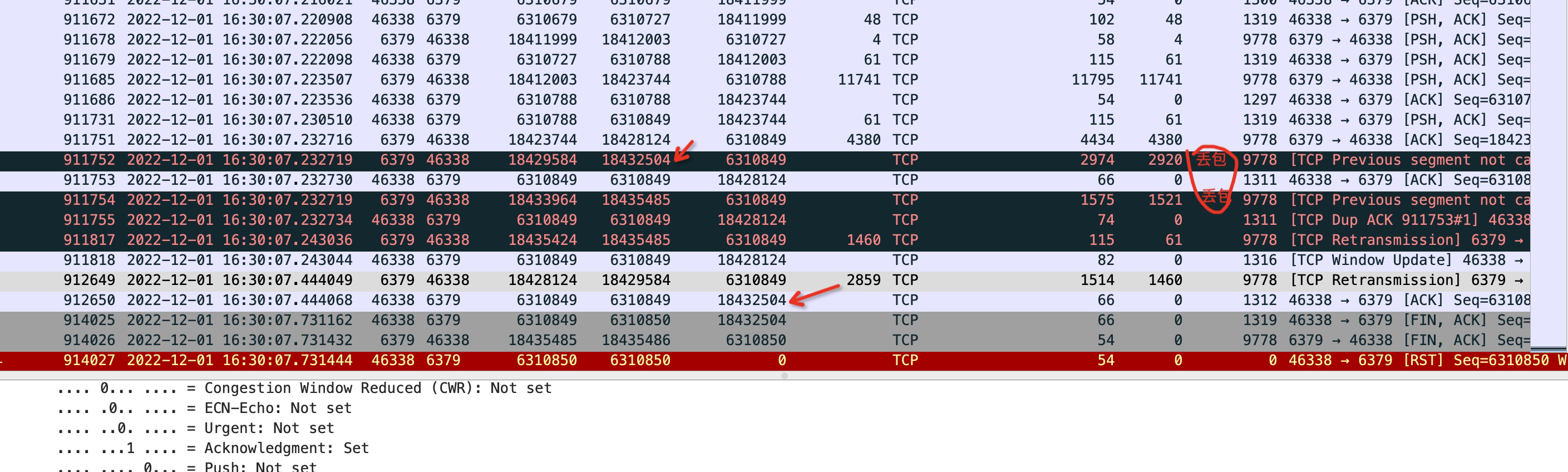
看到現在,我有了充足的理由相信,是雲服務提供商那邊的問題,中間由於網路丟包的原因,且延遲較大導致了redis的讀超時。拿著這些證據也說服了他們,並最終圓滿解決。
提工單,雲服務商的排查支援
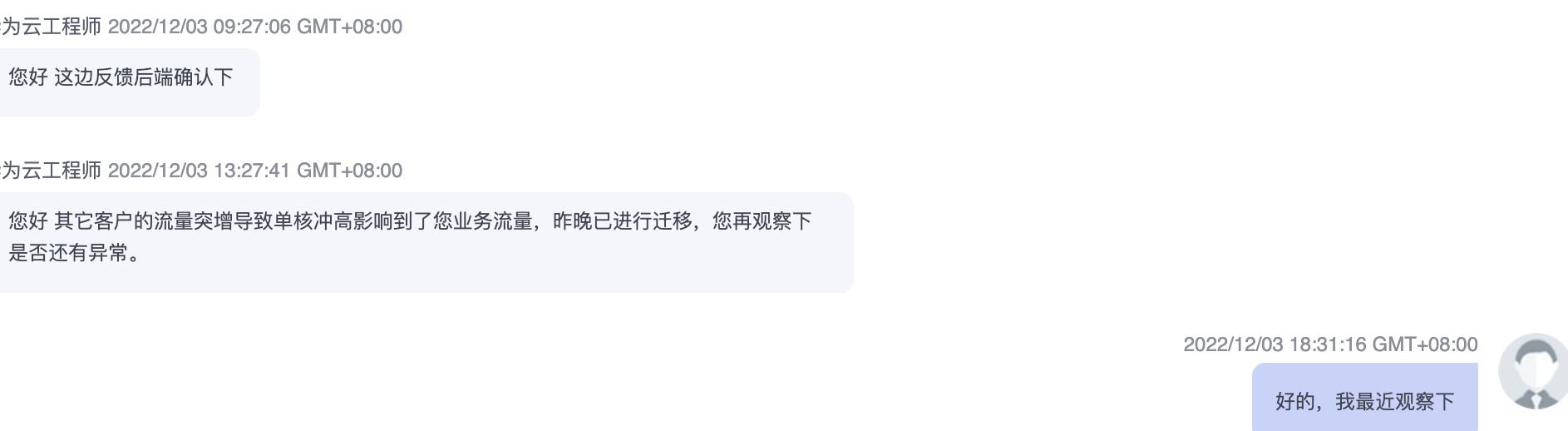
圓滿解決