配運基礎資料快取瘦身實踐
作者:京東物流 張仲良
一、背景:
在現代物流的實際作業流程中,會有大量關係到運營相關資訊的資料產生,如商家,車隊,站點,分揀中心,客戶等等相關的資訊資料,這些資料直接支撐齊了物流的整個業務流轉,具有十分重要的地位,那麼對於這一類資料我們需要提供基本的增刪改查存的能力,目前京東物流的基礎資料是由中臺配運組來整體負責。
在基礎資料的常規能力當中,資料的存取是最基礎也是最重要的能力,為了整體提高資料的讀取能力,快取技術在基礎資料的場景中得到了廣泛的使用,下面會重點展示一下配運組近期針對資料快取做的瘦身實踐。
二、方案:
這次優化我們挑選了商家基礎資料和C後臺2個系統進行了快取資料的優化試點,從結果看取得了非常顯著的成果,節省了大量的硬體資源成本,下面的資料是優化前後的快取使用情況對比:
商家基礎資料Redis資料量由45G降為8G;
C後臺Redis資料量由132G降為7G;
從結果看這個優化的力度太大了,相信大家對如何實現的更加好奇了,那接下來就讓我們一步步來看是如何做到的吧!
首先目前的商家基礎資料使用@Caceh註解元件作為快取方式,它會將從db中查出的值放入本地快取及jimdb中,由於該元件早期的版本沒有jimdb的預設過期時間且使用註解時也未顯式宣告,造成早期大量的key沒有過期時間,從而形成了大量的殭屍key。
所以如果我們可以找到這些殭屍key並進行優化,那麼就可以將快取進行一個整體的瘦身,那首先要怎麼找出這些key呢?
2.1 keys命令
可能很多同學會想到簡單粗暴的keys命令,遍歷出所有的key依次判斷是否有過期時間,但Redis是單執行緒執行,keys命令會以阻塞的方式執行,遍歷方式實現的複雜度是O(n),庫中的key越多,阻塞的時間會越長,通常我們的資料量都會在幾十G以上,顯然這種方式是無法接受的。
2.2 scan命令
redis在2.8版本提供了scan命令,相較於keys命令的優勢:
- scan命令的時間複雜度雖然也是O(N),但它是分次進行的,不會阻塞執行緒。
- scan命令提供了類似sql中limit引數,可以控制每次返回結果的最大條數。
當然也有缺點:
- 返回的資料有可能會重複,至於原因可以看文章最後的擴充套件部分。
- scan命令只保證在命令開始執行前所有存在的key都會被遍歷,在執行期間新增或刪除的資料,是不確定的即可能返回,也可能不返回。
2.3基本語法
目前看來這是個不錯的選擇,讓我們來看下命令的基本語法:
SCAN cursor [MATCH pattern] [COUNT count]
- cursor:遊標
- pattern:匹配的模式
- count:指定從資料集裡返回多少元素,預設值為10
2.4 實踐
首先感覺上就是根據遊標進行增量式迭代,讓我們實際操作下:
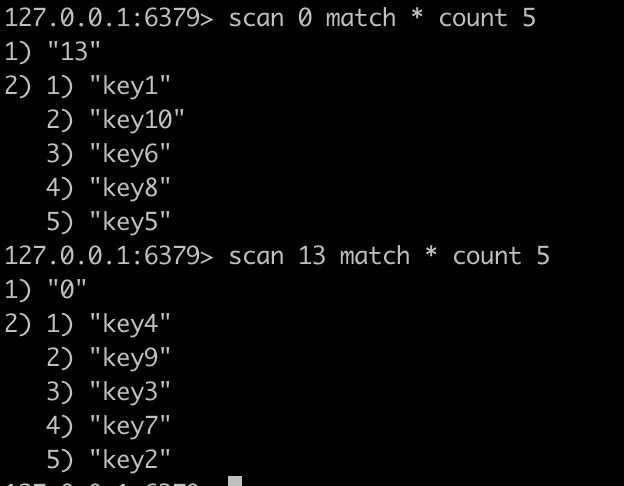
看來我們只需要設定好匹配的key的字首,迴圈遍歷刪除key即可。
可以通過Controller或者呼叫jsf介面來觸發,使用雲redis-API,demo如下:
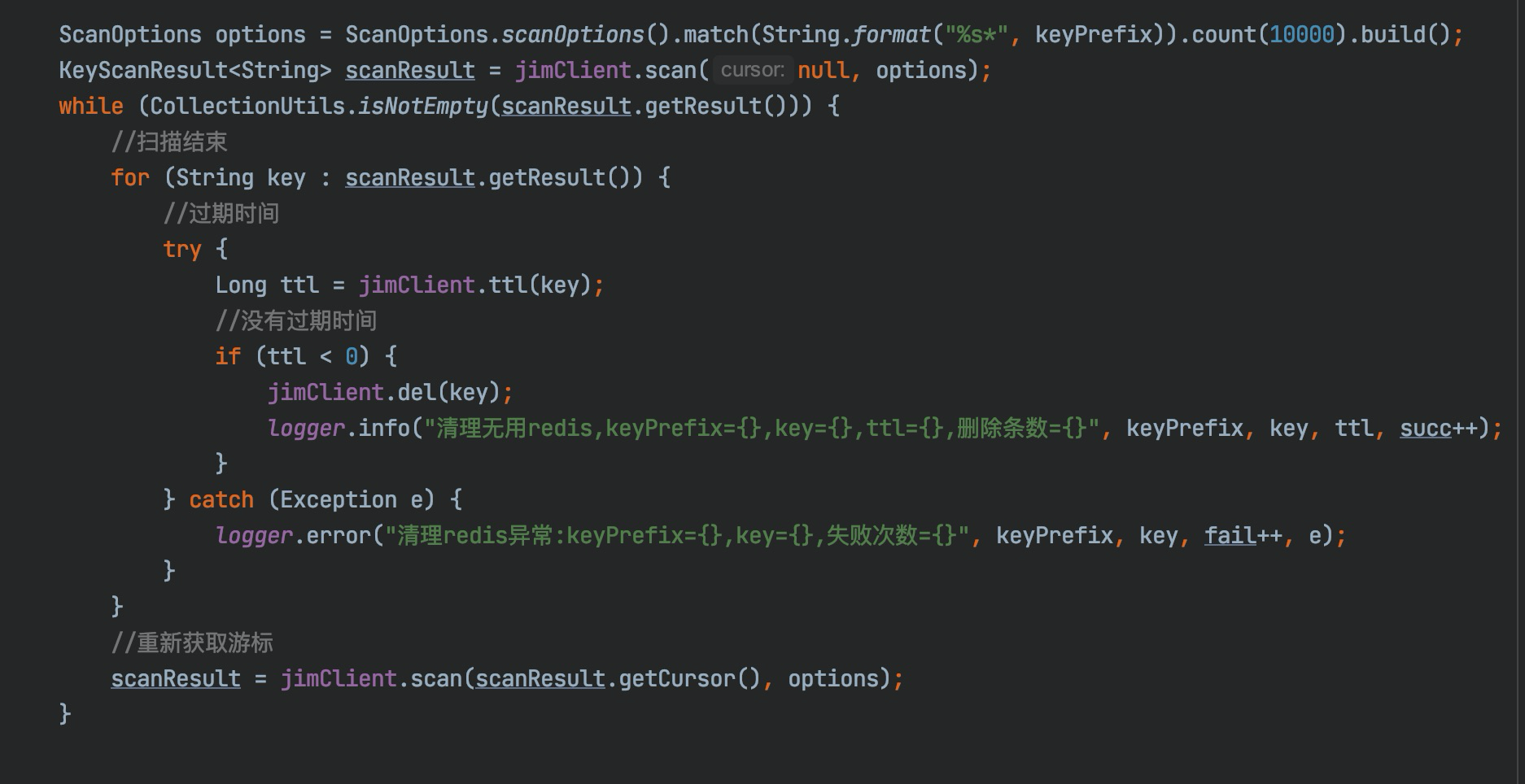
好的,大功告成.在管理端執行randomkey命令檢視.發現依然存在大量的無用key,貌似還有不少漏網之魚,這裡又是怎麼回事呢?
下面又到了喜聞樂見的踩坑環節。
2.5 避坑指南
通過增加日發現,返回的結果集為空,但遊標並未結束!
其實不難發現scan命令跟我們在資料庫中按條件分頁查詢是有別的,mysql是根據條件查詢出資料,scan命令是按字典槽數依次遍歷,從結果中再匹配出符合條件的資料返回給使用者端,那麼很有可能在多次的迭代掃描時沒有符合條件的資料。
我們修改程式碼使用scanResult.isFinished()方法判斷是否已經迭代完成。
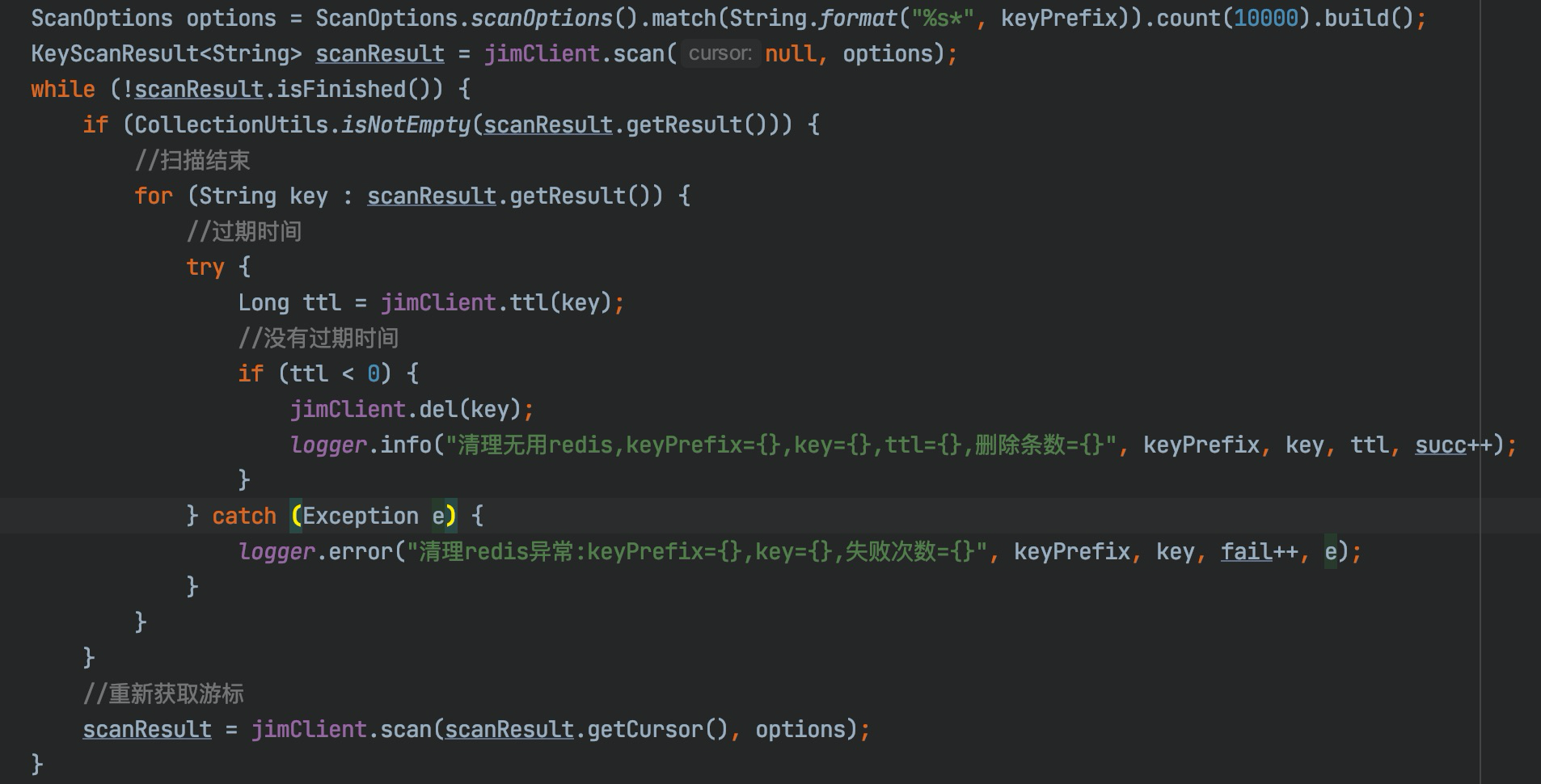
至此程式執行正常,之後通過傳入不同的匹配字元,達到清楚快取的目的。
三、課後擴充套件
這裡我們探討重複資料的問題:為什麼遍歷出的資料可能會重複?
3.1 重複的資料
首先我們看下scan命令的遍歷順序:
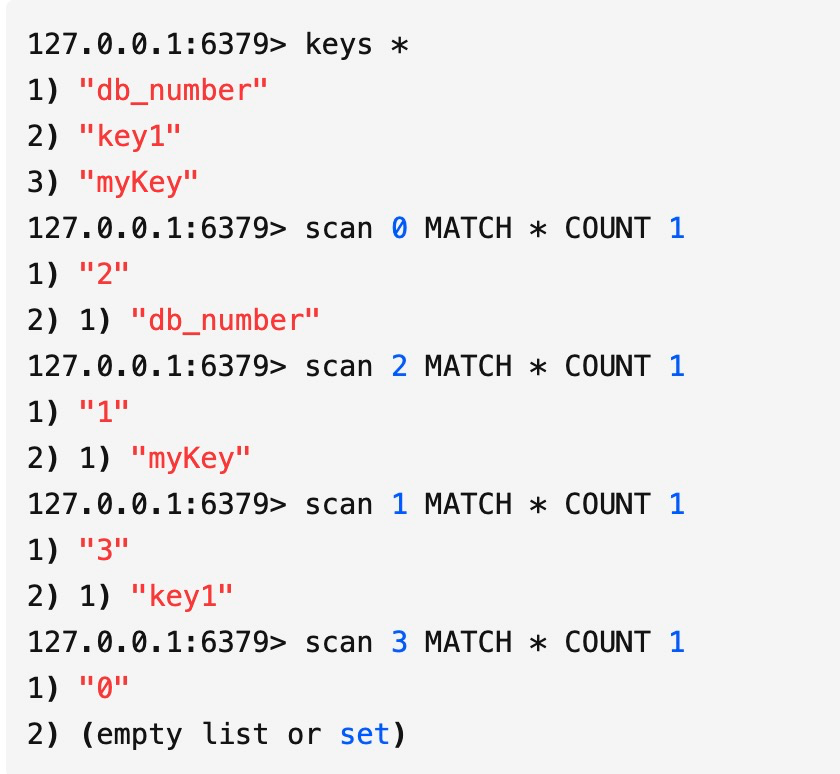
Redis中有3個key,我們用scan命令檢視發現遍歷順為0->2->1->3,是不是感到奇怪,為什麼不是按0->1->2->3的順序?
我們都知道HashMap中由於存在hash衝突,當負載因子超過某個閾值時,出於對連結串列效能的考慮會進行Resize操作.Redis也一樣,底層的字典表會有動態變換,這種掃描順序也是為了應對這些複雜的場景。
3.1.1 字典表的幾種狀態及使用順序掃描會出現的問題
-
字典表沒有擴容
欄位tablesize保持不變,順序掃描沒有問題 -
字典表已擴容完成
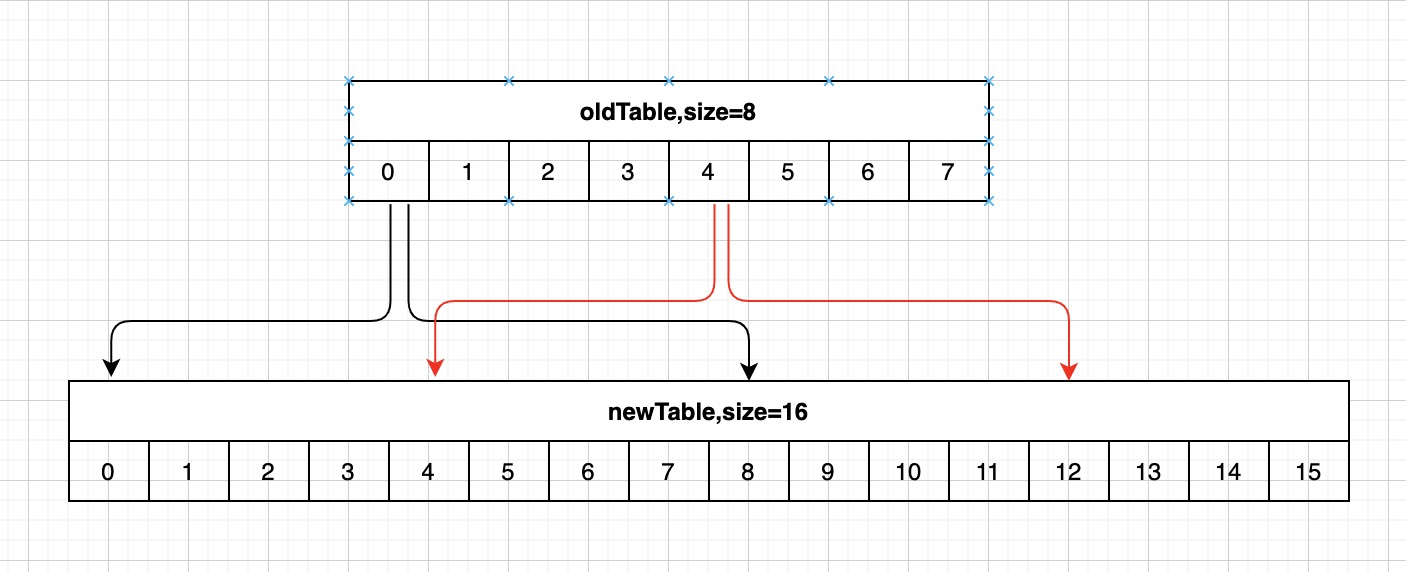
假設字典tablesize從8變為16,之前已經存取過3號桶,現在03號桶的資料已經rehash到811號桶,若果按順序繼續存取4~15號桶,那麼這些元素就重複遍歷了。
- 字典表已縮容完成
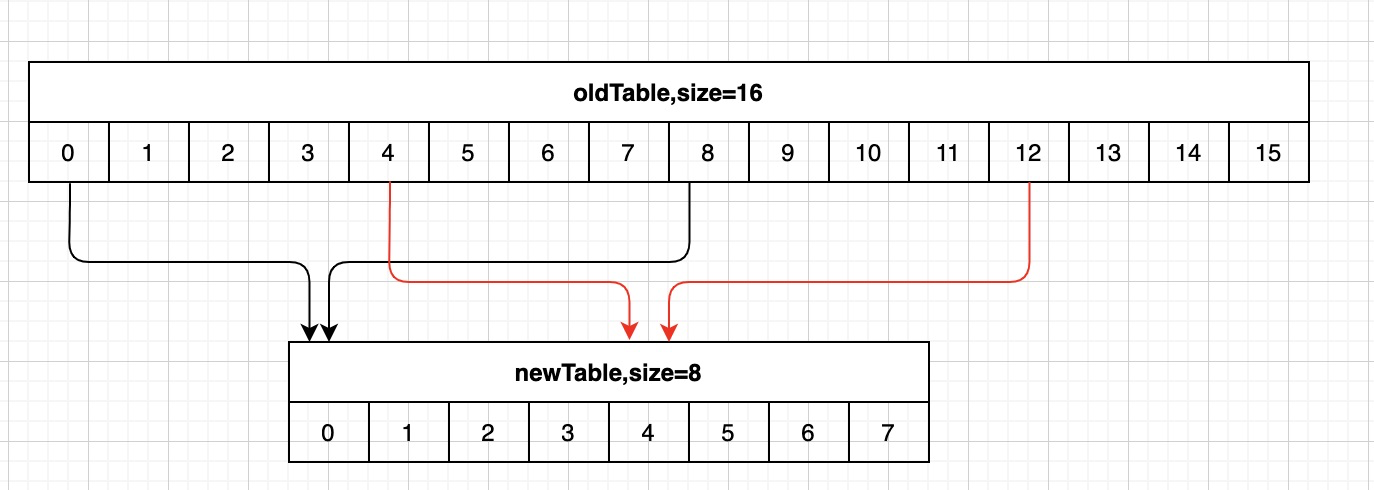
假設字典tablesize從16縮小到8,同樣已經存取過3號桶,這時8~11號桶的元素被rehash到0號桶,若按順序存取,則遍歷會停止在7號桶,則這些資料就遺漏掉了。
- 字典表正在Rehashing
Rehashing的狀態則會出現以上兩種問題即要麼重複掃描,要麼遺漏資料。
3.1.2 反向二進位制迭代器演演算法思想
我們將Redis掃描的遊標與順序掃描的遊標轉換成二進位制作對比:
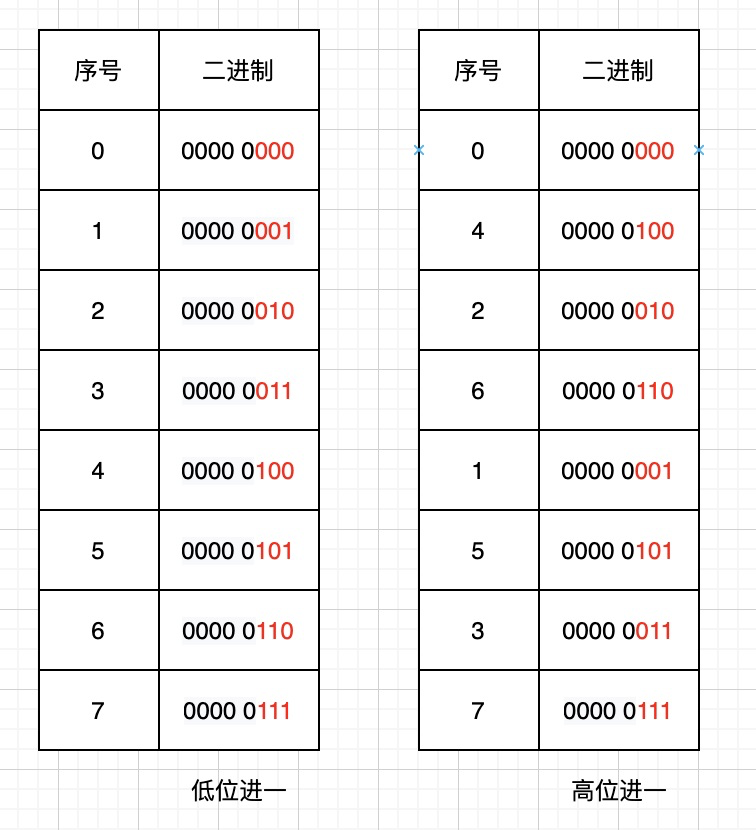
高位順序存取是按照字典sizemask(掩碼),在有效位上高位加1。
舉個例子,我們看下Scan的掃描方式:
1.字典tablesize為8,遊標從0開始掃描;
2.返回使用者端的遊標為6後,字典tablesize擴容到之前的2倍,並且完成Rehash;
3.使用者端傳送命令scan 6;
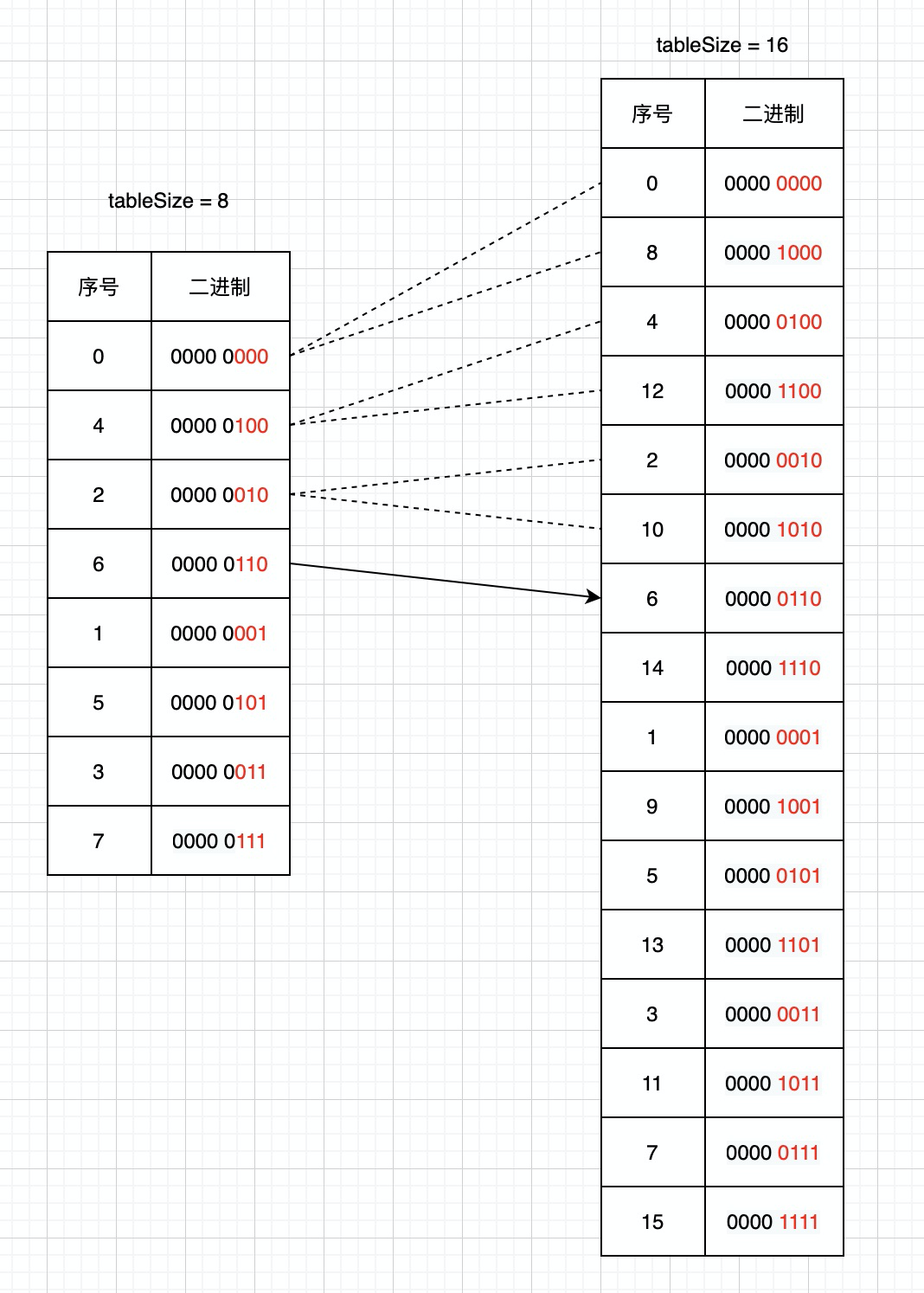
這時scan命令會將6號桶中連結串列全部取出返回使用者端,並且將當前遊標的二進位制高位加一計算出下次迭代的起始遊標.通過上圖我們可以發現擴容後8,12,10號槽位的資料是從之前0,4,2號槽位遷移過去的,這些槽位的資料已經遍歷過,所以這種遍歷順序就避免了重複掃描。
字典擴容的情況類似,但重複資料的出現正是在這種情況下:
還以上圖為例,再看下縮容時Scan的掃描方式:
1.字典tablesize的初始大小為16,遊標從0開始掃描;
2.返回使用者端的遊標為14後,字典tablesize縮容到之前的1/2,並完成Rehash;
3.使用者端傳送命令scan 14;
這時字典表已完成縮容,之前6和14號桶的資料已經Rehash到新表的6號桶中,那14號桶都沒有了,要怎麼處理呢?我們繼續在原始碼中找答案:
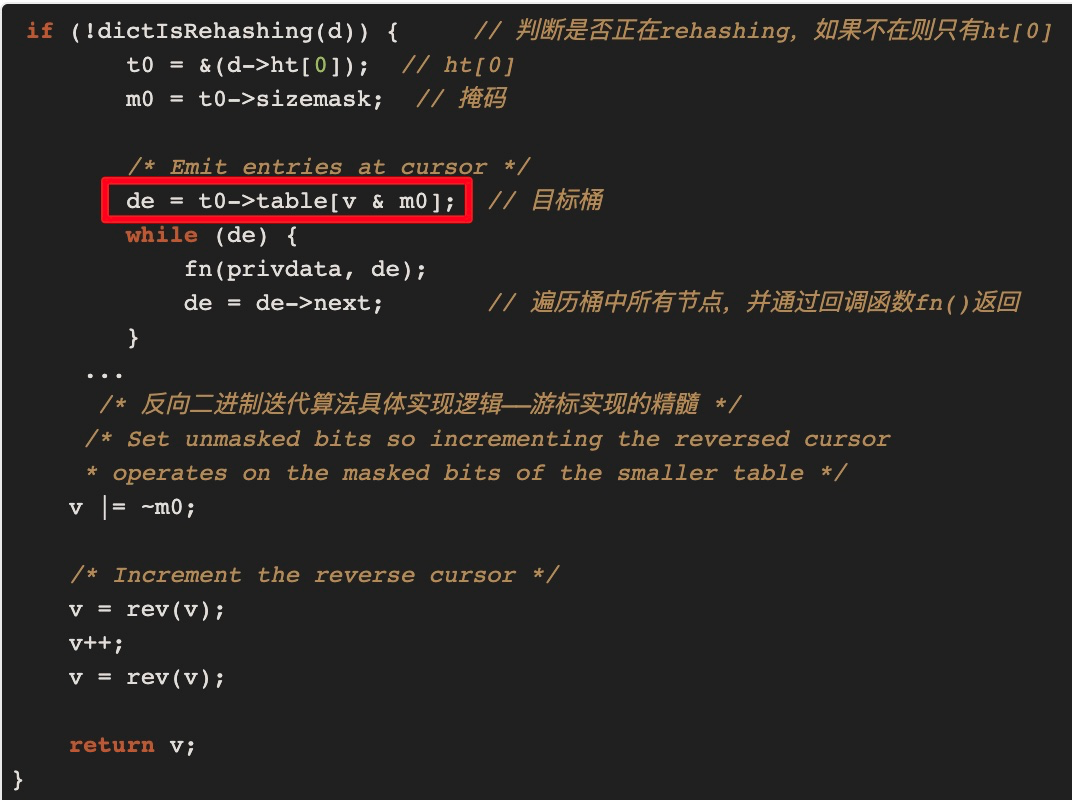
即在找目標桶時總是用當前hashtaba的sizemask(掩碼)來計算,v=14即二進位制000 1110,當前字典表的掩碼從15變成了7即二進位制0000 0111,v&m0的值為6,也就是說在新表上還要掃一遍6號桶.但是縮容後舊錶6和14號桶的資料都已遷移到了新表的6號桶中,所以這時掃描的結果就出現了重複資料,重複的部分為上次未縮容前已掃描過的6號桶的資料。
結論:
當字典縮容時,高位桶中的資料會合並進低位桶中(6,14)->6,scan命令要保證不遺漏資料,所以要得到縮容前14號桶中的資料,要重新掃描6號桶,所以出現了重複資料.Redis也挺難的,畢竟魚和熊掌不可兼得。
總結
通過本次Redis瘦身實踐,雖然是個很小的工具,但確實帶來的顯著的效果,節約資源降低成本,並且在排查問題中又學習到了命令底層巧妙的設計思想,收貨頗豐,最後歡迎感興趣的小夥伴一起交流進步。