一次系統延遲性優化案例
一次系統延遲性優化案例
延遲的本質
本質是cpu沒有及時的執行程式程式碼。
程序內部
網路io,磁碟io,cpu排程 達到瓶頸
第三方系統
呼叫的第三方系統慢,mysql,redis等基礎元件排程慢, 第三方應用系統呼叫慢
問題背景
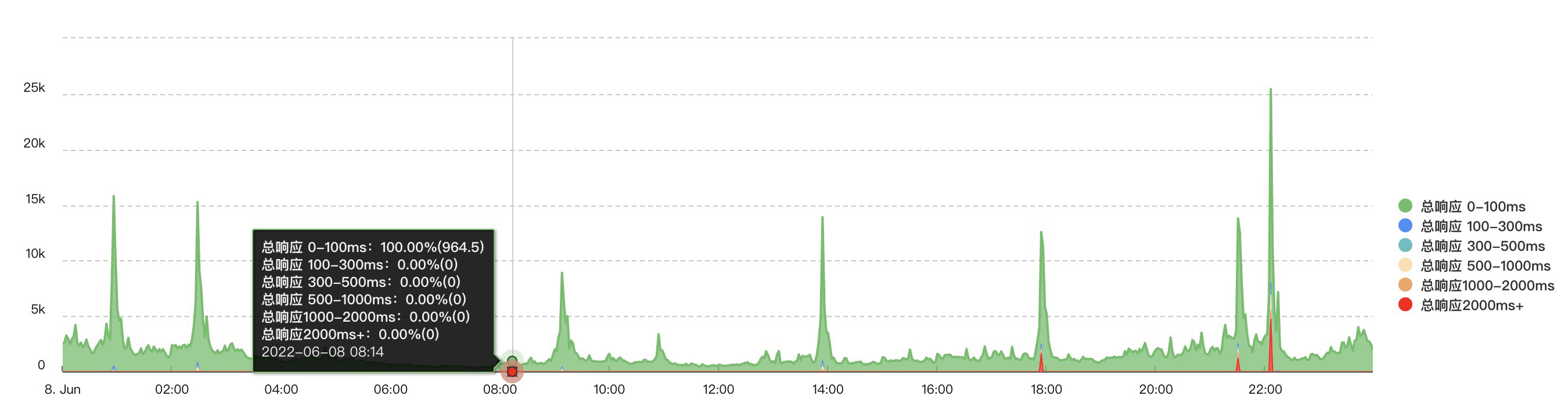
線上隔三差五晚上10點左右總會有sql報警出現,且是同樣的sql,我們的sql報警是在應用程式內部通過對sql操作增加勾點函數,對sql前後執行的位置進行計時,然後sql執行完畢後,對時間進行判斷,大於1s則報警。
晚上10點正好是我們的業務高峰。部分介面也會在此期間出現超過2s的響應。
探索過程
排查sql慢查詢
通過後臺的慢查詢紀錄檔,沒有發現這條慢sql列印出來,且重新執行該sql,執行時間仍然在毫秒內完成,排除掉sql寫法本身帶來的效能問題。
排查系統各項指標
檢視系統cpu,網路頻寬Mbps,磁碟iops,Bps,均未到達瓶頸,僅在高峰期有波峰。
 系統是4核系統,唯一達到瓶頸的也就是系統負載達到了5。說明有程序或執行緒在等待執行。
系統是4核系統,唯一達到瓶頸的也就是系統負載達到了5。說明有程序或執行緒在等待執行。
為什麼系統各個硬體指標都不是很高,程式反而慢了呢,cpu為什麼沒有幹更多活來執行更多的指令呢。
考慮程式在執行一個cpu使用率不高的動作,但是這個動作卻不是在執行使用者程式碼
一般通過go tool pprof 檢視cpu的使用率是檢視hot-cpu,也就是cpu真正執行的時間,但是如果要看等待cpu的時間得看off-cpu,go提供了這樣的工具(github.com/felixge/fgprof)
 可以看到一個方法在執行時由於查詢了資料庫,cpu在withLock 和等待資料庫返回資料庫時耗費了很多等待時間。但是這裡只能看出這部分程式碼等待cpu的時間佔所有等待時間的大部分,無法確定程式真正等待的時間。
可以看到一個方法在執行時由於查詢了資料庫,cpu在withLock 和等待資料庫返回資料庫時耗費了很多等待時間。但是這裡只能看出這部分程式碼等待cpu的時間佔所有等待時間的大部分,無法確定程式真正等待的時間。
用go trace分析系統延遲
基於上面分析,為更進一步確定是資料庫查詢帶來的耗時, 採用更加精確化的工具 go trace分析程式執行時的動作。go trace 是golang提供的官方工具。
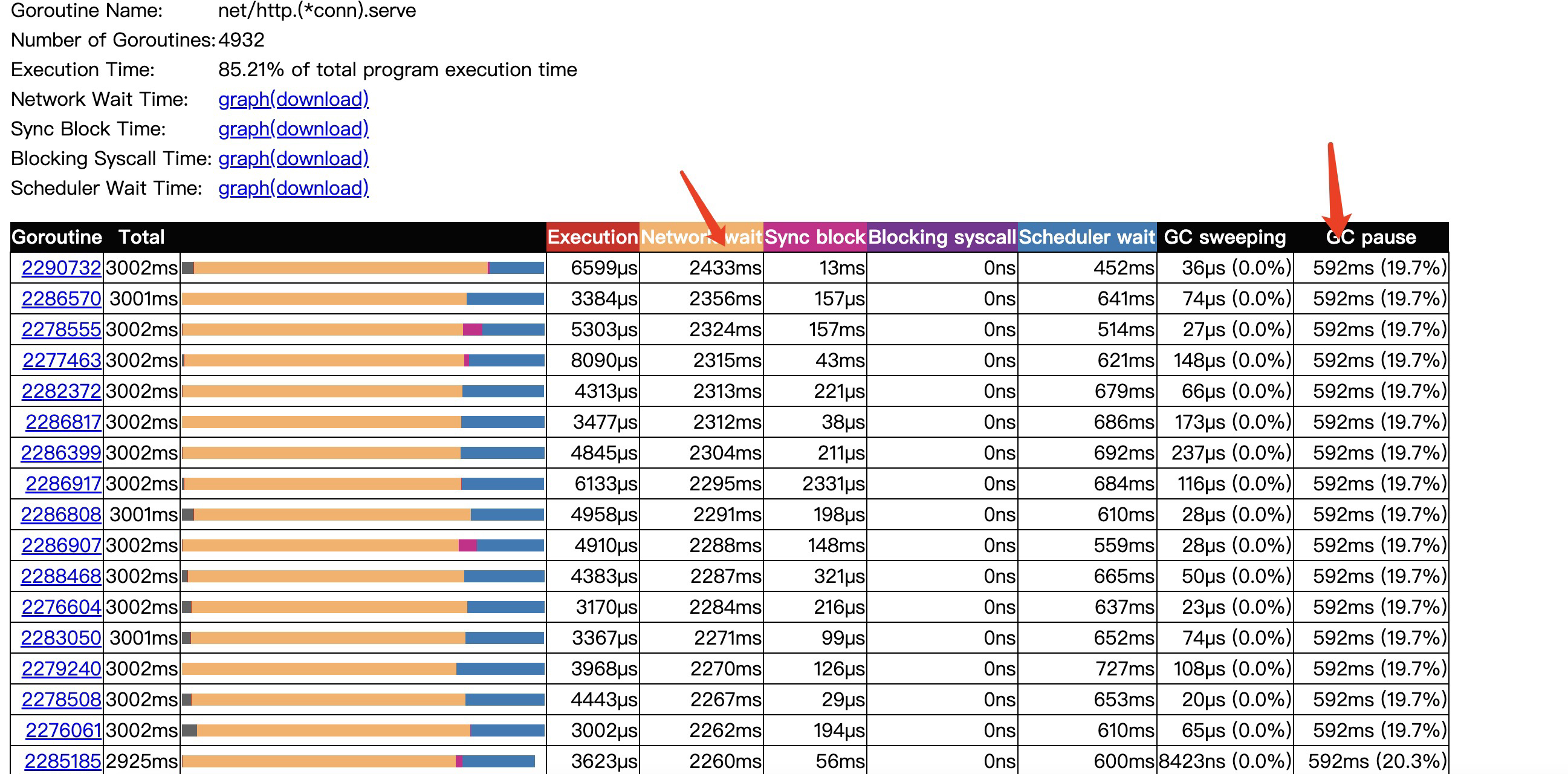
進行了3s的取樣,其中網路io等待時間就佔了2秒多,我的理解程式會在網路io系統呼叫開始時記錄下此時協程的時間,並將協程從p佇列拿下來,然後非同步等到epoll回撥通知,等到檔案描述符可讀後,將協程重新加入到p佇列,重新執行排程。這裡的Network wait就是從p佇列拿下來到加入到p佇列的時間間隔,然後真正執行是要等待Scheduler wait 排程等待時間才會被排程。
這裡協程的網路等待時間長,但是不能完全說明是導致系統延遲的原因,因為在keepAlive開始時,一個協程是有可能處理多個網路請求的,所以有可能是多次請求間,讀等待時間較長導致。所以繼續看下其他指標。
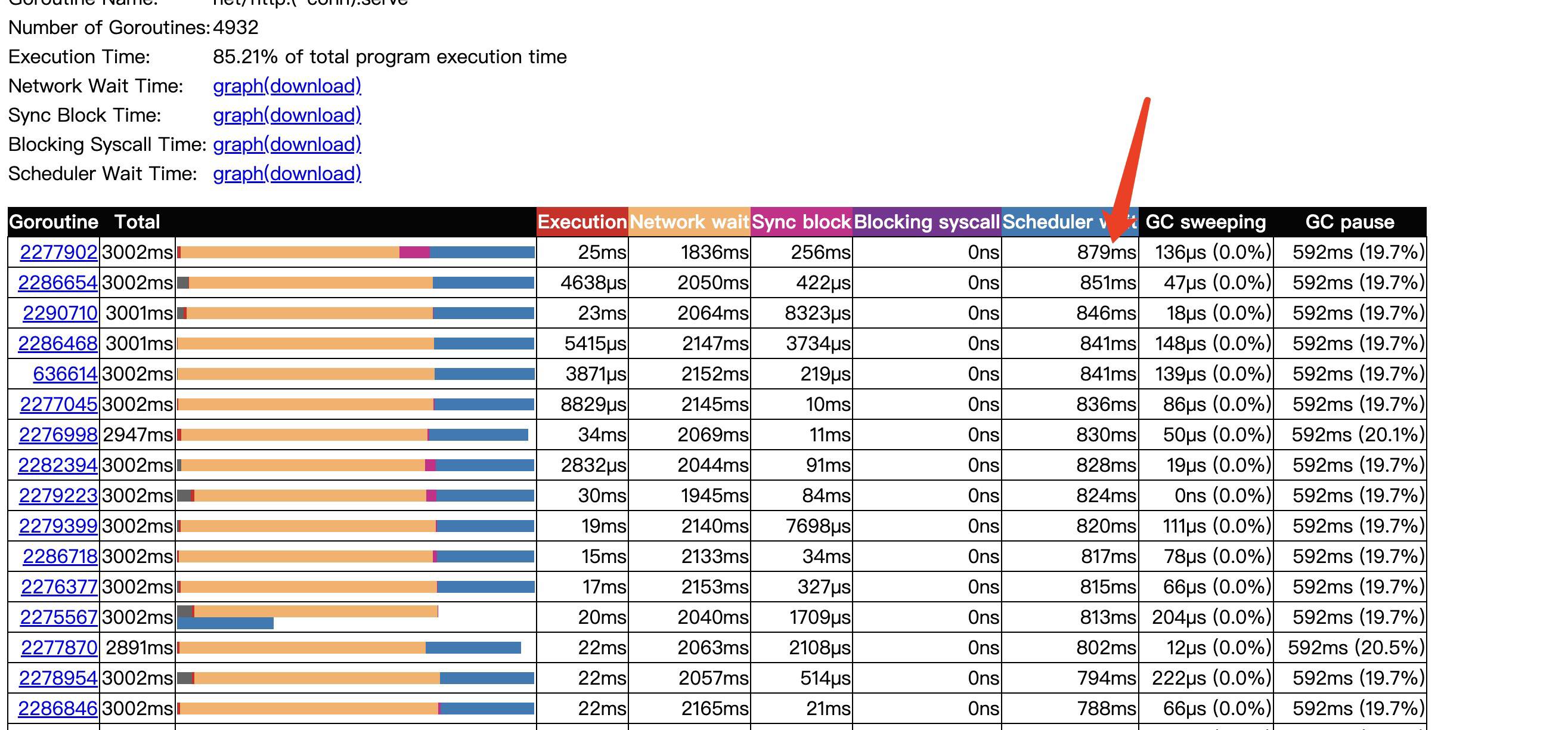
協程從就緒可執行狀態到真正被排程耗時了879ms,可見協程排程的壓力也是過大的。

由於程式阻塞帶來的延遲開銷也是不小的,達到778ms。
對應於之前off-cpu看到的網路和阻塞開銷就是執行資料庫操作時的網路請求以及withlock操作,由於阻塞更加劇了協程排程的開銷。每次阻塞都會引發協程的重新排程。當然go trace左上角可以點選graph同樣能觀察得出上述結論。
優化
由於程式的阻塞雖然不是慢查詢導致,但是依然是由於資料庫操作帶來的,所以簡單直接的優化就是減少資料庫操作,或者更直接點說,在高並行介面下,儘可能減少網路等阻塞操作。
將這部分查詢資料提前存到記憶體裡,通過記憶體直接查詢。
成果
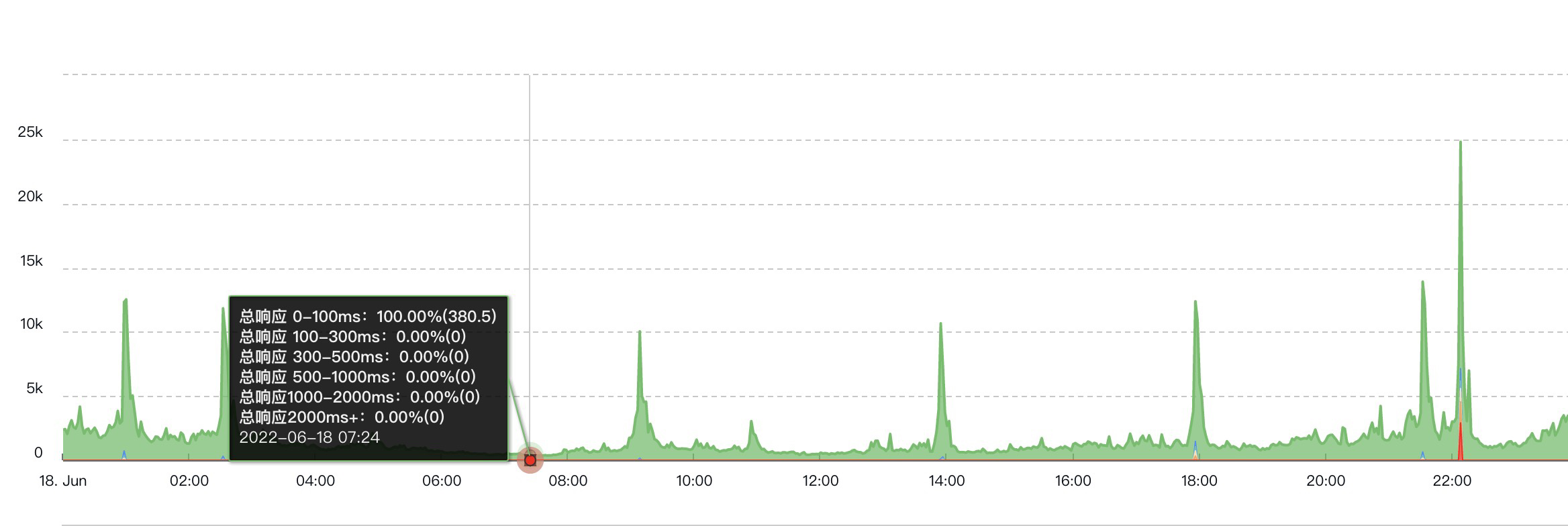 可以看到對比之前情況,除開22點峰值,已經沒有超過2s的響應了,但是22點峰值時還是會有,原因是我們線上的機器同時部署了多臺服務,由於其他服務的影響導致,所以後續可能還會繼續做優化,將其他服務的處理介面能力提升上去,或者更好的做好隔離。
可以看到對比之前情況,除開22點峰值,已經沒有超過2s的響應了,但是22點峰值時還是會有,原因是我們線上的機器同時部署了多臺服務,由於其他服務的影響導致,所以後續可能還會繼續做優化,將其他服務的處理介面能力提升上去,或者更好的做好隔離。
結論
go trace 是個很好的分析系統延遲的工具。
對高並行介面的設計最好減少網路以及其他阻塞操作,流量上去後,這些阻塞很可能帶來系統延遲。