遷移學習(EDA)《Energy-based Domain Adaption with Active Learning for Emerging Misinformation Detection》
論文資訊
論文標題:Energy-based Domain Adaption with Active Learning for Emerging Misinformation Detection
論文作者:Kyumin Lee; Guanyi Mou; Scott Sievert
論文來源:
論文地址:download
論文程式碼:download
1 介紹
基於能量的模型(EBM),應該給正確的類 $\breve{y}$ 產生較低的能量:
$\breve{y}=\operatorname{argmin}_{y \in Y} E(x, y) \quad\quad\quad(1)$
本文域適應損失——源域監督損失 + 域對齊損失。
源域監督損失 $L_{s-\text { classification }}$ 如下:
$L_{s-\text { classification }}=E(x, y ; \theta)^{2}+e x p^{(-E(x, \bar{y} ; \theta))} \quad\quad\quad(2)$
其中,$y$ 是真實的類,$\bar{y}$ 是另一個/不正確的類。
域對齊損失 $L_{D-\text { Alignment }}$ 如下:
$L_{D-\text { Alignment }}=\max \left(0, \mathbb{E}_{x \sim \mathcal{D}_{S}} F(x ; \theta)-\mathbb{E}_{x \sim \mathcal{D}_{T}} F(x ; \theta)\right) \quad\quad\quad(3)$
其中,$F(x ; \theta)= -\log \sum\limits _{y \in Y} \exp ^{(-E(x, y ; \theta))}$ 。
總損失如下:
$L_{D A}=L_{S \text {-classification }}+\lambda * L_{D-\text { Alignment }} \quad\quad\quad(4)$
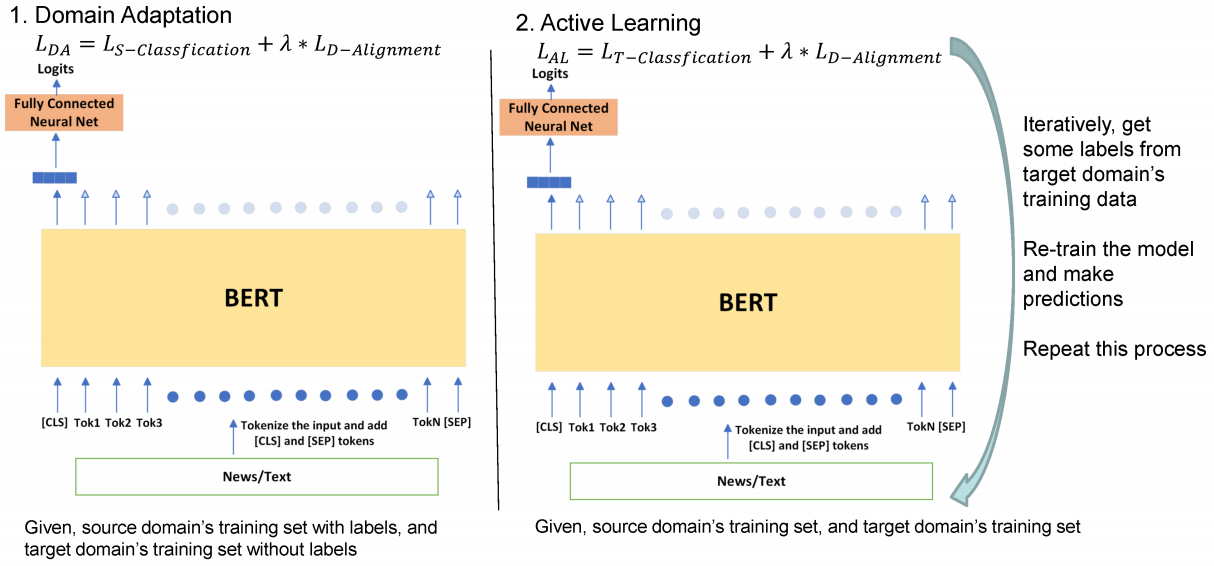
如 Figure 1 所示,模型經過域自適應訓練,就進行主動學習,它基於一定準測從目標域選取一些實列,並取得其真實標籤。然後,使用帶標記的目標範例來進一步訓練我們的模型。
在每一輪中,一旦從目標域得到帶有標記的樣本,將進一步重新訓練模型,然後測量以下損失函數:
$L_{A L}=L_{T \text {-classification }}+\lambda * L_{D-\text { Alignment }} \quad\quad\quad(5)$
$L_{T \text {-classification }}$ 代表了帶標記樣本的分類損失(選擇的)。$L_{D-\text { Alignment }}$ 用於對齊源域和目標域的自由能分佈。
Note:本文的主動學習策略為:(i) 隨機選擇(EDA-randon)和 (ii)基於不確定性的選擇(EDA-不確定性)。
模型框架圖:
2 實驗
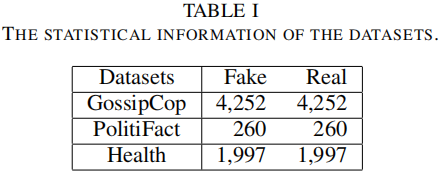
資料集
實驗細節
每個資料集分別被拆分為訓練集、驗證集和測試集,其比例分別為 70%、10% 和 20%。選擇其中一個資料集作為目標域資料集,其餘兩個資料集通過組合在一起作為源域資料集。
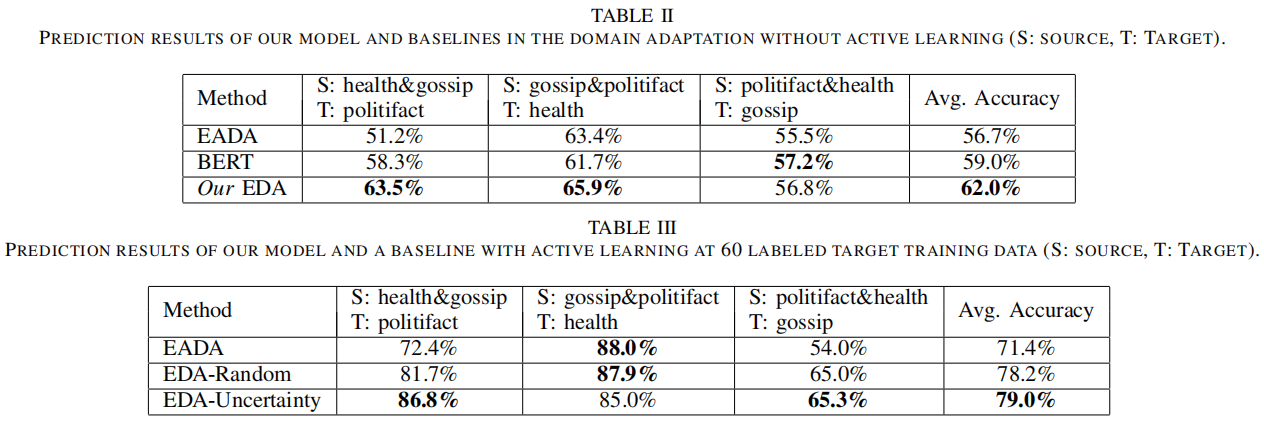
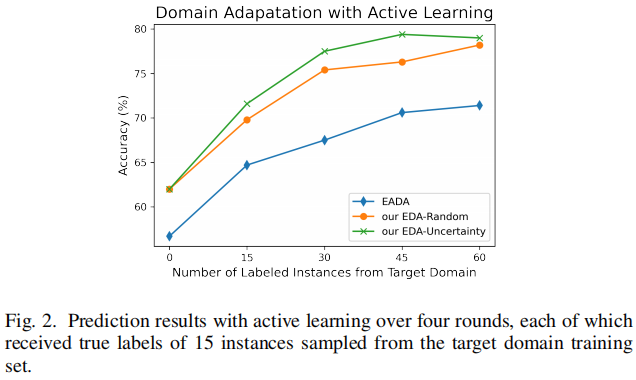
實驗結果
因上求緣,果上努力~~~~ 作者:加微信X466550探討,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/17189660.html