淺析 SplitChunksPlugin 及程式碼分割的意義
起因
有同事分享webpack的程式碼分割,其中提到了SplitChunksPlugin,對於檔案上的描述大家有著不一樣的理解,所以打算探究一下。
Q:什麼是 SplitChunksPlugin?SplitChunksPlugin 是用來幹嘛的?
A: 最初,chunks(以及內部匯入的模組)是通過內部webpack 圖譜中的父子關係關聯的。CommonsChunkPlugin曾被用來避免他們之間的重複依賴,但是不可能再做進一步的優化。從webpack v4 開始,移除了CommonsChunkPlugin,取而代之的是 optimization.splitChunks。SplitChunksPlugin可以去重和分離 chunk
webpack的中文檔案,對SplitChunksPlugin的描述是這樣子的:

針對以上的第二點描述新的 chunk 體積大於 20kb(在進行 min+gz 之前的體積),有同事是這麼理解的:
chunk 大於 20kb 時,webpack會對當前的chunk進行拆包,一般情況下,100kb的包會拆成 5 個包 即 5 * 20kb = 100kb. 如果有並行請求的限制,webpack會自動把某些包合併,如並行請求數是 2 ,那麼這個100kb的包將會被拆成 2 個,每個包的大小為50kb,即 2 * 50kb = 100kb。
而我對此表示有不同的看法:
既然這個外掛是用來對程式碼進行分割的,那麼沒有必要再對程式碼進行合併,這樣子會讓這個外掛變得不純粹,而且會增加外掛邏輯的複雜度,所以這句話的意思應該是分割出來的新chunk得大於 20kb。
由於大家都不是三言兩語就能被說服的,所以打算去查查資料,動動手驗證一下到底是怎麼一回事。
檔案資料
一、英文檔案
首先為了避免中華語言博大精深,導致個人理解有偏差,我先去檢視了一下英文檔案,英文檔案上是這麼描述的:

關鍵詞 new chunk:新的chunk,只有分離出來的才算是新的chunk吧,那麼這句話的意思應該就是新的chunk將會大於20kb。
二、社群文章
其次為了再次避免個人英文理解有偏差,到網上去翻閱了一些社群文章:

作者:前端論道
連結:https://juejin.cn/post/6844904103848443912
來源:稀土掘金
從上圖中可以看到,第三方包vue已經超過了預設的20kb,直接被分割成一個單獨的2.js的包,並不是按照20kb平均分成多個包。
動手實踐
// index.js
import "./a";
console.log("this is index");
// a.js
import "vue";
import "react";
import "jquery";
import "lodash";
console.log("this is a");
// webpack.config.js
const path = require('path');
module.exports = {
mode: "production",
entry: './src/index.js',
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'dist'),
},
optimization: {
splitChunks: {
chunks: 'all',
},
},
};
編譯結果:
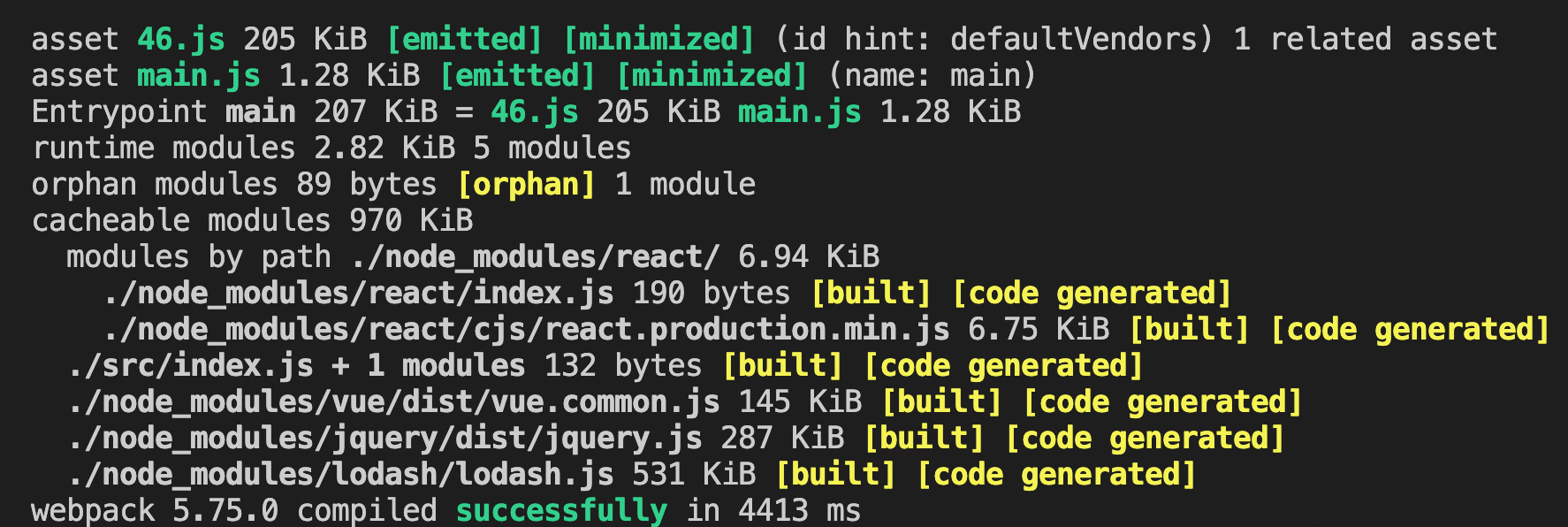
從編譯的結果中可以看到,除了main.js,僅僅多出了一個205kb的46.js。
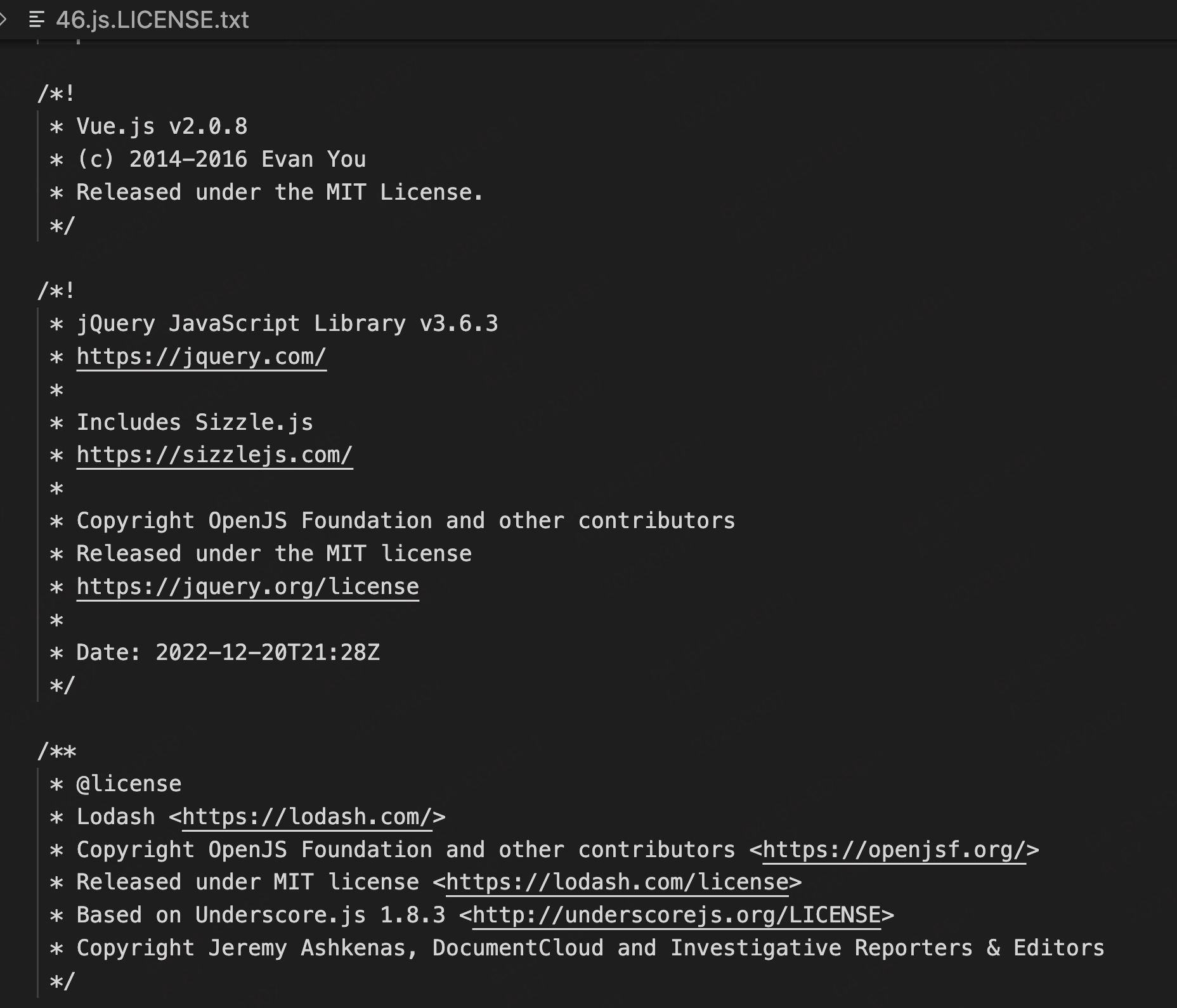
從上圖可以看出,vue、jquery、lodash等一起都被打包到 46.js 中,並沒有以20kb為基礎平均分割成很多個chunk。
結論
新的 chunk 體積大於 20kb(在進行 min+gz 之前的體積),指的是引入的依賴中,在進行min+gz之前的體積大於20kb,這個依賴將會被分割出來成為一個新的chunk。
新的疑問
到這裡還沒有結束,因為我還有幾個疑問:
-
webpack為什麼要進行程式碼分割? -
瀏覽器的並行請求一般不是4~6個嗎?為什麼文章裡提到的按需請求和初始請求都是小於或者等於30?
webpack為什麼要進行程式碼分割?
- 前端程式碼體積變大,偵錯和上線都需要很長的編譯時間,開發時修改一行程式碼也要重新打包整個指令碼。
- 使用者需要花額外的時間和頻寬下載更大體積的指令碼檔案。
一、按需載入
首次載入只載入必要的內容,提升使用者的首次載入的速度。其他的模組可以根據使用者的互動進行按需載入,即使用者跳轉新路由或者點選的頁面的時候再進行載入。
二、有效利用快取
通過webpack在打包是對程式碼進行分割,可以有效的利用快取:打包編譯的時候,只需要編譯需要更新的部分;使用者存取的時候只需要下載被修改的檔案即可。
場景:
你有一個體積巨大的檔案,並且只改了一行程式碼,使用者仍然需要重新下載整個檔案。但是如果你把它分為了兩個檔案,那麼使用者只需要下載那個被修改的檔案,而瀏覽器則可以從快取中載入另一個檔案。
三、預獲取/預載入模組
prefetch(預獲取):將來某些導航下可能需要的資源:這會生成<link rel="prefetch" href="login-modal-chunk.js">並追加到頁面頭部,指示著瀏覽器在閒置時間預取login-modal-chunk.js檔案。preload(預載入):當前導航下可能需要資源
---preload chunk會在父chunk載入時,以並行方式開始載入。prefetch chunk會在父chunk載入結束後開始載入。
---preload chunk具有中等優先順序,並立即下載。prefetch chunk在瀏覽器閒置時下載。
---preload chunk會在父chunk中立即請求,用於當下時刻。prefetch chunk會用於未來的某個時刻。
--- 瀏覽器支援程度不同。
瀏覽器的並行請求一般不是4~6個嗎?為什麼文章裡提到的按需請求和初始請求都是小於或者等於30?
隨著http2.0的普及,瀏覽器的並行請求的限制得到了很好的解決。通過http2.0的多路複用,理論上可以通過一個TCP請求傳送無數個請求。然後翻了下webpack程式碼倉庫原始碼,發現了以下注釋:
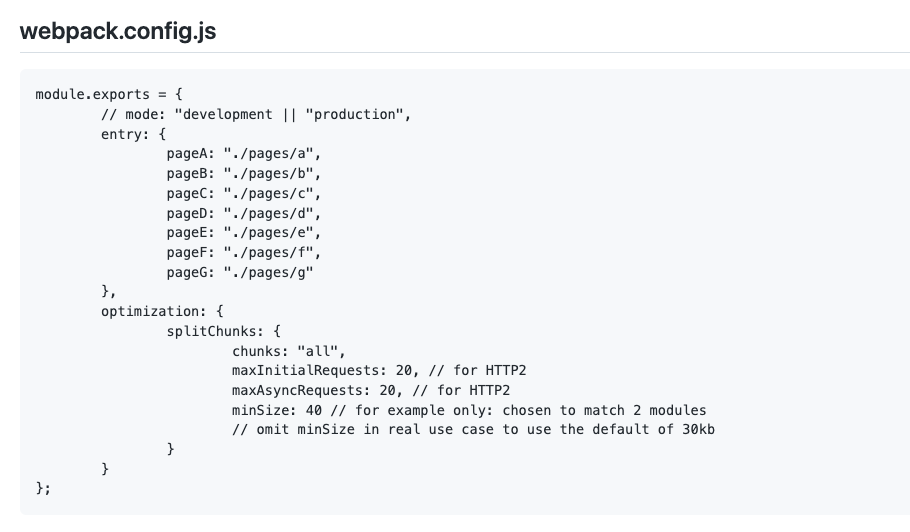
http2.0支援情況:

所以在webpack的程式碼分割邏輯裡,按需請求和初始請求都超過了之前瀏覽器對http1.0單個域名請求的限制。
參考檔案:
webpack中文檔案
webpack英文檔案
如何使用 splitChunks 精細控制程式碼分割