減少80%儲存-風控名單服務重構剖析
引言
小小的 Redis 大大的不簡單,本文將結合風控名單服務在使用 Redis 儲存資料時的資料結構設計及優化,並詳細分析 redis 底層實現對資料結構選型的重要性。
背景
先來交代下使用場景,在風控場景下,名單服務每時每刻都需要承受海量資料查詢。
名單檢索內容涉及維度非常廣:使用者業務標識(UID)、手機號、身份證號、裝置號、IMEI(International Mobile Equipment Identity, 國際移動裝置識別碼)、Wifi Mac、IP 等等。使用者的一次業務請求,在風控的中會擴散到多個名單維度,同時還需要在 RT(Response-time) 上滿足業務場景訴求。
這就導致名單服務的構建需要承受住如下挑戰:
- 海量資料儲存:維度多,儲存內容尚可(是否命中),按照 X 個使用者,Y 個維度,Z 個業務線(隔離),量級非常大
- 大流量、高並行:業務場景下任何存在風險敞口的點都需要評估過風控,每天決策峰值 TPS 過萬
- 極低耗時:留給名單服務的時間不多了,如果整體業務系統給風控決策的耗時是 200 ms,名單服務必須要在 30 ~ 50 ms 就得得到結果,否則將極大影響後續規則引擎的運算執行進度
如上系統要求其實在巨量資料系統架構下都是適用的,只是名單服務要的更極致而已。
在上一篇 《風控核心子域——名單服務構建及挑戰》 文章中已經介紹了名單服務設計,選用了 Redis 作為儲存,目前也只能是 Redis 能滿足名單服務場景的高效能訴求。同時也介紹了選擇用 Redis 中遇到的資料異常及高可用設計架構,忘了或者感興趣的朋友可以再回顧一遍。
名單資料的儲存結構選用的是 Hash 儲存,結構如下:

在此我提出幾個疑問(不知道讀者看完後是否也有~):
- 為何使用 Hash? 使用
set key-value結構可以麼? - 過期時間如何維護?set key-val 可以直接基於
expire設定, hash 結構內過期的資料是如何刪除的? - 當前設計架構,對 Redis 的記憶體消耗大概在什麼水位?可預見的未來能夠滿足業務的增長需求麼?
如果你也有這些疑問,那麼本篇文章將為你解惑,希望能有收穫。
Redis 是如何儲存資料的?
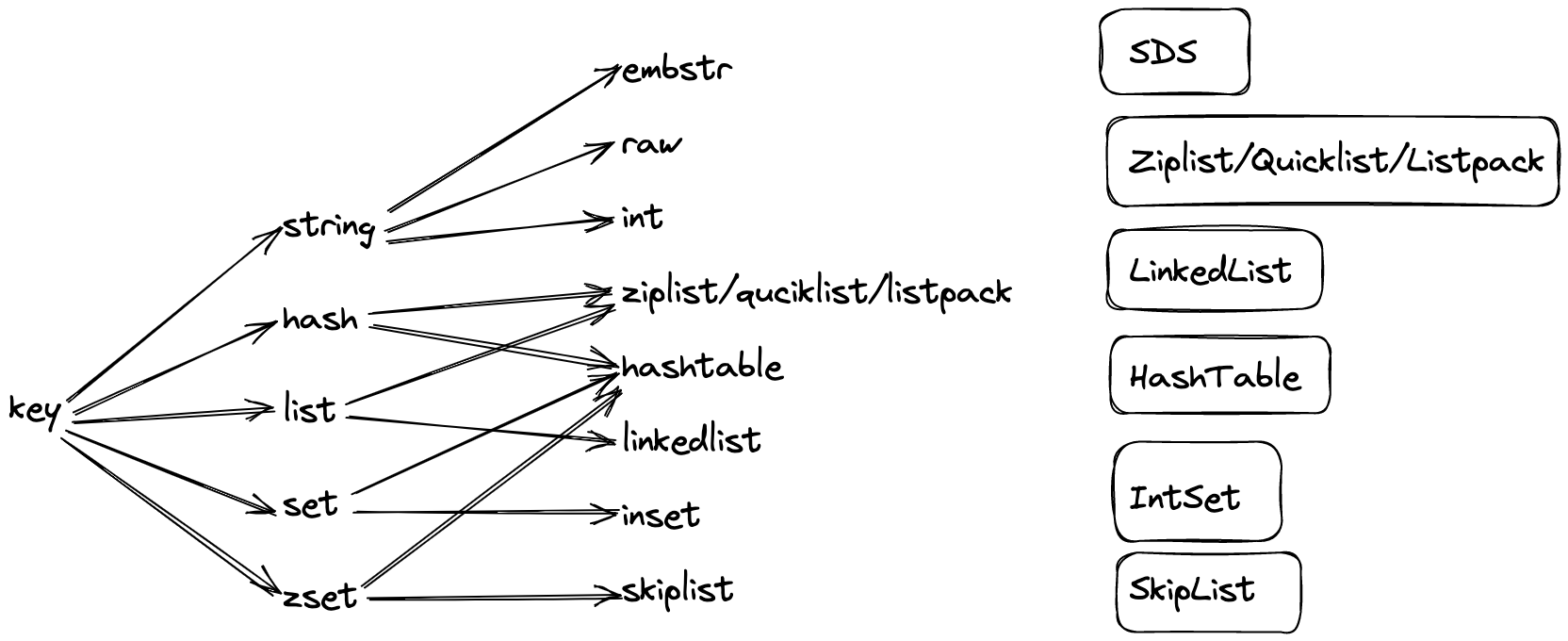
工欲善其事必先利其器,我們先將常用的 Redis 結構底層實現摸透,才能在使用上游刃有餘,由於本文在用的 redis 結構只會涉及到 string 和 hash,筆者僅分析這兩種,其它的讀者們感興趣可以自行搜尋。
字串儲存
string 是 redis 中最常用的儲存結構,redis 實現是是基於 C 語言,此處的字串並不是直接使用 c 中的字串,而是自己實現了一套 「SDS」(簡單動態字串)。
struct sdshdr(
//記錄 buf 陣列中已使用位元組的數量
//等於 SDS 儲存字串的長度
int len;
//記錄 buf 陣列中未使用位元組的數量
int free;
//位元組陣列,用於儲存字串
char buf[];
}
redis 的底層儲存會使用三種方式來儲存資料:**int**、**raw**和**embstr**
int 型別
儲存值:整形,且可以用 long 型別來表示的。舉例如下:
redis> OBJECT ENCODING number
"int"

raw 型別
儲存值:字串值,且字串長度 > 39 位元組的。舉例如下:
redis> SET story "Long, long, long ago there lived a king ..."
OK
redis> STRLEN story
(integer) 43
redis> OBJECT ENCODING story
"raw"

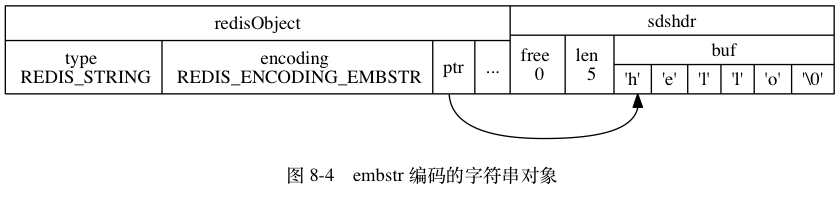
embstr 型別
儲存值:字串值,且字串長度 <= 39 位元組的。
embstr 編碼的字串物件在執行命令時, 產生的效果和 raw 編碼的字串物件執行命令時產生的效果是相同的, 但使用 embstr 編碼的字串物件來儲存短字串值有以下好處:
- embstr 編碼將建立字串物件所需的記憶體分配次數從 raw 編碼的兩次降低為一次。
- 釋放 embstr 編碼的字串物件只需要呼叫一次記憶體釋放函數, 而釋放 raw 編碼的字串物件需要呼叫兩次記憶體釋放函數。
- 因為 embstr 編碼的字串物件的所有資料都儲存在一塊連續的記憶體裡面, 所以這種編碼的字串物件比起 raw 編碼的字串物件能夠更好地利用快取帶來的優勢。
舉例如下:
redis> SET msg "hello"
OK
redis> OBJECT ENCODING msg
"embstr"
總結如下(redis version > 3.2):
| 值 | 編碼 | 佔用記憶體 |
|---|---|---|
| 可以用 long 型別儲存的整數。 | int | 定長 8 位元組 |
| 可以用 long double 型別儲存的浮點數。 | embstr 或者 raw | 動態擴容的,每次擴容 1 倍,超過 1M 時,每次只擴容 1M。 |
| 字串值, 或者因為長度太大而沒辦法用 long 型別表示的整數, 又或者因為長度太大而沒辦法用 long double 型別表示的浮點數。 | embstr 或者 raw | 用來儲存大於 44 個位元組的字串。 |
Hash 儲存
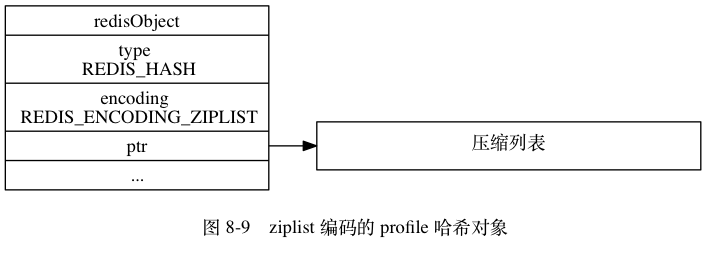
雜湊物件的編碼可以是 ziplist 或者 hashtable 。
ziplist 型別
ziplist 編碼的雜湊物件使用壓縮列表作為底層實現, 每當有新的鍵值對要加入到雜湊物件時, 程式會先將儲存了鍵的壓縮列表節點推入到壓縮列表表尾, 然後再將儲存了值的壓縮列表節點推入到壓縮列表表尾, 因此:
- 儲存了同一鍵值對的兩個節點總是緊挨在一起, 儲存鍵的節點在前, 儲存值的節點在後;
- 先新增到雜湊物件中的鍵值對會被放在壓縮列表的表頭方向, 而後來新增到雜湊物件中的鍵值對會被放在壓縮列表的表尾方向。
舉例如下:
redis> HSET profile name "Tom"
(integer) 1
redis> HSET profile age 25
(integer) 1
redis> HSET profile career "Programmer"
(integer) 1

hashtable 型別
雜湊物件中的每個鍵值對都使用一個字典鍵值對來儲存:
- 字典的每個鍵都是一個字串物件, 物件中儲存了鍵值對的鍵;
- 字典的每個值都是一個字串物件, 物件中儲存了鍵值對的值。
如果上述例子的底層儲存方式是 hashtable,那麼物件結構會如圖所示:

總結如下(redis version < 3.2,新版本的優化了使用 quicklist,更新的版本使用 listpack,道理一樣,此處以 ziplist 總結):
| 值 | 編碼 | 佔用記憶體 |
|---|
| 雜湊物件儲存的所有鍵值對的鍵和值的字串長度都小於 64 位元組;
雜湊物件儲存的鍵值對數量小於 512 個; | ziplist | 本質是一個字串;尋值需要遍歷字串;缺點是耗費更多的 cpu 來查詢(如果值很少,可以忽略不計) |
| 不滿足上述 ziplist 條件的值 | hashtable | 類似 java HashMap 實現;空間換時間;需要多花費本身儲存的 25%記憶體 |
注意:ziplist 兩個條件的上限值是可以修改的, 具體請看組態檔 redis.conf 中關於 hash-max-ziplist-value 選項和 hash-max-ziplist-entries 選項的說明。
兩種資料結構,按照解釋,當 value 數量控制在 512 時,效能和單純的使用 hashtable 基本一致,value 數量在不超過 1024 時,效能只有極小的降低,然而記憶體的佔用 ziplist 比 hashtable 降低了 80% 左右。
名單服務改造
通過如上的分析,我們得出兩個重要結論:
- key 或者 val 使用編碼是 int 型別時(8 個位元組),要比編碼使用 string 即 raw|embstr 要省很多空間
- 使用 ziplist 儲存,要比使用 key-value 節省巨大的空間
分析一下名單服務支撐的業務資料量,假設有 5 億個使用者(可能非活躍,就假設全量),每個使用者衍生出 10 個名單維度(手機號、身份證、裝置等等),每個維度再衍生出 10 個沙盒隔離環境(業務線、渠道等等),那麼總的資料量級在: 500 億左右。
分桶
500 億個值如果都存放在 hash 結構中,需要分散到不同的桶(bucket)中,每個桶最大不超過 512 個(這個可以自行設定,最好不超 1024 個,不然損失了查詢效能,設定過大後需要實際壓測檢驗)。從而避免 hash 的編碼從 ziplist 切換至 hashtable。
bucket 數量 = 500 億 / 512 = 97,656,250,即需要這麼多桶來承載,如果是 1024 個,則桶的量可縮小一倍,但是意義不大。
hash 演演算法選擇
需要將這麼多維度的資料通過 hash 演演算法,均勻、離散的分攤到這些個 bucket 內,必須選擇業內比較有名且碰撞率不高的優秀演演算法。可以選擇 crc32(key) % bucketNum,得到該存在哪個 bucket 內,此時再使用 hash 演演算法(需要考慮前後兩次 hash 的碰撞率,建議選擇與分桶演演算法不一致)或者直接使用 Java 物件的 hashcode 作為 field 即可,整體效果如圖:

新老資料比對

我將用三種資料作比對,分別是:字串直插、老的名單服務資料、新的資料結構
字串直插
key = deviceHash-${名單型別}-${裝置指紋}-${沙盒隔離標識}
val = 過期時間戳
模擬在同一個裝置指紋下有 10 個業務域隔離,即需要插入 10 條資料
## 插入 10 條資料,此處省略剩餘 9 條
127.0.0.1:6379> set deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724-100000 1678157018608
OK
## 單條佔用記憶體大小(位元組)
127.0.0.1:6379> memory usage deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724-100000
(integer) 136
## 編碼型別
127.0.0.1:6379> debug object deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724-100000
Value at:0xffffb9a7c0c0 refcount:1 encoding:int serializedlength:14 lru:439622 lru_seconds_idle:745
整體佔用記憶體(位元組) = 136 * 10 = 1360
老名單服務資料結構
key = deviceHash-${名單型別}-${裝置指紋}
field = ${沙盒隔離標識}
val = 過期時間戳
模擬在同一個裝置指紋下有 10 個業務域隔離,即需要插入 10 條資料
## 插入 10 條資料,此處省略剩餘 9 條
127.0.0.1:6379> hset deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724 100000 1678157018608
(integer) 1
## 單條佔用記憶體大小(位元組)
memory usage deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724
(integer) 296
## 編碼型別
127.0.0.1:6379> debug object deviceHash-3-a313633418103bf58fe65b56bef28884e0ada768d20c94d69fc49ad618d92724
Value at:0xffffb9a7c0d0 refcount:1 encoding:ziplist serializedlength:75 lru:439622 lru_seconds_idle:1168
整體佔用記憶體(位元組) = 296
注:此處 hash 的 field 和 val 都為超 64 位元組,滿足 ziplist 要求。
新名單服務資料結構
key = bucket_${取餘}
field = hash_long_method(deviceHash-${名單型別}-${裝置指紋}-${沙盒隔離標識})
val = 過期時間戳
模擬在同一個裝置指紋下有 10 個業務域隔離,即需要插入 10 條資料
## 插入 10 條資料,此處省略剩餘 9 條
127.0.0.1:6379> hset bucket_11 206652428 1678157018608
(integer) 1
## 單條佔用記憶體大小(位元組)
127.0.0.1:6379> memory usage bucket_11
(integer) 248
## 編碼型別
127.0.0.1:6379> debug object bucket_11
Value at:0xffffb9a7c050 refcount:1 encoding:ziplist serializedlength:76 lru:439622 lru_seconds_idle:1214
整體佔用記憶體(位元組) = 248(此處實際節省的是原始字串作直接作為 key 所帶來的消耗)
可見,如上按照 500 億資料計算的話,去除 10 個沙盒隔離維度,則老方案需要 50 億個 hash 結構來儲存,新方案只需要不到 1 億個 結構來儲存,節省的記憶體還是很客觀的。
由於名單服務比較特殊,field 和 val 都不大,假設業務上儲存的值超 64 位元組或者 filed 個數超 512,轉變為 hashtable 的話,則新方案節省的就是巨量的記憶體。
總結
新的資料設計結構規避了如下幾個問題:
- 使用 Hash 是有代價的,底層如果是 hashtable 實現的話,會多用 25% 記憶體空間,畢竟空間換時間嘛
- key 最好不用原始的字串,更有勝者,長短不一,導致記憶體碎片,佔用空間情況更加嚴重
- 部分開發者喜歡原始字串加 MD5 後得到 32 位字元,解決了記憶體碎片問題,但是相比於編碼是 int 型別,emstr 更佔用空間,畢竟前者只需固定 8 個位元組
- 如上
value我們只儲存了時間戳,即是 long 型別整數,沒有什麼好優化的,假設業務中需要儲存的是 字串,序列化 JSON 串等,應採用高效的 byte[] 壓縮演演算法,如Protocol Buffers等等
同時,在實施過程中也要注意一些問題:
- hash 演演算法終歸是有碰撞率的,在一些不容許錯誤的(比如金融、風控)等場景下,需要一定的取捨
- 才有 hash 結構儲存資料,失去了 redis 天然的支援 expire 功能,需要自主維護資料的生命週期,比如在值中追加生命時間戳,整體的高可用也需要保證
往期精彩
歡迎關注公眾號:咕咕雞技術專欄
個人技術部落格:https://jifuwei.github.io/ >
