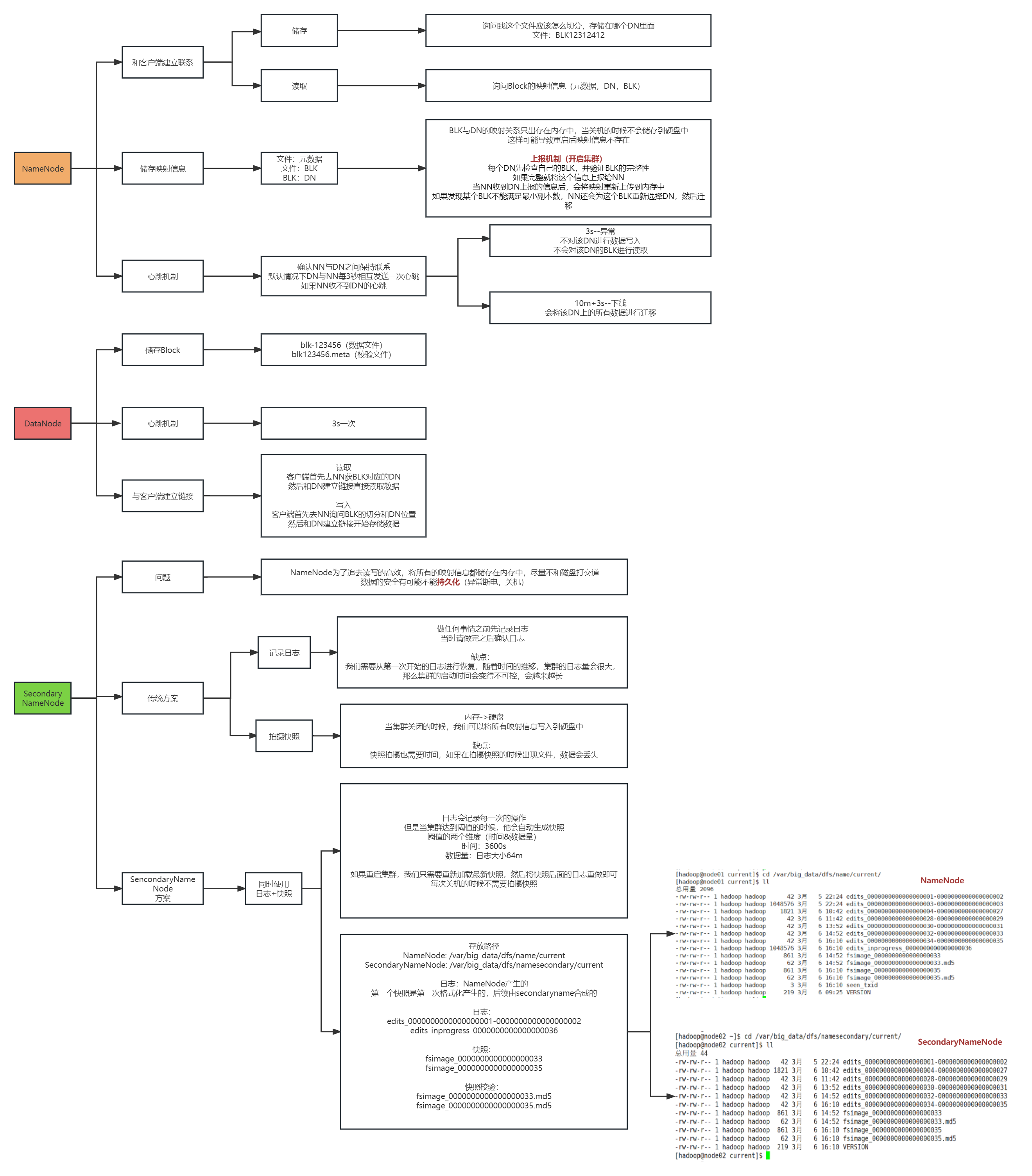
Hadoop節點的分類與作用
檔案的資料型別
檔案有一個stat命令
- 後設資料資訊-->描述檔案的屬性
檔案有一個vim命令
- 檢視檔案的資料資訊
分類
- 後設資料
File 檔名
Size 檔案大小(位元組)
Blocks 檔案使用的資料塊總數
IO Block 資料塊的大小
regular file:檔案型別(常規檔案)
Device 裝置編號
Inode 檔案所在的Inode
Links 硬連結次數
Access 許可權
Uid 屬主id/使用者
Gid 屬組id/組名
Access Time:簡寫為atime,表示檔案的存取時間。當檔案內容被存取時,更新這個時間
Modify Time:簡寫為mtime,表示檔案內容的修改時間,當檔案的資料內容被修改時,更新這個時間。
Change Time:簡寫為ctime,表示檔案的狀態時間,當檔案的狀態被修改時,更新這個時間,例如檔案的連結數,大小,許可權,Blocks數。
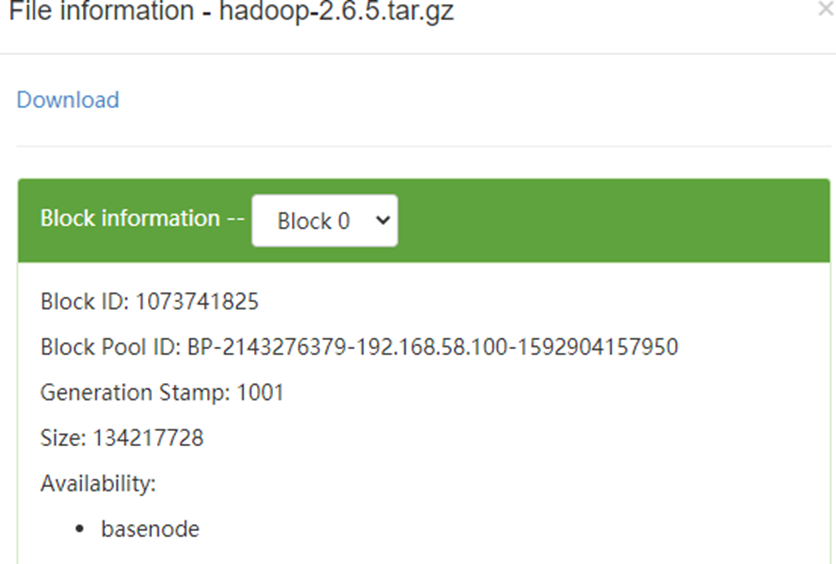
檔案資料
- 真實存在於檔案中的資料
NameNode(NN)
功能
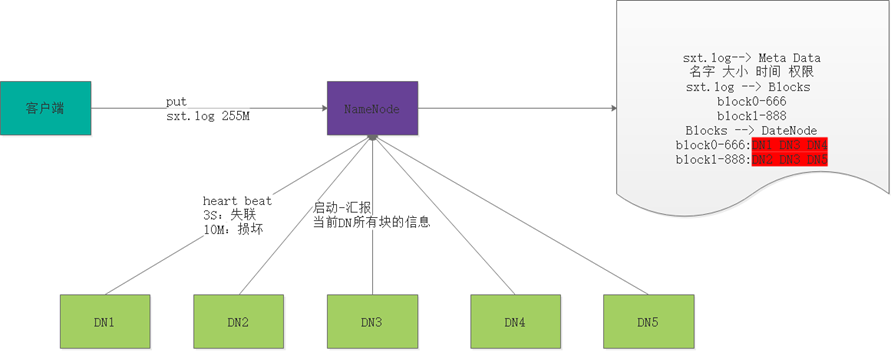
接受使用者端的讀寫服務
-
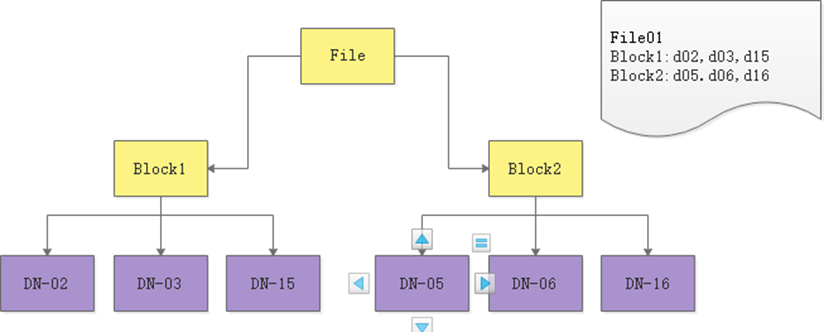
NameNode存放檔案與Block的對映關係
-
DataNode存放Block與DataNode的對映關係
儲存檔案的後設資料資訊
-
檔案的歸屬
-
檔案的許可權
-
檔案的大小時間
-
lock資訊,但是block的位置資訊不會持久化,需要每次開啟叢集的時候DN上報

收集Block的資訊
-
系統啟動時
- NN關機的時候是不會儲存任意的Block與DN的對映資訊
- DN啟動的時候,會將自己節點上儲存的Block資訊彙報給NN
- NN接受請求之後重新生成對映關係
- Block--DN3
- 如果某個資料塊的副本數小於設定數,那麼NN會將這個副本拷貝到其他節點
-
叢集執行中
- NN與DN保持心跳機制,三秒鐘傳送一次
<property> <description>Determines datanode heartbeat interval in seconds.</description> <name>dfs.heartbeat.interval</name> <value>3</value> </property> <property> <name>heartbeat.recheck.interval</name> <value>300000</value> </property>- 如果使用者端需要讀取或者上傳資料的時候,NN可以知道DN的健康情況
- 可以讓使用者端讀取存活的DN節點
-
如果DN超過三秒沒有心跳,就認為DN出現異常
- 不會讓新的資料讀寫到DataNode - 客戶存取的時候不提供異常結點的地址-
如果DN超過10分鐘+30秒沒有心跳,那麼NN會將當前DN儲存的資料轉存到其他節點
-
超時時長的計算公式為:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而預設的heartbeat.recheck.interval 大小為5分鐘,dfs.heartbeat.interval預設為3秒。
-
-
效能
NameNode為了效率,將所有的操作都在記憶體中完成
-
NameNode不會和磁碟進行任何的資料交換
-
問題:
- 資料的持久化
- 資料儲存在記憶體中,掉電易失
DataNode(DN)
功能
存放的是檔案的資料資訊和驗證檔案完整性的校驗資訊
-
資料會存放在硬碟上
-
1m=1條後設資料 1G=1條後設資料
-
NameNode非常排斥儲存小檔案,一般小檔案在儲存之前需要進行壓縮
彙報
-
啟動時
- 彙報之前先驗證Block檔案是否被損壞
- 向NN彙報當前DN上block的資訊
-
執行中
- 向NN保持心跳機制
- 客戶可以向DN讀寫資料
-
當用戶端讀寫資料的時候,首先去NN查詢file與block與dn的對映
- 然後使用者端直接與dn建立連線,然後讀寫資料
SecondaryNameNode
傳統解決方案
紀錄檔機制
-
做任何操作之前先記錄紀錄檔
-
當NN下次啟動的時候,只需要重新按照以前的紀錄檔「重做」一遍即可缺點
-
缺點
- edits檔案大小不可控,隨著時間的發展,叢集啟動的時間會越來越長
- 有可能紀錄檔中存在大量的無效紀錄檔
-
優點
- 絕對不會丟失資料
拍攝快照
我們可以將記憶體中的資料寫出到硬碟上
- 序列化
啟動時還可以將硬碟上的資料寫回到記憶體中
- 反序列化
缺點
-
關機時間過長
-
如果是異常關機,資料還在記憶體中,沒法寫入到硬碟
-
如果寫出頻率過高,導致記憶體使用效率低(stop the world) JVM
優點
- 啟動時間較短
SNN解決方案
解決思路(紀錄檔edits+快照fsimage)
讓紀錄檔大小可控
- 定時快照儲存
NameNode檔案目錄
- 檢視目錄

解決方案
當我們啟動一個叢集的時候,會產生四個檔案
-
edits_0000000000000000001
-
fsimage_00000000000000000
-
seen_txid
-
VERSION
我們每次操作都會記錄紀錄檔 -->edits_inprogress-000000001
隨和時間的推移,紀錄檔檔案會越來越大,當達到閾值的時候(64M 或 3600秒)
dfs.namenode.checkpoint.period 每隔多久做一次checkpoint ,預設3600s
dfs.namenode.checkpoint.txns 每隔多少操作次數做一次checkpoint,預設1000000次
fs.namenode.checkpoint.check.period 每個多久檢查一次操作次數,預設60s
會生成新的紀錄檔檔案
-
edits_inprogress-000000001 -->edits_0000001
-
建立新的紀錄檔檔案edits_inprogress-0000000016

節點的分類與作用匯總圖