記錄一次鎖的優化
專案背景
老規矩,先講講專案背景。可跳過。
小工具類的微系統。
我們會有一些文字語意描述的事件。譬如某小區兩戶人家因為寵物發生了爭吵,比如某人撥打12345熱線反映小區深夜還在跳廣場舞等等。這些統稱事件。
小學語文老師告訴我們描述事件的敘述文三要素,時間地點人物。
所以我們需要通過NLP從事件裡提取出來這3個關鍵要素。
我們今天主要討論人物,由事件到人。哪些具體的人(必須是非常精準的人,他的戶籍常住身份手機車牌,而不是某個姓名符號)出現在這個事件。
上面提到的事件描述裡會有人的若干相關資訊描述,包括姓名身份證號碼電話車牌等。這些資訊都是零散的語意描述。
比如
2023年5月20日,張三,女,3343身份證號碼1000001,反映住其對面的李四(手機號:1593432322)長期把垃圾丟到過道里,影響樓道衛生案例。
通過NLP或者簡單正則,我們能提取出來兩個姓名,1個身份證號碼,1個手機號。
那麼身份證號碼或者手機號到底屬於張三還是李四一個人還是兩個人呢?
簡單的NLP是沒辦法做到的,最近大火的chatGPT倒是可以,雖然準確率不能達到百分之百。
比如輸入上面一段事件描述,再提問「裡面出現了哪些人,並將他們的身份證號碼和手機號分別輸出」是可以達到我們想要的效果的。
但是畢竟不可能在內網線上生產環境使用。
所以我們只能根據常口庫來進行關聯。這裡面有相對精確的人口資料(也有滯後,換了手機號碼車牌什麼的)。
身份證肯定能關聯出唯一的一個人。
手機號和車牌則不一定。
而且常口庫只是某小部份,有很多手機或車牌根本關聯不到常口庫。
如果手機號關聯不到常口庫也把他加入常口庫作為一個人口資訊。
你能想象嗎?
常口庫裡就兩個欄位ID和手機號有值,其它的比如,姓名,身份證,車牌,戶籍地,常住地,性別,年齡,籍貫,學歷,家族成員,政治面貌等等等等全部一片空白。
如果後期協p調y到了新的常口資料,比如進來戶籍人,通過手機號把上面那條奇葩資料的手機號關聯上了,兩條資料再做合併。
世上的技術千篇一律,奇葩的需求花枝招展
上面文字不全是為了吐槽,而是說明,解析一條記錄過後,需要做很多條件判斷,IO讀寫。比較耗時。
且為什麼會有由事到人過後再有由人到事。
技術背景
專案背景簡單說,有一批文字語意描述,提取其中的的人員要素(身份證,手機,車牌等)將真人進行關聯,再將真人與文字事件進行關聯。這其中有兩個方向,一是從文字事件關聯到人,二是從人關聯到文字事件。
處理流程:資料入到系統,呼叫演演算法解析,基礎資料入庫,然後寫入訊息佇列,非同步處理由事到人的關聯。
資料流量:以區縣為基本單位部署,售前和產品瞭解到年事件量幾十萬級別。平均日上報量甚至不到1000。這個數量級可以說是非常少了。前面說到,每個事件的關聯處理相對比較耗時,在秒級。
滿打滿算,按日均1000條資料算,單個執行緒處理也在20分鐘以內完成,完全是可以接受的。歷史資料是部署前就直接跑完,所以只考慮到新增資料即可。
如果客戶不按常理出牌,幾天匯入一次,也可以在apollo設定裡面通過spring.kafka.listener.concurrency引數來增加kafka消費端執行緒數,並行加速處理。
簡化流程後的虛擬碼:
// 1.根據事件解析要素查詢 是否關聯常口表
List<TPersonInfo> personInfos = personInfoMapper.selectList(eventItem);
List<TWarningRecordDTO> warningRecords = new ArrayList<>();
for (TPersonInfo person : personInfos){
String personId = null;
// 2.是否重點人
if(person.getIsKeyPerson().intValue() == 1){
personId = person.getId();
} else {
personId = SnowflakeIdUtil.snowflakeId();
}
// 3.是否存在於新增人員表
TRiskPerson rperson = riskPersonMapper.selectOne();
// 4.upsert新增人員表
if (rperson != null) {
// 5.update by personId
} else {
// 6.insert by personId
}
}
// 7.寫入事件-人員關係記錄表
但是如果spring.kafka.listener.concurrency>1變成了多執行緒,這第4個步驟upsert新增人員表就有執行緒安全問題。
如果兩個personId同時在做update不同的手機號,那麼最終的可能是最後只保留了一個手機號。
這裡不多做解釋,應該是顯而易見的。
因為是單機應用,所以新增同步塊即可。
同步鎖
public synchronized void upsert(){
// 3.是否存在於新增人員表
TRiskPerson rperson = riskPersonMapper.selectOne();
// 4.upsert新增人員表
if (rperson != null) {
// 5.update by personId
} else {
// 6.insert by personId
}
}
因為其它地方也使用到這段程式碼,將這段程式碼單獨提出來,加上同步鎖,就能解決上面的執行緒安全問題。
這裡解釋一下在業務上關於鎖的粒度問題。
可以只鎖step 5裡的update操作嗎?
在具體的業務裡還真是不可以。
在step 3中,假設兩個執行緒同時執行,同時返回null,表示資料庫沒有此人,那麼它就會執行兩次insert操作。將會丟擲異常:
Duplicate entry 'x' for key 'PRIMARY'
因為人員ID和身份證是唯一索引。
說到這個異常,多說兩句,這裡分為update 和 insert兩步操作,沒有使用insert into on duplicate key update ,因為這裡只有一條資料,橫豎只做1次IO操作。
如果是多條資料,最好也別用,因為這個語法可能會造成死鎖,以及它有嚴重的效能問題,後者特別是多條記錄同時操作且唯一鍵衝突比較嚴重的時候,這裡不做展開。
同時複習一下synchronized本身鎖粒度問題。
- 這裡synchronized加到方法上,因為是非static方法,所以鎖物件為當前類的範例物件。等同於:
public void upsert(){
synchronized(this){
}
}
如果是static方法,因為靜態方法屬於類,所以鎖物件為類物件。等同於:
public void upsert(){
synchronized(Demo.class){
}
}
2.如果synchronized同步程式碼塊,參考上面。
鎖可以是類物件與類的範例物件。
除此以外可以是任意物件。
但注意Integer之類的物件。
3.注意鎖物件的安全問題。
比如鎖物件為類的範例物件。但類為多例。那麼就有多把鎖。
兩個執行緒各拿各的鎖進入本該序列進入的房間。
一些特殊的物件,比如
Integer做為鎖物件。也可能會造成多把鎖。
同樣的,兩個執行緒各拿各的鎖進入本該只有一把鎖序列進入的房間。
業務上的鎖粒度
然後上線過後,萬萬沒想到,客戶可不是按照每天或每幾天匯入幾條百資料這樣的常規操作來,而是半月甚至一個月想起來,匯入一次資料。
這樣,一次匯入的可是幾萬條資料。按單條資料秒計算,消費端開10個並行執行緒,最終耗時也是按10小時為單位計。
因為使用的是全域性悲觀鎖,引數過大,鎖競爭會越大,所以spring.kafka.listener.concurrency引數也不是越大越好。
客戶覺得太慢了,完全不能接受,想盡快看到資料匯入的效果,怎麼辦?
嘗試著分析一下鎖的粒度。看能不能再降低一些。
首先,鎖的粒度當然越低越好,但通過前面的分析,同步方法在程式碼上已經屬於最小粒度。
但是在業務上呢?
實際上執行緒安全問題只是針對同一個人。對吧?同一個人才會有寫入新增的執行緒安全問題,不同人之間其實是互不干擾的。
但是同步方法針對的是所有人。所有執行緒執行到這一步的時候都被阻塞,等待鎖。
那麼把鎖物件降低到人員ID呢?
public void upsert(){
synchronized (personId){
// 3.是否存在於新增人員表
TRiskPerson rperson = riskPersonMapper.selectOne();
// 4.upsert新增人員表
if (rperson != null) {
// 5.update by personId
} else {
// 6.insert by personId
}
}
}
因為經常關聯事件的人以萬計,所以可想而知,這樣的粒度降低肯定會帶來較大的效能提升。
經過真實資料測試,萬資料可降到小時以內。
樂觀鎖?
有的讀者可能已經看出來了,根據業務場景分析,我們知道,若干個事件關聯若干個人,它執行緒衝突到具體到個人,機率還是比較小的,這是一個典型的適用樂觀鎖的場景。
java提供的lock預設是全域性鎖,因為在業務上的最小粒度已經是個人了,所以我們在這裡使用lock的話得自己構建一個分段鎖。
提到分段鎖,javaer首先想到的應該就是concurrentHashMap?
它是怎麼實現鎖的呢?眾所周知,hashmap由陣列+連結串列組成。hashtable直接使用synchronized鎖定整個陣列,而concurrentHashMap呢,它通過segment只鎖住陣列裡面的部份元素。
這樣一來,不同segment的操作不存在競態條件,而只存在於同一segment,這時候才需要加鎖。從而降低了鎖的粒度。
假設陣列長度為16,我給0-15每個元素都建立一個鎖物件【或者按段來,0-3 4-7 8-11 12-15每個段建立一個鎖物件】,當操作不同下標的元素是不會產生競爭和鎖等待。
同樣的,我們有若干個人,想要把鎖的粒度降到最小,就得給每個人都建立一個鎖物件。
虛擬碼:
HashMap<String, ReentrantLock> locks = new HashMap<>();
/**
* 通過人員唯一標識來獲取鎖,如果不存在則新建立一把鎖
* @param personId
* @return
*/
public ReentrantLock getLock(String personId){
ReentrantLock lock = locks.get(personId);
if (lock != null){
return lock;
}
lock = new ReentrantLock();
locks.put(personId, lock);
return lock;
}
public void upsert(){
ReentrantLock lock = getLock(personId);
try {
lock.tryLock(60, TimeUnit.SECONDS);
// 3.是否存在於新增人員表
TRiskPerson rperson = riskPersonMapper.selectOne();
// 4.upsert新增人員表
if (rperson != null) {
// 5.update by personId
} else {
// 6.add by personId
}
} catch (Exception exception) {
//
} finally {
lock.unlock();
}
}
但最終在生產環境不會採用這種方式
1.通過
synchronized已經將鎖粒度降低到了個人,在個人層面上,鎖衝突已經非常小,樂觀鎖的優勢並不大,實現起來反而麻煩。
2.這樣會建立太多的鎖。如果採用真正的分段,將一個範圍內的人一把鎖,或者hash求模什麼的,鎖的粒度又會放大。
總之怎麼都是得不償失的。
上面第1點也可以從ConcurrentHashmap的原始碼看出。
1.7的原始碼
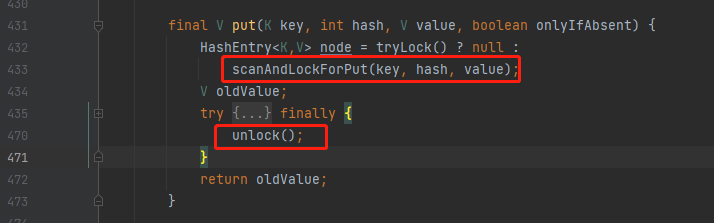
1.8的原始碼
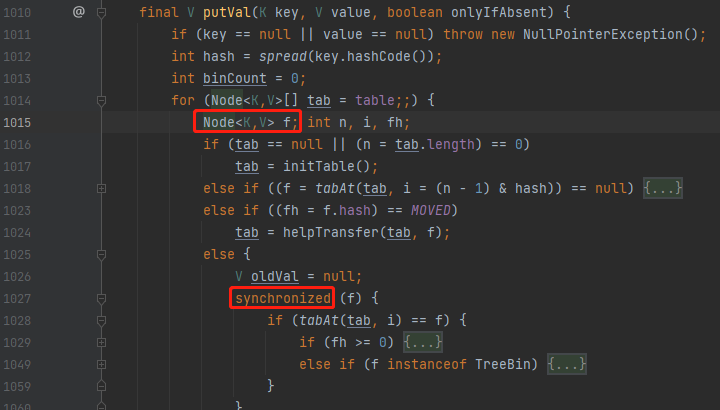
1.7使用的lock,到1.8直接換成了synchronized,因為此時的鎖粒度已經降低到了Node(Key-value entry)級別。這時候鎖競爭顯著減小,synchronized比lock更具優勢。
分散式鎖
單機應用是怎麼用上分散式鎖的呢?
你不會是為了技術而技術吧,簡稱搞事?
這就要怪搞事的**了,之前的邏輯是從事關聯到人。
現在要從人關聯到事了。
常口庫某個人手機號變了,車牌換了個,這個時候他原來手機號關聯的事件可能就沒了,新新增的手機號可能關聯了新的事件。
對吧?
從事到人,從人到事都涉及到人員資訊的更新。那麼這兩塊業務邏輯程式碼不一樣,但涉及到同一記錄的查詢和修改,所以兩邊都加同一把鎖。
所以這裡雖然是單機應用,但是就得用到分散式鎖了。
因為環境中本來就有redis,所以順理成章的使用redission來實現一個分散式鎖,實現起來也比較簡單方便。原理這裡就不展開了。
後記
很多網友是不是有過這樣的疑惑:
我在一個很low的平臺,我在一個很low的專案裡做一個CRUD boy。
我沒有高並行大流量分散式的實際場景,怎麼學習這些技術呢?
背了忘忘了背,沒有實戰經歷,面試前背了不少八股文,一問深點就露餡。

螢幕前的你以為我在罵你?
其實我在自嘲而已。
我所從事的專案對於搞巨量資料來說,平臺資料量還是真蠻大,但是對於web開發來說,真的不太友好。需求一天3變,最重要的是一個平臺真沒什麼流量,就內部人員使用,如果有個幾百上千人使用,說明系統真的做得很優秀。
在這樣的一些個業務場景下,怎樣不荒廢web經歷,最大限度提升技術能力呢?
以上只不過是我的一點點小小的努力罷了。
比如,前文小小的騙了一下大家。事實上,這其實只是一個半邊緣化的產品。甲方客戶也根本沒怎麼催我。
比這更悲傷的是,客戶根據沒怎麼使用。
前面說到的功能,只要能實現功能就行。客戶根據沒有精力來關心效率問題。
後面的優化都只是我個人行為。
雖然小小的騙了一下大家,但優化是真的在做優化。
我自己當過面試官,更是求職者。我自己的感受,有的時候八股文是不得已,因為簡歷上真的沒有東西可寫,可問。那怎麼辦呢?
至少,下次求職的時候,當面試官問到八股文高頻面試題concurrentHashMap的實現原理。我能結合這段優化的經歷簡單提提原理相通的部份,證明不是單純的在背是吧?
來,乾了這杯雞湯!
