時延檢測利器-uftrace
本文來自部落格園,作者:T-BARBARIANS,轉載請註明原文連結:https://www.cnblogs.com/t-bar/p/16898892.html 謝謝!
篇幅較長,閱讀耗時告警!
一、前言
作為後臺程式的開發人員,應用程式的效能一直是我們的核心關注點。
大到業務程式的架構設計、支撐業務的元件選型,小到具體某些功能相似方法的效能橫向對比、編譯優化、甚至摳某一行程式碼,目的都是為了給我們的程式插上翅膀。
有了這些就夠了麼?顯然不是的,因為做到了這些,實際的綜合表現還是未知的。就像生產一款新型汽車,組裝好了你得拉出來溜一溜,對照眾多測試用例,核驗各項設計指標。
本文要介紹的就是藉助uftrace工具,核查C/C++/Rust程式中每一個函數的執行耗時,在此基礎上,優化耗時大的函數,真正為我們的程式起飛打下堅實基礎。
二、拋磚引玉
介紹uftrace之前,先簡單聊一聊perf。
perf是c/c++領域效能分析的一大利器。perf可以統計過去一段時間裡,所有被執行函數和指令的CPU使用總時間,通過統計報表的形式,直觀展示熱點函數和指令的CPU佔比。例如下圖一所示,開發者可以通過對熱點的針對性分析,達到程式效能優化的目的。

圖 1
perf完美了麼,就沒有它不能覆蓋的效能分析場景了麼?顯然不是,perf是基於過去一段時間的所有累計之和,是從宏觀的角度去分析。那從微觀角度,比如我有一個需求:有沒有這樣的一種工具,它可以記錄某個使用者態函數在過去一段時間裡,每一次執行的單獨耗時,以及它的完整呼叫鏈?從而挖出宏觀角度發現不了的深坑!
例如一個「hello world」函數,大部分時間該函數的執行時長都比較一致,但是會偶發執行時長大幅增加的情況,那這背後的原因就值得我們去深入分析。

圖 2
perf tools的ftrace具備「記錄函數每一次的執行耗時」能力,但是ftrace是基於核心的,只能跟蹤分析linux核心中各種函數的執行耗時。這裡我使用trace-cmd工具(ftrace的一個命令列工具,大大簡化ftrace的使用)來記錄「do_page_fault」缺頁中斷函數在一段時間範圍的執行耗時。
1、只檢視函數的每一次執行耗時。
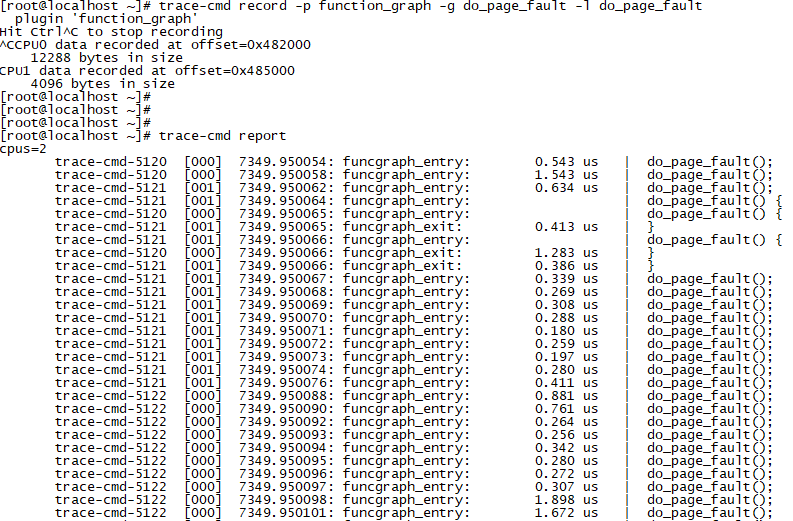
圖 3
由圖3可知,do_page_fault在核心的每一次執行,耗時都集中在1us左右,短時間內未見異常。
2、檢視do_page_fault每次耗時,以及函數內部各子函數的執行耗時。
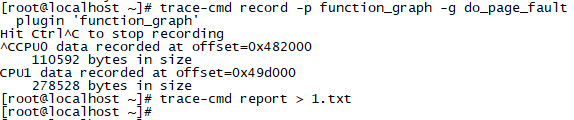
圖 4
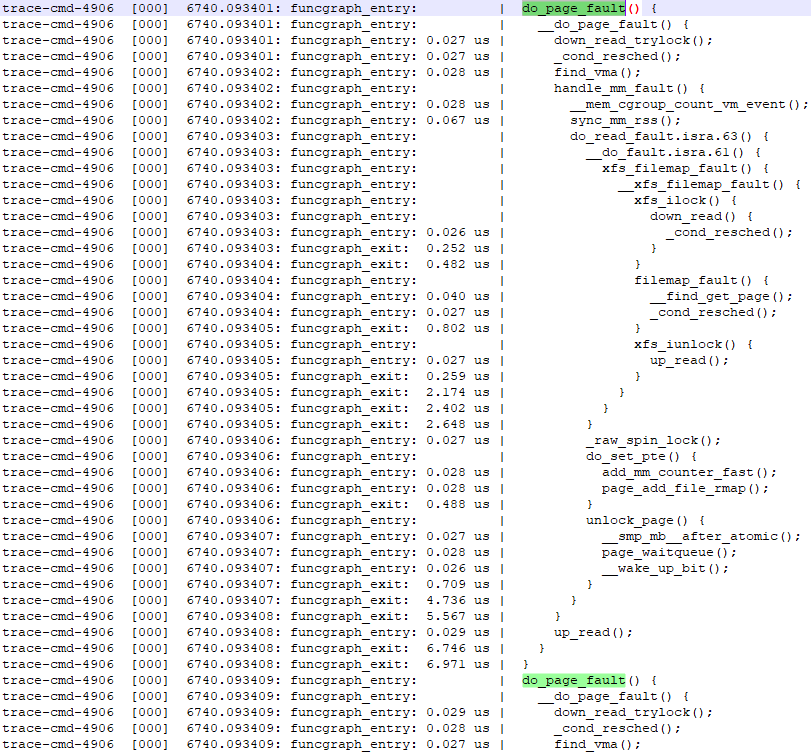
圖 5
圖5直接展示了do_page_fault函數內部各子函數的執行耗時。假設當某一次do_page_fault耗時異常,那就可以通過紀錄檔準確定位到某個異常的子函數,這樣對我們定位問題是非常有用的。
那使用者態呢,有分析和記錄使用者態函數執行耗時的工具麼?答案是當然有,優秀的工具鳳毛麟角,uftrace百裡挑一!
三、uftrace簡介
uftrace是一個分析C/C++/Rust使用者態程式效能,且支援多執行緒效能分析的開源工具。
(1)安裝簡介
1、獲取最新Release安裝包,https://github.com/namhyung/uftrace
2、解壓安裝包,執行相關設定,編譯,安裝命令
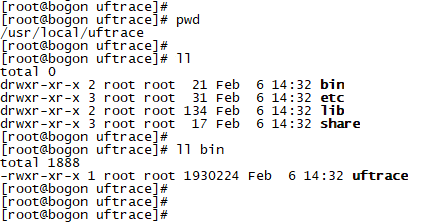
最後,在指定的安裝目錄:/usr/local/uftrace下,有如下目錄,uftrace的可執行程式就位於bin目錄下。
(2)uftrace初露鋒芒
如何使用uftrace呢?通過一個demo,我們先來實踐一下uftrace的基本使用方法,以及初步介紹uftrace的時延分析方法。
有如下malloc多執行緒程式,每一個執行緒執行10S,且在每一個執行緒裡會不斷的多次重複執行malloc()和free()。
另外:
1、編譯選項裡要新增引數 -pg(使編譯器在函數入口插入對mcount()樁函數的呼叫,從而實現每個函數的耗時記錄);
2、去掉所有優化選項-O,否則對於龐大的程式,uftrace只能展示優化後程式碼的序列執行順序,非常不利於我們對照程式碼進行問題排查。
1 #include <iostream> 2 #include <pthread.h> 3 #include <unistd.h> 4 #include <sys/syscall.h> 5 6 using namespace std; 7 8 #define gettid() syscall(__NR_gettid) 9 10 // g++ -g -pg -o multi_thread_malloc -std=c++11 multi_thread_malloc.c -lpthread 11 12 void *malloc_time_delay(void *para) 13 { 14 int last_time; 15 int current_time; 16 int malloc_times = 0; 17 char *ptr; 18 19 last_time = time(NULL); 20 current_time = time(NULL); 21 22 //cout << "thread id:" << gettid() << ", malloc test begin" << endl << endl; 23 24 while(1) { 25 26 if(current_time - last_time >= 10) { 27 break; 28 } 29 30 ptr = (char *)malloc(1024); 31 if(ptr == NULL) { 32 cout << "malloc error" << endl; 33 break; 34 } 35 36 free(ptr); 37 38 malloc_times++; 39 current_time = time(NULL); 40 usleep(1000); 41 } 42 43 cout << "thread id:" << gettid() << ", malloc test over, malloc total times:" << malloc_times << endl; 44 pthread_exit(NULL); 45 } 46 47 int main(int argc, char *argv[]) 48 { 49 int cnt; 50 int max_thread_num = 2; 51 52 pthread_t thread_ptr[8]; 53 54 for(cnt = 0; cnt < max_thread_num; ++cnt) { 55 if(pthread_create(&thread_ptr[cnt], NULL, malloc_time_delay, NULL)) { 56 cout << "malloc_time_delay thread create failed" << endl; 57 return -1; 58 } 59 } 60 61 for(cnt = 0; cnt < max_thread_num; ++cnt) { 62 pthread_join(thread_ptr[cnt], NULL); 63 } 64 65 return 0; 66 }
執行如圖6所示的命令:
/usr/local/uftrace/bin/uftrace --time record ./multi_thread_malloc
--time表示記錄時間資訊,record表示使用分析模式。程式執行完畢後,會在當前目錄生成uftrace.data目錄,裡面記錄了程式執行過程中採集到的相關資訊。當然,也可以在程式執行過程中通過:kill -15 $(pid)結束程式,uftrace會儲存程式結束前的採集資料,方便我們分析長時間執行的程式。
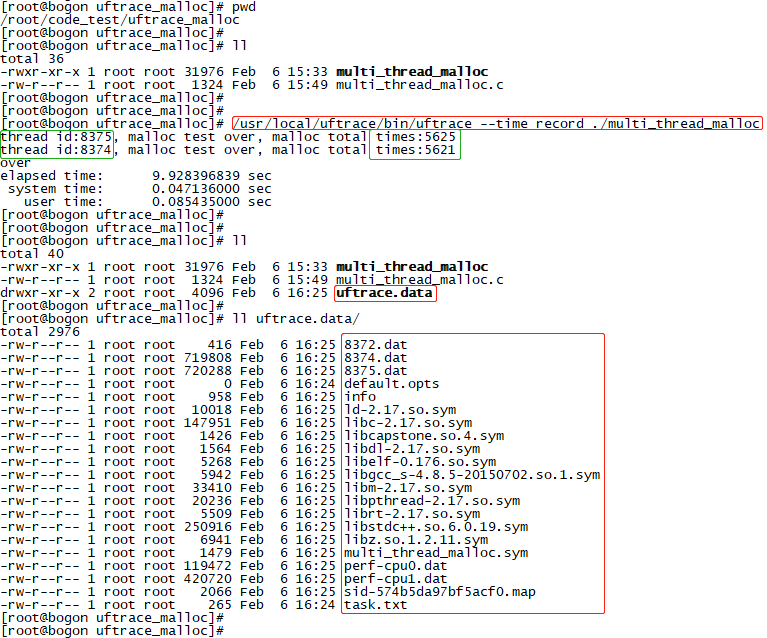
圖 6
通過replay模式檢視multi_thread_malloc程式的時延資訊。雖然記錄了函數呼叫鏈和每個函數的執行時間,是不是總感覺亂亂的?那是因為uftrace把多執行緒的所有資訊按時間順序序列記錄啦,導致記錄資訊有交叉。
結果擷取片段:
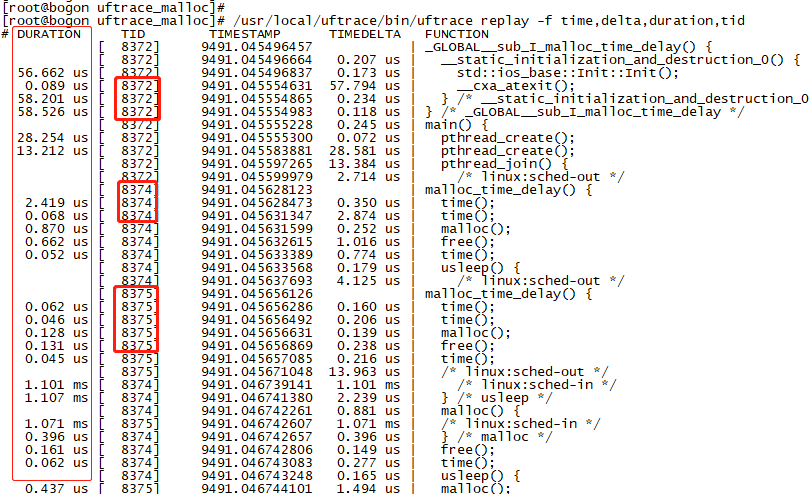
圖 7
升級一下命令,增加對執行緒id的過濾,一下子就清爽了很多,只展示了thread-8374隨時間序列執行的執行鏈(結果只擷取了片段)。
/usr/local/uftrace/bin/uftrace replay -f time,delta,duration,tid --tid 8374
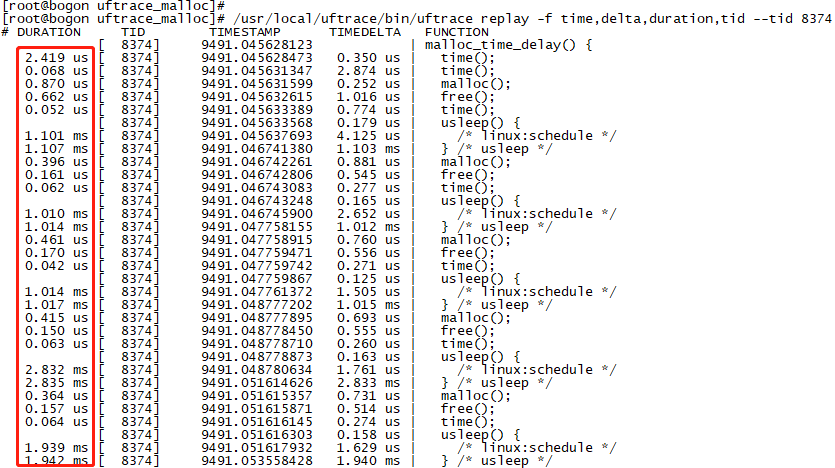
圖 8
但是問題又來了,我怎麼知道眾多的malloc函數裡是否存在超長執行的情況呢?
那就使用時間過濾條件和函數過濾條件試試,比如檢視是否存在執行耗時大於1us的malloc函數。
/usr/local/uftrace/bin/uftrace replay -f time,delta,duration,tid --tid 8374 -t 1us --filter=malloc
結果擷取片段:

圖 9
問題又來了,受螢幕限制,沒法檢視完所有的malloc函數執行耗時。那就把過濾後的結果進行重定向吧,通過檔案檢視所有的malloc執行耗時。
/usr/local/uftrace/bin/uftrace replay -f time,delta,duration,tid --tid 8374 -t 1us > thread-8374.log
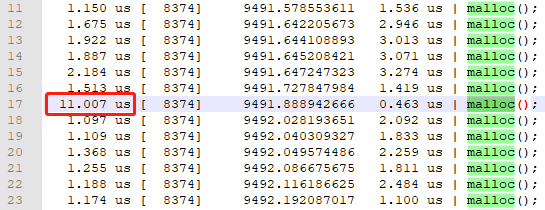
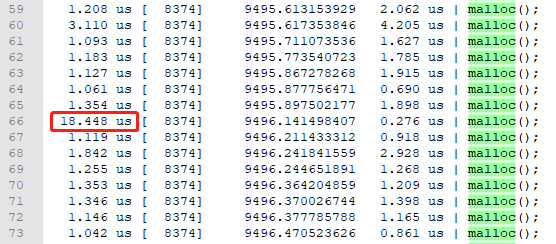
圖 10
multi_thread_malloc只是一個簡單範例,通過uftrace分析,還真有波動較大的malloc執行耗時,不過都是us級,影響不大。但是uftrace提供的這種分析能力,可以讓我們有機會發現大型,多執行緒使用者態程式在執行過程中的明顯耗時異常,從而挖掘出業務程式碼中隱藏的深坑,這與核心使用的ftrace異曲同工!
四、uftrace大顯身手
我的程式碼邏輯沒有問題(高光時刻)!看似很OK,現實很打臉(尬得一匹)。其實邏輯沒有問題,不代表就是一份好程式碼。
接下來說說uftrace在我們業務系統中解決的問題吧。
(1)背景
我們有一個大型的多執行緒應用程式,程式碼量大,框架邏輯非常複雜。基於歷史原因,該程序裡同時有一個超時檢測執行緒,專門用於檢測是否存在任務執行超時、超長的工作執行緒,如果有工作執行緒出現超時執行情況,就會產生相關告警資訊。
(2)問題現象
家裡測試千百遍,執行很爽,很流暢,從未報執行緒執行超時。但是使用者現場卻不定時,不定期的出現任務執行緒超時告警,少的時候一兩個,多的時候所有執行緒都在報任務超時,且超時都是秒級往上。好比監測中的心電圖,突然出現一個突刺衝高,或者多個執行緒某段時間集體衝高,簡直要了老命。

執行緒超時少發時,還能扛住現場業務流量。執行緒超時多發時,完全cover不住,丟包嚴重,造成了非常大的負面影響。老闆說:「解決不了就給我立馬滾蛋!」

(3)嘗試的解決手段
問題很棘手,腦瓜嗡嗡嗡。
1、嘗試過perf,但是perf是基於長時間的綜合統計,根本不知道偶發的超時突刺出現在哪;
2、嘗試過pstack,可是這個命令又卡又慢,等返回資訊時,採集到的說不定是已經超時後的棧資訊;
3、嘗試過超時出現時,主動拋異常,並列印堆疊資訊。看似有希望,但是捕捉到的有可能只是其中一段資訊,或者說是超時執行鏈中的某一小段,資訊量太少,根本沒法站在更宏觀的角度去觀察問題所在。
確實,對於這種偶發性超時突刺問題,之前並沒有發現比較好的定位手段。
4、帶著相關問題搜尋了很多資訊,gprof是第一個我覺得有希望解決問題的工具,它是一個程式執行時間監測工具,可以統計出各個函數的呼叫次數、時間、以及產生函數的呼叫圖。但是使用後發現一個致命缺點:不支援多執行緒,只有放棄。
5、繼續帶著相關關鍵詞,github搜尋一通,終於發現了uftrace,作用跟gprof類似,且完全支援多執行緒。寫了一個前文第三部分,第(2)節「uftrace初露鋒芒」的demo,經過驗證後,得到了上面例舉圖片的結果。心中一陣莫名的驚喜,至少我有了可以嘗試定位問題的手段。
(4)問題舉例
問題1:迴圈+樹遍歷
使用uftrace執行我們的被監測程式,出現超時告警紀錄檔後,手動Kill掉程式,得到了過去一段時間該程序的所有執行紀錄檔。
心情忐忑又焦急,一是擔心抓不到問題點;二是紀錄檔量很大,需要使用前面的相關過濾手段產生紀錄檔檔案,然後再把紀錄檔切割分片(split命令,推薦)為很多小份紀錄檔(紀錄檔大了電腦沒法開啟了。。。),最後才能詳細的研究相關紀錄檔。
功夫不負有心人,先上圖(圖比較寬,受排版影響,有些模糊)。

圖 11
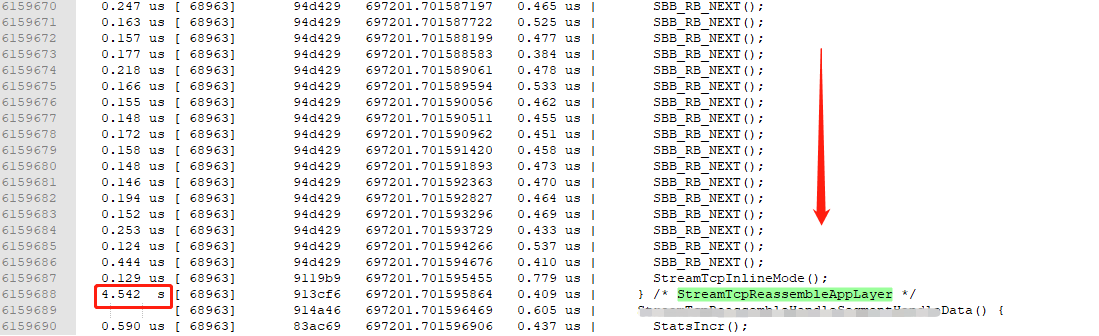
圖 12
抓取結果如上圖所示,執行鏈實在太長,只擷取了開始和結束的部分資訊。
紀錄檔說明:
1、上帝角度。函數呼叫鏈非常清楚。執行緒ID:68963隨時間遞增的執行過程列印得明明白白。
2、問題證據。記錄了函數StreamTcpReassembleAppLayer的執行耗時為4.542秒,直接把執行緒68963卡死。
3、耗時原因。在函數裡有一個while迴圈,第一次while迴圈時,SBB_RB_NEXT函數只執行了1次;第二次while迴圈時,SBB_RB_NEXT執行了2次;依次遞增,到最後一次while迴圈時,SBB_RB_NEXT執行了8800+次;整個while迴圈裡,執行了300多萬次SBB_RB_NEXT!
站在上帝的視角,發現問題的同時還抓到了證據!這就是uftrace的價值所在!
問題分析:
1、為什麼家裡不會復現?家裡的測試資料,while執行幾十,上百次到頂。通常也是幾百或者上千微秒,耗時很短,問題根本無法復現。
2、耗時原因是什麼?資料重組導致外層按資料總個數迴圈,每一次的外層迴圈再巢狀了一次裡層按偏移遍歷樹的操作,導致出現N*M的操作。萬萬沒想到居然還有這種流量存在,也進一步說明了當前使用的資料結構存在缺陷。
解決方法:
現場的快速解決方式:某個異常資料超過設定的閾值後直接砍斷。業務先恢復了再說,哈哈哈!
問題2:系統呼叫access
自從解決了上面的重大問題,現場業務再也沒有出現過超時告警了,老闆最近也不叫我立馬滾蛋了。可是好景不長,執行緒超時告警又出現了,不過這次是出現在家裡,還用不著被老闆威脅!
再次秀出獨門絕技,三下五除二就把問題給捉住了,老闆揚起嘴角笑了笑並說道:「下午請你吃個餅」,但是閉口不提漲工資。
結果如下圖所示:
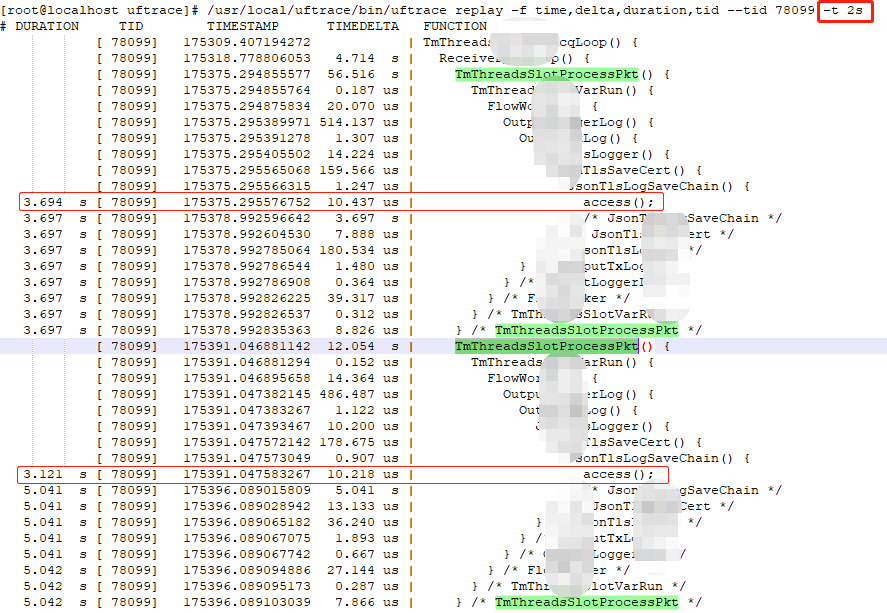
圖 13
紀錄檔說明:
使用了條件「-t 2」,檢視紀錄檔裡是否存在大於2s以上的函數耗時。結果還真有,居然是access,真是想不到是它!
問題分析:
為什麼access系統呼叫造成了長延時?後來才知道是有位兄弟會使勁的往某個目錄下新增檔案,一個目錄下居然達到了上萬個檔案,然後某個時候又會去讀取其中的某個檔案,結果就是卡死!還是印證了前面提到過的一句話:程式碼沒問題不代表就是份好程式碼。
解決方法:
寫檔案改為寫資料庫,把所有要儲存的檔案資訊按id存到資料庫。
uftrace使用技巧tip:
1、record模式,使用-F,只記錄你懷疑的大函數,可以減少紀錄檔量;
2、record模式,使用-t,只記錄大於時間引數t的執行紀錄檔,相當於檢查業務執行過程中是否存在偶發時延,同時可以減少很多紀錄檔量;
3、replay模式,可以使用-t,檢視結果中是否存在大於指定時間引數以上的執行函數,幫助我們快速定位時延位置;
4、replay模式,可以使用-r,快速獲取指定時間範圍內的紀錄檔資訊,也是一種很好的過濾能力。這個能力,我給社群提過一個BUG,且得到了修正。https://github.com/namhyung/uftrace/issues/1593
其它技巧,uftrace安裝包的 /doc/uftrace.html檔案有很詳細的介紹,真的寫得非常好,朋友們可以多多參考。
五、結語
通常,我們很難觀察到業務程式的偶發時延,想挖掘出偶發時延的背後原因更是難上加難!萬幸還有uftrace的存在,可以針對性的解決這一類問題。
現實中總有很多意料之外的事情,不僅僅是技術,生活亦是如此,即使我們在這之前已經做了很充分的準備工作。遇到問題時只要我們不放棄,且經得住持久戰,那解決問題後的成就感就會讓自己覺得之前的所有付出都是值得的。
技術是不斷實踐積累的,在此分享出來與大家一起共勉!
碼字不易,把解決問題的方法闡述清楚更不容易。如果文章對你有些許幫助,還請各位技術愛好者登入點贊呀,非常感謝!
本文來自部落格園,作者:T-BARBARIANS,轉載請註明原文連結:https://www.cnblogs.com/t-bar/p/16898892.html 謝謝!