飛槳paddlespech 語音喚醒初探
PaddleSpeech提供了MDTC模型(paper: The NPU System for the 2020 Personalized Voice Trigger Challenge)在Hey Snips資料集上的語音喚醒(KWS)的實現。這篇論文是用空洞時間折積網路(dilated temporal convolution network, DTCN)的方法來做的,曾獲the 2020 personalized voice trigger challenge (PVTC2020)的第二名,可見這個方案是比較優秀的。想看看到底是怎麼做的,於是我對其做了一番初探。
1,模型理解
論文是用空洞時間折積網路(DTCN)的方法來實現的。為了減少引數量,用了depthwise & pointwise 一維折積。一維折積以及BatchNormal、relu等組成1個DTCNBlock, 4個DTCNBlock組成一個DTCNStack。實現的模型跟論文裡的有一些差異。論文裡的模型具體見論文,實現的模型框圖見下圖:
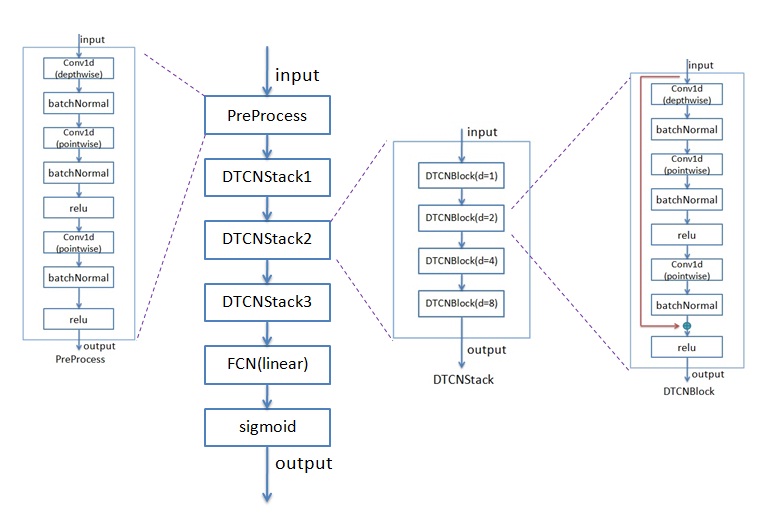
引數個數是比較少的,相對論文裡的也少了不少。剛開始我不太相信,後來我對網路中的模型每層都算了引數個數,的確是這麼多。想了一下,對比paper裡的模型,引數變少主要有兩點:一是少了一些模組,二是FCN由linear替代(linear替代FCN會少不少引數)。
模型用的特徵是80維的mel-filter bank,即每幀的特徵是一個80維的資料。把一個utterance的這些幀的特徵作為模型的輸入,輸出是每一幀的後驗概率,如果有一幀的後驗概率大於threshold,就認為這一utterance是關鍵詞,從而喚醒裝置。舉例來說,一個utterance有158幀,模型的輸入就是158*80的矩陣(158是幀數,80是特徵的維度),輸出是158*1的矩陣,即158個後驗概率。假設threshold設為0.8,這158個後驗概率中只要有一個達到0.8,這個utterance就認為是關鍵詞。
2,環境搭建
PaddleSpeech相關的檔案裡講了如何搭建環境(Ubuntu下的),這裡簡述一下:
1)建立conda環境以及啟用這個conda環境等:
conda create --name paddletry python=3.7
conda activate paddletry
2)安裝 paddelpaddle (paddlespeech 是基於paddelpaddle的)
pip install paddlepaddle
3)clone 以及編譯paddlespeech 程式碼
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
pip install .
3,資料集準備
資料集用的是sonos公司的」hey snips」。我幾天內用三個不同的郵箱去註冊申請,均沒給下載連結,難道是跟目前在科技領域緊張的中美關係有關?後來聯絡到了這篇paper的作者, 他願意分享資料集。在此謝謝他,真是個熱心人!他用百度網路硬碟分享了兩次資料集,下載後均是tar包解壓出錯,估計是傳輸過程中出了問題。在走投無路的情況下嘗試去修復壞的tar包。找到了tar包修復工具gzrt,運氣不錯,能修復大部分,關鍵是定義train/dev/test集的json檔案能修復出來。如果自己寫json檔案太耗時耗力了。Json中一個wav檔案資料格式大致如下:
{
"duration": 4.86,
"worker_id": "0007cc59899fa13a8e0af4ed4b8046c6",
"audio_file_path": "audio_files/41dac4fb-3e69-4fd0-a8fc-9590d30e84b4.wav",
"id": "41dac4fb-3e69-4fd0-a8fc-9590d30e84b4",
"is_hotword": 0
},
資料集中原有wav檔案96396個,修復了81401個。寫python把在json中出現的但是audio_files目錄中沒有的去掉,形成新的json檔案。原始的以及新的資料集中train/dev/test wav數如下:

從上表可以看出新的資料集在train/dev/test上基本都是原先的84%左右。
4,訓練和評估
在PaddleSpeech/examples/hey_snips/kws0下做訓練。訓練前要把這個目錄下conf/mdtc.yaml裡的資料集的路徑改成自己放資料集的地方。由於我用CPU訓練,相應的命令就是./run.sh conf/mdtc.yaml 。 訓練50個epoch(預設設定)後,在驗證集下的準確率為99.79%(見下圖),還是不錯的,就沒再訓練下去。

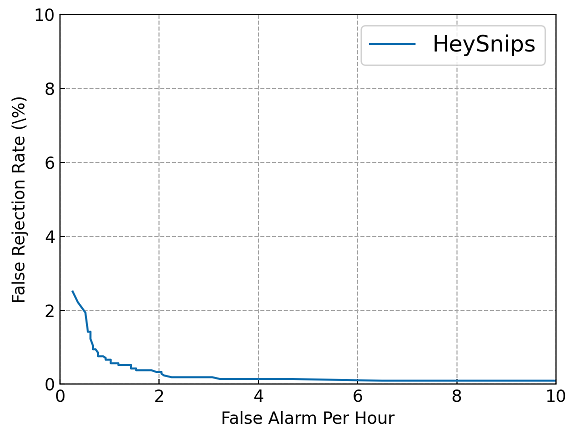
評估出的DET圖如下:
Paddlespeech也提供了KWS推理命令: paddlespeech kws。需要研究一下這個命令是怎麼用的,看相關程式碼。--input 後面既可以是一個具體的wav檔案(這時只能評估一個檔案),也可以是一個txt檔案,把要評估的檔名都寫在裡面,具體格式如下圖:

--ckpt_path是模型的路徑,--config是設定組態檔,也就是mdtc.yaml。因為要對整個測試集做評估,所以--input要寫成txt的形式。Hey Snips資料集wav檔案都在audio_files目錄下,需要寫指令碼把測試集的wav檔案取出來放在一個目錄下(我的是heytest), 還要寫指令碼把這次測試檔案的檔名以及路徑寫到上圖所示的txt檔案裡。同時還要在paddlespeech 里加些程式碼看推理出的值是否跟期望值一致,做些統計。把這些都弄好後就開始做執行了,具體命令如下圖:

最終測試集下的結果,見下圖:

共19442個檔案,跟期望一致的(圖中correct的)是19410個,準確率為99.84%。與驗證集下的大體相當。