RabbitMQ真實生產故障問題還原與分析
RabbitMQ生產故障問題分析
由某一次真實生產環境rabbitMQ故障引發血案,下面覆盤問題發生原因以及問題解決方法。
1、 問題引發
由某個服務BI-collector-xx佇列出現阻塞,影響很整個rabbitMQ叢集服務不可用,多個應用MQ生產者服務出現假死狀態,系統影響面較廣,業務影響很大。當時為了應急處理,恢復系統可用,運維相對粗暴的把一堆阻塞佇列資訊清空,然後重啟整個叢集。
在覆盤整個故障過程中,我心中有不少疑惑,至少存在以下幾個問題點:
- 為什麼出現佇列阻塞?
- 某個佇列出現阻塞為什麼會影響到其他佇列的執行(即多佇列間相互影響)?
- 某個應用MQ佇列出現問題,為什麼會導致應用不可用呢?
2、 試驗佇列阻塞
某天週末在家裡,找個測試環境,安裝rabbitmq嘗試重現這過程,並做模擬測試。
寫兩個測試應用Demo(假設是兩個專案應用)分別有生產者和消費者,並分別使用佇列testA和testB。
為了儘可能還原生產的情況,一開始測試使用了同一個vhost,後面分別設定不同vhost。
生產者A,範例程式碼如下

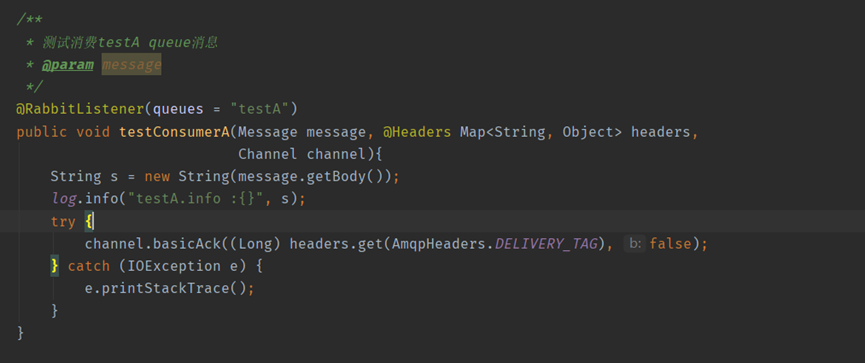
消費者A
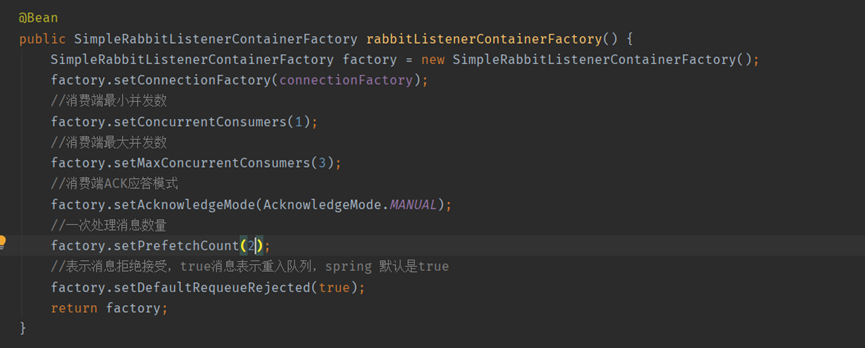
MQ設定
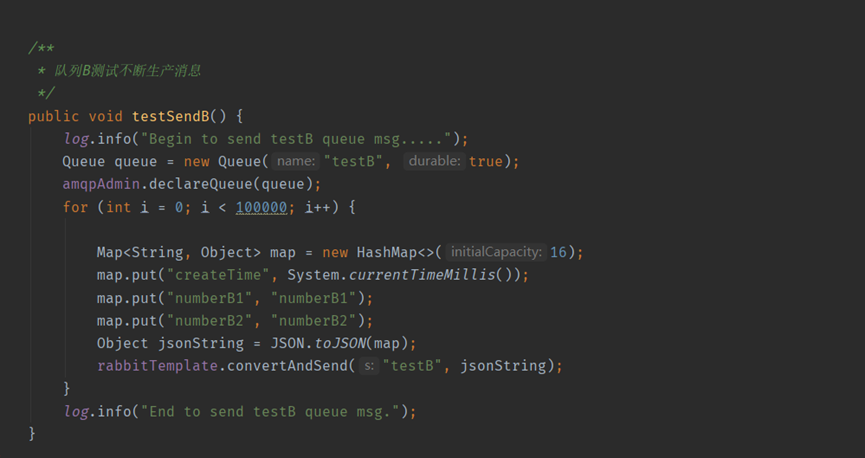
生產者B,每次生產10萬條訊息
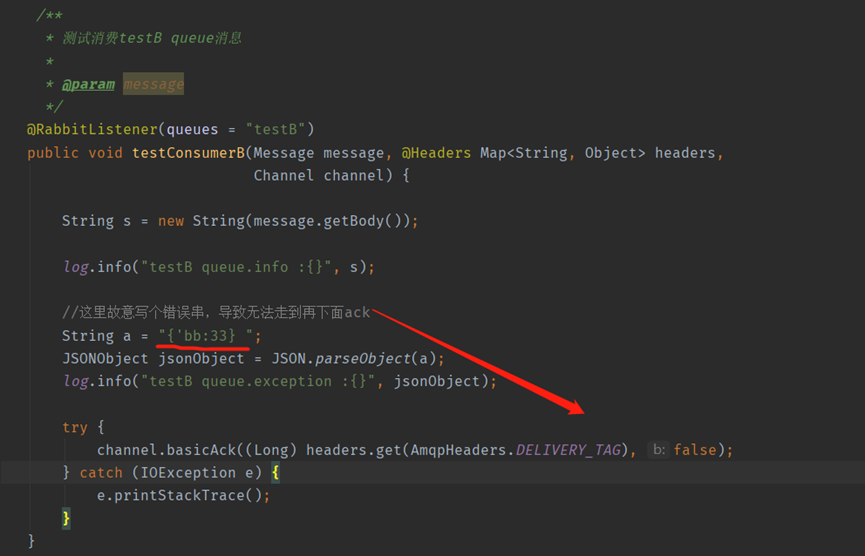
消費者B,程式碼故意寫錯(模擬出現異常的情況),不是正常的json串導致解釋json時丟擲異常
先了解一下Rabbitmq使用者端啟動連線工作過程,通過wireshark抓包分析,如下
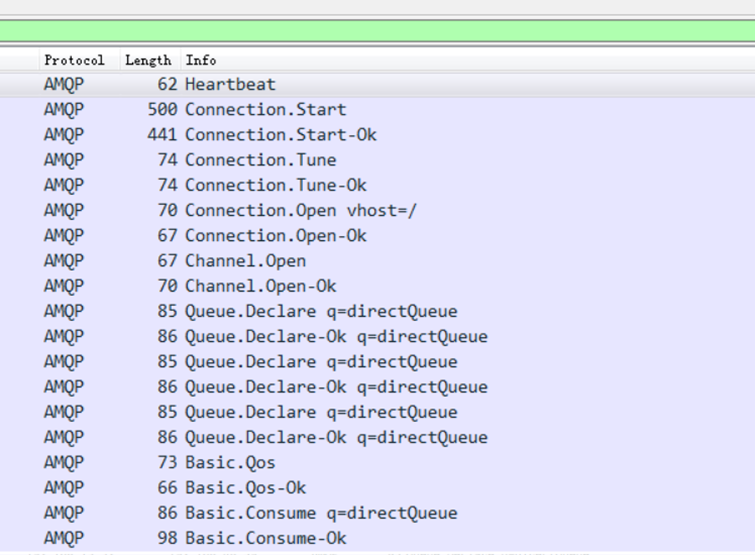
先對AMQP做一個簡單的介紹,請求的AMQP協定方法資訊,AMQP協定方法包含類名+方法名+引數,這一列主要展示了類名和方法名
Connection.Start:請求伺服器端開始建立連線Channel.Open:請求伺服器端建立通道Queue.Declare:宣告佇列Basic.Consume:開始一個消費者,請求指定佇列的訊息
詳細方法可以檢視amqp官網https://www.rabbitmq.com/amqp-0-9-1-reference.html
工作過程分析:
Basic.Publish: 使用者端傳送Basic.Publish方法請求,將訊息釋出到exchange,rabbitmq server會根據路由規則轉發到佇列中;
Basic.Deliver: 伺服器端傳送Basic.Deliver方法請求,投遞訊息到監聽佇列的使用者端消費者;
Basic.Ack: 使用者端傳送Basic.Ack方法請求,告知rabbimq server,訊息已接收處理。
兩個應用程式啟動後,通過rabbitmq管理控制檯可以觀察一些引數和監控指標
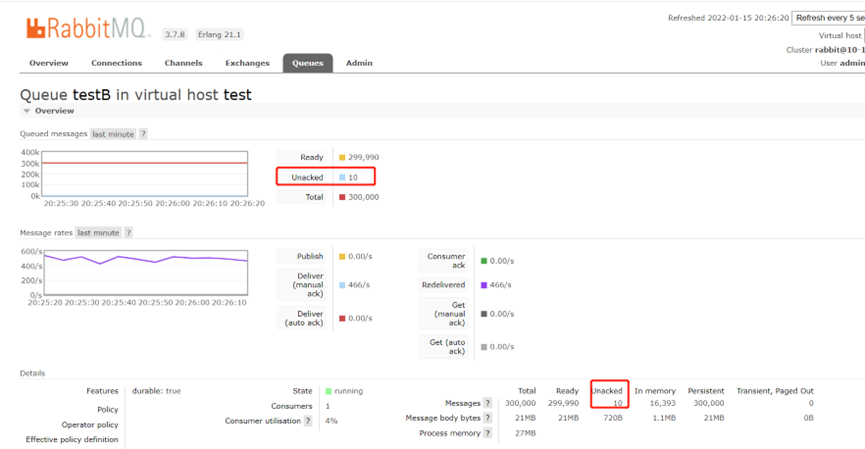
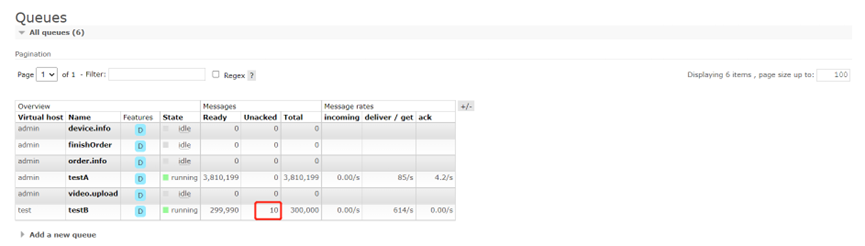
一開始A應用生產和消費都是正常的。
B消費端錯誤程式碼異常,狂刷報錯資訊
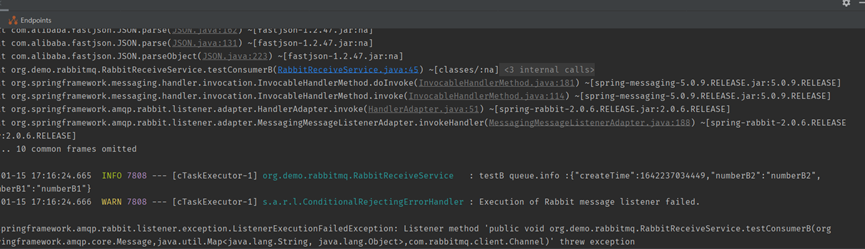
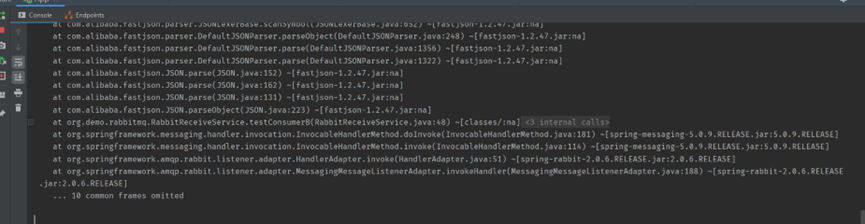
經過大概30分鐘執行,觀察A生產者應用控制檯也有出現異常資訊
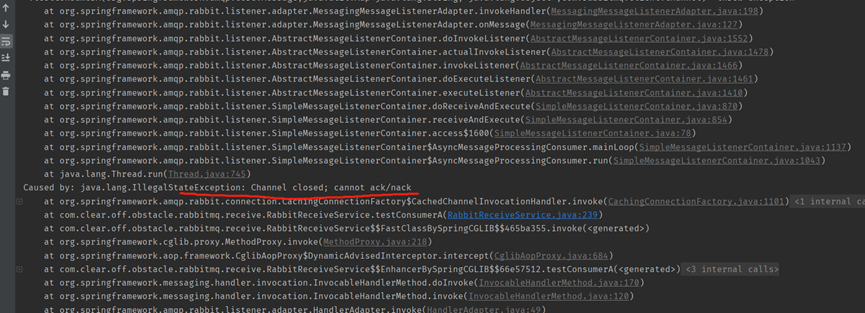
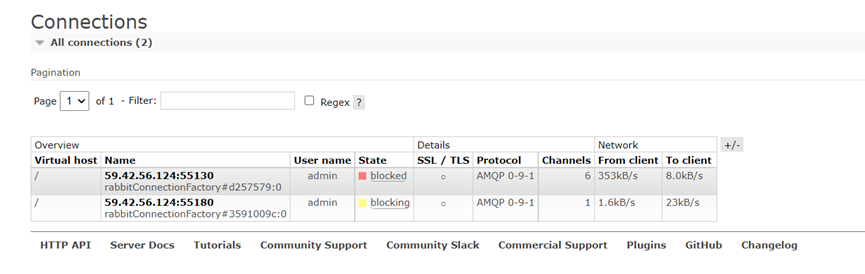
檢視伺服器端連線狀態出現blocked情況,與生產故障發生情景很類似。
此時使用者端即本機器,CPU和記憶體上漲明顯,風扇聲音很響,明顯示卡頓,再過30分鐘應用基本不可用狀態。
分析原因
上面錯誤程式碼展示了消費者B無法ack,由於沒有進行ack導致隊裡阻塞。那麼問題來了,這是為什麼呢?其實這是RabbitMQ的一種保護機制。防止當訊息激增的時候,海量的訊息進入consumer而引發consumer宕機。
RabbitMQ提供了一種QOS(服務質量保證)功能,即在非自動確認的訊息的前提下,限制通道上的消費者所能保持的最大未確認的數量。可以通過設定prefetchCount實現,自動確認prefetchCount設定無效。
舉例說明:可以理解為在consumer前面加了一個緩衝容器,容器能容納最大的訊息數量就是PrefetchCount。如果容器沒有滿RabbitMQ就會將訊息投遞到容器內,如果滿了就不投遞了。當consumer對訊息進行ack以後就會將此訊息移除,從而放入新的訊息。
通過上面的設定發現prefetch初始我只設定了2,並且concurrency設定的只有1,所以當我傳送了2條錯誤訊息以後,由於解析失敗這2條訊息一直沒有被ack。將緩衝區沾滿了,這個時候RabbitMQ認為這個consumer已經沒有消費能力了就不繼續給它推播訊息了,所以就造成了佇列阻塞。
判斷佇列是否有阻塞的風險。
當ack模式為manual,並且線上出現了unacked訊息,這個時候不用慌。由於QOS是限制通道channel上的消費者所能保持的最大未確認的數量。所以允許出現unacked的數量可以通過channelCount * prefetchCount * 消費節點數量得出。
channlCount就是由concurrency,max-concurrency決定的。
min = concurrency * prefetch *消費節點數量max = max-concurrency * prefetch *消費節點數量
由此可以得出結論
unacked_msg_count < min佇列不會阻塞。但需要及時處理unacked的訊息。unacked_msg_count >= min可能會出現堵塞。unacked_msg_count >= max佇列一定阻塞。
重點注意
1、unacked的訊息在consumer切斷連線後(如重啟)再連線,會自動回到隊頭。
2、若將ack模式改成auto自動,這樣會使QOS不生效。會出現大量訊息湧入consumer從而可能造成consumer宕機風險。
再回看程式設定,做一些分析和調整

對B消費端問題程式碼加個try-catch-finally,不管中間有何問題,都進行訊息簽收ACK。
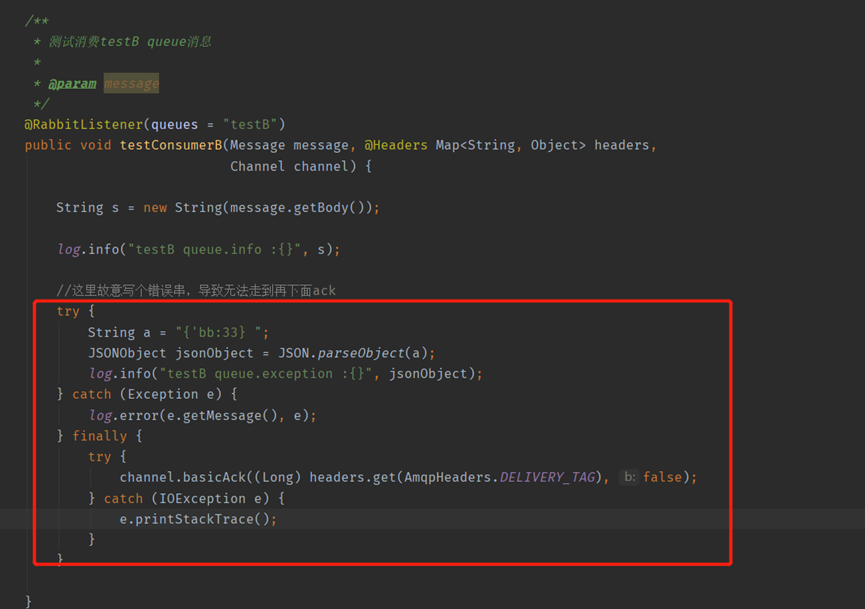
程式碼調整之後,兩個佇列正常執行,使用者端兩個應用也正常執行。

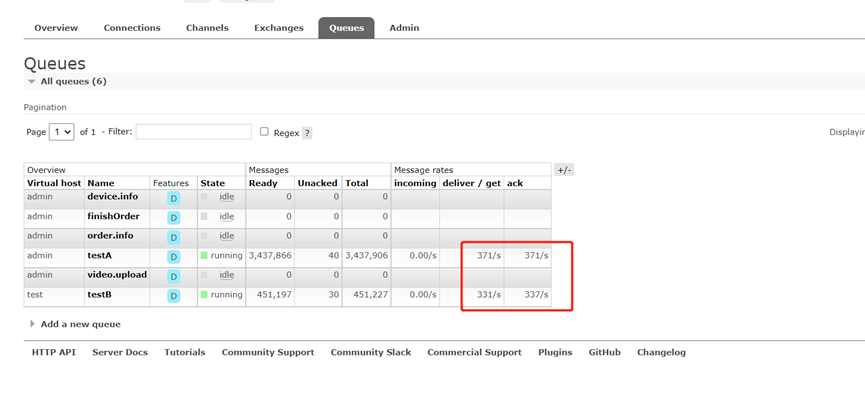
經過一段時間消費,B消費者端已經把堆積的訊息消費完了。
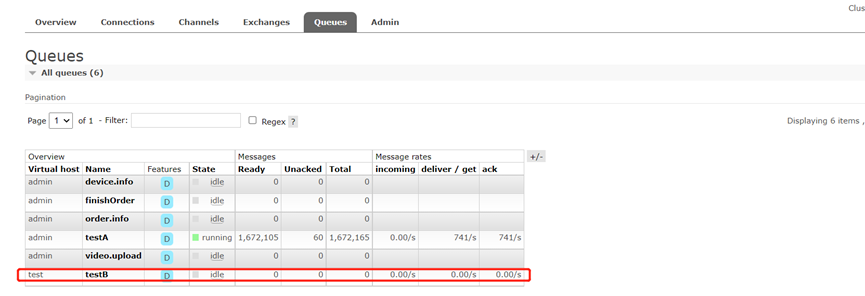
3、 第三個問題原因分析
還是檢視抓包資訊
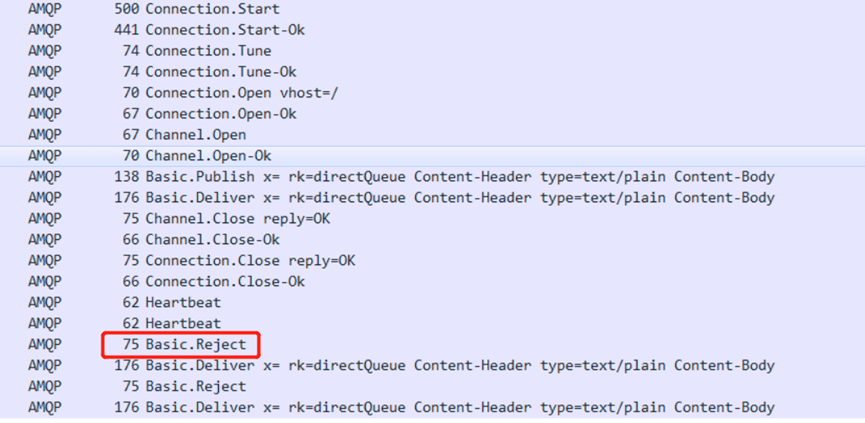
Basic.Reject: 使用者端傳送Basic.Reject方法請求,表示無法處理訊息,拒絕訊息,此時的requeue引數為true,將訊息返回原來的佇列;
Basic.Deliver: 伺服器端呼叫Basic.Deliver方法,和第一次Basic.Deliver方法不同的是,此時的redeliver引數為true,表示重新投遞訊息到監聽佇列的消費者,然後這兩步會一直重複下去。
RabbitMQ訊息監聽程式異常時,consumer會向rabbitmq server傳送Basic.Reject,表示訊息拒絕接受,由於Spring預設requeue-rejected設定為true,訊息會重新入隊,然後rabbitmq server重新投遞。就相當於死迴圈了,所以容易導致消費端資源佔用過高,特別是TCP連線數、執行緒數、IO飆升,如果個別程式帶事務或資料庫操作等連線資源得不到釋放也會佔滿,導致應用假死狀態(出現問題的時候,檢視問題應用出現大量的connection timeout錯誤報錯紀錄檔)。
因此針對性的,有些業務場景(不強調資料強一致性的場景,比如紀錄檔收集)可以設定default-requeue-rejected: false即可。
factory.setDefaultRequeueRejected(false);
會根據異常型別選擇直接丟棄或加入dead-letter-exchange中。
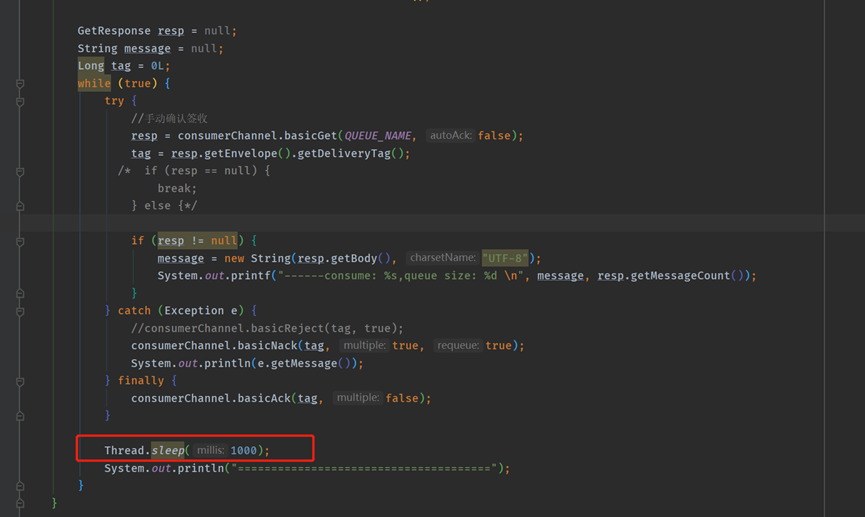
消費者端正確的使用手動確認範例結構程式碼,很重要!
try { // 業務邏輯。 }catch (Exception e){ // 輸出錯誤紀錄檔。 }finally { // 訊息簽收。 }
4、 驗證佇列設定最大長度限制
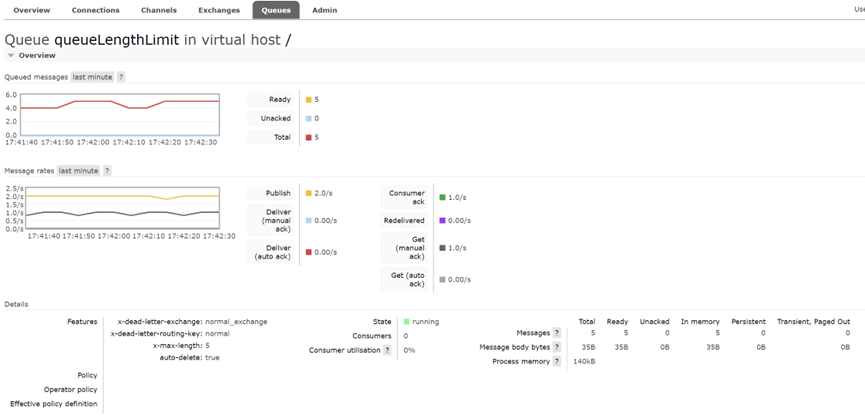
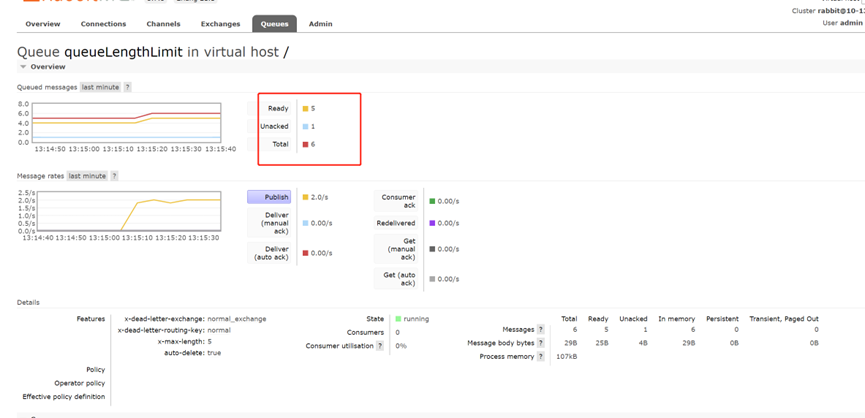
設定queueLengthLimit佇列最大長度限制 x-max-length=5
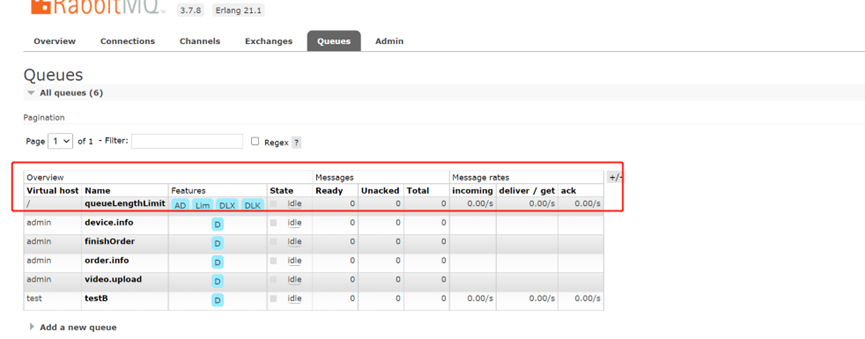
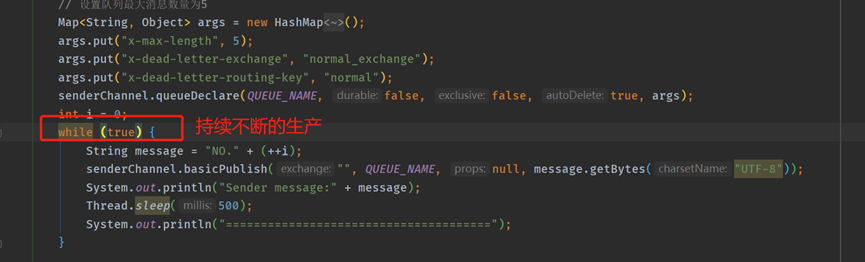
生產者原本想要生產10條訊息

由於受到佇列最大長度限制,實際上只有5條入佇列裡面。
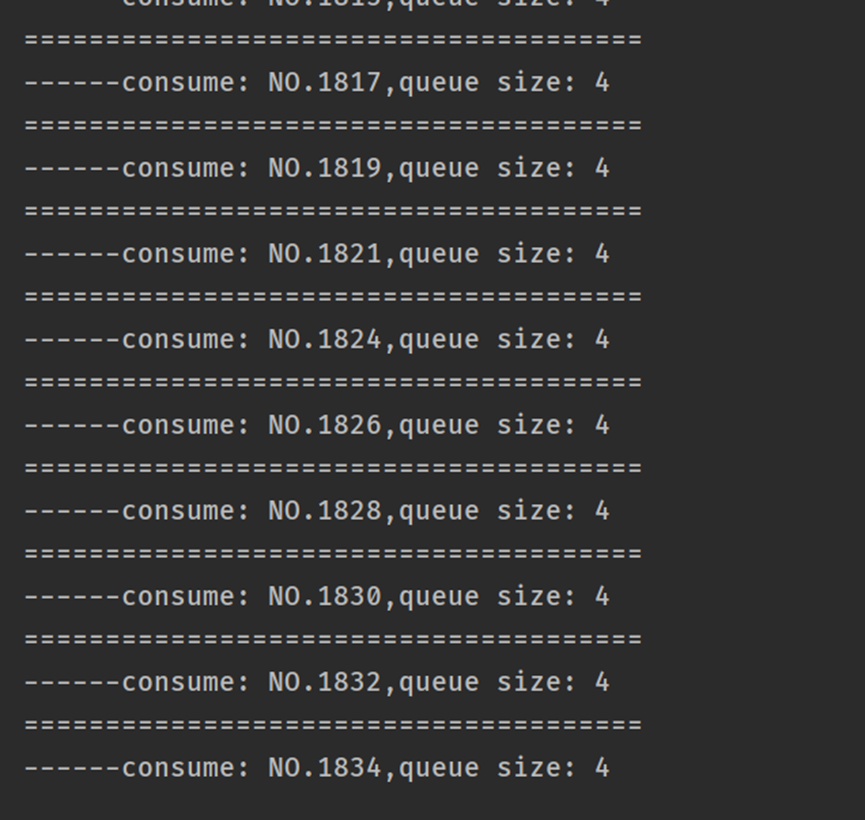
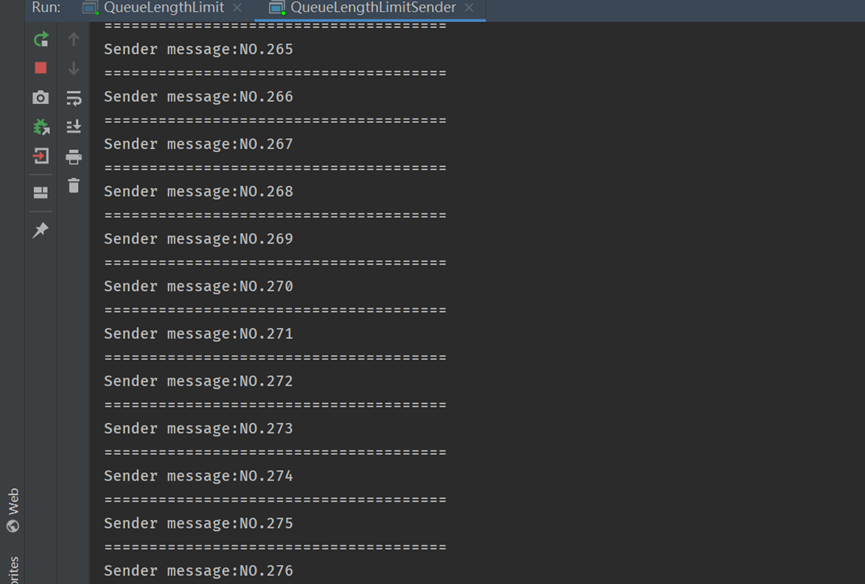
消費者拿出來的訊息,僅有5條,從NO.6~NO.10
改變消費者程式,讓生產者一直產生訊息,消費者消費速度明顯趕不上生產者的生產速度。
從消費端來看訊息是隨機性入隊的,佇列裡面一直最多5條訊息,發再多也進不了,訊息者和生產者也不會發生什麼異常,只是訊息會隨機性丟失(並沒有全部入隊)。
執行情況良好,除了訊息沒有全部入佇列 ,沒有出現異常情況
消費比較慢,本機器CPU和記憶體各項指標正常,沒有異常。
搞一個異常情況出現unack,最大佇列長度限制,是不算unack數量的,如下圖所示
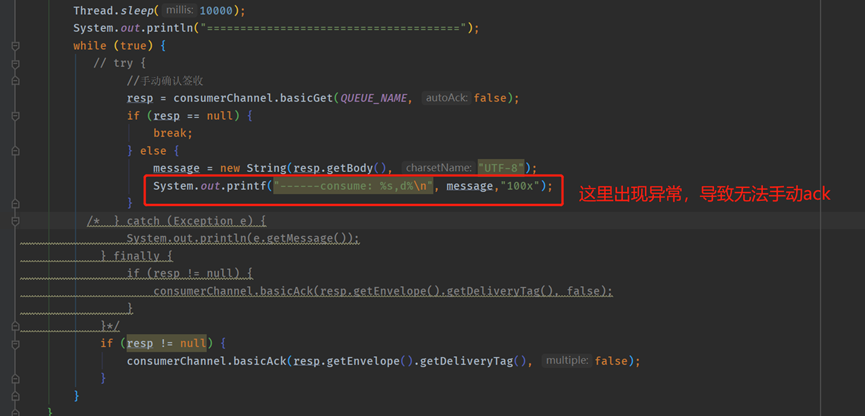

異常之後,此觀察MQ監控管理後臺
生產者不停一直在生產訊息,執行30分鐘,觀察生產者應用也是正常的的,就是訊息入不了佇列。
5、 檢查實際的業務端程式碼
再看我們業務系統消費端程式碼,消費端各種不規範寫法都有,以下例舉幾個典型
1、手動簽收有ACK,但是沒有try-catch-finally結構,消費端業務程式碼如下:
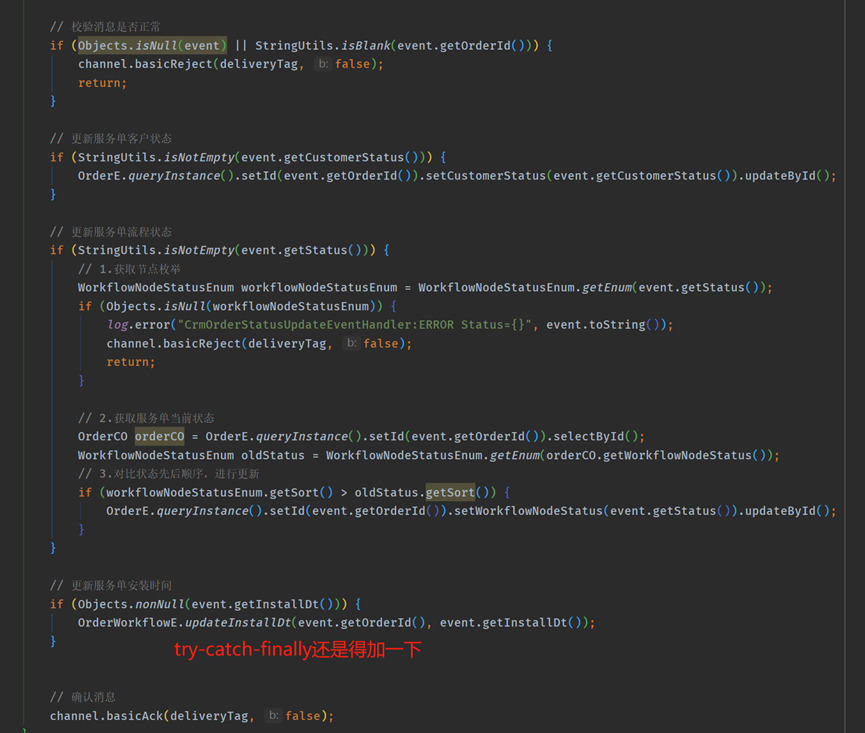
2、有try-catch-finally結構,但是deliverTag是一個固定值0,一樣的會出問題。
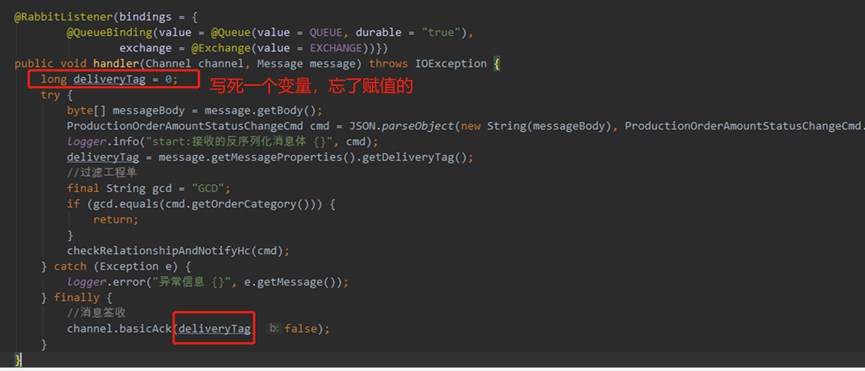
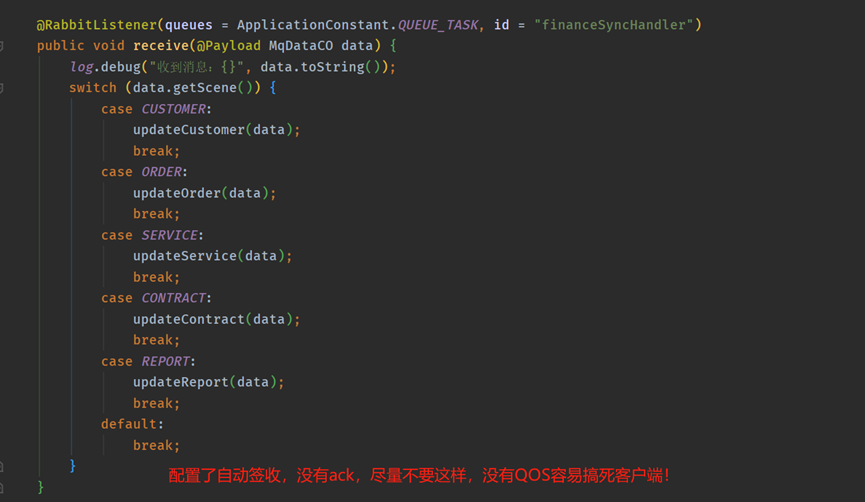
3、自動簽收確認的,大量訊息的時候,容易搞死消費端應用。
6、 總結
- 生產環境不建議使用自動ack模式,這樣會使QOS無法生效。
- 在使用手動ack的時候,需要非常注意訊息簽收,業務程式碼使用try-catch-finally處理結構,防止業務程式碼異常時無法簽收。
- 規範約束mq使用者端程式碼,正確的使用Rabbitmq設定。
- 不同業務專案設定不同的vhost可以隔離一些影響,提升rabbitmq資源使用。
- 考慮設定dead-letter-exchange,當設定了 requeue=false時,可以放入dead-letter-exchange,可以快速排查定位問題。
- Exchange和佇列的最大長度限制可以是限制訊息的數量(引數:x-max-length),或者是訊息的總位元組數(總位元組數表示的是所有的訊息體的位元組數,忽略訊息的屬性和任何頭部資訊),又或者兩者都進行了限制,兩者取小值生效,只有處於ready狀態的訊息被計數,未被確認的訊息不會被計數受到limit的限制。最大佇列設定可以限制生產端,但會造成訊息丟失風險,最大訊息數量限制,不能完全解決佇列阻塞問題。
- 儘量使用Direct-exchange,Direct 型別的 Exchange 投遞訊息是最快的。
- Direct:處理路由鍵,需要將一個佇列繫結到交換機上,要求該訊息與一個特定的路由鍵完全匹配。這是一個完整的匹配。如果一個佇列繫結到該交換機上要求路由鍵為「A」,則只有路由鍵為「A」的訊息才被轉發,不會轉發路由鍵為"B",只會轉發路由鍵為「A」;
- Topic:將路由鍵和某模式進行匹配。此時佇列需要繫結要一個模式上。符號「#」匹配一個或多個詞,符號「*」只能匹配一個詞;
- Fanout:不處理路由鍵。只需要簡單的將佇列繫結到交換機上。一個傳送到該型別交換機的訊息都會被廣播到與該交換機繫結的所有佇列上;
- Headers:不處理路由鍵,而是根據傳送的訊息內容中的 headers 屬性進行匹配。在繫結 Queue 與 Exchange 時指定一組鍵值對;當訊息傳送到 RabbitMQ 時會取到該訊息的 headers 與 Exchange 繫結時指定的鍵值對進行匹配;如果完全匹配則訊息會路由到該佇列,否則不會路由到該佇列。
寫在最後,RabbitMQ叢集做為整個平臺關鍵部件,它的好處自然不用再說,但是它也不是萬金油,一旦巖機影響很大,後果比較嚴重。怎麼用好它?我們有必要正確深入的認識並使用它,首先得擺好正確的姿勢(寫正確的使用者端程式碼、嚴謹的設定),不能隨意,否則後果很嚴重。希望經過此故障經驗教訓能與君共勉,同時也希望我的總結能夠給大家一點幫助和啟發,權當拋磚引玉。