Scrapy 常用方法以及其補充
本文作者:ZiCh
本文連結:https://www.cnblogs.com/zichliang/p/17178868.html
版權宣告:未經作者允許嚴禁轉載
JsonRequest 使用範例
使用 JsonReuquest傳送 JSON POST 請求:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
data = {
'name1': 'value1',
'name2': 'value2',
}
yield JsonRequest(url='http://www.xxx.com/xxx/xxx', data=data)
表示HTTP響應的物件,通常下載(由Downloader)並提供給爬行器進行處理。
引數詳解
- url (str) -- 此響應的URL
- status (int) -- 響應的HTTP狀態。預設為
200. - headers (dict) -- 此響應的頭。dict值可以是字串(對於單值頭)或列表(對於多值頭)。
- body (bytes) -- 反應機構。要以字串形式存取解碼文字,請使用
response.text從編碼感知 Response subclass ,如[TextResponse](https://www.osgeo.cn/scrapy/topics/request-response.html?highlight=jsonrequest#scrapy.http.TextResponse). - flags (list) -- 是一個列表,其中包含
[Response.flags](https://www.osgeo.cn/scrapy/topics/request-response.html?highlight=jsonrequest#scrapy.http.Response.flags)屬性。如果給定,則將淺複製列表。 - request (scrapy.Request) -- 的初始值
[Response.request](https://www.osgeo.cn/scrapy/topics/request-response.html?highlight=jsonrequest#scrapy.http.Response.request)屬性。這代表[Request](https://www.osgeo.cn/scrapy/topics/request-response.html?highlight=jsonrequest#scrapy.http.Request)產生了這個響應。 - certificate (twisted.internet.ssl.Certificate) -- 表示伺服器的SSL證書的物件。
- ip_address (
[ipaddress.IPv4Address](https://docs.python.org/3/library/ipaddress.html#ipaddress.IPv4Address)or[ipaddress.IPv6Address](https://docs.python.org/3/library/ipaddress.html#ipaddress.IPv6Address)) -- 從哪個伺服器發出響應的IP地址。 - protocol (
[str](https://docs.python.org/3/library/stdtypes.html)) -- 用於下載響應的協定。例如:「HTTP/1.0」、「HTTP/1.1」、「H2」
scrapy settings
# -*- coding: utf-8 -*-
# Scrapy settings for companyNews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
from DBSetting import host_redis,port_redis,db_redis,password_redis
#它是一種可以用於構建使用者代理機器人的名稱,預設值:'scrapybot'
BOT_NAME = 'companyNews'
# 它是一種含有蜘蛛其中Scrapy將尋找模組列表,預設值: []
SPIDER_MODULES = ['companyNews.spiders']
# 預設: '',使用 genspider 命令建立新spider的模組。
NEWSPIDER_MODULE = 'companyNews.spiders'
#-----------------------紀錄檔檔案設定-----------------------------------
# 預設: True,是否啟用logging。
# LOG_ENABLED=True
# 預設: 'utf-8',logging使用的編碼。
# LOG_ENCODING='utf-8'
# 它是利用它的紀錄檔資訊可以被格式化的字串。預設值:'%(asctime)s [%(name)s] %(levelname)s: %(message)s'
# LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
# 它是利用它的日期/時間可以格式化字串。預設值: '%Y-%m-%d %H:%M:%S'
# LOG_DATEFORMAT='%Y-%m-%d %H:%M:%S'
#紀錄檔檔名
#LOG_FILE = "dg.log"
#紀錄檔檔案級別,預設值:「DEBUG」,log的最低階別。可選的級別有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
LOG_LEVEL = 'WARNING'
# -----------------------------robots協定---------------------------------------------
# Obey robots.txt rules
# robots.txt 是遵循 Robot協定 的一個檔案,它儲存在網站的伺服器中,它的作用是,告訴搜尋引擎爬蟲,
# 本網站哪些目錄下的網頁 不希望 你進行爬取收錄。在Scrapy啟動後,會在第一時間存取網站的 robots.txt 檔案,
# 然後決定該網站的爬取範圍。
# ROBOTSTXT_OBEY = True
# 對於失敗的HTTP請求(如超時)進行重試會降低爬取效率,當爬取目標基數很大時,捨棄部分資料不影響大局,提高效率
RETRY_ENABLED = False
#請求下載超時時間,預設180秒
DOWNLOAD_TIMEOUT=20
# 這是響應的下載器下載的最大尺寸,預設值:1073741824 (1024MB)
# DOWNLOAD_MAXSIZE=1073741824
# 它定義為響應下載警告的大小,預設值:33554432 (32MB)
# DOWNLOAD_WARNSIZE=33554432
# ------------------------全域性並行數的一些設定:-------------------------------
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 預設 Request 並行數:16
# CONCURRENT_REQUESTS = 32
# 預設 Item 並行數:100
# CONCURRENT_ITEMS = 100
# The download delay setting will honor only one of:
# 預設每個域名的並行數:8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 每個IP的最大並行數:0表示忽略
# CONCURRENT_REQUESTS_PER_IP = 0
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY 會影響 CONCURRENT_REQUESTS,不能使並行顯現出來,設定下載延遲
#DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
#禁用cookies,有些站點會從cookies中判斷是否為爬蟲
# COOKIES_ENABLED = True
# COOKIES_DEBUG = True
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 它定義了在抓取網站所使用的使用者代理,預設值:「Scrapy / VERSION「
#USER_AGENT = ' (+http://www.yourdomain.com)'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'companyNews.middlewares.UserAgentmiddleware': 401,
'companyNews.middlewares.ProxyMiddleware':426,
}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'companyNews.middlewares.UserAgentmiddleware': 400,
'companyNews.middlewares.ProxyMiddleware':425,
# 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':423,
# 'companyNews.middlewares.CookieMiddleware': 700,
}
MYEXT_ENABLED=True # 開啟擴充套件
IDLE_NUMBER=12 # 設定空閒持續時間單位為 360個 ,一個時間單位為5s
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# 在 EXTENSIONS 設定,啟用擴充套件
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'companyNews.extensions.RedisSpiderSmartIdleClosedExensions': 500,
}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 注意:自定義pipeline的優先順序需高於Redispipeline,因為RedisPipeline不會返回item,
# 所以如果RedisPipeline優先順序高於自定義pipeline,那麼自定義pipeline無法獲取到item
ITEM_PIPELINES = {
#將清除的專案在redis進行處理,# 將RedisPipeline註冊到pipeline元件中(這樣才能將資料存入Redis)
# 'scrapy_redis.pipelines.RedisPipeline': 400,
'companyNews.pipelines.companyNewsPipeline': 300,# 自定義pipeline視情況選擇性註冊(可選)
}
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# ----------------scrapy預設已經自帶了快取,設定如下-----------------
# 開啟快取
#HTTPCACHE_ENABLED = True
# 設定快取過期時間(單位:秒)
#HTTPCACHE_EXPIRATION_SECS = 0
# 快取路徑(預設為:.scrapy/httpcache)
#HTTPCACHE_DIR = 'httpcache'
# 忽略的狀態碼
#HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPERROR_ALLOWED_CODES = [302, 301]
# 快取模式(檔案快取)
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#-----------------Scrapy-Redis分散式爬蟲相關設定如下--------------------------
# Enables scheduling storing requests queue in redis.
#啟用Redis排程儲存請求佇列,使用Scrapy-Redis的排程器,不再使用scrapy的排程器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
#確保所有的爬蟲通過Redis去重,使用Scrapy-Redis的去重元件,不再使用scrapy的去重元件
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 預設請求序列化使用的是pickle 但是我們可以更改為其他類似的。PS:這玩意兒2.X的可以用。3.X的不能用
# SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 使用優先順序排程請求佇列 (預設使用),
# 使用Scrapy-Redis的從請求集合中取出請求的方式,三種方式擇其一即可:
# 分別按(1)請求的優先順序/(2)佇列FIFO/(先進先出)(3)棧FILO 取出請求(先進後出)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 可選用的其它佇列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
# Don't cleanup redis queues, allows to pause/resume crawls.
#不清除Redis佇列、這樣可以暫停/恢復 爬取,
# 允許暫停,redis請求記錄不會丟失(重啟爬蟲不會重頭爬取已爬過的頁面)
#SCHEDULER_PERSIST = True
#----------------------redis的地址設定-------------------------------------
# Specify the full Redis URL for connecting (optional).
# If set, this takes precedence over the REDIS_HOST and REDIS_PORT settings.
# 指定用於連線redis的URL(可選)
# 如果設定此項,則此項優先順序高於設定的REDIS_HOST 和 REDIS_PORT
# REDIS_URL = 'redis://root:密碼@主機IP:埠'
# REDIS_URL = 'redis://root:[email protected]:6379'
REDIS_URL = 'redis://root:%s@%s:%s'%(password_redis,host_redis,port_redis)
# 自定義的redis引數(連線超時之類的)
REDIS_PARAMS={'db': db_redis}
# Specify the host and port to use when connecting to Redis (optional).
# 指定連線到redis時使用的埠和地址(可選)
#REDIS_HOST = '127.0.0.1'
#REDIS_PORT = 6379
#REDIS_PASS = '19940225'
#-----------------------------------------暫時用不到-------------------------------------------------------
# 它定義了將被允許抓取的網址的長度為URL的最大極限,預設值:2083
# URLLENGTH_LIMIT=2083
# 爬取網站最大允許的深度(depth)值,預設值0。如果為0,則沒有限制
# DEPTH_LIMIT = 3
# 整數值。用於根據深度調整request優先順序。如果為0,則不根據深度進行優先順序調整。
# DEPTH_PRIORITY=3
# 最大空閒時間防止分散式爬蟲因為等待而關閉
# 這隻有當上面設定的佇列類是SpiderQueue或SpiderStack時才有效
# 並且當您的蜘蛛首次啟動時,也可能會阻止同一時間啟動(由於佇列為空)
# SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 序列化專案管道作為redis Key儲存
# REDIS_ITEMS_KEY = '%(spider)s:items'
# 預設使用ScrapyJSONEncoder進行專案序列化
# You can use any importable path to a callable object.
# REDIS_ITEMS_SERIALIZER = 'json.dumps'
# 自定義redis使用者端類
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
# 如果為True,則使用redis的'spop'進行操作。
# 如果需要避免起始網址列表出現重複,這個選項非常有用。開啟此選項urls必須通過sadd新增,否則會出現型別錯誤。
# REDIS_START_URLS_AS_SET = False
# RedisSpider和RedisCrawlSpider預設 start_usls 鍵
# REDIS_START_URLS_KEY = '%(name)s:start_urls'
# 設定redis使用utf-8之外的編碼
# REDIS_ENCODING = 'latin1'
# Disable Telnet Console (enabled by default)
# 它定義是否啟用telnetconsole,預設值:True
#TELNETCONSOLE_ENABLED = False
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
# 開始下載時限速並延遲時間
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#高並行請求時最大延遲時間
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
#禁止重定向
#除非您對跟進重定向感興趣,否則請考慮關閉重定向。 當進行通用爬取時,一般的做法是儲存重定向的地址,並在之後的爬取進行解析。
# 這保證了每批爬取的request數目在一定的數量, 否則重定向迴圈可能會導致爬蟲在某個站點耗費過多資源。
# REDIRECT_ENABLED = False
Scrapy——LinkExtractor
- 提取連結的方法
在爬取一個網站時,想要爬取的資料通常分佈在多個頁面中,每個頁面包含一部分資料以及到其他頁面的連結,提取頁面中資料的方法大家已經掌握,提取連結有使用 Selector 和使用 LinkExtractor 兩種方法。
(1)使用Selector
因為連結也是頁面中的資料,所以可以使用與提取資料相同的方法進行提取,在提取少量連結或提取規則比較簡單時,使用 Selector 就足夠了。例如我們在專案 toscrapy 中編寫爬蟲 books.py 的資料解析函數 parse() 時,就是用了 Selector 提取了下一個頁面的連結,程式碼如下:
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = [' http://books.toscrape.com/']
def parse(self, response):
......
# 提取連結
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url, callback=self.parse)
第一種方法我們早已掌握,下面學習如何使用 LinkExtractor 提取連結。
(2)使用LinkExtractor
Scrapy 提供了一個專門用於提取連結的類 LinkExtractor,在提取大量連結或提取規則比較複雜時,使用 LinkExtractor 更加方便。
LinkExtractor 的使用非常簡單,我們通過將上述程式碼中的 Selector 替換成 LinkExtractor 進行講解,程式碼如下:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.linkextractors import LinkExtractor
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = [' http://books.toscrape.com/']
def parse(self, response):
...
# 提取連結
le = LinkExtractor(restrict_css='ul.pager li.next')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(next_url, callback=self.parse)
程式碼解析如下:
Step 1:建立一個 LinkExtractor 物件,使用一個或多個構造器引數描述提取規則。這裡傳遞給 restrict_css 引數一個 CSS 選擇器表示式。它描述出下一頁連結所在的區域(在 li.next 下)。
Step 2:呼叫 LinkExtractor 物件的 extract_links 方法傳入一個 Response 物件,該方法依據建立物件時所描述的提取規則, 在 Response 物件所包含的頁面中提取連結,最終返回一個列表,其中的每一個元素都是一個 Link 物件,即提取到的一個連結。
Step 3:由於頁面中的下一頁連結只有一個,因此用 links[0] 獲取 LinkExtractor 物件,LinkExtractor 物件的 url 屬性便是連結頁面的絕對 url 地址(無須再呼叫 response.urljoin 方法),用其構造 Request 物件並提交。
- LinkExtractor 提取連結的規則
接下來,我們來學習使用 LinkExtractor 的構造器引數描述提取連結的規則。
首先我們建立兩個包含多個連結的HTML頁面,作為 LinkExtractor 提取連結的範例網頁:
<!--
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
-->
<html>
<body>
<div id="top">
<p>下面是一些站內連線</p>
<a class="internal" href="/intro/install.html">Installation guide</a>
<a class="internal" href="/intro/tutorial.html">Tutorial</a>
<a class="internal" href="../examples.html">Examples</a>
</div>
<div id="bottom">
<p>下面是一些站外連線</p>
<a href="http://stackoverflow.com/tags/scrapy/info">StackOverflow</a>
<a href="https://github.com/scrapy/scrapy">Fork on Github</a>
</div>
</body>
</html>
<!-- example2.html -->
<html>
<head>
<script type='text/javascript' src='/js/app1.js'/>
<script type='text/javascript' src='/js/app2.js'/>
</head>
<body>
<a href="/home.html">主頁</a>
<a href="javascript:goToPage('/doc.html'); return false">檔案</a>
<a href="javascript:goToPage('/example.html'); return false">案例</a>
</body>
</html>
LinkExtractor 構造器的所有引數都有預設值,如果構造物件時不傳遞任何引數(使用預設值),就提取頁面中所有連結。例如以下程式碼將提取頁面 example1.html 中的所有連結:
下面依次介紹 LinkExtractor 構造器的各個引數:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
pattern = '/intro/.+\.html$'
le = LinkExtractor(allow=pattern)
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://example1.com/intro/install.html', ' http://example1.com/intro/tutorial.html']
(1)allow
allow 接收一個正規表示式或一個正規表示式列表,提取絕對 url 與正規表示式匹配的連結,如果該引數為空(預設),就提取全部連結。
例1:提取頁面 example1.html 中路徑以 /intro 開始的連結:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
pattern = '/intro/.+\.html$'
le = LinkExtractor(allow=pattern)
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://example1.com/intro/install.html', ' http://example1.com/intro/tutorial.html']
(2)deny
接收一個正規表示式或一個正規表示式列表,與 allow 相反,排除絕對 url 與正規表示式匹配的連結。
例2:提取頁面 example1.html 中所有站外連線(即排除站內連線):
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
from urllib.parse import urlparse
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
pattern = '^' + urlparse(response1.url).geturl()
le = LinkExtractor(deny=pattern)
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://stackoverflow.com/tags/scrapy/info', ' https://github.com/scrapy/scrapy']
(3)allow_domains
接收一個域名或一個域名列表,提取到指定域的連結。
例3::提取頁面 example1.html 中所有到 github.com 和 stackoverflow.com 這兩個域的連結:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
domains = ['github.com', 'stackoverflow.com']
le = LinkExtractor(allow_domains=domains)
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://stackoverflow.com/tags/scrapy/info', ' https://github.com/scrapy/scrapy']
(4)deny_domains
接收一個域名或一個域名列表,與 allow_domains 相反,排除到指定域的連結。
例4:提取頁面 example1.html 中除了到 github.com 域以外的連結:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
le = LinkExtractor(deny_domains='github.com')
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://example1.com/intro/install.html', ' http://example1.com/intro/tutorial.html', ' http://example1.com/examples.html', ' http://stackoverflow.com/tags/scrapy/info']
(5)restrict_xpaths
接收一個 XPath 表示式或一個 XPath 表示式列表,提取 XPath 表示式選中區域下的連結。
例5:提取頁面 example1.html 中
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
le = LinkExtractor(restrict_xpaths='//div[@id="top"]')
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://example1.com/intro/install.html', ' http://example1.com/intro/tutorial.html', ' http://example1.com/examples.html']
(6)restrict_css
接收一個 CSS 選擇器或一個 CSS 選擇器列表,提取 CSS 選擇器選中區域下的連結。
例6:提取頁面 example1.html 中
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html1 = open('LE_Example1.html').read()
response1 = HtmlResponse(url='http://example1.com', body=html1, encoding='utf8')
le = LinkExtractor(restrict_css='div#bottom')
links = le.extract_links(response1)
print([link.url for link in links])
# 執行結果:
[' http://stackoverflow.com/tags/scrapy/info', ' https://github.com/scrapy/scrapy']
(7)tags
接收一個標籤(字串)或一個標籤列表,提取指定標籤內的連結,預設為 ['a', 'area'] 。
(8)attrs
接收一個屬性(字串)或一個屬性列表,提取指定屬性內的連結,預設為[‘href’]。
例8:提取頁面 example2.html 中參照 JavaScript 檔案的連結:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
html2 = open('LE_Example2.html').read()
response2 = HtmlResponse(url='http://example2.com', body=html2, encoding='utf8')
le = LinkExtractor(tags='script', attrs='src')
links = le.extract_links(response2)
print([link.url for link in links])
# 執行結果:
[' http://example2.com/js/app1.js', ' http://example2.com/js/app2.js']
(9)process_value
接收一個形如 func(value) 的回撥函數。如果傳遞了該引數,LinkExtractor 將呼叫該回撥函數對提取的每一個連結(如 a 的 href )進行處理,回撥函數正常情況下應返回一個字串(處理結果),想要拋棄所處理的連結時,返回 None。
例9:在頁面 example2.html 中,某些 a 的 href 屬性是一段 JavaScript 程式碼,程式碼中包含了連結頁面的實際 url 地址,此時應對連結進行處理,提取頁面 example2.html 中所有實際連結:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http import HtmlResponse
from scrapy.linkextractors import LinkExtractor
import re
html2 = open('LE_Example2.html').read()
response2 = HtmlResponse(url='http://example2.com', body=html2, encoding='utf8')
def process(value):
m = re.search("javascript:goToPage\('(.*?)'", value)
# 如果匹配,就提取其中 url 並返回,如果不匹配則返回原值
if m:
value = m.group(1)
return value
le = LinkExtractor(process_value=process)
links = le.extract_links(response2)
print([link.url for link in links])
# 執行結果:
[' http://example2.com/doc.html', ' http://example2.com/example.html']j
Scrapy 選擇器
一、簡介
前面介紹了scrapy命令和Scrapy處理流程與重要元件
這裡介紹一下Scrapy的Selector,Scrapy的Selector和Beautifulsoup非常像,關於Beautifulsoup可以參考BeautifuSoup實用方法屬性總結 和BeautifulSoup詳解
先來看一下Selector的知識點:
二、xpath
我們先介紹一下xpath,因為xpath語法比較簡潔,並且如果能夠靈活應用的話,可以簡化我們提取HTML內容的複雜度。
| 符號 | 說明 |
|---|---|
| / | 從根節點選取,使用絕對路徑,路徑必須完全匹配 |
| // | 從整個檔案中選取,使用相對路徑 |
| . | 從當前節點開始選取 |
| … | 從當前節點父節點開始選取 |
| @ | 選取屬性 |
光看說明有些抽象,我們通過一個例子來簡單說明一下:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy import Selector
content = '''
<div>
<p>out inner div p</p>
<div id="inner"><p>in inner div p</p></div>
</div>
<p>out div p</p>
'''
selector = Selector(text=content)
# 在整個檔案中選取id為inner的div節點
inner_div_sel = selector.xpath("//div[@id='inner']")
# 獲取整個檔案中的p節點的文字
print(inner_div_sel.xpath('//p/text()').getall())
# 從inner div節點的父節點開始獲取所有p節點的文字
print(inner_div_sel.xpath('..//p/text()').getall())
# 從inner div節點開始獲取所有p節點的文字
print(inner_div_sel.xpath('.//p/text()').getall())
Scrapy——os批次更新
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
import os
from scrapy import spiderloader
from scrapy.utils.project import get_project_settings
from scrapy.utils.log import configure_logging
settings = get_project_settings()
spider_loader = spiderloader.SpiderLoader.from_settings(settings)
spiders = spider_loader.list()
print(spiders)
# if __name__ == '__main__':
# settings = get_project_settings()
# print(settings)
# print(settings.get('BOT_NAME'))
for spider in spiders:
os.system("scrapy crawl {}".format(spider))
scrapy 解析xml格式的資料
XMLFeedSpider 主要用於 解析 xml格式的資料
建立一個scrapy 框架
scrapy startproject xxx
建立一個spider
scrapy genspider -t xmlfeed ZhaoYuanCity_2_GovPro(名字) xxx.com(網站名)
解析的例子為招遠市人民政府的資料
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
import re
import scrapy
from scrapy.spiders import XMLFeedSpider
from curreny.items import CurrenyItem
class Zhaoyuancity2GovproSpider(XMLFeedSpider):
name = 'ZhaoYuanCity_2_GovPro'
# allowed_domains = ['xxx.com']
start_urls = ['http://www.zhaoyuan.gov.cn/module/web/jpage/dataproxy.jsp?page=1&webid=155&path=http://www.zhaoyuan.gov.cn/&columnid=48655&unitid=180549&webname=%25E6%258B%259B%25E8%25BF%259C%25E5%25B8%2582%25E6%2594%25BF%25E5%25BA%259C&permiss']
iterator = 'iternodes' # you can change this; see the docs
itertag = 'datastore' # change it accordingly
def parse_node(self, response, selector):
# 用css 獲取 一個列表
source_list = selector.css('recordset record::text').extract()
for li in source_list:
# 用正則解析url 我們去裡面獲取時間標題和內容
url= re.search(r'href=\"(.*\.html)\"',li).group(1)
yield scrapy.Request(
url=url,
callback=self.parse
)
def parse(self,response):
# 呼叫item
item = {}
# 寫入連結提取器中獲取到的url
item['title_url'] = response.url
# 標題名
item['title_name'] = response.css('meta[name="ArticleTitle"]::attr(content)').get()
# 標題時間
item['title_date'] = response.css('meta[name="pubdate"]::attr(content)').get()
# 內容提取 含原始碼
item['content_html'] = response.css('.main').get()
# 交給item處理
yield item
最後執行專案
scrapy crawl ZhaoYuanCity_2_GovPro --nolog
註釋:
- iterator屬性:設定使用的迭代器,預設為「iternodes」(一個基於正規表示式的高效能迭代器),除此之外還有「html」和「xml」迭代器;
- itertag:設定開始迭代的節點;
- parse_node方法:在節點與所提供的標籤名相符合時被呼叫,在其中定義資訊提取和處理的操作;
- namespaces屬性:以列表形式存在,主要定義在檔案中會被蜘蛛處理的可用命令空間;
- parse方法: 解析資料 發起正常請求
- **adapt_response(response)方法:在spider分析響應前被呼叫;
- **process_results(response, results)方法:在spider返回結果時被呼叫,主要對結果在返回前進行最後的處理。
scrapy 執行 其中的spider檔案
from scrapy import cmdline
cmdline.execute(['scrapy','crawl','NeiMengGuInvestPro'])
scrapy 批次執行 使用scrapy command
在settings中 寫入
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
print('爬取開始')
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
獲取檔名 並且執行
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
...
if __name__ == '__main__':
import sys
import os
from scrapy import cmdline
file_name = os.path.basename(sys.argv[0])
file_name=file_name.split(".")[0]
cmdline.execute(['scrapy', 'crawl', file_name])
scrapy urljoin
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
next_page_url = response.xpath('...').extract() #搞到拼接的變動的引數內容
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
post_urls=response.css("#archive .floated-thumb .post-thumb a::attr(href)").extract()
for post_url in post_urls:
yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
scrapy 的 re_frist 方法
re_first()用來返回第一個匹配的字串,就在re的基礎上提取一個資料而已,而re可以提取多條資料。
re_first 與 extract_first('')都是獲取列表的第一項, 而re_first('(\d+)') 是利用正則獲取列表第一項的數位
例如:response.xpath('//a[contains(@href, "image")]/text()').re(r'Name:\s(.)')
scrapy 獲取實時cookie
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.http.cookies import CookieJar
cookie_jar = CookieJar()
cookie_jar.extract_cookies(response, response.request)
print(cookie_jar)
cookie_dict = dict()
cookie_list =''
for k, v in cookie_jar._cookies.items():
for i, j in v.items():
for m, n in j.items():
cookie_dict[m] = n.value
for i,j in cookie_dict.items():
print(i,'----------------',j)
Cookie1 = response.request.headers.getlist('Cookie')
這裡有兩個css選擇器的擴充套件語法
就是 ::text 和 ::attr 分別獲取標籤文字和屬性。屬性還可以用這種方式獲得:
response.css('li.next a').attrib['href']
Scrapy設定下載延時和自動限速
Scrapy設定下載延時和自動限速
DOWNLOAD_DELAY 在settings.py檔案中設定
#延時2秒,不能動態改變,時間間隔固定,容易被發現,導致ip被封
DOWNLOAD_DELAY=2
# RANDOMIZE_DOWNLOAD_DELAY 在settings.py檔案中設定
# 啟用後,當從相同的網站獲取資料時,Scrapy將會等待一個隨機的值,延遲時間為0.5到1.5之間的一個隨機值乘以DOWNLOAD_DELAY
RANDOMIZE_DOWNLOAD_DELAY=True
# 自動限速擴充套件 在settings.py中設定
AUTOTHROTTLE_ENABLED #預設為False,設定為True可以啟用該擴充套件
AUTOTHROTTLE_START_DELAY #初始下載延遲,單位為秒,預設為5.0
AUTOTHROTTLE_MAX_DELAY #設定在高延遲情況下的下載延遲,單位為秒,預設為60
AUTOTHROTTLE_DEBUG #用於啟動Debug模式,預設為False
CONCURRENT_REQUESTS_PER_DOMAIN #對單個網站進行並行請求的最大值,預設為8
CONCURENT_REQUESTS_PER_IP #對單個IP進行並行請求的最大值,如果非0,則忽略CONCURRENT_REQUESTS_PER_DOMAIN設定,使用該IP限制
在spider中修改settings中的設定
custom_settings = {
'HTTPERROR_ALLOWED_CODES': [404,302, 301],
}
Scrapy命令
commands 作用 命令作用域
crawl 使用一個spider開始爬取任務 專案內
check 程式碼語法檢查 專案內
list 列出當前專案中所有可用的spiders ,每一行顯示一個spider 專案內
edit 在命令視窗下編輯一個爬蟲 專案內
parse 用指定spider方法來存取URL 專案內
bench 測試當前爬行速度 全域性
fetch 使用Scrapy downloader獲取URL 全域性
genspider 使用預定義模板生成一個新的spider 全域性
runspider Run a self-contained spider (without creating a project) 全域性
settings 獲取Scrapy設定資訊 全域性
shell 命令列互動視窗下存取URL 全域性
startproject 建立一個新專案 全域性
version 列印Scrapy版本 全域性
view 通過瀏覽器開啟URL,顯示內容為Scrapy實際所見 全域性
scrapy genspider -h
Usage
=====
scrapy genspider [options] <name> <domain>
Generate new spider using pre-defined templates
Options
=======
--help, -h show this help message and exit
--list, -l List available templates
--edit, -e Edit spider after creating it
--dump=TEMPLATE, -d TEMPLATE
Dump template to standard output
--template=TEMPLATE, -t TEMPLATE
Uses a custom template.
--force If the spider already exists, overwrite it with the
template
Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
scrapy 傳遞 params
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from urllib.parse import urlencode
params = {
'wbtreeid': '5571',
'searchtext': '',
'wsbslistCURURI': 'ED1C87781DBB6EE748D288AAF4957433',
'wsbslistKEYTYPES': '4,4,4,12,12,93',
'actiontype': '',
'wsbslistORDER': 'desc',
'wsbslistORDERKEY': 'wbdate',
'wsbslistCountNo': '20',
'wsbslistNOWPAGE': str(num),
'wsbslistPAGE': '0',
'wsbslistrowCount': '3545'
}
url = "https://zwfw.nx.gov.cn/jfpt/newslist_ycs.jsp?" + urlencode(params)
18. scrapy 給單個請求設定超時時間
在請求中
meta = {'download_timeout':30}
Scrapy框架的代理使用
中介軟體新增代理
首先在中介軟體middlewares.py中,在最後加入如下程式碼:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
class ProxyMiddleware(object):
def process_request(self,request,spider):
entry = 'http://{}:{}@{}:{}'.format("賬戶", "密碼","host","port")
request.meta["proxy"] = entry
然後在setting.py中設定優先順序:
DOWNLOADER_MIDDLEWARES = {
'你的專案名.middlewares.ProxyMiddleware': 100,
}
spider中設定代理
entry = 'http://{}-zone-custom:{}@proxy.ipidea.io:2334'.format("帳號", "密碼")
# api
# entry = 'http://{}'.format("api獲取的ip代理")
# 傳參meta迭代下一個方法
for url in self.starturl:
yield scrapy.Request(url,meta={"proxy":entry})
scrapy retry 錯誤重試設定
有時候用scrapy爬蟲的時候會遇到請求某些url的時候發生異常的情況(多半是因為代理ip抽風了),這時候就可以設定一下retry讓它自動重試,很簡單。
settings中介軟體設定
看了下官網
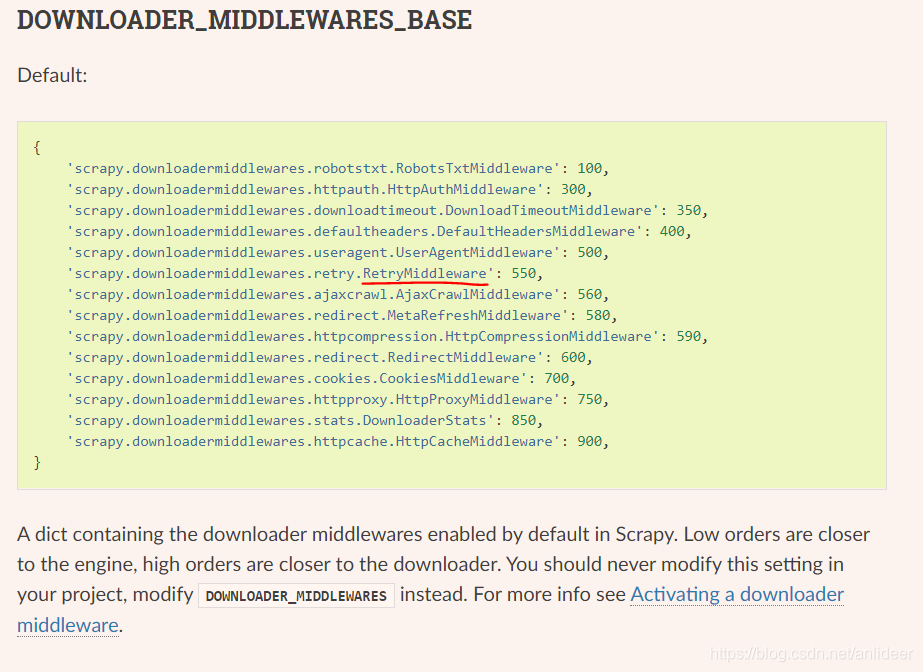
那麼很方便的,我們也可以在settings裡這麼寫
DOWNLOADER_MIDDLEWARES = {
'rent.middlewares.ProxyMiddleWare': 700,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
}
其中第一個是我自己定義的代理ip的中介軟體,像官網一樣proxy中介軟體的優先順序數位應該比retry更大。(數位越大越先執行,想想如果你遇到一個抽風的代理ip,然後你開始retry,如果retry比proxy先執行,那麼你就會不停用這個抽風的ip去重試,毫無意義;反之,因為我在proxy中介軟體有些如果response不是200就換個ip,這樣的話就還算合理)
settings引數設定
最後需要在settings裡再加幾行
# Retry settings
RETRY_ENABLED = True
RETRY_TIMES = 5 # 想重試幾次就寫幾
# 下面這行可要可不要
RETRY_HTTP_CODES = [500, 502, 503, 504, 408]
最下面那行如果需要指定一些code來retry的話,可以寫上,否則不用寫,我寫的這幾個就是不寫的時候預設的。
Scrapy結合Redis實現增量爬取
Scrapy適合做全量爬取,但是,我們不是一次抓取完就完事了。很多情況,我們需要持續的跟進抓取的站點,增量抓取是最需要的。
Scrapy與Redis配合,在寫入資料庫之前,做唯一性過濾,實現增量爬取。
一、官方的去重Pipeline
官方檔案中有一個去重的過濾器:
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
官方的這個過濾器的缺陷是隻能確保單次抓取不間斷的情況下去重,因為其資料是儲存在記憶體中的,當一個爬蟲任務跑完後程式結束,記憶體就清理掉了。再次執行時就失效了。
二、基於Redis的去重Pipeline
為了能夠多次爬取時去重,我們考慮用Redis,其快速的鍵值存取,對管道處理資料不會產生多少延時。
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
import pandas as pd
import redis
redis_db = redis.Redis(host=settings.REDIS_HOST, port=6379, db=4, password=settings.REDIS_PWD)
redis_data_dict = "f_uuids"
class DuplicatePipeline(object):
"""
去重(redis)
"""
def __init__(self):
if redis_db.hlen(redis_data_dict) == 0:
sql = "SELECT uuid FROM f_data"
df = pd.read_sql(sql, engine)
for uuid in df['uuid'].get_values():
redis_db.hset(redis_data_dict, uuid, 0)
def process_item(self, item, spider):
if redis_db.hexists(redis_data_dict, item['uuid']):
raise DropItem("Duplicate item found:%s" % item)
return item
- 首先,我們定義一個redis範例: redis_db和redis key:redis_data_dict。
- 在DuplicatePipeline的初始化函數init()中,對redis的key值做了初始化。當然,這步不是必須的,你可以不用實現。
- 在process_item函數中,判斷redis的hash表中存在該值uuid,則為重複item。
至於redis中為什麼沒有用list而用hash? 主要是因為速度,hash判斷uuid是否存在比list快好幾個資料級。
特別是uuid的資料達到100w+時,hash的hexists函數速度優勢更明顯。
最後別忘了在settings.py中加上:
三、總結
本文不是真正意義上的增量爬取,而只是在資料儲存環節,對資料唯一性作了處理,當然,這樣已經滿足了大部分的需求。
後續我會實現不需要遍歷所有的網頁,判斷抓取到所有最新的item,就停止抓取。敬請關注!
scrapy如何使用同一個session來存取幾個url
需要提交的表單裡面有個驗證碼,我需要先把驗證碼下下來再轉換成文字放上去,然後 post 到一個 URL 裡。這裡面應該要用同一個 session 才可以完成。 requests 裡面用 session 就很方便,想請問下在 scrapy 裡怎麼使用同一個 session?
這樣用meta不行。
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
def start_requests(self):
cookie_jar = CookieJar()
yield scrapy.Request(
self.getUrl,
meta={'cookiejar': cookie_jar},
callback=self.downloadPic)
def downloadPic(self, response):
yield scrapy.Request(self.vcodeUrl, meta={'cookiejar': response.meta['cookiejar']}, callback=self.getAndHandlePic)
def getAndHandlePic(self, response):
# handle picture, not the point here
pic = self.handlePic(response.body)
yield FormRequest(self.postUrl, formdata={'a':a, 'pic':pic}, meta={'cookiejar': response.meta['cookiejar']}, callback=self.parse)
def parse(self, response):
# do process source code
scrapy 拿到2進位制資料
直接用 response.body
快速請求連結 並儲存圖片
# -*- coding: utf-8 -*-
# @Time : 2022/10/14 13:12
# @Author : lzc
# @Email : [email protected]
# @blogs : https://www.cnblogs.com/zichliang
# @Software: PyCharm
import urllib.request
url = "https://www.lnzwfw.gov.cn/hz_tzxm_root/userCenter/rand.html"
urllib.request.urlretrieve(url=url, filename="captcha.png")