【偵錯】ftrace(一)基本使用方法
簡介
Ftrace是Linux Kernel的官方tracing系統,支援Function trace、靜態tracepoint、動態Tracepoint的跟蹤,還提供各種Tracer,用於統計最大irq延遲、最大函數呼叫棧大小、排程事件等。
Ftrace還提供了強大的過濾、快照snapshot、範例(instance)等功能,可以靈活設定。
核心設定Ftrace後,如果功能不開啟,對效能幾乎沒有影響。開啟事件記錄後,由於是在percpu buffer中記錄log,各CPU無需同步,引入的負載不大,非常適合在效能敏感的場景中使用。
相比kernle的log_buf和dynamic_debug機制,Ftrace的buffer大小可以靈活設定,可以生成快照,也有一定的優勢。
ftrace 框架
整個ftrace框架可以分為幾部分:ftrace核心框架,RingBuffer,debugfs,Tracepoint,各種Tracer。
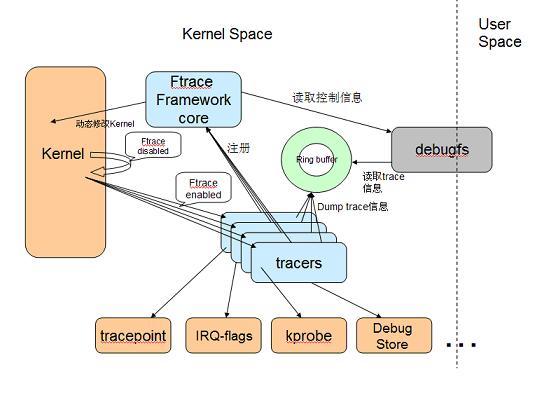
ftrace框架是整個ftrace功能的紐帶,包括對核心的修改,Tracer的註冊,RingBuffer的控制等等。
RingBuffer是靜態動態ftrace的載體。
debugfs則提供了使用者空間對ftrace設定介面。
Tracepoint是靜態trace,他需要提前編譯進核心;可以客製化列印內容,自由新增;並且核心對主要subsystem提供了Tracepoint。
Tracer有很多種,主要幾大類:
函數類:function, function_graph, stack
延時類:irqsoff, preemptoff, preemptirqsoff, wakeup, wakeup_rt, waktup_dl
其他類:nop, mmiotrace, blk
Trace檔案系統
設定核心支援ftrace需要開啟以下宏定義。
CONFIG_FTRACE=y
CONFIG_STACK_TRACER=y
CONFIG_FUNCTION_TRACER=y
CONFIG_FUNCTION_GRAPH_TRACER=y
CONFIG_HAVE_DYNAMIC_FTRACE=y
CONFIG_HAVE_FUNCTION_TRACER=y
CONFIG_IRQSOFF_TRACER=y
CONFIG_SCHED_TRACER=y
CONFIG_FTRACE_SYSCALLS=y
CONFIG_PREEMPTIRQ_EVENTS=y
CONFIG_TRACER_SNAPSHOT=y
Ftrace使用tracefs檔案系統去儲存控制檔案和顯示輸出的檔案。
當tracefs被設定進核心時,目錄/sys/kernel/tracing將會被建立。為了掛載這個目錄,你可以在/etc/fstab檔案中新增以下資訊:
tracefs /sys/kernel/tracing tracefs defaults 0 0
或者在執行時掛在:
mount -t tracefs nodev /sys/kernel/tracing
為了快速存取這個目錄可以建立一個軟連結::
ln -s /sys/kernel/tracing /tracing
注意:
-
在4.1版本之前,所有的ftrace跟蹤控制檔案都在
debugfs檔案系統中,該檔案系統通常位於/sys/kernel/debug/tracing。為了向後相容,當掛載debugfs檔案系統時,tracefs檔案系統將自動掛載在/sys/kernel/debug/tracing。位於tracefs檔案系統中的所有檔案也將位於debugfs檔案系統目錄中。 -
任何選定的ftrace選項也將建立
tracefs檔案系統。檔案中的操作都在ftrace的目錄中(/sys/kernel/tracing或者/sys/kernel/debug/tracing)。
在mount tracefs後,即可存取ftrace的控制和輸出檔案。以下是一些關鍵檔案的列表:
root@firefly:/sys/kernel/debug/tracing# ls
README kprobe_profile set_graph_function
available_events max_graph_depth set_graph_notrace
available_filter_functions options snapshot
available_tracers per_cpu trace
buffer_size_kb printk_formats trace_clock
buffer_total_size_kb saved_cmdlines trace_marker
current_tracer saved_cmdlines_size trace_options
dyn_ftrace_total_info saved_tgids trace_pipe
enabled_functions set_event tracing_cpumask
events set_event_pid tracing_max_latency
free_buffer set_ftrace_filter tracing_on
instances set_ftrace_notrace tracing_thresh
kprobe_events set_ftrace_pid
available_events
用於設定或顯示當前使用的跟蹤器;使用 echo 將跟蹤器名字寫入該檔案可以切換到不同的跟蹤器。系統啟動後,其預設值為 nop ,即不做任何跟蹤操作。在執行完一段跟蹤任務後,可以通過向該檔案寫入 nop 來重置跟蹤器。
available_filter_functions
記錄了當前可以跟蹤的核心函數。對於不在該檔案中列出的函數,無法跟蹤其活動。
available_tracers
記錄了當前編譯進核心的跟蹤器的列表,可以通過 cat 檢視其內容;寫 current_tracer 檔案時用到的跟蹤器名字必須在該檔案列出的跟蹤器名字列表中。
buffer_size_kb
用於設定單個 CPU 所使用的跟蹤快取的大小。跟蹤器會將跟蹤到的資訊寫入快取,每個 CPU 的跟蹤快取是一樣大的。跟蹤快取實現為環形緩衝區的形式,如果跟蹤到的資訊太多,則舊的資訊會被新的跟蹤資訊覆蓋掉。注意,要更改該檔案的值需要先將 current_tracer 設定為 nop 才可以。
buffer_total_size_kb
顯示所有的跟蹤快取大小,不同之處在於buffer_size_kb是單個CPU的,buffer_total_size_kb是所有CPU的和。
trace_pipe
輸出和trace一樣的內容,輸出實時tracing紀錄檔,這樣就避免了RingBuffer的溢位。cat trace_pipe > trace.txt &儲存檔案,但是cat時候會帶來一些效能損耗。
trace_options
控制Trace列印內容格式或者設定跟蹤器,可以通過trace_options新增很多附加資訊。
current_tracer
設定和顯示當前正在使用的跟蹤器。使用echo命令可以把跟蹤器的名字寫入current_tracer檔案,從而切換不同的跟蹤器。
dyn_ftrace_total_info
debug使用,顯示available_filter_functins中跟中函數的數目,兩者一致。
enabled_functions
顯示有回撥附著的函數名稱。這個檔案更多的是用於偵錯ftrace,但也可以用於檢視是否有任何函數附加了回撥。不僅ftrace框架使用ftrace函數tracing,其他子系統也可能使用。該檔案顯示所有附加回撥的函數,以及附加回撥的數量。注意,一個回撥也可以呼叫多個函數,這些函數不會在這個計數中列出。
如果回撥被一個帶有"save regs"屬性的函數註冊tracing(這樣開銷更大),一個’R’將顯示在與返回暫存器的函數的同一行上。
如果回撥被一個帶有"ip modify"屬性的函數註冊tracing(這樣regs->ip就可以被修改),'I’將顯示在可以被覆蓋的函數的同一行上。
如果體系架構支援,它還將顯示函數直接呼叫的回撥。如果計數大於1,則很可能是ftrace_ops_list_func()。
如果函數的回撥跳轉到特定於回撥而不是標準的"跳轉點"的跳轉點,它的地址將和跳轉點呼叫的函數一起列印。
events
系統Trace events目錄,在每個events下面都有enable、filter和fotmat。enable是開關;format是events的格式,然後根據格式設定 filter。
free_buffer
在關閉該檔案時,ring buffer將被調整為其最小大小。如果有一個tracing的程序也開啟了這個檔案,當該程序退出,該檔案的描述符將被關閉,在此過程,ring bufer也將被"freed"。
如果options/disable_on_free選項被設定將會停止tracing。
kprobe_events
啟用 dynamic trace opoints。參考核心檔案Documentation/trace/kprobetrace.rst。
kprobe_profile
Dynamic trace points 統計資訊。 參考核心檔案Documentation/trace/kprobetrace.rst。
max_graph_depth
被用於function_graph tracer。這是tracing一個函數的最大深度。將其設定為1將只顯示從使用者空間呼叫的第一個核心函數。
options
目錄檔案,裡面是每個trace options的檔案,和trace_options對應,可以通過echo 0/1使能options。
per_cpu:包含跟蹤 per_cpu 資訊的目錄。
- per_cpu/cpu0/buffer_size_kb:設定per_cpu的buffer空間
- per_cpu/cpu0/trace:當前CPU的trace檔案。
- per_cpu/cpu0/trace_pipe:當前CPU的trace_pipe檔案。
- per_cpu/cpu0/trace_pipe_raw:當前CPU的trace_pipe_raw
- per_cpu/cpu0/snapshot:當前CPU的snapshot
- per_cpu/cpu0/snapshot_raw:當前CPU的snapshot_raw
- per_cpu/cpu0/stats:當前CPU的trace統計資訊
printk_formats
提供給工具讀取原始格式trace的檔案。如果環形緩衝區中的事件參照了一個字串,則只有指向該字串的指標被記錄到緩衝區中,而不是字串本身。這可以防止工具知道該字串是什麼。該檔案顯示字串和字串的地址,允許工具將指標對映到字串的內容。
saved_cmdlines
ftrace會存放pid的comms在一個pid mappings,在顯示event時候同時顯示comm,這裡可以設定pid對應的comm,如果設定,顯示類似<idle>-0,否則<...>-0。
saved_cmdlines_size
saved_cmdlines的數目,預設為128
saved_tgids
如果設定了選項「record-tgid」,則在每個排程上下文切換時,任務的任務組 ID 將儲存在將執行緒的 PID 對映到其 TGID 的表中。預設情況下,「record-tgid」選項被禁用。
set_event
也可以在系統特定事件觸發的時候開啟跟蹤。為了啟用某個事件,你需要:echo sys_enter_nice >> set_event(注意你是將事件的名字追加到檔案中去,使用>>追加定向器,不是>)。要禁用某個事件,需要在名字前加上一個「!」號:echo '!sys_enter_nice' >> set_event。以下三種方式都可以啟用事件
echo sched:sched_switch >> /debug/tracing/set_event
echo sched_switch >> /debug/tracing/set_event
echo 1 > /debug/tracing/events/sched/sched_switch/enable
set_event_pid
tracer將只追蹤寫入此檔案PID的對應程序的event。"event-fork" option設定後,pid對應程序建立的子程序event也會自動跟蹤。
set_ftrace_filter 和 set_ftrace_notrace
在編譯核心時設定了動態 ftrace (選中 CONFIG_DYNAMIC_FTRACE 選項)後使用。前者用於顯示指定要跟蹤的函數,後者則作用相反,用於指定不跟蹤的函數。如果一個函數名同時出現在這兩個檔案中,則這個函數的執行狀況不會被跟蹤。這些檔案還支援簡單形式的含有萬用字元的表示式,這樣可以用一個表示式一次指定多個目標函數;注意,要寫入這兩個檔案的函數名必須可以在檔案 available_filter_functions 中看到。預設為可以跟蹤所有核心函數,檔案 set_ftrace_notrace 的值則為空。甚至可以對函數的名字使用萬用字元。例如,要用所有的vmalloc_函數,通過echo vmalloc_* > set_ftrace_filter進行設定。
set_ftrace_pid
tracer將只追蹤寫入此檔案PID的對應的程序。"function-fork" option設定後,pid對應程序建立的子程序也會自動跟蹤。
set_graph_function
設定要清晰顯示呼叫關係的函數,顯示的資訊結構類似於 C 語言程式碼,這樣在分析核心運作流程時會更加直觀一些。在使用 function_graph 跟蹤器時使用;預設為對所有函數都生成呼叫關係序列,可以通過寫該檔案來指定需要特別關注的函數。
echo function_graph > current_tracer
echo __do_fault > set_graph_function //跟蹤__do_fault
snapshot
是對trace的snapshot。
- echo 0清空快取,並釋放對應記憶體。
- echo 1進行對當前trace進行snapshot,如沒有記憶體則分配。
- echo 2清空快取,不釋放也不分配記憶體。
trace
檔案提供了檢視獲取到的跟蹤資訊的介面。可以通過 cat 等命令檢視該檔案以檢視跟蹤到的核心活動記錄,也可以將其內容儲存為記錄檔案以備後續檢視。
trace_clock
每當一個事件被記錄到環形緩衝區中時,都會新增一個「時間戳」。此標記來自指定的時鐘。預設情況下,ftrace 使用「本地」時鐘。本地時鐘可能與其他 CPU 上的本地時鐘不同步。
- local:預設時鐘,在每CPU中快速且精準,但是可能不會在各個CPU之間同步;
- global:各CPU間同步,但是比local慢;
- counter:並不是時鐘,而是一個原子計數器。數值一直+1,但是所有cpu是同步的。主要用處是分析不同cpu發生的events
- uptime:time stamp和jiffies counter根據boot time;
- perf:clock跟perf使用一致。
- x86-tsc:非系統自己時鐘。比如x86有TSC cycle clock;
- ppc-tb:使用powerpc的基礎時鐘暫存器值;
- mono:使用fast monotonic clock (CLOCK_MONOTONIC)
- mono_raw:使用raw monotonic clock (CLOCK_MONOTONIC_RAW)
- boot:使用boot clock (CLOCK_BOOTTIME)。
trace_marker
用於將使用者空間與核心空間中發生的事件同步。將字串寫入該檔案將被寫入ftrace緩衝區。
在應用程式中,應用程式開始開啟這個檔案並參照檔案描述符::
void trace_write(const char *fmt, ...)
{
va_list ap;
char buf[256];
int n;
if (trace_fd < 0)
return;
va_start(ap, fmt);
n = vsnprintf(buf, 256, fmt, ap);
va_end(ap);
write(trace_fd, buf, n);
}
開始:
trace_fd = open("trace_marker", WR_ONLY);
注意:寫入trace_marker檔案也可以觸發寫入/sys/kernel/tracing/events/ftrace/print/trigger的觸發器。詳細看核心檔案Documentation/trace/histogram.rst (Section 3.)。
trace_options
此檔案允許使用者控制在上述輸出檔案之一中顯示的資料量。還存在用於修改跟蹤器或事件的工作方式(堆疊跟蹤、時間戳等)的選項。
trace_pipe:"trace_pipe"輸出與"trace"檔案相同的內容,但是對跟蹤的影響不同。每次從"trace_pipe"讀取都會被消耗。這意味著後續的讀取將有所不同。跟蹤是動態的:
# echo function > current_tracer
# cat trace_pipe > /tmp/trace.out &
[1] 4153
# echo 1 > tracing_on
# usleep 1
# echo 0 > tracing_on
# cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 0/0 #P:4
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
#
# cat /tmp/trace.out
bash-1994 [000] .... 5281.568961: mutex_unlock <-rb_simple_write
bash-1994 [000] .... 5281.568963: __mutex_unlock_slowpath <-mutex_unlock
bash-1994 [000] .... 5281.568963: __fsnotify_parent <-fsnotify_modify
bash-1994 [000] .... 5281.568964: fsnotify <-fsnotify_modify
bash-1994 [000] .... 5281.568964: __srcu_read_lock <-fsnotify
bash-1994 [000] .... 5281.568964: add_preempt_count <-__srcu_read_lock
bash-1994 [000] ...1 5281.568965: sub_preempt_count <-__srcu_read_lock
bash-1994 [000] .... 5281.568965: __srcu_read_unlock <-fsnotify
bash-1994 [000] .... 5281.568967: sys_dup2 <-system_call_fastpath
注意,讀取"trace_pipe"檔案將會阻塞,直到新增更多輸入。這與"trace"檔案相反。如果任何程序開啟"trace"檔案進行讀取,它實際上將禁用tracing並阻止新增新條目。"trace_pipe"檔案沒有這個限制。
tracing_cpumask
可以通過此檔案設定跟蹤指定CPU,二進位制格式。
tracing_max_latency
記錄某些Tracer的最大延時。比如interrupts的最大延時關閉後,會記錄在這裡。可以echo值到此檔案,然後遇到比設定值更大的延遲才會更新。
tracing_on
用於控制跟蹤的暫停。有時候在觀察到某些事件時想暫時關閉跟蹤,可以將 0 寫入該檔案以停止跟蹤,這樣跟蹤緩衝區中比較新的部分是與所關注的事件相關的;寫入 1 可以繼續跟蹤。
tracing_thresh
延時記錄Trace的閾值,當延時超過此值時才開始記錄Trace。單位是ms,只有非0才起作用。
跟蹤器使用方法
blk跟蹤器
blktrace應用程式使用的跟蹤程式。
blk tracer比較特別,需要設定/sys/block/xxx/trace/enable 才工作,可參考https://lwn.net/Articles/315508/
echo 1 > /sys/block/mmcblk0/trace/enable
echo blk > /sys/kernel/debug/tracing/current_tracer
echo 1 > /sys/kernel/debug/tracing/tracing_on
cat /sys/kernel/debug/tracing/trace
# tracer: blk
#
jbd2/mmcblk0p9--1100 [001] ...1 679.901410: 179,0 A WS 323710 + 8 <- (179,9) 265048
jbd2/mmcblk0p9--1100 [001] ...1 679.901428: 179,0 Q WS 323710 + 8 [jbd2/mmcblk0p9-]
jbd2/mmcblk0p9--1100 [001] ...1 679.901469: 179,0 G WS 323710 + 8 [jbd2/mmcblk0p9-]
jbd2/mmcblk0p9--1100 [001] ...1 679.901474: 179,0 P N [jbd2/mmcblk0p9-]
jbd2/mmcblk0p9--1100 [001] ...1 679.901491: 179,0 A WS 323718 + 8 <- (179,9) 265056
mmcqd/0-998 [000] ...1 679.901627: 179,0 m N cfq1100SN dispatch_insert
mmcqd/0-998 [000] ...1 679.901635: 179,0 m N cfq1100SN dispatched a request
mmcqd/0-998 [000] ...1 679.901641: 179,0 m N cfq1100SN activate rq, drv=1
mmcqd/0-998 [000] ...2 679.901645: 179,0 D WS 323710 + 16 [mmcqd/0]
mmcqd/0-998 [000] ...1 679.902979: 179,0 C WS 323710 + 16 [0]
function跟蹤器
追蹤所有的核心函數
檢視可追蹤的核心函數
root@firefly:~# cd /sys/kernel/debug/tracing/
root@firefly:/sys/kernel/debug/tracing# cat available_filter_functions
顯示和設定當前的tracer
cat available_tracers
blk function_graph wakeup_dl wakeup_rt wakeup irqsoff function nop
cat current_tracer
nop
echo function > current_tracer
echo do_sys_open > set_ftrace_filter
echo 1 > tracing_on
echo 0 > tracing_on
cat trace
echo nop > current_tracer
echo > set_ftrace_filter
輸出
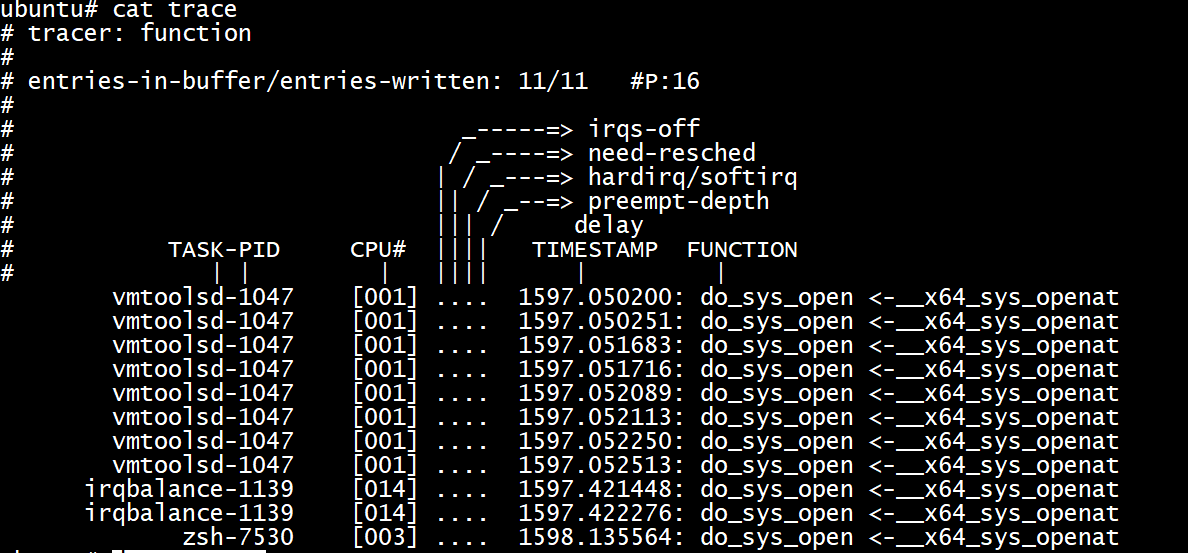
11/11
跟蹤條目11個
#P16
表示當前系統可用的CPU有16個
TASK-PID
程序名字-PID
CPU#
程序執行在那個CPU上
irqs-off
中斷開關狀態
need-resched
可以設定為以下值
-
N:表示程序設定了
TIF_NEED_RESCHED和PREEMPT_NEED_RESCHED標誌位,說明需要被排程。 -
n:表示程序僅設定了
TIF_NEED_RESCHED標誌 -
p:表示程序僅設定了
PREEMPT_NEED_RESCHED標誌 -
.:表示不需要排程
hardirq/softirq
可以設定為以下值
-
H:表示在一次軟中斷中發生了硬體中斷
-
h:表示硬體中斷的發生
-
s:表示軟體中斷的發生
-
.:表示沒有中斷髮生
preempt-depth
表示搶佔關閉的巢狀層級
delay
用特殊符號表示延時時間
-
$:大於1s
-
@:大於100ms
-
*:大於10ms
-
:大於1000us
-
!:大於100us
-
+:大於10us
TIMESTATION
時間戳。如果開啟了latency-format選項,表示相對時間,即從開始跟蹤算起。否則,使用絕對時間。
FUNCTION
表示函數名稱
function_graph跟蹤器
和「function tracer」比較類似,但它除了探測函數的入口還探測函數的出口。它可以畫出一個圖形化的函數呼叫,類似於c原始碼風格。
echo function_graph > current_tracer
echo do_sys_open > set_graph_function
echo 1 > tracing_on
echo 0 > tracing_on
cat trace
echo nop > current_tracer
echo > set_graph_function
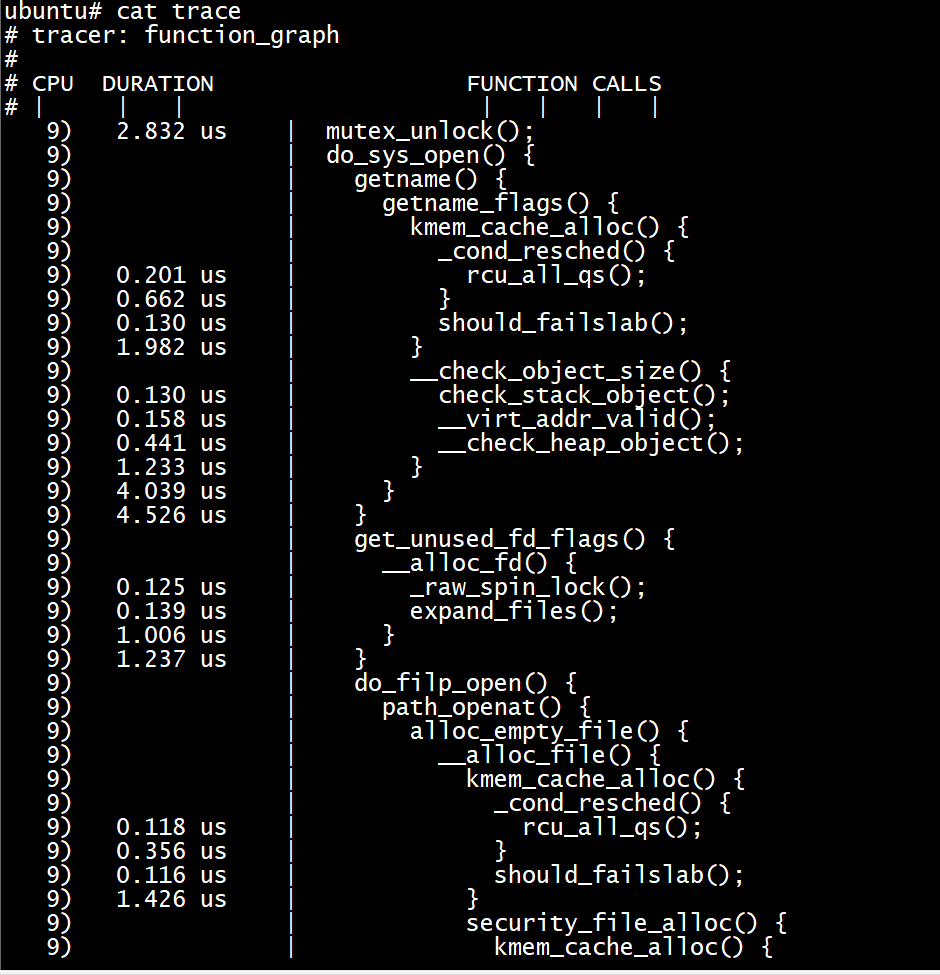
function_graph 和function跟蹤器在Linux version 4.4.194的開發板上發現無法生效,給set_graph_function echo 特定函數後,仍會跟蹤所有函數。但是在Linux version 5.4.0-135 ubuntu18.04中是生效的。不知道是不是核心版本差異的原因?
irqsoff跟蹤器
當關閉中斷時,CPU 會延遲對裝置的狀態變化做出反應,有時候這樣做會對系統效能造成比較大的影響。
irqsoff 跟蹤器可以對中斷被關閉的狀況進行跟蹤,有助於發現導致較大延遲的程式碼;
當出現最大延遲時,跟蹤器會記錄導致延遲的跟蹤資訊,檔案 tracing_max_latency 則記錄中斷被關閉的最大延時,遇到比設定值更大的延遲才會更新。
echo irqsoff > current_tracer
echo 0 > tracing_max_latency
echo 1 >tracing_on
echo 0 >tracing_on
cat trace
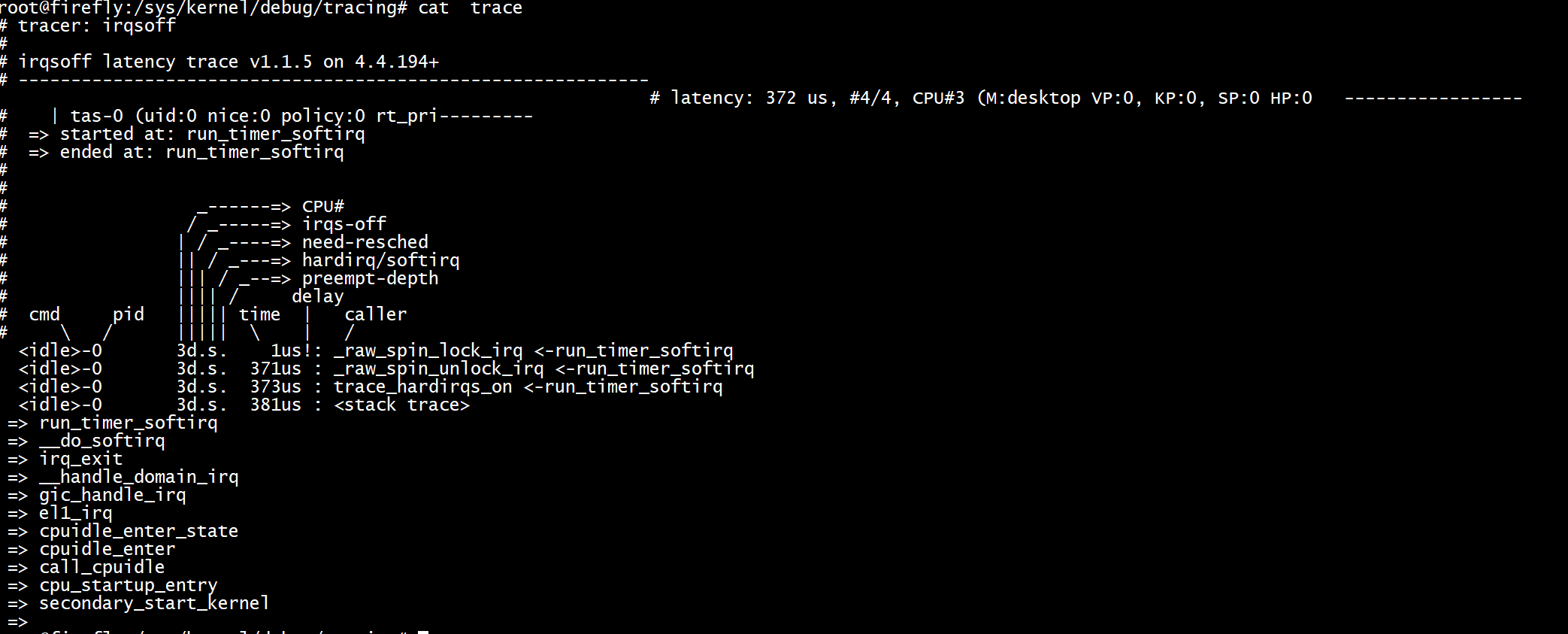
latency表示當前最大的中斷延時為372us,跟蹤條目總和為4個。
started at 和 ended at 顯示發生中斷的開始函數和結束函數分別為run_timer_softirq。
latency顯示中斷延時為372us,但是在stack trace 顯示為306us,這是因為在記錄最大延遲資訊時需要花費一些時間。
其他引數說明可參考function跟蹤器。
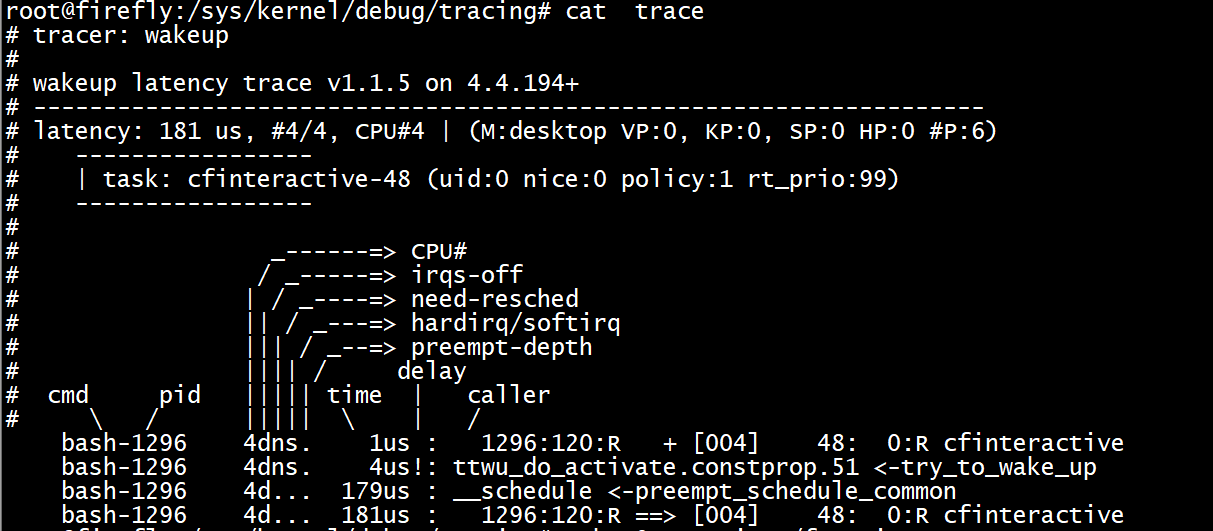
wakeup/wakeup_rt/wakeup_dl跟蹤器
wakeup:顯示程序從woken到wake up的延時,包括所有程序。
wakeup_dl:顯示SCHED_DEADLINE型別排程延時。
wakeup_rt:顯示實時程序的排程延時。
echo wakeup > current_tracer
echo 0 > tracing_max_latency
echo 1 > tracing_on
echo 0 > tracing_on
cat trace
stack跟蹤器
核心棧大小是有限的,為了跟蹤核心棧的使用情況,可以使用ftrace stack trace。
使能跟蹤一段時間後,可以檢視最大棧佔用情況,stack_max_size這裡列印的是最長棧的size。而在stack_trace 中列印的是最長棧的每個函數佔用棧大小的情況,注意這裡也只會記錄的最長的棧情況。
echo stack > current_tracer
echo do_sys_open > stack_trace_filter
echo 1 > /proc/sys/kernel/stack_tracer_enabled
echo 0 > /proc/sys/kernel/stack_tracer_enabled
cat stack_max_size
cat stack_trace

488 表示堆疊大小為488位元組,其中el0_svc_naked使用了最大的棧空間360。
小結
總結下ftrace 跟蹤器的三步法為:1,設定tracer型別;2,設定tracer引數;3,使能tracer
trace event 用法
ftrace中的跟蹤機制主要有兩種,分別是函數和跟蹤點。前者屬於簡單操作,後者可以理解為Linux核心的預留位置函數。
tracepoint可以輸出開發者想要的引數、區域性變數等資訊。
跟蹤點的位置比較固定,一般為核心開發者新增,可以理解為C語言中的#if DEBUG部分。如果執行時不開啟DEBUG,不佔用任何系統開銷。
trace event使用方法
set_event介面
/sys/kernel/debug/tracing/available_events定義了當前支援的trace event。
root@firefly:/sys/kernel/debug/tracing# cat available_events
raw_syscalls:sys_exit
raw_syscalls:sys_enter
ipi:ipi_exit
ipi:ipi_entry
ipi:ipi_raise
emulation:instruction_emulation
kvm:kvm_halt_poll_ns
kvm:kvm_age_page
kvm:kvm_fpu
kvm:kvm_mmio
kvm:kvm_ack_irq
kvm:kvm_set_irq
kvm:kvm_vcpu_wakeup
kvm:kvm_userspace_exit
kvm:kvm_toggle_cache
.....
啟用特定event,如sched_wakeup,echo到 /sys/kernel/debug/tracing/set_event。例如:
echo sched_wakeup >> /sys/kernel/debug/tracing/set_event
注意:需要使用>>,否則會首先disable所有的events。
關閉特定event,在echo event name到set_event之前設定一個!字首,比如
echo '!sched_wakeup' >> /sys/kernel/debug/tracing/set_event
使能所有event,echo *:* or *:到set_event中:
echo *:* > set_event
關閉所有event,echo一個空行到set_event中
echo > set_event
events 通常以subsystems的形式展現,例如ext4, irq, sched等等。一個完整的event name類似nfs4:nfs4_access:format。
subsystem name是可選的,但是它會顯示在available_events檔案中。一個subsystem中所有的events可以通過 :*語法來表示,
例如:enable所有的irq event:
echo 'irq:*' > set_event
enable介面
所有有效的trace event同時會在/sys/kernel/debug/tracing/events/資料夾中列出。
enable event ‘sched_wakeup’:
echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
disable:
echo 0 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
enable sched subsystem中所有的events:
echo 1 > /sys/kernel/debug/tracing/events/sched/enable
enable所有的events:
echo 1 > /sys/kernel/debug/tracing/events/enable
當讀enable檔案時,可能會有以下4種結果:
0 - all events this file affects are disabled
1 - all events this file affects are enabled
X - there is a mixture of events enabled and disabled
? - this file does not affect any event
為了早期啟動時偵錯,可以使用以下boot選項:
trace_event=[event-list]event-list是逗號分隔的event列表。
event格式
每個trace event都有一個與它相關聯的format檔案,該檔案包含log event中每個欄位的描述。這個資訊用來解析二進位制的trace流,其中的欄位也可以在event filter中找到對它的使用。
它還顯示用於在文字模式下列印事件的格式字串,以及用於分析的事件名稱和ID。
每個event都有一系列通用的欄位,全部都以common_作為字首。其他的欄位都需要在TRACE_EVENT()中定義。
format中的每個欄位都有如下形式:
field:field-type field-name; offset:N; size:N;
offset是欄位在trace record中的offset,size是資料項的size,都是byte單位。
舉例, sched_wakeup event的format資訊:
cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/format
name: sched_wakeup
ID: 60
format:
field:unsigned short common_type; offset:0; size:2;
field:unsigned char common_flags; offset:2; size:1;
field:unsigned char common_preempt_count; offset:3; size:1;
field:int common_pid; offset:4; size:4;
field:int common_tgid; offset:8; size:4;
field:char comm[TASK_COMM_LEN]; offset:12; size:16;
field:pid_t pid; offset:28; size:4;
field:int prio; offset:32; size:4;
field:int success; offset:36; size:4;
field:int cpu; offset:40; size:4;
print fmt: "task %s:%d [%d] success=%d [%03d]", REC->comm, REC->pid,
REC->prio, REC->success, REC->cpu
這個event包含10個欄位,5個通用欄位5個自定義欄位。除了COMM是一個字串,此事件的所有欄位都是數位,這對於事件過濾非常重要。
event 過濾
trace event支援 filter expressions式的過濾。一旦trace event被記錄到trace buffer中,其欄位就針對與該event型別相關聯的filter expressions進行檢查。
如果event匹配filter將會被記錄,否則將會被丟棄。如果event沒有設定filter,那麼在任何時刻都是匹配的,event預設就是no filter設定。
語法
一個filter expression由多個 predicates組成,使用邏輯操作符&&、||組合在一起。
field-name relational-operator value
-
數位類的操作符包括:
==, !=, <, <=, >, >=, & -
字元類的操作符包括:
==, !=, ~約等於操作符(~)接受萬用字元形式 (*,?)和字元類 ([)。舉例:
prev_comm ~ "*sh" prev_comm ~ "sh*" prev_comm ~ "*sh*" prev_comm ~ "ba*sh"
設定filters
通過將filter expressions寫入給定event的filter檔案來設定單個event的filter。
例如
echo 'pid > 1000' > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter # pid大於100的事件
echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
cat /sys/kernel/debug/tracing/trace
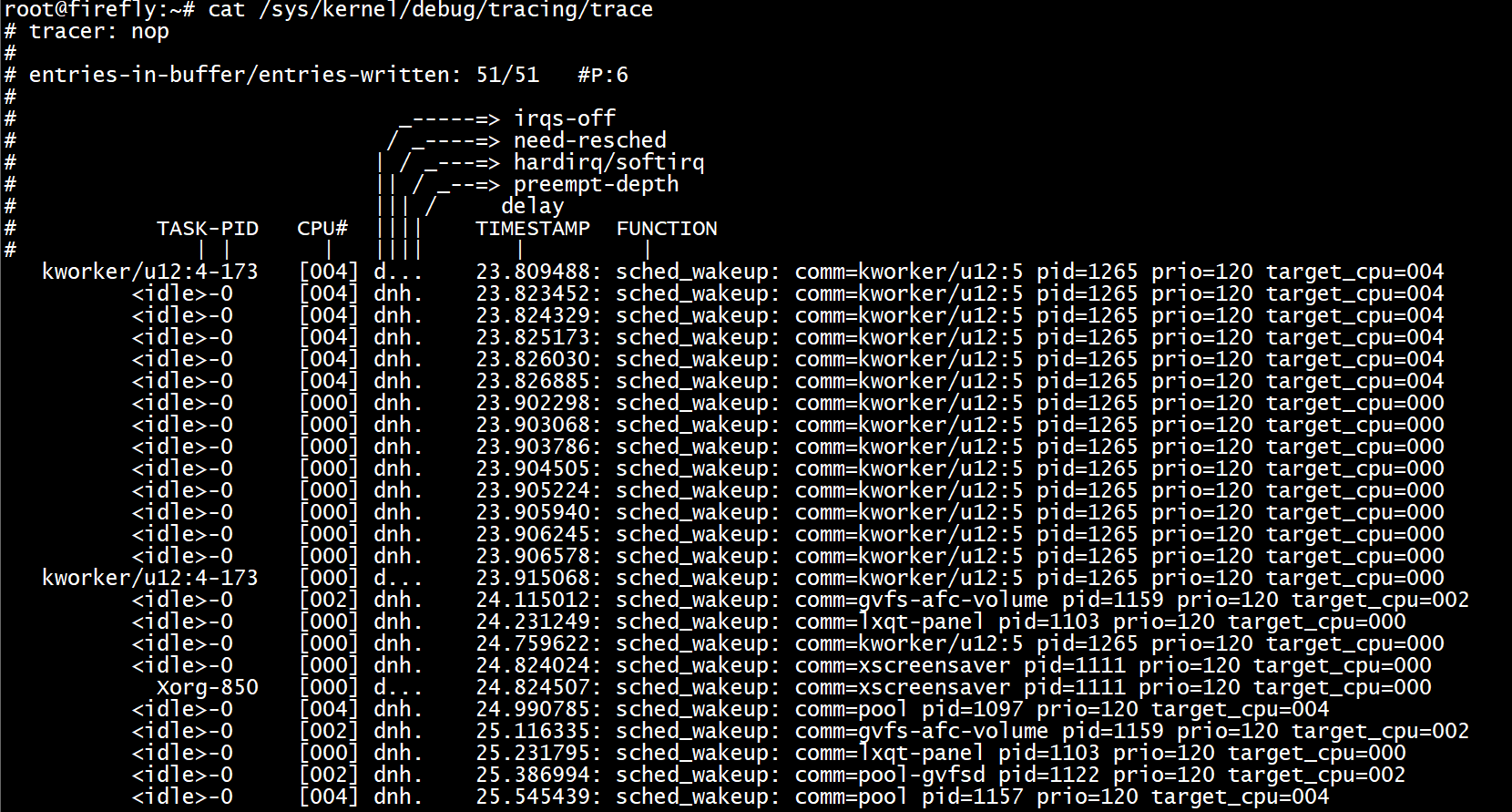
過濾程序名為rcu_sched的事件
echo 'comm == "rcu_sched"' > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter
echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
cat /sys/kernel/debug/tracing/trace
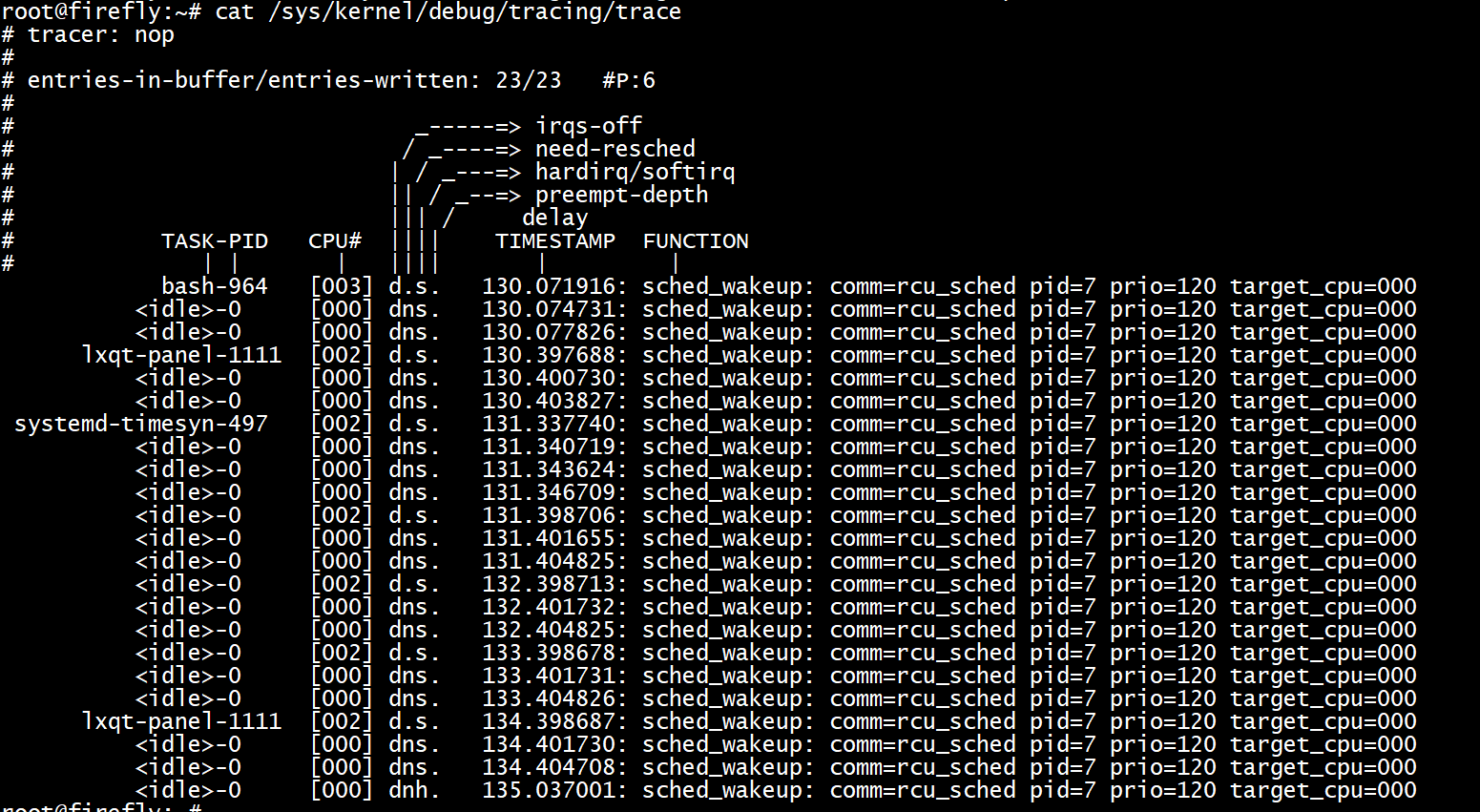
如果表示式中存在錯誤,則在設定時會得到一個Invalid argument錯誤,錯誤的字串連同錯誤訊息可以通過檢視過濾器來檢視,例如:
cd /sys/kernel/debug/tracing/events/signal/signal_generate
echo '((sig >= 10 && sig < 15) || dsig == 17) && comm != "bash"' > filter
-bash: echo: write error: Invalid argument
cat filter
((sig >= 10 && sig < 15) || dsig == 17) && comm != bash
^
parse_error: Field not found
清除filters
清除某個event的filter,echo 0 到對應event的filter檔案。
清除某個subsystem中所有events的filter,echo 0 到對應subsystem的filter檔案。
echo 0 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter
echo 0 > /sys/kernel/debug/tracing/events/sched/filter
子系統filters
為了方便起見,可以將子系統中的每個事件的過濾器作為一個組來設定或清除,將一個過濾器表示式寫入子系統根目錄下的過濾器檔案中。
如果子系統內的任何事件的過濾器缺少子系統過濾器中指定的欄位,或者如果過濾器不能應用於任何其他原因,則該事件的過濾器將保留其以前的設定。只有參照公共欄位的過濾器才能保證成功地傳播到所有事件。
舉例:
清除sched subsystem中所有events的filter:
echo 0 > /sys/kernel/debug/tracing/events/sched/filter
cat /sys/kernel/debug/tracing/events/sched_switch/filter
none
cat /sys/kernel/debug/tracing/events/sched_wakeup/filter
none
使用sched subsystem中所有events都有的通用欄位來設定filter(所有event將以同樣的filter結束):
echo 'common_pid == 0' > /sys/kernel/debug/tracing/events/sched/filter
cat /sys/kernel/debug/tracing/events/sched/sched_switch/filter
common_pid == 0
cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter
common_pid == 0
嘗試使用sched subsystem中非所有events通用欄位來設定filter(所有沒有prev_pid欄位的event將保留原有的filter):
echo prev_pid == 0 > /sys/kernel/debug/tracing/events/sched/filter
cat /sys/kernel/debug/tracing/events/sched/sched_switch/filter
prev_pid == 0
cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter
common_pid == 0
PID filters
頂級資料夾下的set_event_pid 檔案,可以給所有event設定PID過濾:
echo $$ > /sys/kernel/debug/tracing/set_event_pid
echo 1 > /sys/kernel/debug/tracing/events/enable
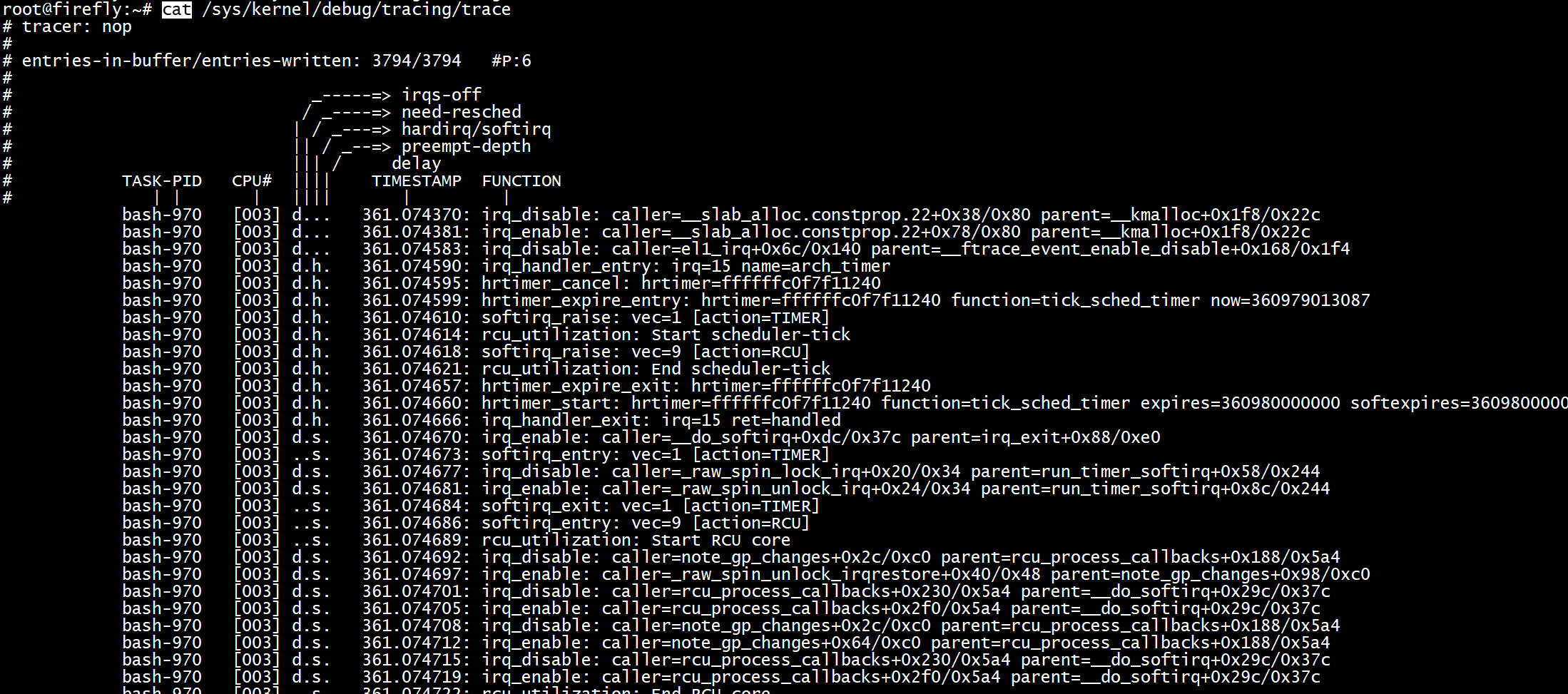
以上設定將會只追蹤當前程序。
追加PID使用>>:
echo 123 244 1 >> set_event_pid
Event triggers
跟蹤事件可以有條件地呼叫trigger commands,每當呼叫具有附加觸發器的trace event時,就會呼叫與該event相關聯的 trigger commands。
任何給定的觸發器還可以具有與它相關聯的事件過濾中描述的相同形式的事件過濾器。如果呼叫的事件通過關聯的篩選器,則該命令將被呼叫。
給定的event可以有任意數量的trigger與它相關聯,個別命令可能在這方面有所限制。
Event triggers是在「soft」模式上實現的,這意味如果一個event有一個或者多個trigger與之相關聯,即使該event是disable狀態,但實質上已經被actived,然後在「soft」模式中被disable。
也就是說,tracepoint 將被呼叫,但將不會被跟蹤,除非它被正式的enable。該方案允許即使disable的event也可以呼叫trigger,並且還允許當前event filter實現用於有條件地呼叫trigger。
設定event triggers的語法類似於設定set_ftrace_filter ftrace filter commands 的語法(可以參考‘Filter commands’ section of Documentation/trace/ftrace.txt),但存在很大的差異。
語法
使用echo command 到‘trigger’檔案的形式來增加Trigger:
echo 'command[:count] [if filter]' > trigger
移除Trigger使用同樣的命令,但是加上了 ‘!’ 字首:
echo '!command[:count] [if filter]' > trigger
filter部分的語法和上一節 ‘Event 過濾’ 中描述的相同。
為了方便使用,當前filter只支援使用>增加或刪除單條trigger,必須使用!命令逐條移除。
支援的命令
enable_event/disable_event
當triggering event被命中時,這些命令可以enable or disable其他的trace event。當這些命令被註冊,trace event變為active。
但是在「soft」 mode下disable。這時,tracepoint會被呼叫但是不會被trace。這些event tracepoint一直保持在這種模式中,直到trigger被觸發。
舉例,當一個read系統呼叫進入,以下的trigger導致kmalloc events被trace,:1 表明該行為只發生一次:
echo 'enable_event:kmem:kmalloc:1' > \
/sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger
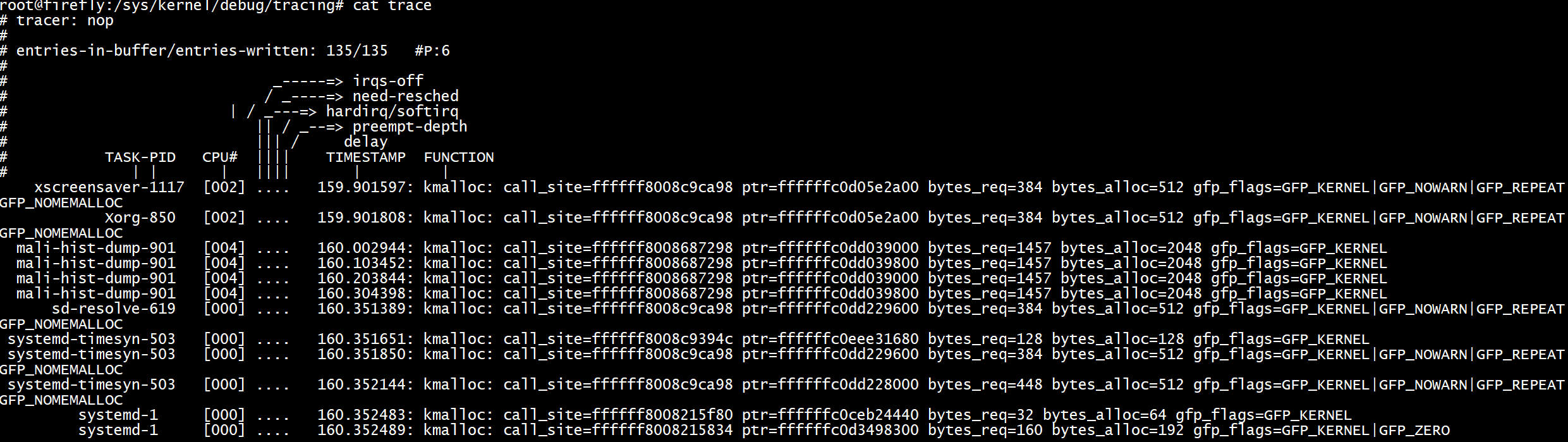
當一個read系統呼叫退出,以下的trigger導致kmalloc events被disable trace,每次退出都會呼叫:
echo 'disable_event:kmem:kmalloc' > /sys/kernel/debug/tracing/events/syscalls/sys_exit_read/trigger
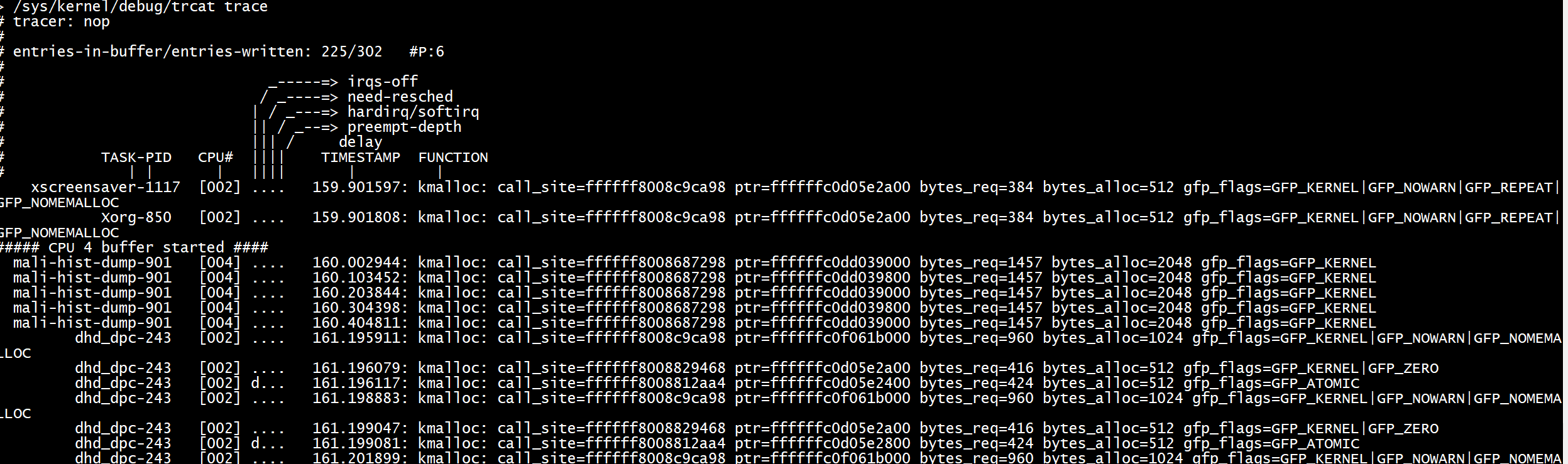
命令格式如下:
enable_event:<system>:<event>[:count]
disable_event:<system>:<event>[:count]
移除命令:
echo '!enable_event:kmem:kmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger
echo '!disable_event:kmem:kmalloc' > /sys/kernel/debug/tracing/events/syscalls/sys_exit_read/trigger
注意:每個 triggering event可以有任意多個觸發動作,但是每種觸發動作只能有一個。
例如,sys_enter_read可以觸發enable kmem:kmalloc和sched:sched_switch,但是kmem:kmalloc不能有兩個版本kmem:kmalloc and kmem:kmalloc:1或者是kmem:kmalloc if bytes_req == 256 and kmem:kmalloc if bytes_alloc == 256。
stacktrace
在triggering event發生時,這個命令在trace buffer中dump出堆疊呼叫。
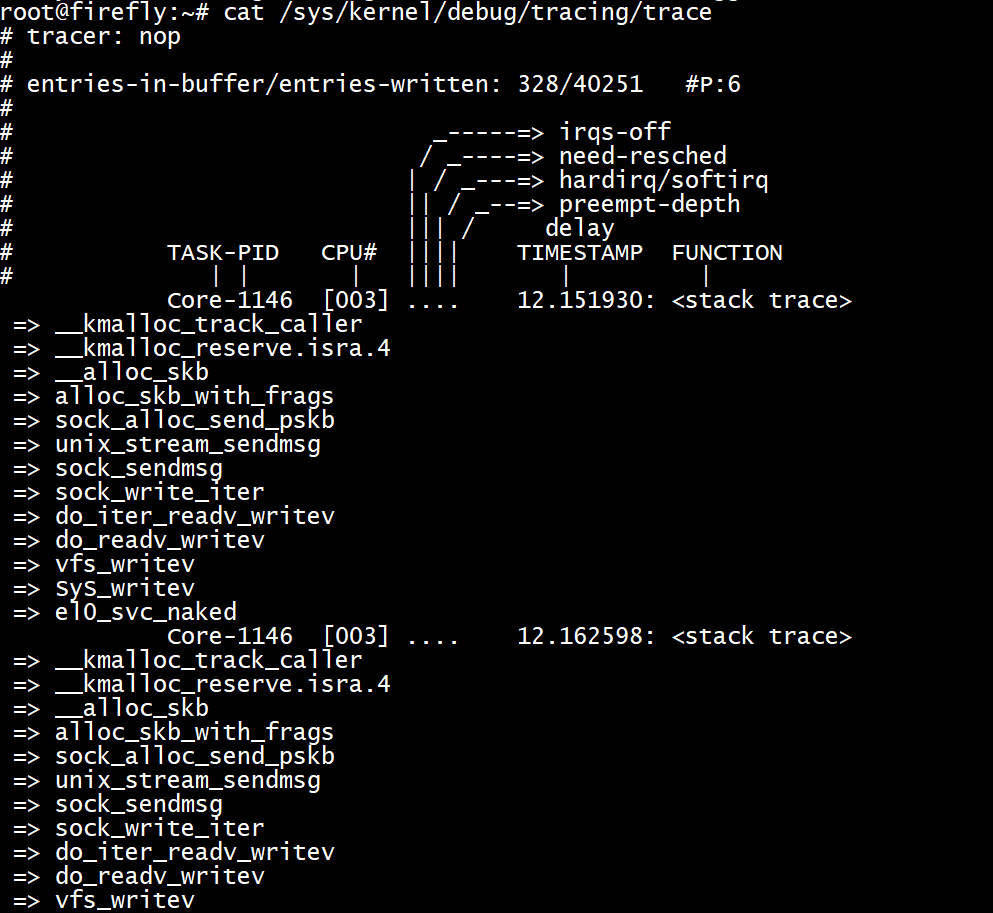
舉例,在每次kmalloc tracepoint被命中,以下的trigger dump出堆疊呼叫,
echo 'stacktrace' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
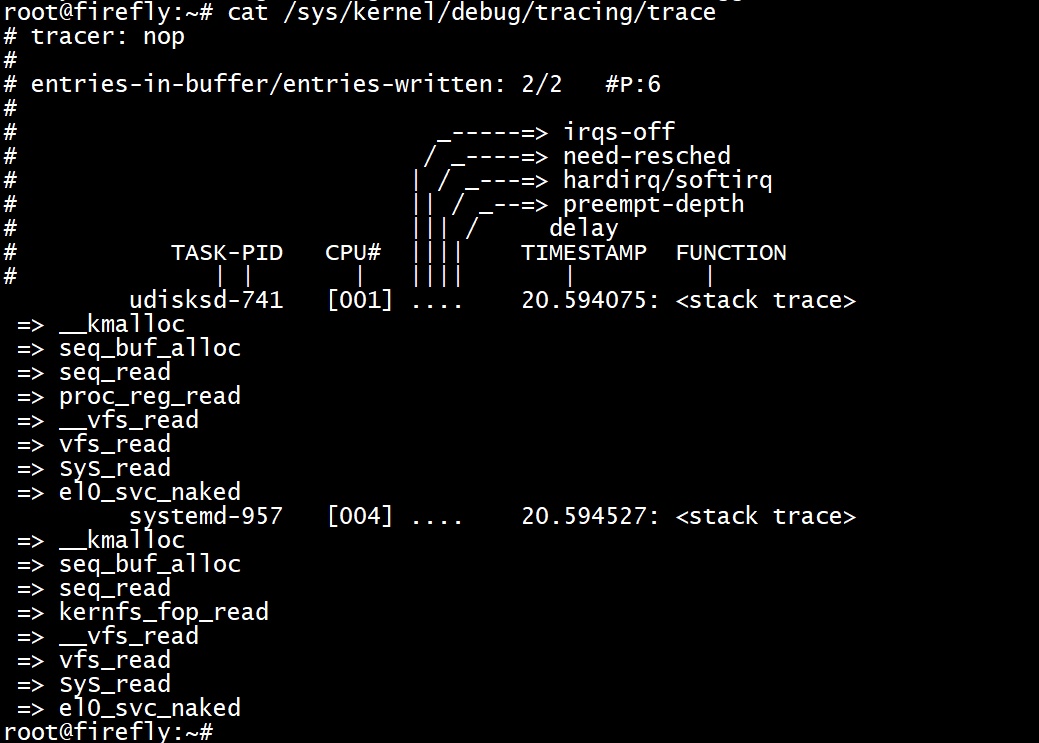
以下的trigger dump出堆疊呼叫,在kmalloc請求bytes_req >= 800的前2次
echo 'stacktrace:2 if bytes_req >= 800' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
命令格式如下:
stacktrace[:count]
移除命令:
echo '!stacktrace' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
echo '!stacktrace:2 if bytes_req >= 800' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
後者也可以通過下面的(沒有過濾器)更簡單地去除:
echo '!stacktrace:2' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
注意:每個trace event只能有一個stacktrace觸發器。
snapshot
當triggering event發生時,這個命令會觸發snapshot。
只有程序名為snapd才會建立一個snapshot。
如果你想trace一系列的events or functions,在 trigger event發生時,snapshot trace buffer將會抓住這些events:
echo 'snapshot if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger #設定trigger,只有程序名為snapd才會snapshot
echo 'enable_event:kmem:kmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger #觸發kmalloc
cat /sys/kernel/debug/tracing/snapshot #檢視快照
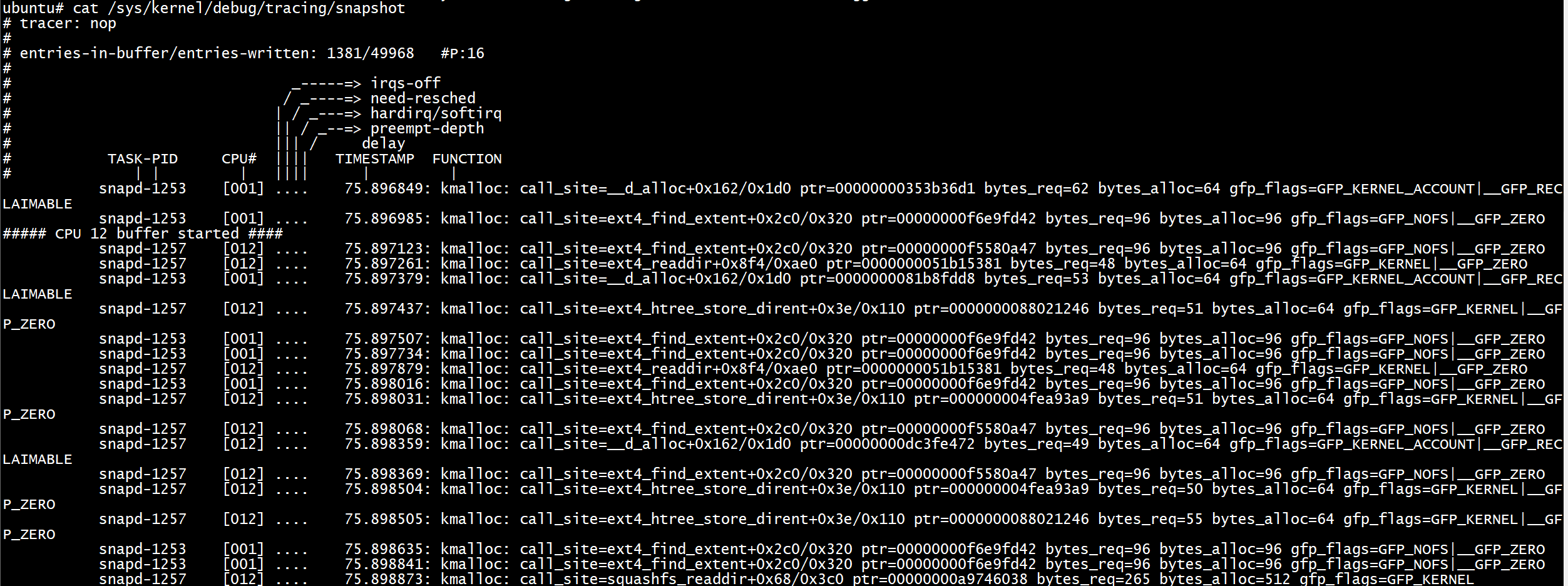
只snapshot一次:
echo 'snapshot:1 if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
echo 'enable_event:kmem:kmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger #觸發kmalloc
cat /sys/kernel/debug/tracing/snapshot #檢視快照
移除命令:
echo '!snapshot if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
echo '!snapshot:1 if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
注意:每個trace event只能有一個snapshot觸發器。
traceon/traceoff
這個命令將會把整個trace tracing on/off當event被命中。parameter 決定了系統 turned on/off 多少次。沒有描述就是無限制。
以下命令將 turns tracing off 在block request queue第一次unplugged並且depth > 1,如果您當時正在跟蹤一組事件或函數,則可以檢查跟蹤緩衝區,以檢視導致觸發事件的事件序列:
echo 'traceoff:1 if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
一直disable tracing 當nr_rq > 1:
echo 'traceoff if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
移除命令:
echo '!traceoff:1 if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
echo '!traceoff if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
注意:每個trace event只能有一個traceon or traceoff觸發器。
hist
組合觸發。這個命令聚合多個trace event的欄位到一個hash表中。
echo 'hist:key=id.syscall,common_pid.execname:val=hitcount:sort=id,hitcount if id == 16' > /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/trigger
cat /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/hist

詳細 可以參考Documentation/trace/histogram.txt。
本文參考
https://www.kernel.org/doc/html/latest/trace/events.html
https://www.cnblogs.com/hellokitty2/p/17055175.html
https://www.cnblogs.com/fellow1988/p/6417379.html
https://blog.csdn.net/u012489236/article/details/119519361
https://lwn.net/Articles/365835/
https://lwn.net/Articles/366796/
https://www.cnblogs.com/wsg1100/p/17020703.html
https://www.cnblogs.com/arnoldlu/p/7211249.html
https://www.cnblogs.com/hpyu/p/14348151.html
https://mjmwired.net/kernel/Documentation/trace/ftrace.txt
https://mjmwired.net/kernel/Documentation/trace/events.txt
《奔跑吧Linux核心》