OpenAI Chat completion API 入門指南
ChatGPT 由 OpenAI 最先進的語言模型 gpt-3.5-turbo 提供支援。
使用 OpenAI API,您可以使用 GPT-3.5-turbo 構建自己的程式來做一些如下的事情:
- 起草電子郵件或其他書面檔案
- 編寫 Python 程式碼
- 回答關於一組檔案的問題
- 建立對話代理程式
- 為你的軟體提供自然語言介面
- 充當導師輔導多學科
- 充當翻譯
- 模擬遊戲中的角色等等
1.模型介紹
GPT-3.5-turbo 模型是以一系列訊息作為輸入,並將模型生成的訊息作為輸出。
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
訊息是一個物件陣列,其中每個物件都有一個角色,一共有三種角色。
- 系統 訊息有助於設定助手的行為。在上面的例子中,助手被指示 「你是一個得力的助手」。
- 使用者 訊息有助於指導助手。 就是使用者說的話,向助手提的問題。
- 助手 訊息有助於儲存先前的回覆。這是為了持續對話,提供對談的上下文。
2.建立持續對談
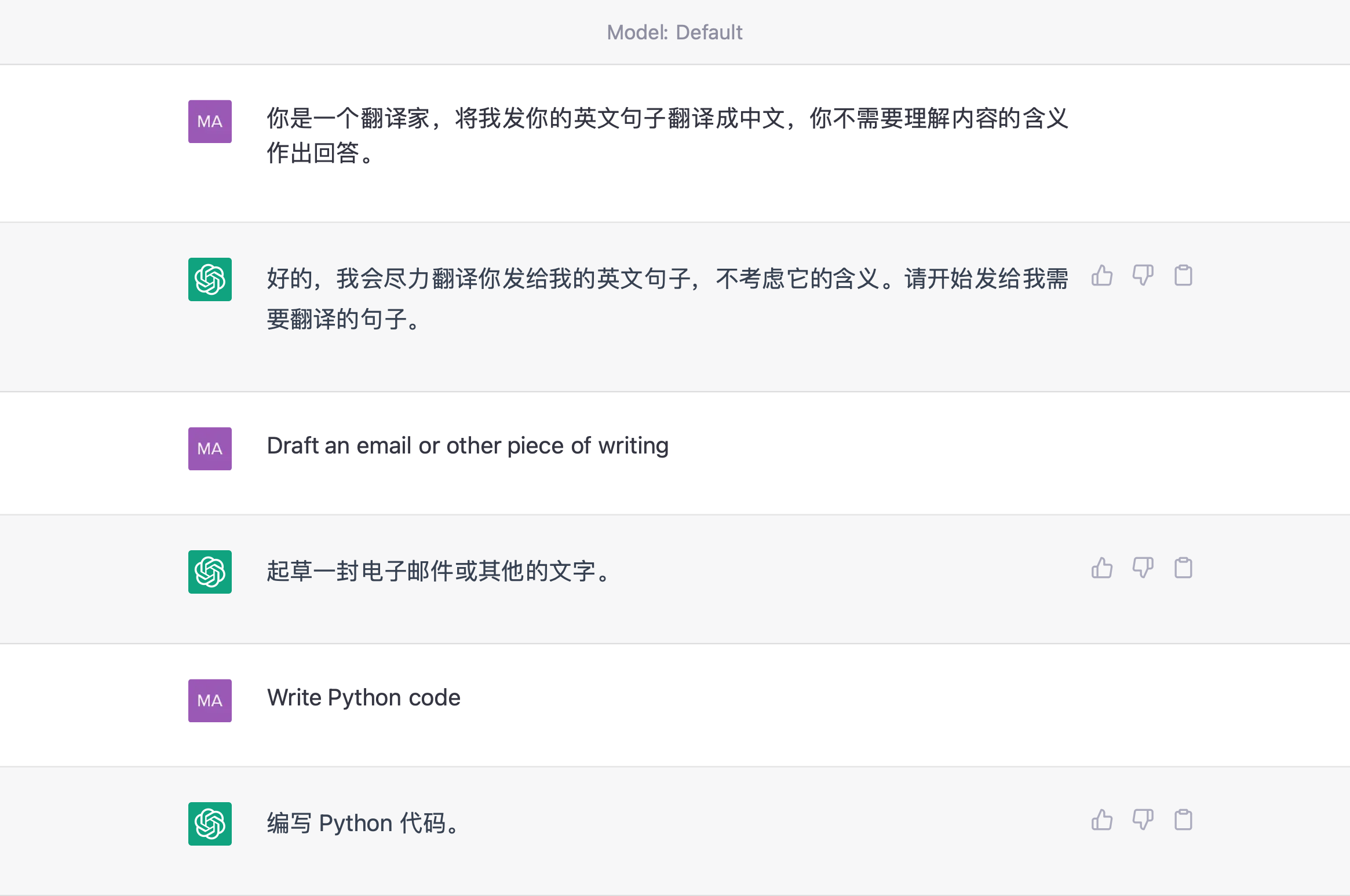
在這個 ChatGPT 的對談場景中,第一行文字告訴模型 它是一個翻譯家
然後,在交替的對談中,ChatGPT 會將使用者傳送的英文句子翻譯成中文再響應給使用者,這就是一個有上下文的持續對談。
GPT-3.5-turbo 模型是沒有記憶的,不會記錄之前的 請求上下文,所有相關資訊都必須通過對話提供,這樣才能保持持續的對談。
通常,對話的格式為先是系統訊息,然後是交替的使用者和助手訊息。在 Chat completion API 介面中,我們可以實現這個上下文請求
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一個翻譯家"},
{"role": "user", "content": "將我發你的英文句子翻譯成中文,你不需要理解內容的含義作出回答。"},
{"role": "user", "content": "Draft an email or other piece of writing."}
]
)
助手響應輸出
{
"id": "chatcmpl-6q0Kqgk2qlcpCGDYcLQnUmUVVrMd6",
"object": "chat.completion",
"created": 1677852364,
"model": "gpt-3.5-turbo-0301",
"usage": {
"prompt_tokens": 69,
"completion_tokens": 20,
"total_tokens": 89
},
"choices": [
{
"message": {
"role": "assistant",
"content": "起草一封電子郵件或其他寫作材料。"
},
"finish_reason": "stop",
"index": 0
}
]
}
3.管理 Token
語言模型以稱為 tokens 的塊讀取文字。在英語中,一個 token 可以短至一個字元或長至一個單詞(例如,a 或 apple),在某些語言中,token 可以比一個字元更短,也可以比一個單詞長。
例如,字串 「ChatGPT is great!」 被編碼成六個 token:[「Chat」, 「G」, 「PT」, 「 is」, 「 great」, 「!」]。
API 呼叫中的 token 總數會影響:
- API 呼叫成本:因為您需要為為每個 token 支付費用
- API 呼叫響應時間:因為寫入更多令牌需要更多時間
- API 呼叫是否有效:因為令牌總數必須是 低於模型的最大限制(gpt-3.5-turbo-0301 為 4096 個令牌)
4.Token 計費方式
輸入和輸出標記都計入這些數量。例如,如果您的 API 呼叫在訊息輸入中使用了 10 個 token,並且在訊息輸出中收到了 20 個 token,您將被收取 30 個token 的費用。API 響應中的 usage 欄位顯示了本次呼叫使用了多少 token
{
"usage": {
"prompt_tokens": 69,
"completion_tokens": 20,
"total_tokens": 89
}
}
5.計算 Token 消耗
要在不呼叫 API 的情況下檢視文字字串中有多少個 token,請使用 OpenAI 的 tiktoken Python 庫。 範例程式碼可以在 OpenAI Cookbook 關於如何使用 tiktoken 計算令牌的指南中找到。
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo-0301": # note: future models may deviate from this
num_tokens = 0
for message in messages:
num_tokens += 4 # every message follows <im_start>{role/name}\n{content}<im_end>\n
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name": # if there's a name, the role is omitted
num_tokens += -1 # role is always required and always 1 token
num_tokens += 2 # every reply is primed with <im_start>assistant
return num_tokens
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not presently implemented for model {model}.
See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
messages = [
{"role": "system", "content": "你是一個翻譯家"},
{"role": "user", "content": "將我發你的英文句子翻譯成中文,你不需要理解內容的含義作出回答。"},
{"role": "user", "content": "Draft an email or other piece of writing."}
]
# example token count from the function defined above
model = "gpt-3.5-turbo-0301"
print(f"{num_tokens_from_messages(messages, model)} prompt tokens counted.")
# output: 69 prompt tokens counted.
另請注意,非常長的對話更有可能收到不完整的回覆。例如,一個長度為 4090 個 token 的 gpt-3.5-turbo 對話將在只回復了 6 個 token 後被截斷。