幾種型別神經網路學習筆記
跟隨【導師不教?我來教!】同濟計算機博士半小時就教會了我五大深度神經網路,CNN/RNN/GAN/transformer/LSTM一次學會,簡直不要太強!_嗶哩嗶哩_bilibili瞭解的五大神經網路,整理筆記如下:
視訊是唐宇迪博士講解的,但是這個up主發的有一種東拼西湊的感覺,給人感覺不是很完整
一、折積神經網路(優勢:計算機視覺)
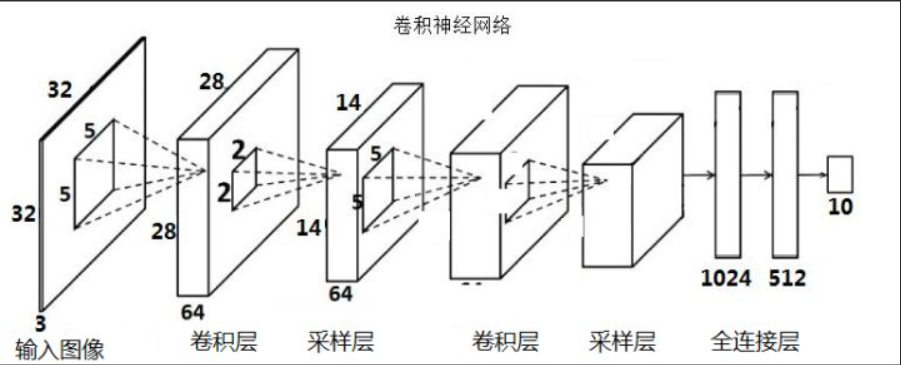
1、折積的作用:特徵提取,本質就是提取折積核那個大小區域中的特徵值
2、利用不同的折積核對同一資料進行提取,可以得到多維度的特徵圖,豐富特徵內容
3、邊緣填充(padding)可以解決邊緣特徵在提取時權重不高的問題
4、折積的結果公式:
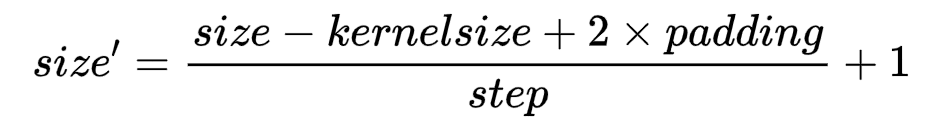
其中size'是下一次特徵圖長或寬,size是這一次特徵圖的長或寬,kernelsize是折積核大小,padding留白行數,step為折積步長
5、為了減少計算量,在一輪折積中,折積核的引數是共用的,不會隨著位置改變而改變
6、池化層的作用:特徵降維
7、通常說幾層神經網路的時候,只有帶權值與引數的層會被計入,如折積層與線性層,如池化層這種不帶權值與引數的層不會被計入
8、經典的CNN網路模型:AlexNet、VGG、ResNet(利用殘差相加提供了增加網路深度的方法)
9、感受野:特徵圖中特徵所代表的原圖中區域的大小
10、具有相同的感受野的多個小折積核組合與一個大折積核相比,所需要的引數少,特徵提取更細緻,加入的非線性變換也更多,所以現在基本上都使用小折積核來進行折積
二、迴圈神經網路(RNN)(優勢:時間序列問題處理,多用於NLP)
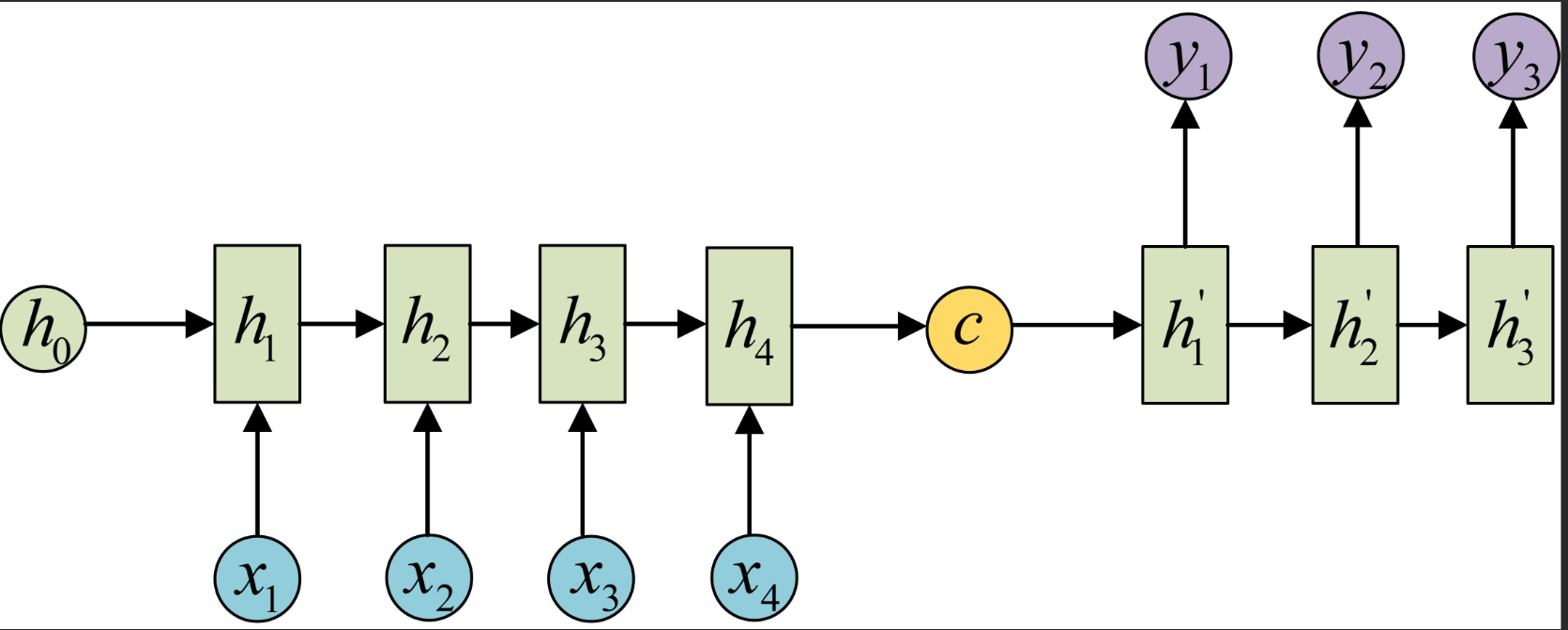
1、輸入資料為特徵向量,並且按照時間順序排列
2、RNN網路缺點是會記憶之前所有的資料,LSTM模型通過加入遺忘門解決了這個問題
3、範例:Word2Vec 文字向量化:建立一個多維的文字空間,一個向量就代表一個詞,詞義越相近的詞在文字空間中的距離也就越近
4、Word2Vec模型中,反向傳播的過程中,不僅會更新神經網路,還會更新輸入的詞向量
5、RNN經典模型:CBOW,skipgram
6、由於資料量大,模型構建方案一般不使用輸入一詞輸出預測詞的模式,而是使用輸入前一詞A和後一詞B,輸出B在A後的概率,但是由於資料集均為通順語句採集而來,概率均為1,所以需要人為在資料集中加入錯誤語句,並且標記概率為0,被稱為負取樣
三、對抗生成網路(GNN)
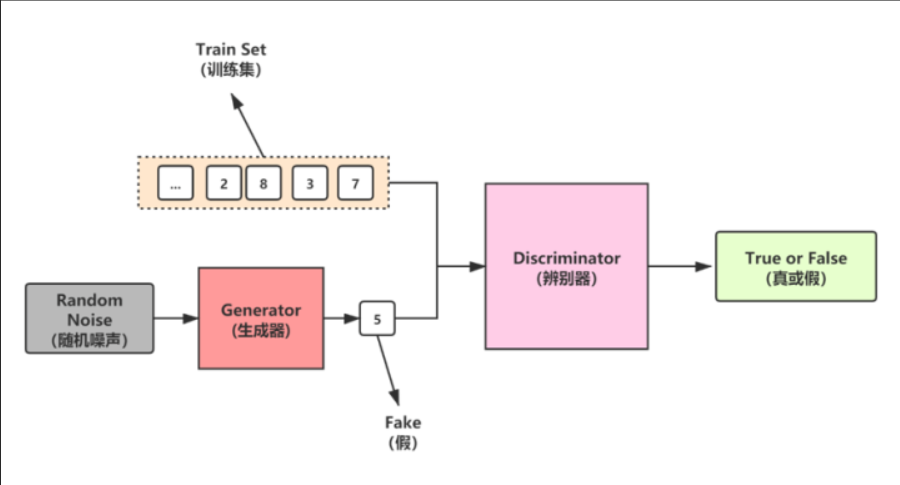
1、對抗生成網路分為生成器、判別器、損失函數,其中生成器負責利用噪聲生成資料,產生以假亂真的效果,判別器需要火眼金睛,分辨真實資料與虛假資料,損失函數負責讓生成器更加真實,讓判別器更加強大。
四、Teansformer(功能強大,但是需要很巨量資料來訓練)
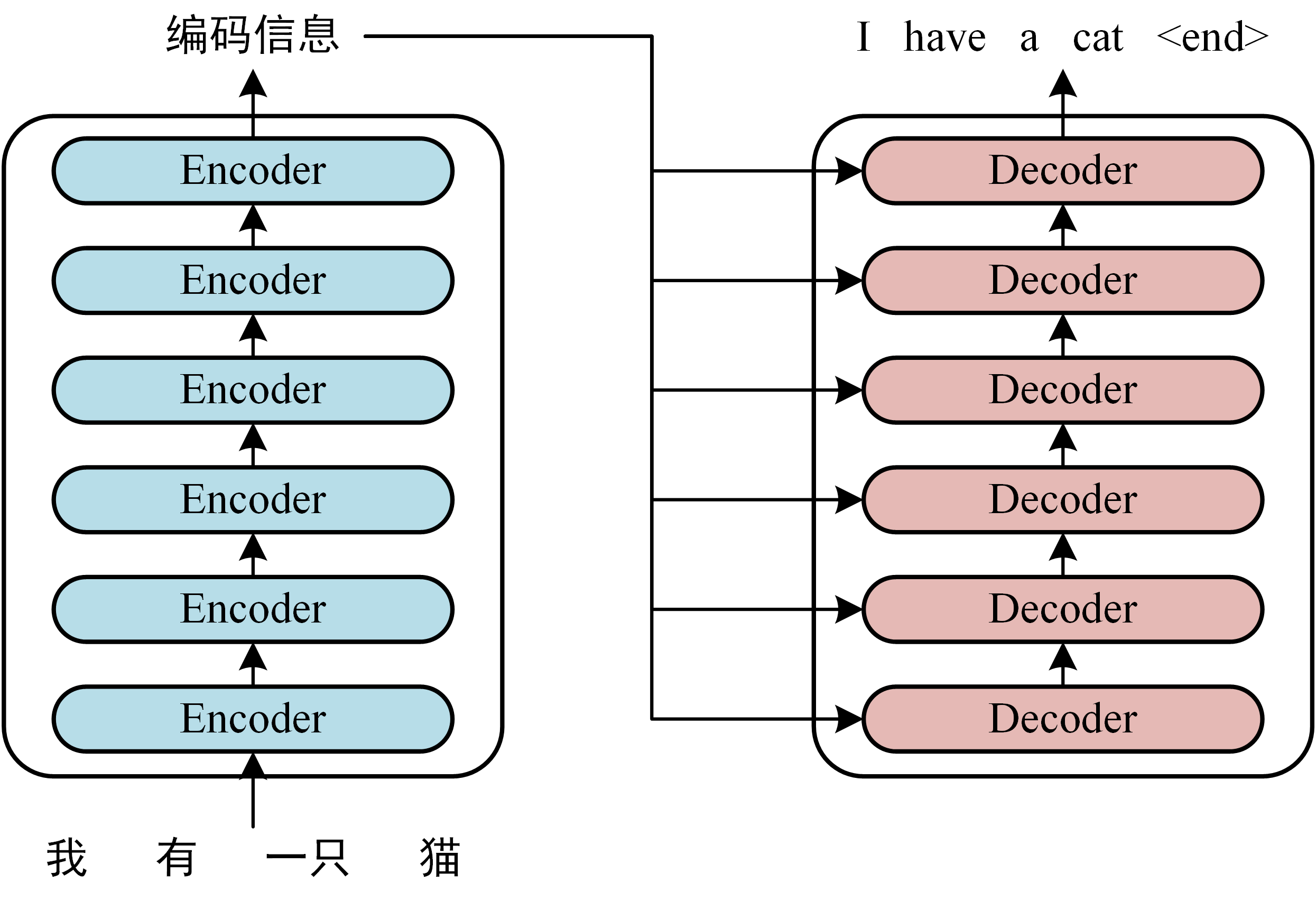
1、Transformer由編碼器(Encoder)和解碼器(Decoder)組成
2、Transfromer的本質就是重組輸入的向量,以得到更加完美的特徵向量
3、Transfromer的工作流程:
3.1、獲取輸入句子的每一個單詞表示向量X(由單詞特徵加上位置特徵得到)
3.2、將得到的單詞表示向量矩陣X傳入Encoder中,輸出編碼矩陣C,C與輸入的單詞矩陣X維度完全一致
3.3、將矩陣C傳遞到Decoder中,Decoder依次根據當前翻譯過的單詞預測下一個單詞。
4、Transformer的內部結構如下圖所示
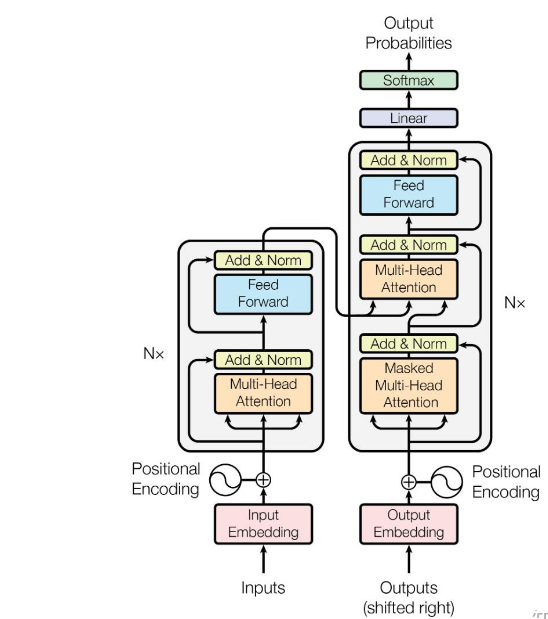
5、在訓練時,Decoder中的第一個Multi-Head Attention採用mask模式,即在預測到第i+1個單詞時候,需要掩蓋i+1之後的單詞。
6、單詞的特徵獲取方法有很多種,比如Word2Vec,Glov演演算法預訓練,或者也可以使用Transformer訓練得到,位置特徵則可以通過公式得到,公式如下:
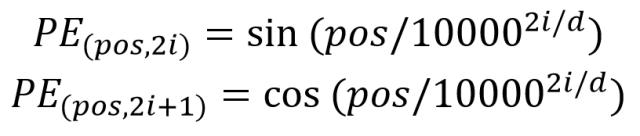
7、Add是殘差連結操作,Norm是LayerNormalization歸一化操作,Feed Forward層是兩個全連線層,第一個全連線層使用ReLU進行非線性啟用,第二個不啟用
8、Transformer內部結構存在多個Multi-Head Attention結構,這個結構是由多個Attention組成的多頭注意力機制,Attention 注意力機制為Transformer的重點,它可以使模型更加關注那些比較好的特徵,忽略差一些的特徵
9、Attention內部結構如下圖所示
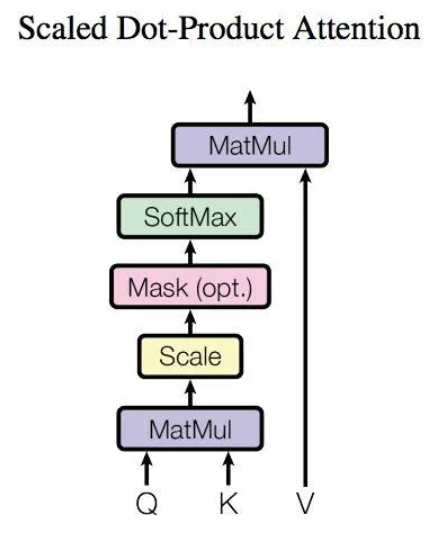
10、Attention接收的輸入為單詞特徵矩陣X或者上一個Encoder block的輸入,經過三個矩陣WQ、WK、WV的變換得到了三個輸入Q、K、V然後經過內部計算得到輸出Z
11、Attention內部計算的公式可以概況為

12、Multi-Head Attention將多個Attention的輸出拼接在一起傳入一個線性層,得到最終的輸出Z
13、Transformer與RNN相比,不能利用單詞順序特徵,所以需要在輸入加入位置特徵,經過實驗,加入位置特徵比不加位置特徵的效果好三個百分點,位置特徵的編碼方式不對模型產生影響。
14、VIT是Transfromer在CV領域的應用,VIT第一層的感受野就可以覆蓋整張圖
15、VIT的結構如下:
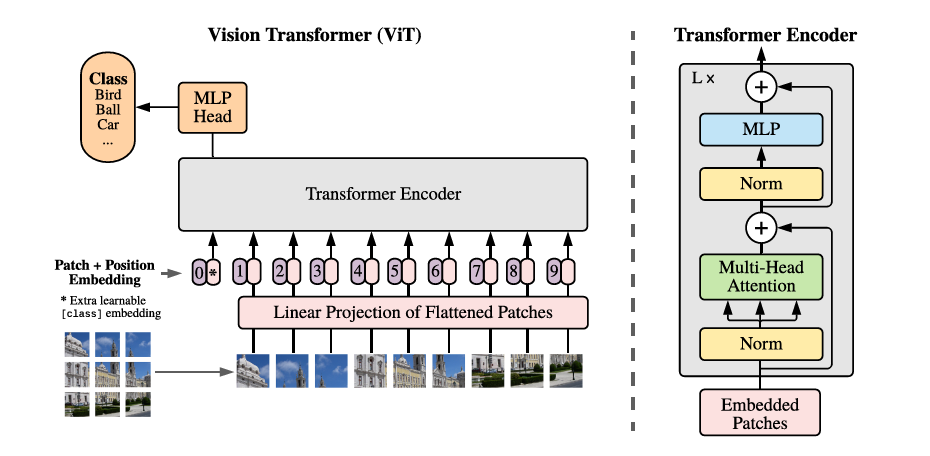
16、VIT將圖片分為多個patch(16*16)然後將patch投影為多個固定長度的向量送入Transformer,利用Transformer的Encoder進行編碼,並且在輸入序列的0位置加入一個特殊的token,token對應的輸出就可以代表圖片的類別
17、Transformer需要大量的資料,比CNN多得多,需要谷歌那個級別的資料量
18、TNT模型:VIT將圖片分為了16*16的多個patch,TNT認為每個patch還是太大了,可以繼續進行分割
19、TNT模型方法:在VIT基礎上,將拆分後的patch當作一張影象進行transformer進一步分割,劃分為新的向量,通過全連線改變輸出特徵大小,使其重組後的特徵與patch編碼大小相同,最後與元素輸入patch向量進行相加
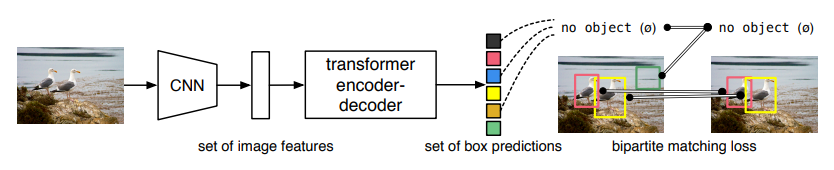
20、DETR模型,用於目標檢測,結構如下
五、LSTM長短期記憶
這部分基本是程式碼解析了,就沒有記錄,我認為LSTM其實就是RNN的一個分支。