火山引擎 DataLeap:揭祕位元組跳動資料血緣架構演進之路
更多技術交流、求職機會,歡迎關注位元組跳動資料平臺微信公眾號,回覆【1】進入官方交流群
DataLeap 是火山引擎數智平臺 VeDI 旗下的巨量資料研發治理套件產品,幫助使用者快速完成資料整合、開發、運維、治理、資產、安全等全套資料中臺建設,降低工作成本和資料維護成本、挖掘資料價值、為企業決策提供資料支撐。
資料血緣是幫助使用者找資料、理解資料以及使資料發揮價值的基礎能力。基於位元組跳動內部沉澱的資料治理經驗,火山引擎 DataLeap 具備完備的資料血緣能力,本文將從資料血緣應用背景、發展概況、架構演講以及未來展望四部分,為大家介紹資料血緣在位元組跳動進化史。
背景介紹
1. 資料血緣是資料資產平臺的重要能力之一
在火山引擎 DataLeap 中,資料資產平臺主要提供後設資料搜尋、展示、資產管理以及知識發現能力。在資料資產平臺中,資料血緣是幫助使用者找資料、理解資料以及使資料發揮價值的重要基礎能力。

2. 位元組跳動的資料鏈路情況

資料來源
在位元組跳動,資料主要來源於以下兩部分:
-
第一,埋點資料:
主要來自 APP 端和 Web 端。經過紀錄檔採集後,這類資料最終進入到訊息佇列中。
-
第二,業務資料:
該類資料一般以線上形式儲存,如 RDS 等。
中間部分是以 Hive 為代表的離線數倉:
該類資料主要來自訊息佇列或者線上儲存,經過資料整合服務把資料匯入離線數倉。經過離線數倉的資料加工邏輯,流轉到以 ClickHouse 為代表的 OLAP 引擎。
另外,在訊息佇列部分,還會通過 Flink 任務或者其他任務對 Topic 分流,因此上圖也展現了一個回指的箭頭。
資料去向
主要以指標系統和報表系統為代表。指標系統包含重要且常用的業務指標,如抖音的日活等。報表系統是把指標以視覺化形式展現出來。
資料服務
主要通過 API 提供資料,具體而言,從訊息佇列、線上儲存、下游消費以及上圖右側所示的資料流轉,都涵蓋在資料血緣範圍內。
血緣發展概況
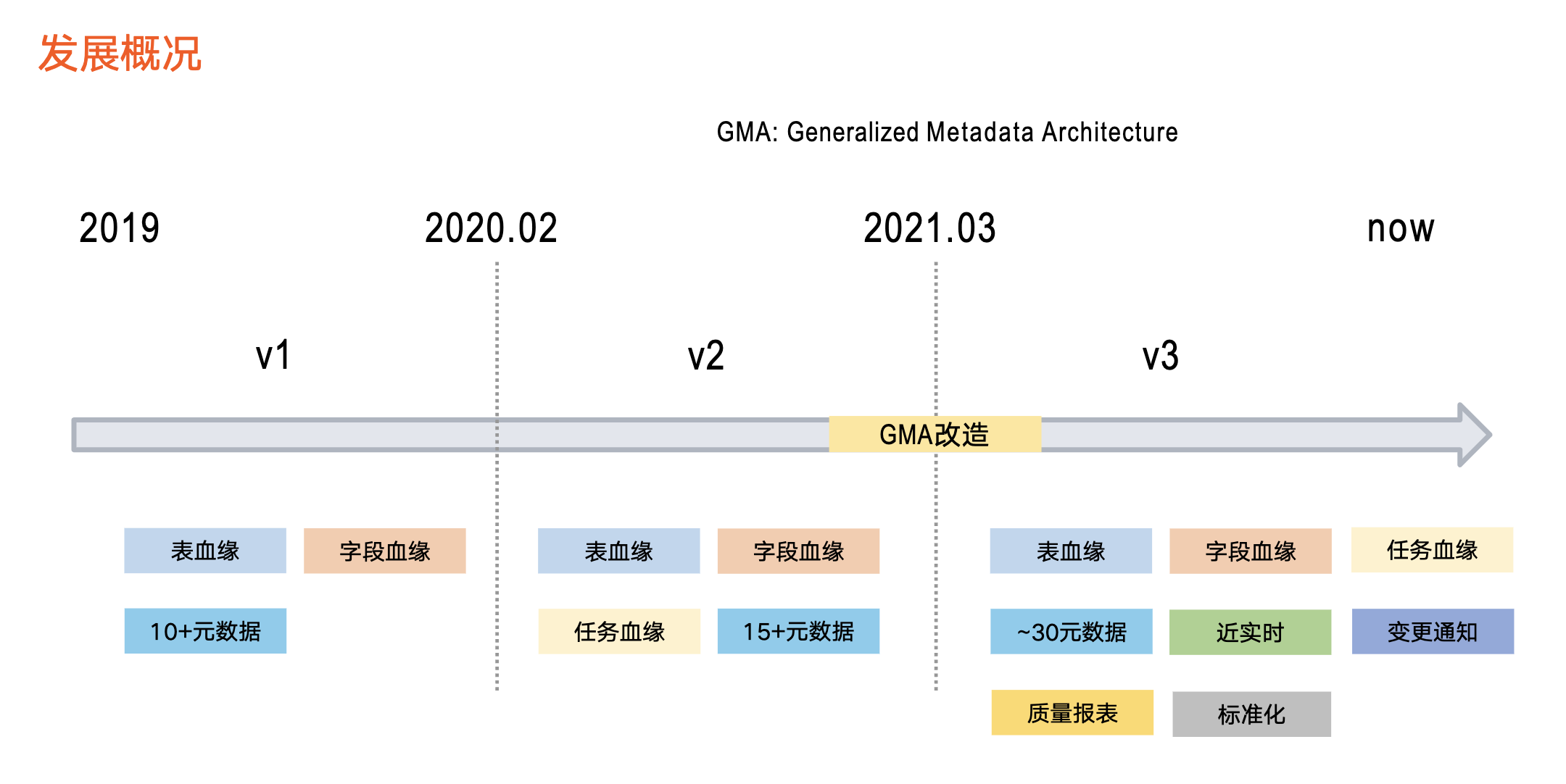
接下來介紹血緣在位元組跳動的三個發展階段。
第一階段:2019 年左右開始
第一階段主要提供資料血緣基礎能力,以 Hive 和 ClickHouse 為代表,支援表級血緣、欄位血緣,涉及 10+後設資料。
第二階段:從 2020 年初開始
第二階段引入了任務血緣,同時支援的後設資料型別進行擴充,達到 15+。
第三階段:從 2021 年上半年至今
在這一階段,我們對整個後設資料系統(即前文提到的資產平臺)進行了 GMA 改造,同步對血緣架構進行全面升級,由此支援了更豐富的功能,具體包括:
-
首先,後設資料種類擴充到近 30 種且時效性提升。之前以離線方式更新血緣資料,導致資料加工邏輯變化的第二天,血緣才會產生變化。目前,基於近實時的更新方式,資料加工邏輯在 1 分鐘內即在血緣中體現。
-
其次,新增血緣消費方式的變更通知。由於該版本支援實時血緣,業務方產生及時瞭解血緣變化的需求,變動通知功能就是把血緣變化情況以訊息佇列的形式告知業務方。
-
再次,支援評估血緣質量。新增一條鏈路,專門服務於血緣資料質量。
-
最後,引入標準化接入方式。為了減少重複工作、降低血緣接入成本,我們制定了詳細的血緣接入標準,業務方資料均以標準化方式接入。
以上就是整體的發展情況,目前處於第三個版本當中。
資料血緣架構的演進
接下來介紹血緣架構的演進。
-
第一版血緣架構:建立血緣基本能力,初探使用場景
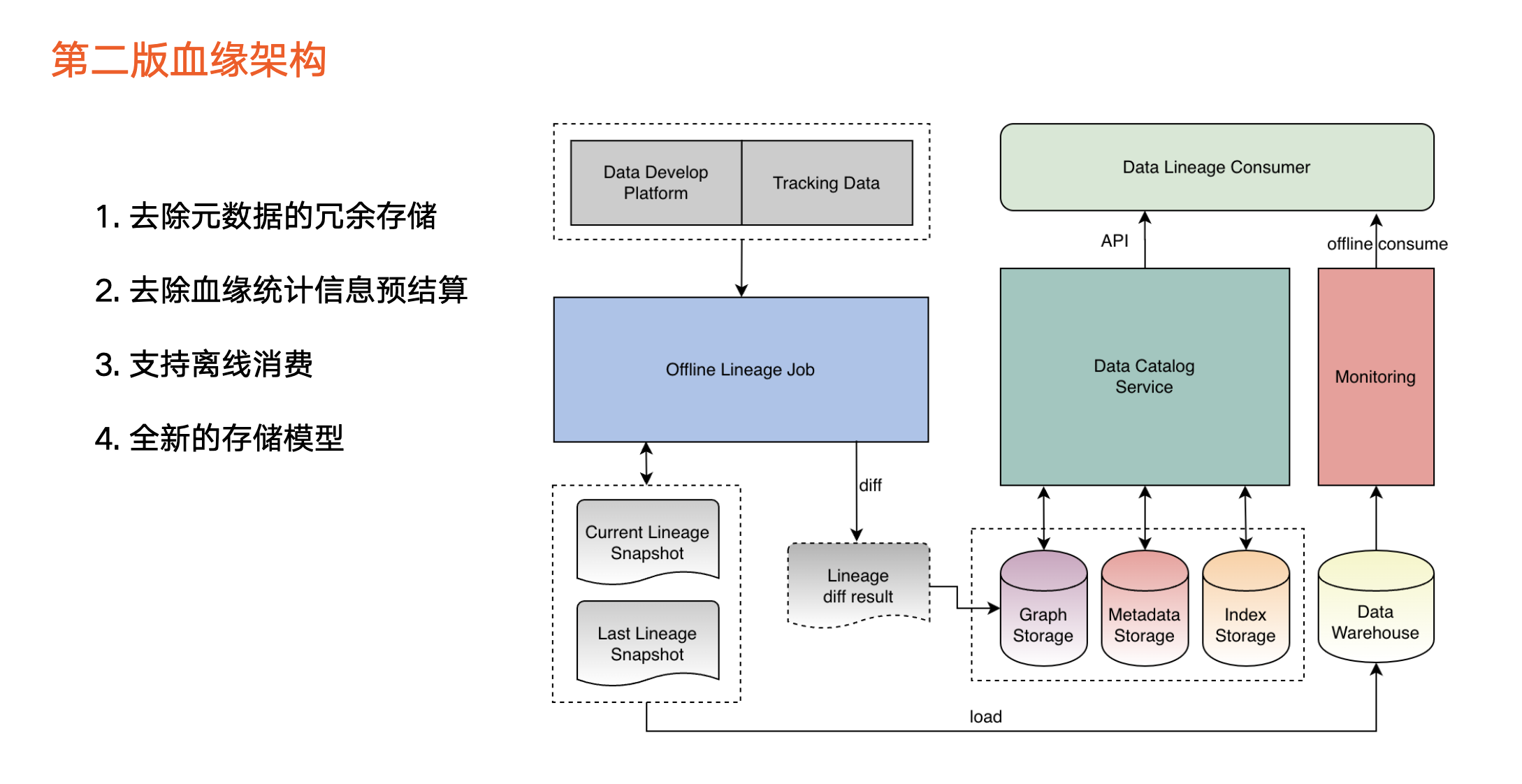
血緣架構

-
在資料來源方面,目前血緣主要包括兩個資料來源(見上圖左上角):
第一,資料開發平臺:使用者在開發平臺寫任務,並對資料加工,由此產生血緣資料。
第二,追蹤資料:第三方平臺(即任務平臺)對使用者埋點等資料進行計算,也會產生血緣資訊。
-
在血緣加工任務方面(見上圖中間部分):
這部分會對任務進行血緣解析,產生血緣快照檔案。由於第一版採用離線方式執行,每天該血緣任務均會生成對應的血緣快照檔案。我們通過對比前後兩天的血緣快照檔案,來獲取血緣的變更情況,然後把這些變更載入到圖中。
除此之外,血緣中涉及的後設資料會冗餘一份,並儲存到圖裡。
-
在血緣儲存方面(見上圖右邊部分),除了圖資料庫之外,血緣本身也會依賴後設資料的儲存,如 Mysql 以及索引類儲存。
-
在血緣消費層面,第一版只支援通過 API 進行消費。
最後總結該版本的三個關鍵點:
-
血緣資料每天以離線方式全量更新。
-
通過對比血緣快照來判斷血緣更新操作,後面將為大家詳細解答為什麼要通過對比的方式。
-
冗餘一份後設資料儲存到圖資料庫中。
儲存模型
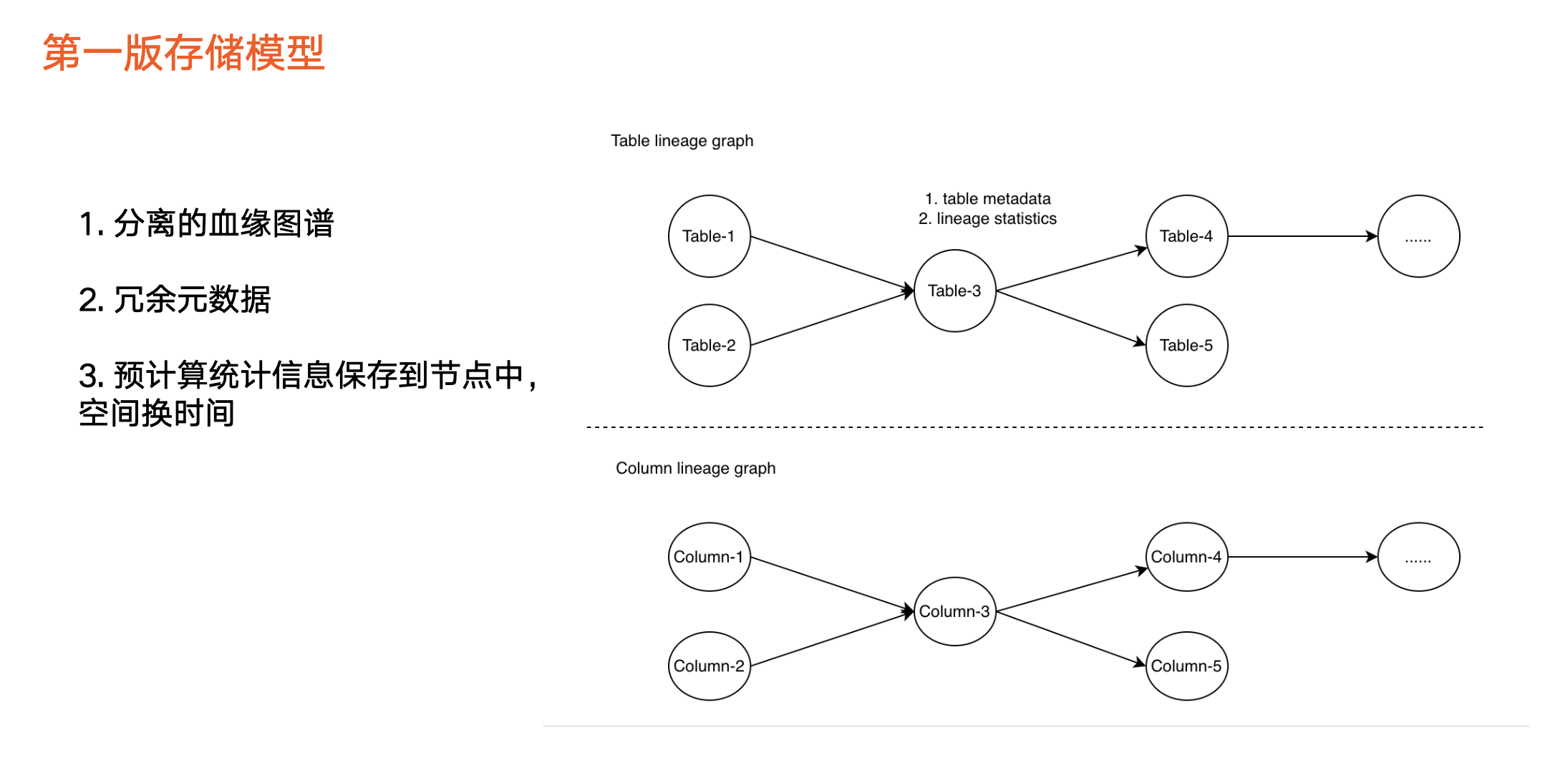
圖中上半部分為表級血緣,只包括一種型別節點,即表節點,比如 Hive 表、 ClickHouse 表等。
圖中下半部分為欄位血緣,第一版主要是提供構建血緣的基本能力,因此用彼此分離的兩張圖來實現。由於血緣中後設資料進行了冗餘,每個圖裡面的每個節點裡面都儲存表相關的後設資料,包括業務資訊以及其他資訊。
除此之外,我們會預先計算一些統計資訊,儲存到圖的節點中,如當前節點下游總節點數量、下游層級數量等。
採用預先計算的目的是為了「用空間換時間」,在產品對外展示的功能上可能要露出資料資訊,如果從圖裡實時查詢可能影響效能,因此採用空間換時間的方式來支援產品的展示。
2. 第二版血緣架構:血緣價值逐步體現,使用場景拓寬
血緣架構
經過 1 年的使用,血緣在資料資產中的價值逐步體現,且不斷有應用場景落地,由此我們進行了第二版本升級。升級點具體包括:
-
第一,去除第一版本中後設資料冗餘。後設資料冗餘在圖提升了效能,但是可能導致 Metadata Store 的後設資料不一致,給使用者帶來困擾。
-
第二,去掉了預計算的統計資訊。隨著血緣的資料量增多,預計算的資訊透出不能給很好輔助使用者完成業務判斷,且導致任務負擔重。比如,即使知道某一節點的下游資料量,還是要拉出所有節點才能進一步分析或決策。
-
第三,支援一條全新鏈路,在新增鏈路上,我們把血緣快照檔案匯入離線數倉,主要應用於兩個場景:
離線分析場景或全量分析場景。
基於離線數倉的血緣資料實現資料監控,儘早發現血緣異常情況。
因此,從第二版開始,資料血緣新增了很多離線消費方式。
儲存模型
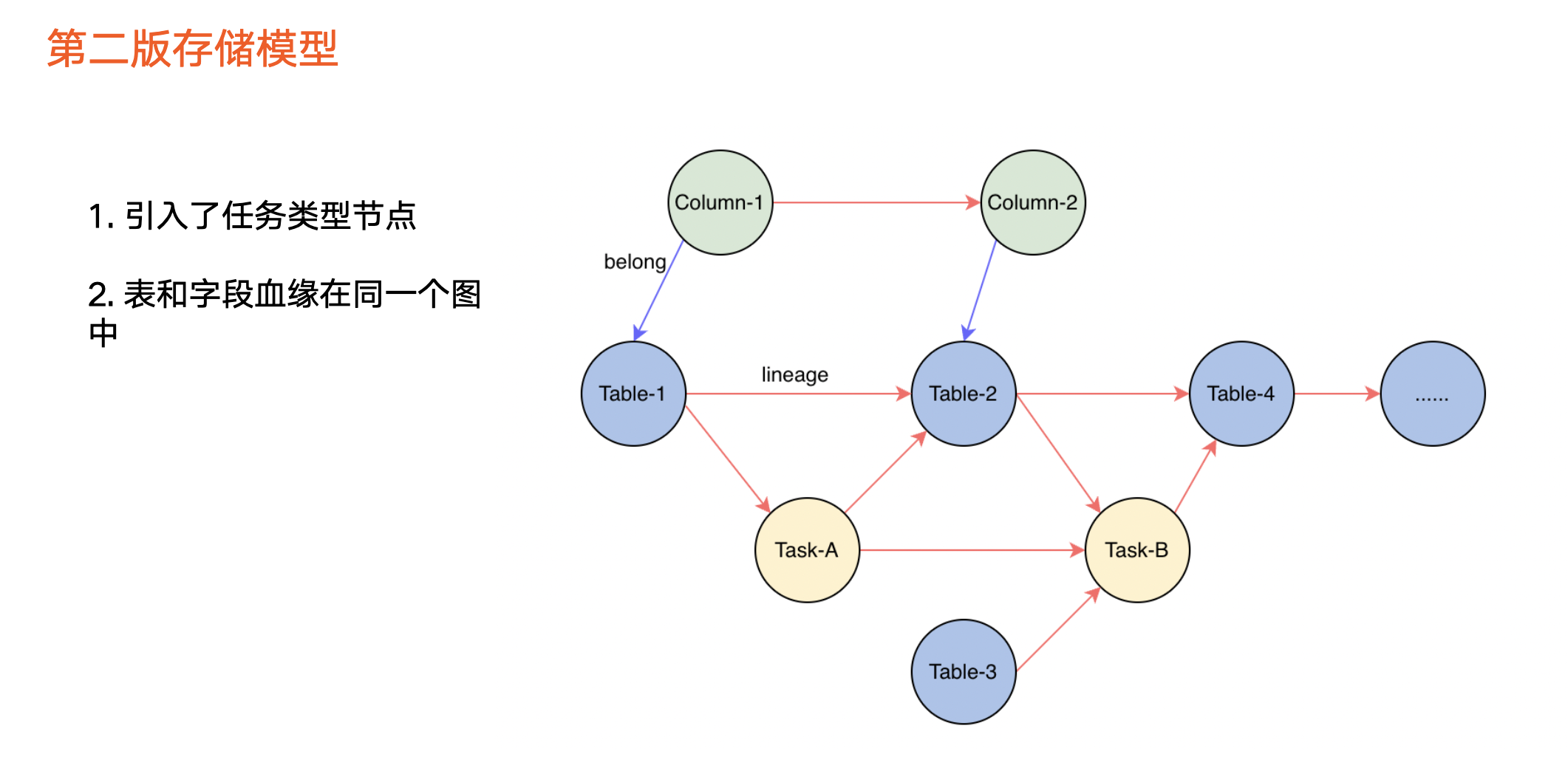
第二個版本引入了全新血緣儲存模型(如上圖所示),並將第一個版本兩張圖融合成一張圖,解決了無法通過表遍歷欄位血緣的問題。
除此之外,第二個版本還引入了任務型別節點,服務於以下三種遍歷場景:
-
單純遍歷資料血緣,即從資料節點到資料節點。
-
資料血緣和任務血緣混合方式。
-
單純任務之間血緣關係。
第三版血緣架構:血緣成為資料發揮價值的重要基礎能力
血緣架構

2021 年初,火山引擎 DataLeap 資料血緣迭代到第三版,也成為公司內部資料發揮價值的重要基礎能力。
服務於業務方對資料高質量要求,第三版升級點如下:
-
血緣資料來源:除了支援兩個平臺之外,還支援包括報表、第三方人物誌等其他平臺 。
-
血緣任務:之前版本只支援每天定時執行的離線排程方式,第三版引入實時消費方式,支援實時解析血緣,並提取通用邏輯,複用離線血緣任務和實時血緣任務。
-
血緣解析:不同型別任務需要使用不同解析邏輯。在之前版本中,Hive SQL 任務和 Flink SQL 任務的解析邏輯是整合到血緣任務中。從第三版開始,我們把解析服務拆解成可設定的外掛,實現了外掛化。當某一種任務型別的血緣解析邏輯需要調整的時候,只用改動其中一個解析服務,其他解析服務不受影響,同時也讓血緣任務更好維護。
-
後設資料儲存統一:只依賴圖資料庫和索引儲存,同時支援從系統中把所有相關的資料匯出離線數倉。
-
實時消費:血緣發生變更的資訊會被同步到訊息佇列。
-
血緣的驗證模組:使用方對血緣資料質量有高要求,因此第三版引入新的血緣的驗證模組。
驗證的前提是要有引擎埋點資料,該埋點資料能清楚知道某一個任務具體讀取資料情況、寫入資料情況
在離線數倉中,通過埋點資料與血緣資料中對比,生成血緣資料質量報表。
資料質量報表對血緣消費者開放,消費者能夠清晰瞭解每個血緣鏈路準確性和覆蓋情況。
-
血緣標準化接入:即讓使用者快速接入資料,不用每一種血緣接入都重複寫邏輯。
儲存模型

第三版血緣儲存模型相對於前兩版的升級點如下:
-
以任務為中心。黃色圓圈為任務節點,資料加工邏輯產生血緣,因此我們把資料加工邏輯抽象為任務節點,血緣的建立則以任務為媒介,任務成為血緣中心。也就是說,表 1、表 2、表 3 之間的血緣,是通過任務 a 完成構建。假設沒有任務 a ,則三個表之間的血緣也不存在。
-
表血緣和欄位血緣模型統一,在欄位血緣之間沒有具體任務的情況下,我們會抽象出虛擬的任務來統一模型。由此,任務和任務之間的血緣採用新的邊來表示依賴關係。
重要特性
增量更新

在實時血緣基礎上,我們還支援增量更新能力,即當某一個任務的加工邏輯發生變化時,只需要更新圖中一小部分。
-
血緣建立:資料加工邏輯上線或開始生效,將被抽象為圖資料庫的操作,即建立一個任務節點和對應的資料節點,並建立兩者之間的邊。上圖例子為表 1、表 2 和任務的邊,以及任務和表 3 之間的邊。
-
血緣刪除:資料的加工邏輯發生了下線、刪除或不生效。先在圖裡面查詢該任務節點,把任務節點以及關聯血緣相關的邊刪除。血緣儲存模型以任務為中心,因此表 1、表 2 和表 3 之間的血緣關係也同步消失,這部分血緣即被刪除。
-
血緣更新:任務本身沒有發生上線或下線,但計算邏輯發生變化。例如,原本血緣關係是表 1、表 2 生成表 3,現在變成了表 2、表 4 生成表 3。我們需要做的如下:
解析出最新血緣狀態,即表 2、表 4 到表 3 的血緣關係,與當前血緣狀態做對比(主要對比該任務 a 相關的邊),上圖例子是入邊發生變化,那麼刪除其中一條邊,構建另外一條邊,即可完成該任務節點的血緣更新。
如果面臨以上血緣關係變化,但是沒有該任務節點,應該執行哪些操作來更新血緣?由於只有血緣最新狀態和當前狀態,沒有任務節點去獲取最小單位的血緣關係,所以只能進行全量血緣或全圖對比,才能得出邊的變化情況,再更新到圖資料庫中。如果不進行全量血緣或全圖對比,無法知曉如何刪除條和建立條,導致血緣無法更新。這也是前兩個版本需要進行血緣快照對比的原因。
血緣標準化

在火山引擎 DataLeap 中,通常把血緣資料接入抽象成一個 ETL 。
首先,血緣資料來源,即第三方平臺血緣相關的資料,通常是一個資料加工邏輯或者稱為任務。接著,對這些任務完成 KeyBy 操作,並與資料資產平臺的任務資訊做對比,確定如何進行任何建立、刪除和更新。
在再完成過濾操作之後, 由 Lineage Parser 對建立、更新等任務進行血緣解析,得出血緣結果之後會生成表示圖相關操作的 Event,最終通過 Sink 把資料寫入到資料資產平臺中。
上圖綠色和藍色分別表示:
-
藍色:對不同血緣接入過程的邏輯一致,可抽象出來並複用。
-
綠色:不同血緣的實現情況不一樣。例如,某一個平臺為拉取資料,另外一個平臺通過其他方式獲取資料,導致三個部分不一樣,因此我們抽取特殊部分,複用共同部分。除此之外,我們還提供通用 SDK,串聯整個血緣接入流程,使得接入新的血緣時,只需要實現綠色元件。
目前,位元組跳動內部業務已經可以使用 SDK 輕鬆接入血緣。
資料血緣質量-覆蓋率
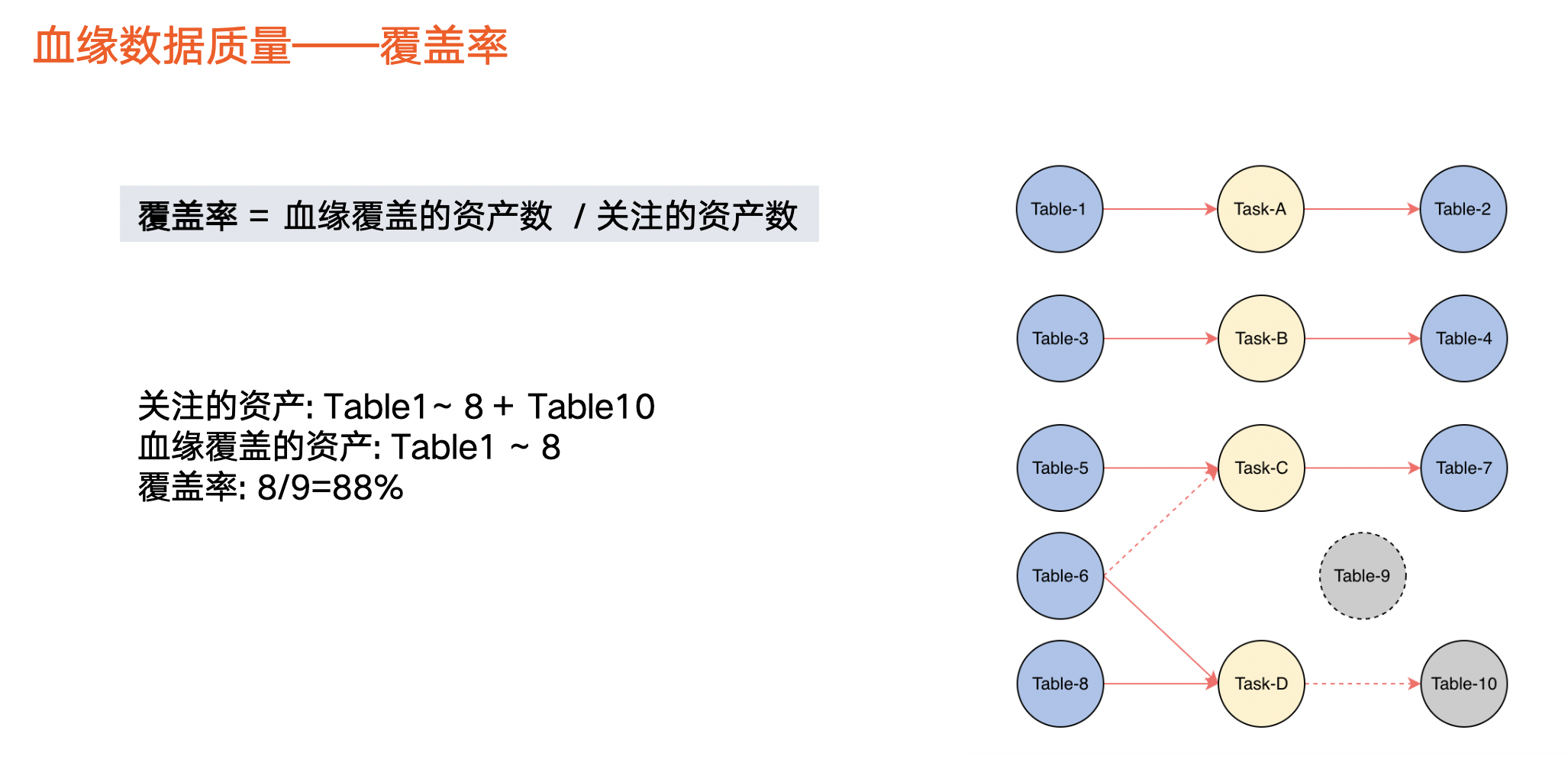
當血緣發展到一定階段,業務方不止關心血緣覆蓋情況、支援情況,還關心血緣資料質量情況。因此,第三版本透出血緣質量相關指標——覆蓋率和準確率。
覆蓋率:血緣覆蓋的資料資產數佔關注的資產數量佔比。
關注的資料資產一般指,有生產任務或有生產行為的資產。上圖虛線圓圈,如 Table 9,使用者建立該表後沒有生產行為,因此也不會產生血緣,在計算中將被剔除掉。上圖實線圓圈,表示有生產行為或有任務讀取,則被認為是關注的資產。關注的資料資產被血緣覆蓋的佔比,即覆蓋率。
以上圖為例,在 10 張表中,由於有任務與 Table 1 ~ 8 關聯,因此判定有血緣。 Table 10,它與 Task-D 之間的連線是虛線,表示本來它應該有血緣,但是實際上血緣任務沒把這個血緣關係解析出來,那麼我們就認為這個 Table 10 是沒有被血緣覆蓋的。整體上被血緣覆蓋的資產就是表 1 ~ 8。除了 Table 9 之外,其他的都是關注的資產,那麼血緣覆蓋的資產佔比就是 8/9。也就是圖上藍色的這第 8 個除以藍色的 8 個加上 Table 10,就是 9 個,所以這個覆蓋率就是 88%。
資料血緣質量-準確率
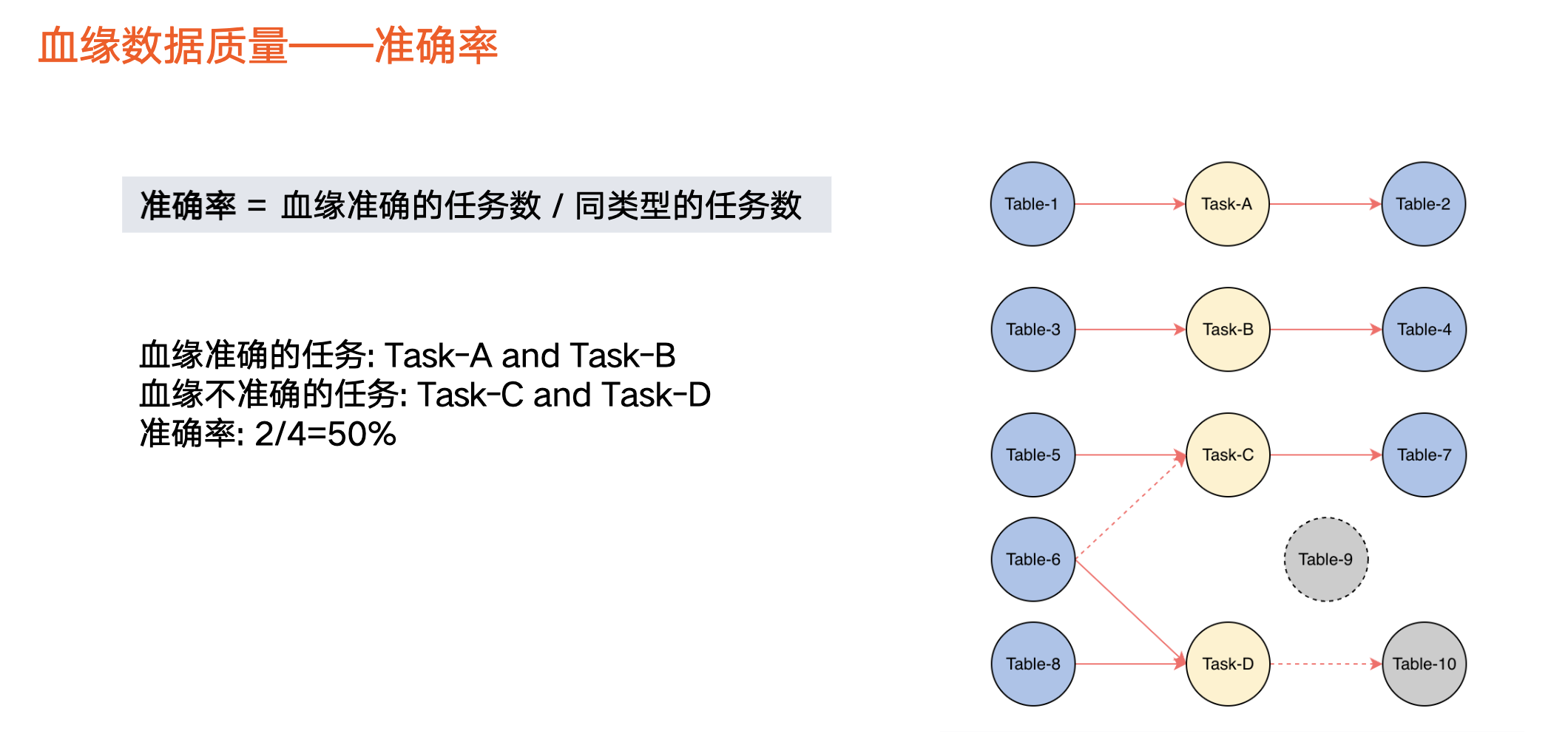
覆蓋血緣不一定是正確的,所以我們還定義了準確率指標,即血緣準確的任務數/同型別的任務數。
舉個例子,假設任務 c 的血緣應該是 Table 5、Table6 生成 Table 7,但實際上被遺漏,沒有被解析(虛線表示),導致任務 c 的血緣不準確。也存在其他情況缺失或多餘情況,導致血緣不準確。
在上圖中,同型別任務包含 4 個,即 a、b、c、d。那麼,準確的血緣解析只有 a、b,因此準確率佔比為 2/4 = 50%。
在火山引擎 DataLeap 中,由於血緣來源是任務,因此我們以任務的視角來看待血緣準確率。
血緣質量-位元組現狀
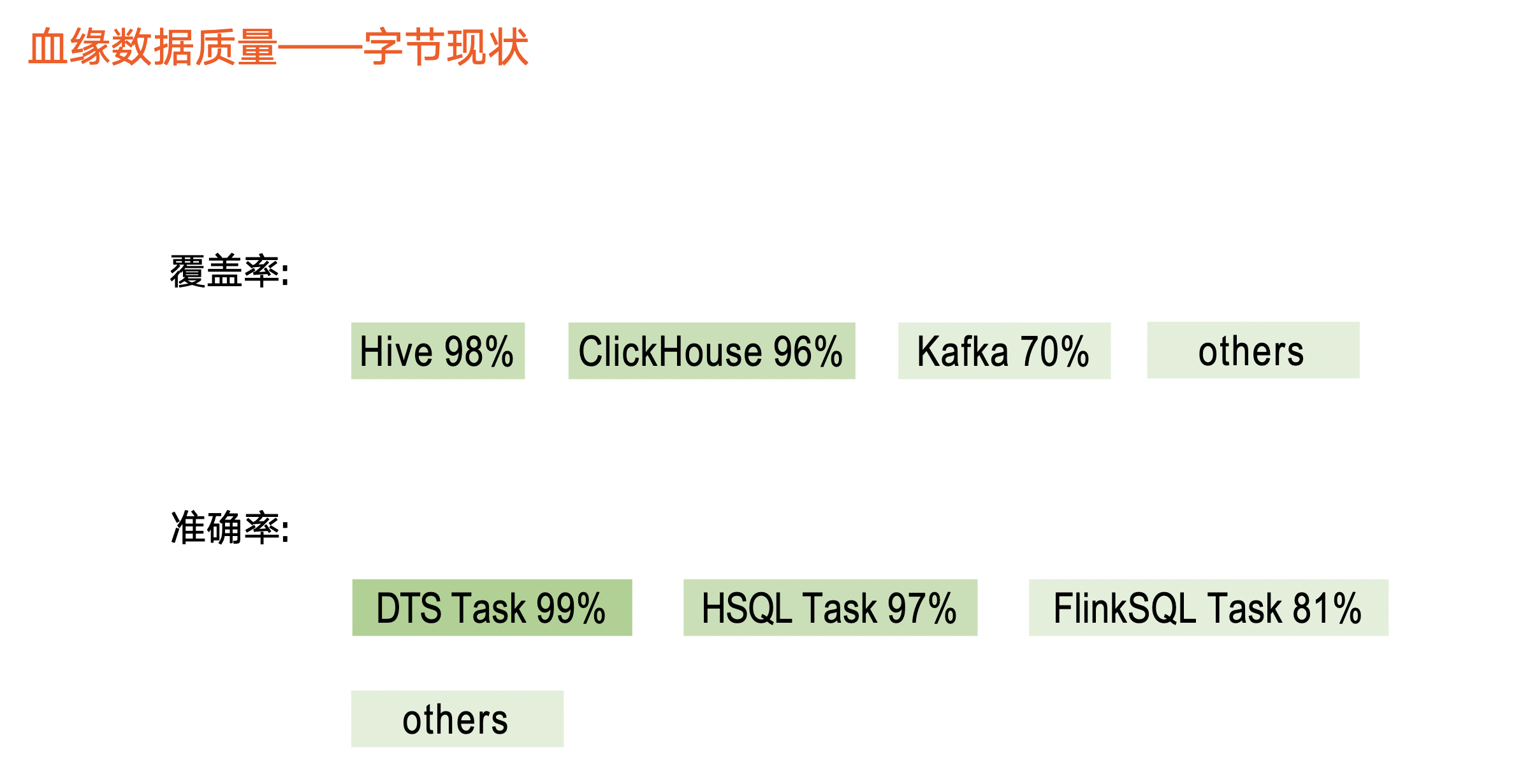
在覆蓋率部分,目前 Hive 和 ClickHouse 後設資料覆蓋度較高,分別達到 98%、96%。對於實時後設資料,如 Kafka ,相關 Topic 覆蓋 70%,其他後設資料則稍低。
在準確率部分,我們區分任務型別做準確性解析。如 DTS 資料整合任務達到 99%以上,Hive SQL 任務、 Flink SQL 任務是 97%、81% 左右。
血緣架構對比
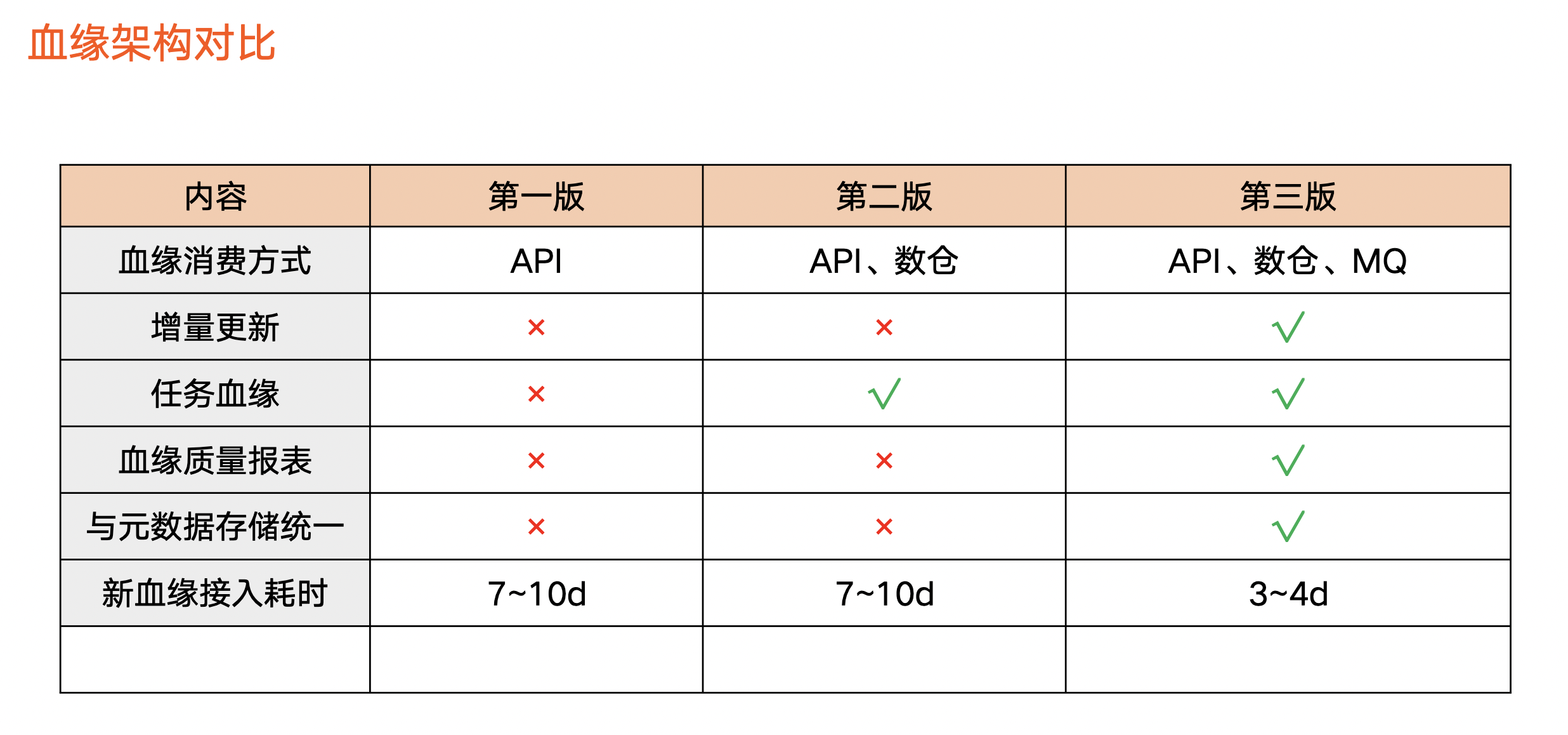
上圖為三個版本對比情況:
-
血緣的消費方式:第一版只支援 API 的方式,使用者需要在資料資產平臺上檢視血緣資訊;第二版支援離線數倉,讓使用者可以全量分析血緣;第三版支援訊息佇列,使使用者可以獲取血緣增量的變化。
-
增量更新:第三版開始支援增量更新。
-
血緣任務:第二個版本開始支援任務血緣,第三個版本支援資料質量。
-
後設資料儲存統一:第三版進行了後設資料架構升級,使得後設資料和血緣儲存在同一個地方。
-
新血緣接入耗時:前兩個版本大概需要花費 7-10 天左右。第三版本引入標準化,外部業務方或位元組內部用標準化流程,實現 3、4 天左右完成開發、測試、上線。
未來展望
第一,持續對架構和流程進行精簡。目前,血緣任務分為離線和實時兩部分,但沒有完全統一。在外掛化、橫向擴充套件等方面也需要加強。
第二,生態化支援。目前支援公司內部的後設資料,未來計劃拓展對開源或外部後設資料的支援。在血緣標準化方面,提供一站式資料血緣能力,作為基礎能力平臺為業務方提供服務。
第三,提升資料質量。除了血緣數量,還需要持續提升質量。同時由於資料鏈路複雜,導致鏈路問題排查異常困難,未來我們也會支援快速診斷。
最後,支援智慧化場景。結合元數倉等資料,提供包含關鍵鏈路梳理在內的智慧化能力。目前,當業務方發現資料有問題之後,主要通過按照血緣資料一個一個排查方式解決,導致效率低下。未來,我們將考慮透出血緣關鍵鏈路,提升排查效率。
以上介紹的資料血緣能力和實踐,目前大部分已通過火山引擎 DataLeap 對外提供服務。
點選跳轉 巨量資料研發治理套件 DataLeap 瞭解更多